Jika kueri SQL berkinerja buruk atau mengembalikan hasil yang tidak sesuai harapan, Anda dapat menggunakan perintah EXPLAIN dan EXPLAIN ANALYZE di Hologres untuk menganalisis rencana eksekusinya. Perintah-perintah ini membantu Anda memahami cara Hologres mengeksekusi kueri sehingga Anda dapat menyesuaikan kueri atau struktur database demi performa yang lebih baik. Topik ini menjelaskan cara menggunakan EXPLAIN dan EXPLAIN ANALYZE di Hologres untuk melihat rencana eksekusi serta menjelaskan makna setiap operator.
Ikhtisar rencana eksekusi
Di Hologres, query optimizer (QO) menghasilkan rencana eksekusi untuk setiap pernyataan SQL. Query engine (QE) kemudian menggunakan rencana tersebut untuk menghasilkan dan mengeksekusi rencana akhir, lalu mengembalikan hasil kueri. Rencana eksekusi mencakup informasi seperti statistik, operator eksekusi, dan waktu proses operator. Rencana eksekusi yang baik mengembalikan hasil lebih cepat dengan penggunaan resource yang lebih sedikit. Oleh karena itu, rencana eksekusi sangat penting dalam pengembangan sehari-hari karena dapat mengungkap masalah SQL dan memberikan panduan untuk optimasi terarah.
Hologres kompatibel dengan PostgreSQL. Anda dapat menggunakan sintaks EXPLAIN dan EXPLAIN ANALYZE untuk memahami rencana eksekusi SQL.
-
EXPLAIN: Menampilkan rencana eksekusi perkiraan dari QO berdasarkan karakteristik SQL. Ini bukan rencana eksekusi aktual, tetapi memberikan referensi yang berguna untuk performa kueri.
-
EXPLAIN ANALYZE: Menampilkan rencana eksekusi aktual saat runtime. Dibandingkan dengan EXPLAIN, output ini mencakup detail eksekusi real-time yang lebih lengkap dan secara akurat mencerminkan operator eksekusi beserta waktu prosesnya. Informasi ini dapat digunakan untuk melakukan optimasi SQL yang terarah.
Mulai dari Hologres V1.3.4x, rencana eksekusi yang ditampilkan oleh EXPLAIN dan EXPLAIN ANALYZE menjadi lebih jelas dan mudah dibaca. Dokumen ini didasarkan pada versi V1.3.4x. Kami menyarankan Anda melakukan upgrade instans ke V1.3.4x atau versi yang lebih baru.
EXPLAIN
-
Sintaksis
Perintah
EXPLAINmenampilkan rencana eksekusi perkiraan dari pengoptimal. Sintaksnya adalah sebagai berikut:EXPLAIN <sql>; -
Contoh
Contoh berikut menggunakan kueri TPC-H.
CatatanContoh ini merujuk pada kueri TPC-H tetapi tidak merepresentasikan hasil resmi benchmark TPC-H.
EXPLAIN SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -
Output
QUERY PLAN Sort (cost=0.00..7795.30 rows=3 width=80) Sort Key: l_returnflag, l_linestatus -> Gather (cost=0.00..7795.27 rows=3 width=80) -> Project (cost=0.00..7795.27 rows=3 width=80) -> Project (cost=0.00..7794.27 rows=3 width=104) -> Final HashAggregate (cost=0.00..7793.27 rows=3 width=76) Group Key: l_returnflag, l_linestatus -> Redistribution (cost=0.00..7792.95 rows=1881 width=76) Hash Key: l_returnflag, l_linestatus -> Partial HashAggregate (cost=0.00..7792.89 rows=1881 width=76) Group Key: l_returnflag, l_linestatus -> Local Gather (cost=0.00..7791.81 rows=44412 width=76) -> Decode (cost=0.00..7791.80 rows=44412 width=76) -> Partial HashAggregate (cost=0.00..7791.70 rows=44412 width=76) Group Key: l_returnflag, l_linestatus -> Project (cost=0.00..3550.73 rows=584421302 width=33) -> Project (cost=0.00..2585.43 rows=584421302 width=33) -> Index Scan using Clustering_index on lineitem (cost=0.00..261.36 rows=584421302 width=25) Segment Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) Cluster Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) -
Penjelasan output
Rencana eksekusi dibaca dari bawah ke atas. Setiap tanda panah (->) merepresentasikan sebuah node, dan setiap node anak mengembalikan detail seperti operator yang digunakan dan perkiraan jumlah baris. Operator utama meliputi hal-hal berikut:
Parameter
Deskripsi
cost
Perkiraan waktu proses operator. Cost pada node induk mencakup cost dari node anaknya. Nilai ini menampilkan startup cost dan total cost, dipisahkan oleh
...-
Startup cost: Cost sebelum fase output dimulai.
-
Total cost: Total cost perkiraan jika operator dijalankan hingga selesai.
Sebagai contoh, pada node Final HashAggregate di atas, startup cost-nya adalah
0.00dan total cost-nya adalah7793.27.rows
Perkiraan jumlah baris output, terutama berdasarkan statistik.
Untuk operasi pemindaian, perkiraan default adalah
1000.CatatanJika Anda melihat
rows=1000, kemungkinan besar statistik tabel sudah usang. Jalankananalyze <tablename>untuk memperbarui statistik.width
Perkiraan rata-rata lebar baris output dalam byte. Nilai yang lebih besar menunjukkan kolom yang lebih lebar.
-
EXPLAIN ANALYZE
-
Sintaksis
Perintah
EXPLAIN ANALYZEmenampilkan rencana eksekusi aktual beserta waktu proses operator untuk membantu mendiagnosis masalah performa SQL. Sintaksnya adalah sebagai berikut:EXPLAIN ANALYZE <sql>; -
Contoh
Contoh berikut menggunakan kueri TPC-H.
