Topik ini menjawab pertanyaan umum mengenai validitas data di Realtime Compute for Apache Flink.
Mengapa saya tidak mendapatkan output di tabel sink?
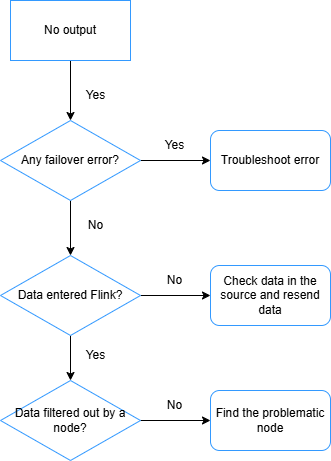
Setelah pekerjaan dimulai, tidak ada data yang muncul di tabel sink. Lakukan pemeriksaan berikut secara berurutan.
-
Periksa adanya failover. Jika pekerjaan mengalami failover, analisis pesan error untuk mengidentifikasi akar penyebab dan selesaikan agar pekerjaan berjalan sesuai harapan.
-
Verifikasi bahwa data telah mencapai Realtime Compute for Apache Flink. Jika tidak terjadi failover tetapi latensi data sangat tinggi, periksa metrik
numRecordsInOfSourcepada halaman pemantauan dan peringatan. Jika metrik menunjukkan nol untuk suatu sumber, berarti tabel sumber tidak mengirim data ke Flink — selidiki sumber data upstream. -
Periksa apakah suatu operator menyaring semua catatan. Tambahkan
pipeline.operator-chaining: 'false'ke bidang Other Configuration (lihat Cara mengonfigurasi parameter running kustom untuk pekerjaan?). Ini akan memisahkan rantai operator sehingga Anda dapat memeriksa metrik Bytes Received dan Bytes Sent masing-masing operator secara terpisah. Operator yang memiliki input tetapi output nol adalah penyebabnya — pelaku umum adalah JOIN, WINDOW, dan WHERE. -
Periksa apakah database downstream menyimpan data di buffer penulisannya. Kurangi ukuran batch konektor downstream agar data segera dikirim.
PentingHindari ukuran batch yang terlalu kecil. Ukuran batch 1 berarti Flink mengirim permintaan terpisah untuk setiap catatan yang diproses, yang dapat membebani database downstream saat volume data tinggi.
-
Periksa adanya deadlock di ApsaraDB RDS for MySQL. Lihat Deadlock saat menulis ke MySQL melalui konektor ApsaraDB RDS atau TDDL.
Untuk mengisolasi masalah, cetak hasil antara ke log menggunakan tabel sink print. Lihat Lihat output konektor print.
Output kosong akibat mengaktifkan MiniBatch dengan konsumsi binlog parsial dalam CDC
-
Gejala
Pekerjaan CDC mulai mengonsumsi binlog dari tengah menggunakan
latestatau offset tertentu, dengan MiniBatch diaktifkan. Tabel sink kemudian menerima data parsial atau sama sekali tidak ada output. -
Penyebab
MiniBatch menggabungkan dan saling membatalkan pesan changelog untuk primary key yang sama dalam satu batch. Saat pekerjaan dimulai dari tengah binlog, mungkin menerima
UPDATE_AFTERtanpa pasanganUPDATE_BEFOREyang sesuai (atau sebaliknya). Pesan-pesan yang berlawanan ini saling membatalkan di dalam batch dan tidak menghasilkan output, sehingga menyebabkan data downstream menjadi salah. -
Solusi
-
Konsumsi binlog dari awal. Hindari mode konsumsi parsial seperti
latestatau offset tertentu agar urutan perubahan lengkap untuk setiap catatan tetap terjaga. -
Nonaktifkan MiniBatch agar pekerjaan memproses catatan satu per satu. Opsi ini menukar sebagian throughput demi keakuratan.
-
Bagaimana cara memecahkan masalah pembacaan sumber Flink?
Jika Realtime Compute for Apache Flink tidak dapat membaca dari sumber, periksa hal-hal berikut.