EXPLAIN ANALYZE SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -
Output
QUERY PLAN Sort (cost=0.00..7795.30 rows=3 width=80) Sort Key: l_returnflag, l_linestatus [id=21 dop=1 time=2427/2427/2427ms rows=4(4/4/4) mem=3/3/3KB open=2427/2427/2427ms get_next=0/0/0ms] -> Gather (cost=0.00..7795.27 rows=3 width=80) [20:1 id=100003 dop=1 time=2426/2426/2426ms rows=4(4/4/4) mem=1/1/1KB open=0/0/0ms get_next=2426/2426/2426ms] -> Project (cost=0.00..7795.27 rows=3 width=80) [id=19 dop=20 time=2427/2426/2425ms rows=4(1/0/0) mem=87/87/87KB open=2427/2425/2425ms get_next=1/0/0ms] -> Project (cost=0.00..7794.27 rows=0 width=104) -> Final HashAggregate (cost=0.00..7793.27 rows=3 width=76) Group Key: l_returnflag, l_linestatus [id=16 dop=20 time=2427/2425/2424ms rows=4(1/0/0) mem=574/570/569KB open=2427/2425/2424ms get_next=1/0/0ms] -> Redistribution (cost=0.00..7792.95 rows=1881 width=76) Hash Key: l_returnflag, l_linestatus [20:20 id=100002 dop=20 time=2427/2424/2423ms rows=80(20/4/0) mem=3528/1172/584B open=1/0/0ms get_next=2426/2424/2423ms] -> Partial HashAggregate (cost=0.00..7792.89 rows=1881 width=76) Group Key: l_returnflag, l_linestatus [id=12 dop=20 time=2428/2357/2256ms rows=80(4/4/4) mem=574/574/574KB open=2428/2357/2256ms get_next=1/0/0ms] -> Local Gather (cost=0.00..7791.81 rows=44412 width=76) [id=11 dop=20 time=2427/2356/2255ms rows=936(52/46/44) mem=7/6/6KB open=0/0/0ms get_next=2427/2356/2255ms pull_dop=9/9/9] -> Decode (cost=0.00..7791.80 rows=44412 width=76) [id=8 dop=234 time=2435/1484/5ms rows=936(4/4/4) mem=0/0/0B open=2435/1484/5ms get_next=4/0/0ms] -> Partial HashAggregate (cost=0.00..7791.70 rows=44412 width=76) Group Key: l_returnflag, l_linestatus [id=5 dop=234 time=2435/1484/3ms rows=936(4/4/4) mem=313/312/168KB open=2435/1484/3ms get_next=0/0/0ms] -> Project (cost=0.00..3550.73 rows=584421302 width=33) [id=4 dop=234 time=2145/1281/2ms rows=585075720(4222846/2500323/3500) mem=142/141/69KB open=10/1/0ms get_next=2145/1280/2ms] -> Project (cost=0.00..2585.43 rows=584421302 width=33) [id=3 dop=234 time=582/322/2ms rows=585075720(4222846/2500323/3500) mem=142/142/69KB open=10/1/0ms get_next=582/320/2ms] -> Index Scan using Clustering_index on lineitem (cost=0.00..261.36 rows=584421302 width=25) Segment Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) Cluster Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) [id=2 dop=234 time=259/125/1ms rows=585075720(4222846/2500323/3500) mem=1418/886/81KB open=10/1/0ms get_next=253/124/0ms] ADVICE: [node id : 1000xxx] distribution key miss match! table lineitem defined distribution keys : l_orderkey; request distribution columns : l_returnflag, l_linestatus; shuffle data skew in different shards! max rows is 20, min rows is 0 Query id:[300200511xxxx] ======================cost====================== Total cost:[2505] ms Optimizer cost:[47] ms Init gangs cost:[4] ms Build gang desc table cost:[2] ms Start query cost:[18] ms - Wait schema cost:[0] ms - Lock query cost:[0] ms - Create dataset reader cost:[0] ms - Create split reader cost:[0] ms Get the first block cost:[2434] ms Get result cost:[2434] ms ====================resource==================== Memory: 921(244/230/217) MB, straggler worker id: 72969760xxx CPU time: 149772(38159/37443/36736) ms, straggler worker id: 72969760xxx Physical read bytes: 3345(839/836/834) MB, straggler worker id: 72969760xxx Read bytes: 41787(10451/10446/10444) MB, straggler worker id: 72969760xxx DAG instance count: 41(11/10/10), straggler worker id: 72969760xxx Fragment instance count: 275(70/68/67), straggler worker id: 72969760xxx -
Penjelasan output
Perintah
EXPLAIN ANALYZEmenampilkan jalur eksekusi aktual sebagai pohon operator, dengan informasi waktu proses terperinci untuk setiap tahap. Output mencakup empat bagian utama: QUERY PLAN, ADVICE, rincian biaya (Cost breakdown), dan konsumsi resource.
QUERY PLAN
Bagian QUERY PLAN menampilkan informasi eksekusi terperinci untuk setiap operator. Mirip dengan EXPLAIN, Anda dapat membaca rencana kueri EXPLAIN ANALYZE dari bawah ke atas. Setiap tanda panah (->) merepresentasikan sebuah node.
Contoh | Deskripsi |
(cost=0.00..2585.43 rows=584421302 width=33) |
Nilai-nilai ini merepresentasikan perkiraan pengoptimal, bukan pengukuran aktual. Maknanya sama seperti pada EXPLAIN.
|
[20:20 id=100002 dop=20 time=2427/2424/2423ms rows=80(20/4/0) mem=3528/1172/584B open=1/0/0ms get_next=2426/2424/2423ms] |
Nilai-nilai ini merepresentasikan pengukuran waktu proses aktual.
|
Karena satu pernyataan SQL dapat melibatkan beberapa operator, bagian berikut memberikan penjelasan terperinci untuk setiap operator. Untuk informasi lebih lanjut, lihat Makna operator.
Perhatikan hal berikut mengenai nilai time, rows, dan mem:
-
Nilai time suatu operator mencakup waktu kumulatif dari operator anaknya. Untuk menentukan waktu aktual operator tersebut, Anda dapat mengurangi waktu operator anaknya.
-
Nilai rows dan mem bersifat independen untuk setiap operator dan tidak kumulatif.
ADVICE
Bagian ADVICE berisi saran penyetelan otomatis berdasarkan hasil EXPLAIN ANALYZE saat ini:
-
Saran untuk mengatur kunci distribusi, kunci pengelompokan, atau indeks bitmap, seperti
Table xxx misses bitmap index. -
Statistik tabel tidak tersedia:
Table xxx Miss Stats! please run 'analyze xxx';. -
Kemungkinan adanya kesenjangan data:
shuffle data xxx in different shards! max rows is 20, min rows is 0.
Saran ini hanya berdasarkan hasil EXPLAIN ANALYZE saat ini dan mungkin tidak selalu berlaku. Anda harus menganalisis skenario bisnis spesifik Anda sebelum mengambil tindakan.
Biaya dan konsumsi waktu
Bagian Biaya menampilkan total waktu kueri dan rincian waktu untuk setiap fase. Informasi ini dapat digunakan untuk mengidentifikasi bottleneck performa.
Total cost: Total waktu eksekusi kueri dalam milidetik (ms). Termasuk biaya-biaya berikut:
-
Optimizer cost: Waktu yang dihabiskan QO untuk menghasilkan rencana eksekusi, dalam ms.
-
Build gang desc table cost: Waktu yang diperlukan untuk mengonversi rencana eksekusi QO menjadi struktur data yang dibutuhkan oleh mesin eksekusi, dalam ms.
-
Init gangs cost: Waktu yang diperlukan untuk pra-pemrosesan rencana eksekusi QO dan mengirim permintaan ke mesin eksekusi sebelum kueri dimulai, dalam ms.
-
Start query cost: Waktu inisialisasi setelah Init gangs selesai tetapi sebelum eksekusi kueri aktual dimulai. Ini mencakup penyelarasan skema, penguncian, dan proses persiapan lainnya:
-
Wait schema cost: Waktu yang diperlukan bagi storage engine (SE) dan frontend (FE) untuk menyelaraskan versi skema. Latensi tinggi biasanya terjadi ketika SE memproses lambat, terutama dengan operasi Data Definition Language (DDL) yang sering pada tabel induk partisi. Hal ini dapat memperlambat penulisan dan kueri data. Anda dapat mempertimbangkan untuk mengoptimalkan frekuensi DDL.