Konektivitas jaringan
Secara default, Realtime Compute for Apache Flink hanya dapat mengakses layanan di wilayah dan virtual private cloud (VPC) yang sama. Untuk akses lintas jaringan:
-
Lintas-VPC: Bagaimana cara mengakses layanan lain lintas VPC?
-
Akses Internet: Bagaimana cara mengakses Internet?
Daftar putih layanan upstream
Untuk membaca dari layanan seperti Kafka dan Elasticsearch, tambahkan ruang kerja Flink Anda ke daftar putih mereka:
-
Dapatkan Blok CIDR vSwitch ruang kerja Flink Anda. Lihat Bagaimana cara mengonfigurasi daftar putih?
-
Tambahkan Blok CIDR tersebut ke daftar putih layanan upstream. Lihat bagian "Prasyarat" pada dokumen konektor terkait, misalnya Kafka.
Konsistensi bidang antara tabel Flink dan tabel fisik
Ketidaksesuaian definisi bidang merupakan penyebab umum kegagalan baca. Saat menulis DDL untuk tabel sumber Flink Anda:
-
Urutan bidang: Sesuaikan urutan bidang persis seperti pada tabel fisik.
-
Huruf besar/kecil nama bidang: Gunakan huruf besar/kecil yang identik seperti pada tabel fisik.
-
Tipe bidang: Gunakan tipe yang setara sesuai pemetaan. Periksa bagian "Pemetaan tipe data" pada dokumen konektor terkait, misalnya Simple Log Service.
Pengecualian log TaskManager
Periksa apakah log TaskManager tabel sumber berisi pesan pengecualian:
-
Di panel navigasi kiri, buka O&M > Deployment.
-
Klik nama deployment.
-
Klik tab Status, lalu klik vertex sumber di DAG.
-
Di panel kanan, klik tab SubTasks.
-
Di kolom More, klik ikon
 dan pilih Open TaskManager Log Page.
dan pilih Open TaskManager Log Page. 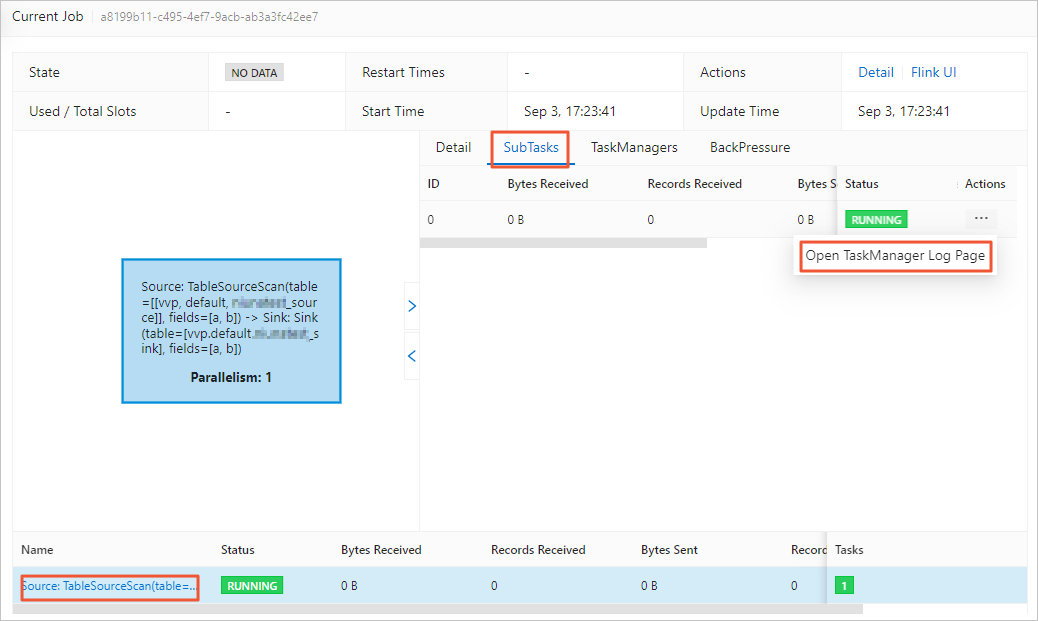
-
Di tab Logs, cari entri paling awal yang berisi "Caused by" — ini biasanya menunjukkan akar penyebab.
Bagaimana cara memecahkan masalah tidak ada output di sistem downstream?
Lakukan pemeriksaan berikut.
Konektivitas jaringan
Secara default, Realtime Compute for Apache Flink hanya dapat mengakses layanan di wilayah dan VPC yang sama. Untuk akses lintas jaringan:
-
Lintas-VPC: Bagaimana cara mengakses layanan lain lintas VPC?
-
Akses Internet: Bagaimana cara mengakses Internet?
Daftar putih sistem downstream
Untuk menulis ke layanan seperti ApsaraDB RDS for MySQL, Kafka, Elasticsearch, AnalyticDB for MySQL 3.0, Apache HBase, Redis, dan ClickHouse, tambahkan ruang kerja Flink Anda ke daftar putih mereka:
-
Dapatkan Blok CIDR vSwitch ruang kerja Flink Anda. Lihat Bagaimana cara mengonfigurasi daftar putih?
-
Tambahkan Blok CIDR tersebut ke daftar putih layanan downstream. Lihat bagian "Prasyarat" pada dokumen konektor terkait, misalnya ApsaraDB RDS for MySQL.
Konsistensi bidang antara tabel Flink dan tabel fisik
Gunakan pemeriksaan yang sama seperti dijelaskan dalam Bagaimana cara memecahkan masalah pembacaan sumber Flink?: verifikasi urutan bidang, huruf besar/kecil nama bidang, dan pemetaan tipe bidang.
Data disaring oleh operator
Periksa jumlah input dan output setiap vertex di DAG pekerjaan. Jika suatu vertex seperti WHERE menunjukkan input = 5 dan output = 0, berarti operator tersebut membuang semua catatan.
Ambang batas buffer konektor sink terlalu tinggi
Saat volume input rendah, ambang batas buffer default yang tinggi dapat mencegah data dikirim ke sistem downstream — buffer tidak pernah cukup penuh untuk memicu penulisan. Kurangi opsi terkait sesuai kebutuhan:
| Opsi | Deskripsi | Layanan downstream terkait |
|---|---|---|
batchSize |
Ukuran data yang ditulis sekaligus | DataHub, Tablestore, MongoDB, ApsaraDB RDS for MySQL, AnalyticDB for MySQL V3.0, ApsaraDB for ClickHouse, TSDB for InfluxDB |
batchCount |
Jumlah maksimum catatan yang ditulis sekaligus | DataHub |
flushIntervalMs |
Interval flush untuk buffer MaxCompute Tunnel Writer | MaxCompute |
sink.buffer-flush.max-size |
Ukuran data yang dibuffer di memori sebelum ditulis ke HBase, dalam byte | ApsaraDB for HBase |
sink.buffer-flush.max-rows |
Jumlah catatan yang dibuffer di memori sebelum ditulis ke HBase | ApsaraDB for HBase |
sink.buffer-flush.interval |
Interval di mana data yang dibuffer secara berkala dikirim ke HBase | ApsaraDB for HBase |
jdbcWriteBatchSize |
Jumlah maksimum baris yang diproses oleh node sink streaming Hologres sekaligus saat menggunakan driver JDBC | Hologres |
Data tidak berurut di window berbasis event-time
Watermark mengontrol catatan mana yang diterima oleh window. Jika catatan pertama memiliki timestamp 2100 dan menetapkan watermark ke 2100, catatan berikutnya dengan timestamp di bawah 2100 (misalnya 2021) dianggap terlambat dan dibuang. Window tidak dapat ditutup hingga catatan dengan timestamp lebih dari 2100 tiba.