-
Lock query cost: Waktu yang dihabiskan untuk mendapatkan kunci kueri. Nilai tinggi menunjukkan adanya kontensi kunci.
-
Create dataset reader cost: Waktu yang diperlukan untuk membuat pembaca data indeks. Nilai tinggi dapat mengindikasikan cache miss.
-
Create split reader cost: Waktu yang diperlukan untuk membuka file. Nilai tinggi menunjukkan cache miss metadata dan overhead I/O yang tinggi.
-
-
Get result cost: Waktu dari selesainya fase Start query hingga semua hasil dikembalikan, dalam ms. Ini mencakup Get the first block cost.
-
Get the first block cost: Waktu dari selesainya fase Start query hingga batch catatan pertama dikembalikan. Metrik ini sangat mirip dengan Get result cost ketika operator teratas, seperti Hash Agg, memerlukan data downstream penuh sebelum dapat menghasilkan output. Untuk kueri yang difilter dengan hasil streaming, nilai ini biasanya jauh lebih rendah daripada Get result cost, tergantung pada volume data.
-
Konsumsi resource
Bagian Resource menampilkan penggunaan resource kueri dalam format total(max/avg/min). Ini mencakup total konsumsi resource dan nilai max, avg, serta min per worker.
Karena Hologres merupakan mesin terdistribusi dengan banyak node pekerja, hasilnya digabungkan setelah setiap worker menyelesaikan pemrosesan. Konsumsi resource dilaporkan sebagai total(max worker/avg worker/min worker):
-
total: Total konsumsi resource dari kueri.
-
max: Konsumsi maksimum oleh satu node pekerja.
-
avg: Konsumsi rata-rata per node pekerja, yaitu total konsumsi dibagi jumlah worker.
-
min: Konsumsi minimum oleh satu node pekerja.
Bagian berikut memberikan penjelasan terperinci mengenai metrik resource:
Metrik | Deskripsi |
Memory |
Total memori yang dikonsumsi selama eksekusi kueri, termasuk total memori plus nilai max, avg, dan min per node pekerja. |
CPU time |
Total waktu CPU yang dikonsumsi oleh pernyataan kueri SQL, yang tidak akurat. Unit: milidetik. Total waktu CPU yang dikonsumsi selama eksekusi kueri (dalam ms, perkiraan). Merepresentasikan waktu CPU kumulatif di seluruh core, secara kasar mengindikasikan kompleksitas kueri. |
Physical read bytes |
Data yang dibaca dari disk dalam byte. Terjadi ketika hasil kueri tidak di-cache. |
Read bytes |
Total byte yang dibaca selama eksekusi kueri dalam byte, termasuk pembacaan fisik dan data yang di-cache. Mencerminkan total data yang diproses. |
Affected rows |
Jumlah baris yang terpengaruh oleh operasi DML. Hanya ditampilkan untuk pernyataan DML. |
Dag instance count |
Jumlah instance DAG dalam rencana kueri. Nilai yang lebih tinggi mengindikasikan kompleksitas dan paralelisme kueri yang lebih besar. |
Fragment instance count |
Jumlah instance fragmen dalam rencana kueri. Nilai yang lebih tinggi mengindikasikan lebih banyak rencana eksekusi dan file. |
straggler_worker_id |
ID node pekerja dengan konsumsi resource maksimum untuk metrik ini. |
Makna operator
SCAN
-
seq scan
Operator Seq Scan membaca data secara berurutan dari tabel dan melakukan pemindaian tabel penuh. Nama tabel mengikuti kata kunci
on.Contoh: Saat Anda mengkueri tabel internal biasa, operator Seq Scan ditampilkan dalam rencana eksekusi.
EXPLAIN SELECT * FROM public.holo_lineitem_100g;Output:
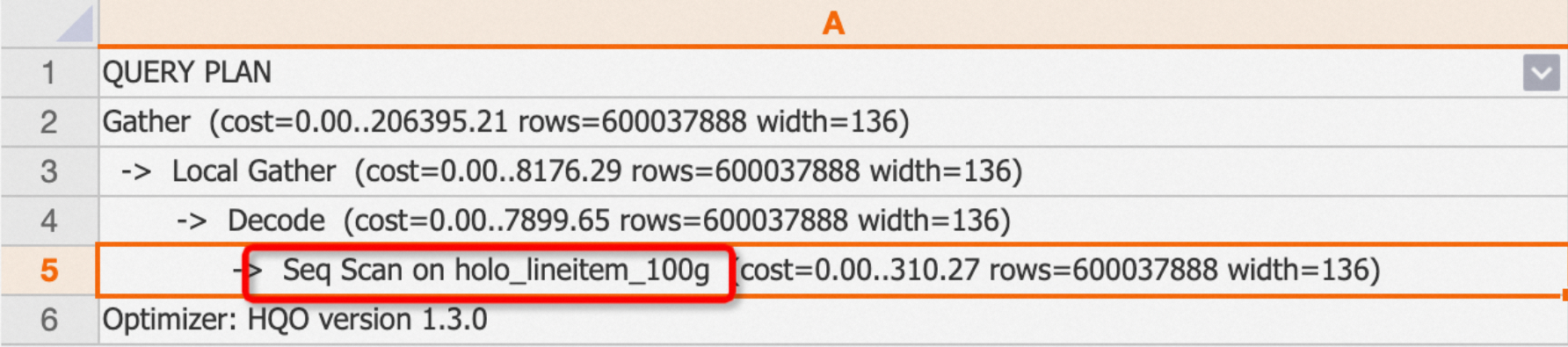
-
Mengkueri tabel partisi
Untuk tabel partisi, rencana menampilkan operator
Seq Scan on Partitioned Tabledan menunjukkan berapa banyak partisi yang dipindai menggunakan "Partitions selected: x out of y".Contoh: Mengkueri tabel induk partisi di mana hanya satu partisi yang dipindai.
EXPLAIN SELECT * FROM public.hologres_parent;Output:

-
Mengkueri tabel eksternal
Untuk tabel eksternal, rencana mencakup operator
Foreign Table Typeuntuk menunjukkan sumbernya. Jenisnya meliputi MaxCompute, OSS, dan Hologres.Contoh: Mengkueri tabel eksternal MaxCompute.
EXPLAIN SELECT * FROM public.odps_lineitem_100;Output:
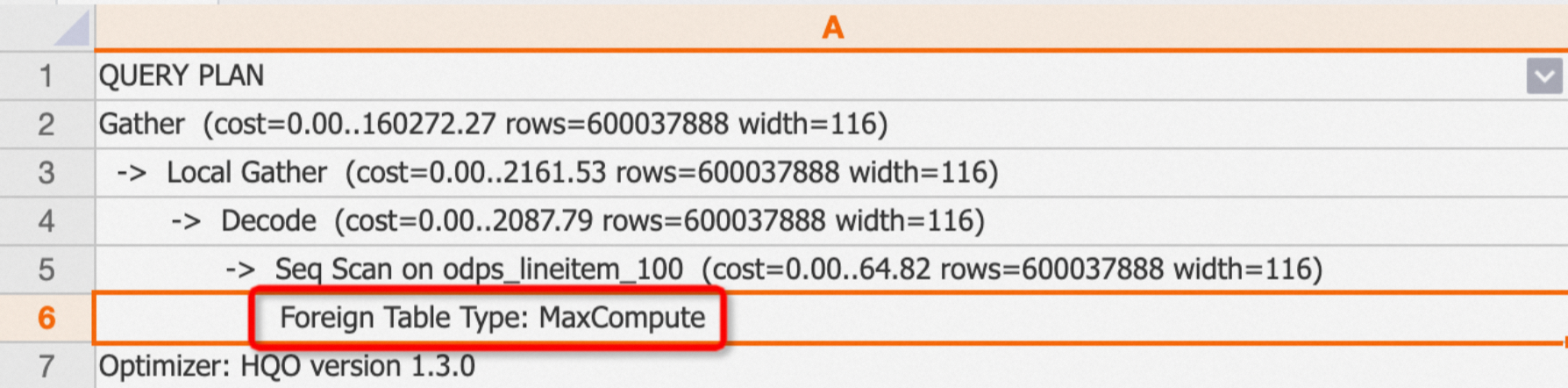
-
-
Index Scan dan Index Seek
Saat pemindaian tabel mengenai indeks, Hologres menggunakan indeks dasar yang berbeda berdasarkan format penyimpanan, yaitu berorientasi baris atau berorientasi kolom. Dua jenis indeks utama adalah Clustering_index dan Index Seek, yang juga disebut pk_index:
-
Clustering_index: Digunakan untuk tabel berorientasi kolom dengan fitur seperti segment dan clustering. Operator ini muncul setiap kali kueri mengenai indeks. Operator
Seq Scan Using Clustering_indexbiasanya muncul dengan subnode Filter yang mencantumkan indeks yang cocok, seperti clustering filter, segment filter, atau bitmap filter. Untuk informasi lebih lanjut, lihat Prinsip penyimpanan kolom.-
Contoh 1: Kueri menggunakan indeks.
BEGIN; CREATE TABLE column_test ( "id" bigint not null , "name" text not null , "age" bigint not null ); CALL set_table_property('column_test', 'orientation', 'column'); CALL set_table_property('column_test', 'distribution_key', 'id'); CALL set_table_property('column_test', 'clustering_key', 'id'); COMMIT; INSERT INTO column_test VALUES(1,'tom',10),(2,'tony',11),(3,'tony',12); EXPLAIN SELECT * FROM column_test WHERE id>2;Output:
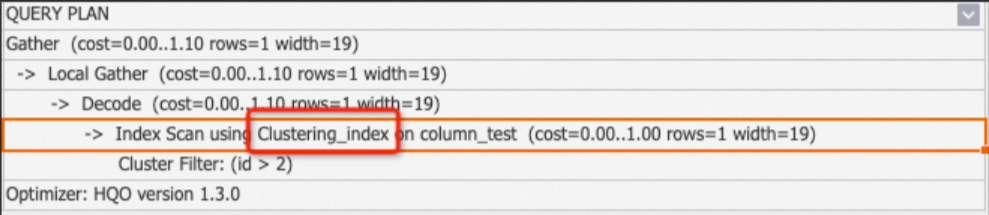
-
Contoh 2: Kueri tidak mengenai indeks, sehingga clustering_index tidak digunakan.
EXPLAIN SELECT * FROM column_test WHERE age>10;Output:

-
-
Index Seek (juga disebut pk_index): Digunakan untuk tabel berorientasi baris dengan indeks kunci primer. Kueri titik (point queries) pada tabel berorientasi baris dengan kunci primer biasanya menggunakan Fixed Plan. Namun, kueri yang tidak menggunakan Fixed Plan tetapi memiliki kunci primer menggunakan pk_index. Untuk informasi lebih lanjut, lihat Prinsip penyimpanan baris.
Contoh: Mengkueri tabel berorientasi baris.
BEGIN; CREATE TABLE row_test_1 ( id bigint not null, name text not null, class text , PRIMARY KEY (id) ); CALL set_table_property('row_test_1', 'orientation', 'row'); CALL set_table_property('row_test_1', 'clustering_key', 'name'); COMMIT; INSERT INTO row_test_1 VALUES ('1','qqq','3'),('2','aaa','4'),('3','zzz','5'); BEGIN; CREATE TABLE row_test_2 ( id bigint not null, name text not null, class text , PRIMARY KEY (id) ); CALL set_table_property('row_test_2', 'orientation', 'row'); CALL set_table_property('row_test_2', 'clustering_key', 'name'); COMMIT; INSERT INTO row_test_2 VALUES ('1','qqq','3'),('2','aaa','4'),('3','zzz','5'); --primary key index EXPLAIN SELECT * FROM (SELECT id FROM row_test_1 WHERE id = 1) t1 JOIN row_test_2 t2 ON t1.id = t2.id;Output:

-
Filter
Operator Filter menerapkan kondisi SQL pada data. Biasanya muncul sebagai node anak dari operator seq scan, yang menunjukkan apakah filter diterapkan selama pemindaian tabel dan apakah filter tersebut mengenai indeks apa pun. Jenis filter sebagai berikut:
-
Filter
Jika rencana hanya menampilkan "Filter", kondisi tersebut tidak mengenai indeks apa pun. Anda dapat memeriksa indeks tabel dan menambahkan indeks yang sesuai untuk meningkatkan performa kueri.
CatatanJika rencana menampilkan
One-Time Filter: false, set hasilnya kosong.Contoh:
BEGIN; CREATE TABLE clustering_index_test ( "id" bigint not null , "name" text not null , "age" bigint not null ); CALL set_table_property('clustering_index_test', 'orientation', 'column'); CALL set_table_property('clustering_index_test', 'distribution_key', 'id'); CALL set_table_property('clustering_index_test', 'clustering_key', 'age'); COMMIT; INSERT INTO clustering_index_test VALUES (1,'tom',10),(2,'tony',11),(3,'tony',12); EXPLAIN SELECT * FROM clustering_index_test WHERE id>2;Output:
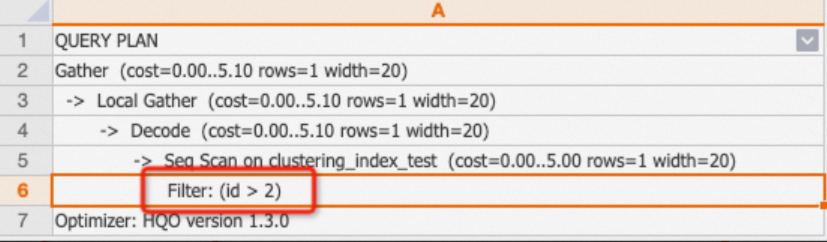
-
Segment Filter
Segment Filter menunjukkan bahwa kueri mengenai indeks segment. Operator ini muncul bersama index_scan. Untuk informasi lebih lanjut, lihat Kolom Waktu Event (Segment Key).
-
Cluster Filter
Cluster Filter menunjukkan bahwa kueri mengenai indeks clustering. Untuk informasi lebih lanjut, lihat Kunci Pengelompokan.
-
Bitmap Filter
Bitmap Filter menunjukkan bahwa kueri mengenai indeks bitmap. Untuk informasi lebih lanjut, lihat Indeks bitmap.
-
Join Filter
Menerapkan penyaringan tambahan setelah operasi join.
Decode
Operator Decode melakukan decoding atau encoding data untuk mempercepat komputasi pada tipe data teks dan sejenisnya.
Local Gather dan Gather
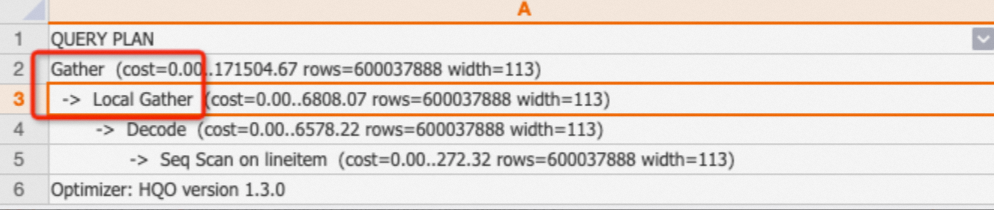
Di Hologres, data disimpan sebagai file dalam shard. Operator Local Gather menggabungkan data dari beberapa file menjadi satu shard. Operator Gather menggabungkan data dari beberapa shard menjadi hasil akhir.
Contoh:
EXPLAIN SELECT * FROM public.lineitem;Output: Rencana eksekusi menunjukkan bahwa data dipindai, lalu digabungkan di tingkat shard oleh operator Local Gather, dan akhirnya dikombinasikan oleh operator Gather.
Redistribution
Operator Redistribution mengacak data di antara shard menggunakan distribusi hash atau acak selama kueri.
-
Operator Redistribution digunakan dalam skenario umum berikut:
-
Operator ini biasanya muncul dalam operasi join, count distinct (yang pada dasarnya adalah join), dan group by ketika kunci distribusi tidak diatur atau diatur secara salah. Hal ini menyebabkan data diacak di antara shard. Pada join multi-tabel, operator Redistribution menunjukkan bahwa kemampuan join lokal tidak dimanfaatkan, yang mengakibatkan performa buruk.
-
Operator ini terjadi ketika kunci join atau group by melibatkan ekspresi yang mengubah tipe field asli, seperti casting, yang mencegah penggunaan join lokal.
-
-
Contoh:
-
Contoh 1: Join dua tabel dengan kunci distribusi tidak sesuai menyebabkan Redistribution.
BEGIN; CREATE TABLE tbl1( a int not null, b text not null ); CALL set_table_property('tbl1', 'distribution_key', 'a'); CREATE TABLE tbl2( c int not null, d text not null ); CALL set_table_property('tbl2', 'distribution_key', 'd'); COMMIT; EXPLAIN SELECT * FROM tbl1 JOIN tbl2 ON tbl1.a=tbl2.c;Output: Rencana eksekusi menunjukkan operator Redistribution karena kunci distribusi tidak sesuai. Kondisi join adalah
tbl1.a=tbl2.c, tetapi kunci distribusinya adalah a dan d. Hal ini menyebabkan pengacakan data.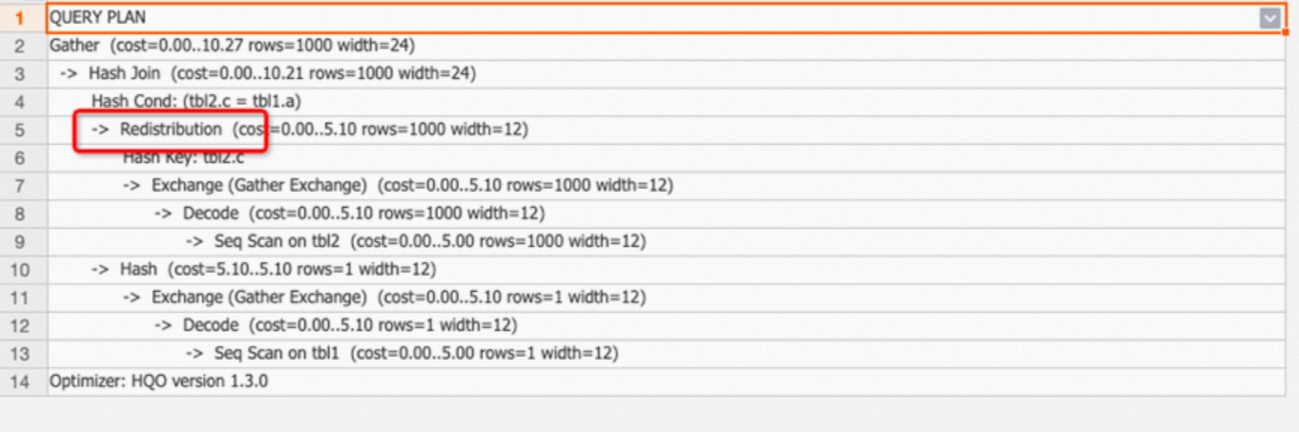
Saran penyetelan: Jika operator Redistribution muncul, periksa apakah kunci distribusi diatur dengan benar. Untuk informasi lebih lanjut tentang skenario dan panduan, lihat Kunci Distribusi.
-
Contoh 2: Rencana eksekusi menunjukkan operator Redistribution karena kunci join melibatkan ekspresi yang mengubah tipe field. Hal ini mencegah penggunaan join lokal.

Untuk penyetelan performa, hindari penggunaan ekspresi.
-
Join
Seperti pada database standar, operator join menggabungkan beberapa tabel. Berdasarkan sintaks SQL, join diklasifikasikan sebagai hash join, nested loop, atau merge join.
-
Hash Join
Hash join membangun tabel hash di memori dari satu tabel—biasanya yang lebih kecil—dan melakukan hashing pada nilai kolom join. Kemudian, hash join membaca tabel lain baris demi baris, menghitung nilai hash, dan mencarinya di tabel hash untuk mengembalikan data yang cocok. Jenis hash join sebagai berikut:
Jenis
Deskripsi
Hash Left Join
Pada join multi-tabel, sistem mengembalikan semua baris dari tabel kiri dan mencocokkannya dengan baris yang sesuai dari tabel kanan. Jika tidak ditemukan kecocokan untuk suatu baris di tabel kiri, kolom untuk tabel kanan akan berisi nilai null.
Hash Right Join
Mengembalikan semua baris dari tabel kanan dan baris yang cocok dari tabel kiri. Baris tabel kiri yang tidak cocok mengembalikan null.
Hash Inner Join
Hanya mengembalikan baris yang memenuhi kondisi join.
Hash Full Join
Mengembalikan semua baris dari kedua tabel. Baris yang tidak cocok mengembalikan null untuk tabel yang tidak sesuai.
Hash Anti Join
Hanya mengembalikan baris yang tidak cocok, umumnya digunakan untuk kondisi NOT EXISTS.
Hash Semi Join
Mengembalikan satu baris untuk setiap kecocokan, biasanya dari kondisi EXISTS. Hasil tidak mengandung duplikat.
Saat menganalisis rencana eksekusi hash join, Anda juga harus memeriksa node anak berikut:
-
hash cond: Kondisi join, misalnya,
hash cond (tmp.a=tmp1.b). hash key: Kunci yang digunakan untuk perhitungan hash di beberapa shard. Dalam kebanyakan kasus, kunci ini menunjukkan kunci klausa GROUP BY.
Saat hash join muncul, Anda harus memverifikasi bahwa tabel yang lebih kecil berdasarkan volume data digunakan sebagai tabel hash. Anda dapat memeriksanya dengan cara berikut:
-
Dalam rencana eksekusi, tabel yang mengandung kata hash adalah tabel hash.
Dalam rencana eksekusi, saat Anda melihatnya dari bawah ke atas, tabel paling bawah adalah tabel hash.
Saran penyetelan:
-
Perbarui statistik
Prinsip penyetelan inti untuk hash join adalah menggunakan tabel yang lebih kecil sebagai tabel hash. Menggunakan tabel besar sebagai tabel hash mengonsumsi memori berlebihan. Hal ini biasanya terjadi ketika statistik tabel sudah usang, sehingga QO salah memilih tabel yang lebih besar.
Contoh: Statistik usang (rows=1000) menyebabkan tabel yang lebih besar hash_join_test_2, yang memiliki 1 juta baris, digunakan sebagai tabel hash alih-alih tabel yang lebih kecil hash_join_test_1 dengan 10.000 baris. Hal ini mengurangi efisiensi kueri.
BEGIN ; CREATE TABLE public.hash_join_test_1 ( a integer not null, b text not null ); CALL set_table_property('public.hash_join_test_1', 'distribution_key', 'a'); CREATE TABLE public.hash_join_test_2 ( c integer not null, d text not null ); CALL set_table_property('public.hash_join_test_2', 'distribution_key', 'c'); COMMIT ; INSERT INTO hash_join_test_1 SELECT i, i+1 FROM generate_series(1, 10000) AS s(i); INSERT INTO hash_join_test_2 SELECT i, i::text FROM generate_series(10, 1000000) AS s(i); EXPLAIN SELECT * FROM hash_join_test_1 tbl1 JOIN hash_join_test_2 tbl2 ON tbl1.a=tbl2.c;Rencana eksekusi menunjukkan bahwa tabel yang lebih besar hash_join_test_2 digunakan sebagai tabel hash:

Jika statistik tidak diperbarui, Anda dapat menjalankan perintah
analyze <tablename>secara manual. Contoh:ANALYZE hash_join_test_1; ANALYZE hash_join_test_2;Rencana yang diperbarui dengan benar menggunakan tabel yang lebih kecil hash_join_test_1 sebagai tabel hash dengan perkiraan jumlah baris yang akurat.

-
Sesuaikan urutan join
Pembaruan statistik menyelesaikan sebagian besar masalah join. Namun, untuk join multi-tabel kompleks dengan lima atau lebih tabel, QO Hologres menghabiskan waktu signifikan untuk memilih rencana eksekusi optimal. Anda dapat menggunakan parameter Grand Unified Configuration (GUC) berikut untuk mengontrol urutan join dan mengurangi overhead QO:
SET optimizer_join_order = '<value>';Opsi nilai:
Nilai
Deskripsi
exhaustive (default)
Menggunakan algoritma untuk mengubah urutan join, menghasilkan rencana optimal tetapi meningkatkan overhead pengoptimal untuk join multi-tabel.
query
Menghasilkan rencana persis seperti yang ditulis dalam SQL tanpa perubahan pengoptimal. Hanya cocok untuk join multi-tabel dengan tabel kecil (di bawah 100 juta baris) untuk mengurangi overhead QO. Jangan atur ini di tingkat database karena memengaruhi join lainnya.
greedy
Menggunakan algoritma greedy untuk menghasilkan urutan join dengan overhead pengoptimal moderat.
-
-
Nested Loop Join dan Materialize
Operator Nested Loop melakukan join nested loop. Operator ini membaca data dari satu tabel—tabel luar—lalu melakukan iterasi melalui tabel lain—tabel dalam—untuk setiap baris luar. Hal ini secara efektif menghitung Produk Kartesius. Tabel dalam biasanya menampilkan operator Materialize dalam rencana eksekusi.
Saran penyetelan:
-
Pada join Nested Loop, tabel dalam dikendalikan oleh tabel luar. Setiap baris luar mencari kecocokan di tabel dalam. Anda dapat menjaga set hasil luar tetap kecil untuk menghindari konsumsi resource berlebihan.
-
Join non-equi biasanya menghasilkan join Nested Loop. Anda dapat menghindari penggunaan join non-equi dalam SQL.
-
Contoh join Nested Loop:
BEGIN; CREATE TABLE public.nestedloop_test_1 ( a integer not null, b integer not null ); CALL set_table_property('public.nestedloop_test_1', 'distribution_key', 'a'); CREATE TABLE public.nestedloop_test_2 ( c integer not null, d text not null ); CALL set_table_property('public.nestedloop_test_2', 'distribution_key', 'c'); COMMIT; INSERT INTO nestedloop_test_1 SELECT i, i+1 FROM generate_series(1, 10000) AS s(i); INSERT INTO nestedloop_test_2 SELECT i, i::text FROM generate_series(10, 1000000) AS s(i); EXPLAIN SELECT * FROM nestedloop_test_1 tbl1,nestedloop_test_2 tbl2 WHERE tbl1.a>tbl2.c;Rencana eksekusi menunjukkan operator Materialize dan Nested Loop, yang mengonfirmasi jalur join Nested Loop.

-
-
Cross Join
Mulai dari V3.0, operator Cross Join mengoptimalkan Nested Loop Join untuk skenario seperti join non-equi dengan tabel kecil. Berbeda dengan Nested Loop Join yang mengambil satu baris luar dalam satu waktu, memindai seluruh tabel dalam, dan mengatur ulang status dalam, Cross Join memuat seluruh tabel kecil ke memori lalu melakukan join dengan data streaming dari tabel besar. Hal ini secara signifikan meningkatkan performa. Namun, Cross Join menggunakan lebih banyak memori daripada Nested Loop Join.
Anda dapat memeriksa rencana kueri untuk operator Cross Join guna mengonfirmasi penggunaannya.
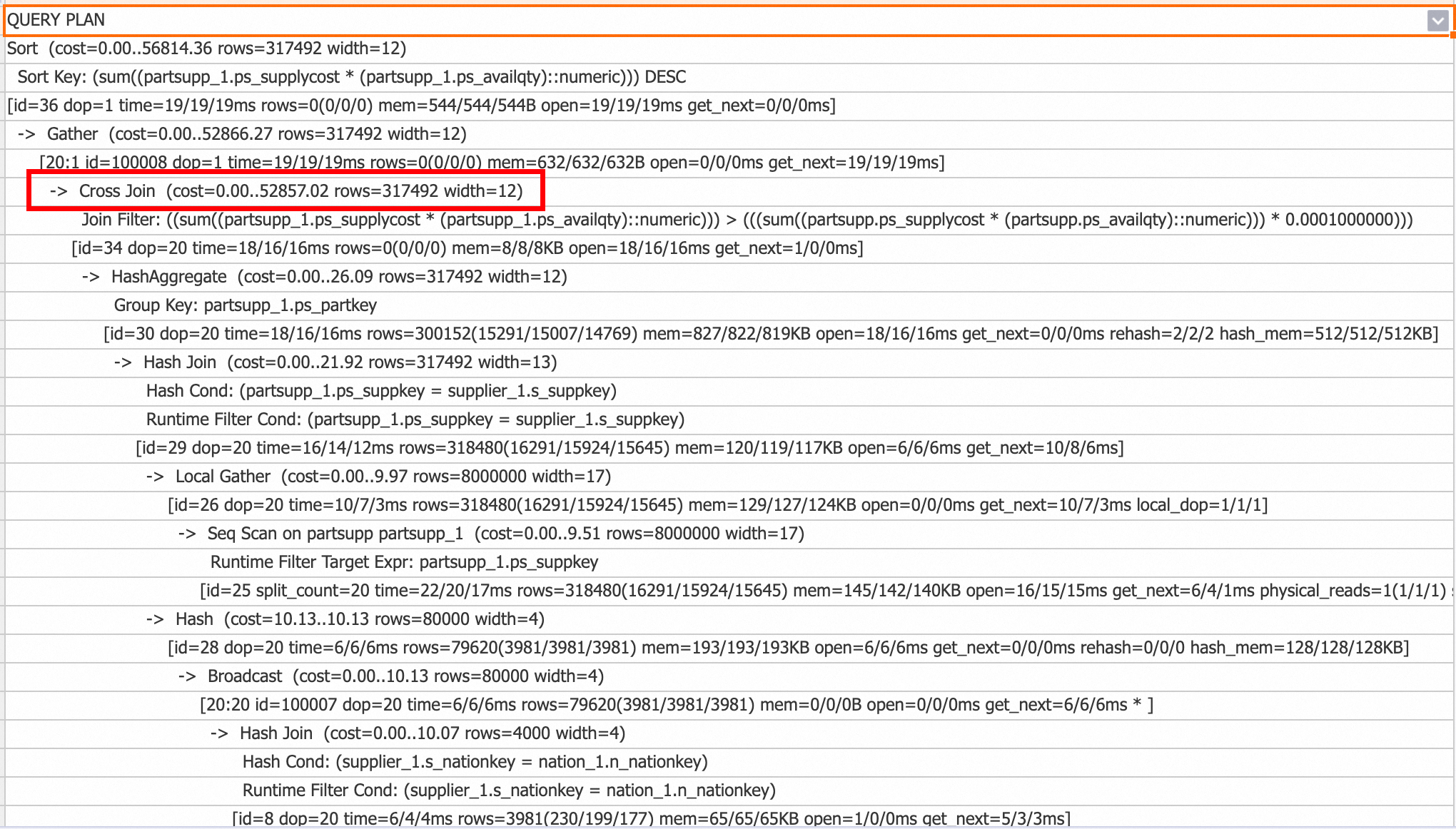
Untuk menonaktifkan Cross Join, jalankan perintah berikut:
-- Nonaktifkan di tingkat session SET hg_experimental_enable_cross_join_rewrite = off; -- Nonaktifkan di tingkat database (berlaku untuk koneksi baru) ALTER database <database name> hg_experimental_enable_cross_join_rewrite = off;
Broadcast
Operator Broadcast mendistribusikan data ke semua shard dan biasanya digunakan dalam skenario Broadcast Join di mana tabel kecil di-join dengan tabel besar. QO membandingkan biaya redistribusi dan Broadcast untuk menghasilkan rencana eksekusi optimal.
Saran penyetelan:
-
Broadcast hemat biaya ketika tabelnya kecil dan instans memiliki jumlah shard yang sedikit, misalnya jumlah shard sebesar 5.
Contoh: Join dua tabel dengan ukuran tabel yang sangat berbeda.
BEGIN; CREATE TABLE broadcast_test_1 ( f1 int, f2 int); CALL set_table_property('broadcast_test_1','distribution_key','f2'); CREATE TABLE broadcast_test_2 ( f1 int, f2 int); COMMIT; INSERT INTO broadcast_test_1 SELECT i AS f1, i AS f2 FROM generate_series(1, 30)i; INSERT INTO broadcast_test_2 SELECT i AS f1, i AS f2 FROM generate_series(1, 30000)i; ANALYZE broadcast_test_1; ANALYZE broadcast_test_2; EXPLAIN SELECT * FROM broadcast_test_1 t1, broadcast_test_2 t2 WHERE t1.f1=t2.f1;Output:

-
Jika operator Broadcast muncul untuk tabel yang tidak kecil, kemungkinan besar disebabkan oleh statistik yang usang. Misalnya, statistik menunjukkan 1.000 baris tetapi pemindaian aktual sebanyak 1 juta baris. Anda dapat memperbarui statistik dengan menjalankan perintah
analyze <tablename>.
Shard prune dan Shards selected
-
Shard prune
Ini menunjukkan cara shard dipilih:
-
lazily: Shard yang relevan pertama-tama ditandai berdasarkan ID shard lalu dipilih selama komputasi.
-
eagerly: Hanya shard yang relevan yang langsung dipilih berdasarkan kecocokan, dan shard yang tidak perlu dilewati.
Pengoptimal secara otomatis memilih metode Shard prune yang sesuai. Tidak diperlukan penyesuaian manual.
-
-
Shards selected
Ini menunjukkan berapa banyak shard yang dipilih. Sebagai contoh, 1 out of 20 berarti 1 shard dipilih dari total 20 shard.
ExecuteExternalSQL
Seperti dijelaskan dalam Arsitektur layanan Hologres, mesin komputasi mencakup komponen Hologres Query Engine (HQE), PostgreSQL Query Engine (PQE), dan Shard Query Engine (SQE). PQE adalah mesin PostgreSQL native. Jika HQE proprietary Hologres tidak mendukung operator atau fungsi tertentu, mereka dieksekusi oleh PQE, yang kurang efisien dibandingkan HQE. Operator ExecuteExternalSQL dalam rencana eksekusi menunjukkan bahwa suatu fungsi atau operator menggunakan PQE.
-
Contoh 1: SQL menggunakan PQE.
CREATE TABLE pqe_test(a text); INSERT INTO pqe_test VALUES ('2023-01-28 16:25:19.082698+08'); EXPLAIN SELECT a::timestamp FROM pqe_test;Rencana eksekusi sebagai berikut. Kehadiran operator ExecuteExternalSQL menunjukkan bahwa operator
::timestampdiproses oleh PQE.
-
Contoh 2: Jika Anda menulis ulang
::timestampsebagaito_timestamp, HQE digunakan sebagai gantinya.EXPLAIN SELECT to_timestamp(a,'YYYY-MM-DD HH24:MI:SS') FROM pqe_test;Rencana eksekusi sebagai berikut: hasilnya tidak mengandung ExecuteExternalSQL, menunjukkan bahwa PQE tidak digunakan.

Saran penyetelan: Anda dapat mengidentifikasi fungsi atau operator yang menggunakan PQE dalam rencana eksekusi dan menulis ulang agar menggunakan HQE demi performa yang lebih baik. Untuk informasi lebih lanjut tentang contoh penulisan ulang umum, lihat Optimalkan performa kueri.
Hologres terus meningkatkan dukungan PQE di setiap versi dengan mendorong lebih banyak operasi PQE ke HQE. Beberapa fungsi mungkin secara otomatis menggunakan HQE setelah Anda melakukan upgrade versi. Untuk informasi lebih lanjut, lihat Catatan rilis fungsi.
Aggregate
Operator Aggregate menggabungkan data menggunakan satu atau beberapa fungsi agregat. Berdasarkan sintaks SQL, agregasi diklasifikasikan sebagai HashAggregate, GroupAggregate, dan sebagainya.
-
GroupAggregate: Data telah diurutkan sebelumnya berdasarkan kunci group by.
-
HashAggregate (paling umum): Data di-hash dan didistribusikan di seluruh shard untuk agregasi, lalu digabungkan menggunakan operator Gather.
EXPLAIN SELECT l_orderkey,count(l_linenumber) FROM public.holo_lineitem_100g GROUP BY l_orderkey; -
Multi-stage HashAggregate: Karena data disimpan dalam file di dalam shard, dataset besar memerlukan beberapa tahap agregasi. Sub-operator utama sebagai berikut:
-
Partial HashAggregate: Melakukan agregasi di dalam file dan shard.
-
Final HashAggregate: Menggabungkan data agregasi dari beberapa shard.
Contoh: Kueri TPC-H Q6 yang menggunakan multi-stage HashAggregate.
EXPLAIN SELECT sum(l_extendedprice * l_discount) AS revenue FROM lineitem WHERE l_shipdate >= date '1996-01-01' AND l_shipdate < date '1996-01-01' + interval '1' year AND l_discount BETWEEN 0.02 - 0.01 AND 0.02 + 0.01 AND l_quantity < 24;Output:

Saran penyetelan: Pengoptimal secara otomatis memilih HashAggregate satu tahap atau multi-tahap berdasarkan volume data. Jika EXPLAIN ANALYZE menunjukkan nilai waktu operator Aggregate yang tinggi, volume data kemungkinan besar besar tetapi pengoptimal hanya melakukan agregasi tingkat shard tanpa agregasi tingkat file. Anda dapat memaksa multi-stage HashAggregate dengan menjalankan perintah berikut:
SET optimizer_force_multistage_agg = on; -
Sort
Operator Sort mengurutkan data dalam urutan menaik (ASC) atau menurun (DESC). Operator ini biasanya berasal dari klausa ORDER BY.
Contoh: Mengurutkan tabel lineitem TPC-H berdasarkan l_shipdate.
EXPLAIN SELECT l_shipdate FROM public.lineitem ORDER BY l_shipdate;Output:
Saran penyetelan: Operasi pengurutan besar mengonsumsi resource signifikan. Anda dapat menghindari pengurutan dataset besar bila memungkinkan.
Limit
Operator Limit menentukan jumlah maksimum baris yang dikembalikan oleh pernyataan SQL. Perhatikan bahwa operator Limit hanya mengontrol baris output akhir, bukan jumlah baris yang benar-benar dipindai. Anda dapat memeriksa apakah operator Limit didorong ke node Seq Scan untuk menentukan jumlah baris yang benar-benar dipindai.
Contoh: Pada pernyataan SQL berikut, LIMIT 1 didorong ke operator Seq Scan, sehingga hanya satu baris yang dipindai.
EXPLAIN SELECT * FROM public.lineitem limit 1;Output: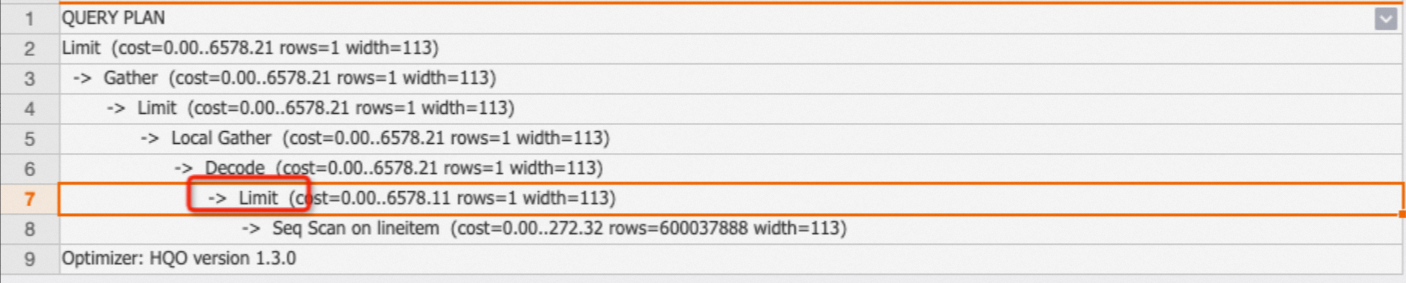
Saran penyetelan:
-
Tidak semua operator Limit didorong ke bawah. Anda dapat menambahkan lebih banyak kondisi filter untuk menghindari pemindaian tabel penuh.
-
Hindari penggunaan nilai LIMIT yang sangat besar, seperti ratusan ribu atau jutaan, karena meningkatkan waktu pemindaian bahkan ketika didorong ke bawah.
Append
Hasil subkueri biasanya digabungkan menggunakan operasi Union All.
Exchange
Data dipertukarkan di dalam satu shard. Tidak diperlukan tindakan.
Forward
Operator Forward mentransfer data operator antara HQE dan PQE atau SQE. Operator ini biasanya muncul dalam kombinasi HQE+PQE atau HQE+SQE.
Project
Operator Project merepresentasikan hubungan pemetaan antara subkueri dan kueri luar. Operator ini tidak memerlukan perhatian khusus.
Referensi
Untuk melihat rencana eksekusi secara visual di HoloWeb, lihat Lihat rencana eksekusi.