Untuk mendeteksi catatan tidak berurut, gunakan tabel sink print atau periksa log Log4j. Lihat Buat tabel sink print dan Konfigurasi output log. Jika catatan terlambat dikonfirmasi, saring atau konfigurasikan strategi watermark Anda untuk mengizinkan periode tenggang bagi kedatangan terlambat.
Subtask sumber tanpa input
Saat subtask sumber tidak menerima data, watermark-nya tetap pada nilai default epoch (1970-01-01T00:00:00Z), yang menjadi watermark keseluruhan operator. Hal ini mencegah window berbasis event-time pernah ditutup.
Periksa DAG pekerjaan dan pastikan semua subtask sumber menerima input. Jika ada subtask yang idle, kurangi paralelisme pekerjaan agar sesuai dengan jumlah shard tabel upstream sehingga setiap subtask mendapat data.
Partisi Kafka kosong
Partisi Kafka kosong dapat menghentikan generasi watermark. Lihat Mengapa window berbasis event time tidak menghasilkan output dari tabel sumber Kafka?
Bagaimana cara memecahkan masalah kehilangan data?
Penurunan volume data biasanya berasal dari klausa WHERE, JOIN, atau operasi berbasis window. Untuk kehilangan yang tidak dapat dijelaskan, periksa hal-hal berikut.
Kebijakan cache tabel dimensi
Kebijakan cache yang salah dapat menyebabkan kegagalan lookup join yang diam-diam membuang catatan. Konfigurasikan kebijakan cache yang sesuai menggunakan opsi terkait cache dalam dokumen konektor, misalnya bagian "Khusus untuk tabel dimensi (seperti parameter Cache)" di ApsaraDB for HBase.
Penggunaan fungsi
Penggunaan fungsi seperti to_timestamp_tz dan date_format yang tidak tepat dapat menyebabkan kegagalan konversi data yang diam-diam membuang catatan. Verifikasi perilaku fungsi menggunakan tabel sink print atau log Log4j. Lihat Print dan Konfigurasi output log.
Data tidak berurut
Event terlambat dibuang ketika timestamp-nya berada di luar rentang yang diterima oleh window saat ini. Misalnya, event dengan timestamp 11s yang masuk ke window 15–20s dibuang karena watermark-nya 11 — di bawah batas bawah window.
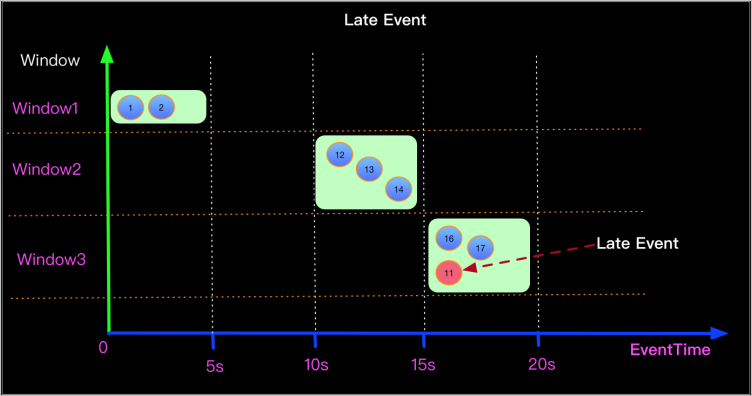
Kehilangan akibat penyebab ini biasanya terkonsentrasi di satu window. Gunakan tabel sink print atau Log4j untuk mengonfirmasi keberadaan data tidak berurut.
Untuk meminimalkan kehilangan akibat ketidakterurutan, tetapkan strategi generasi watermark dengan periode tenggang (misalnya, Watermark = Event time - 5s). Sejajarkan window ke batas hari, jam, atau menit yang tepat — ini membuat perilaku window dapat diprediksi dan mengurangi pembuangan kasus pinggiran saat dikombinasikan dengan periode tenggang yang sesuai.
Mengapa saya mendapatkan hasil yang tidak akurat saat menggunakan ROW_NUMBER untuk menghapus duplikat data yang diingest dari Hologres dalam mode CDC?
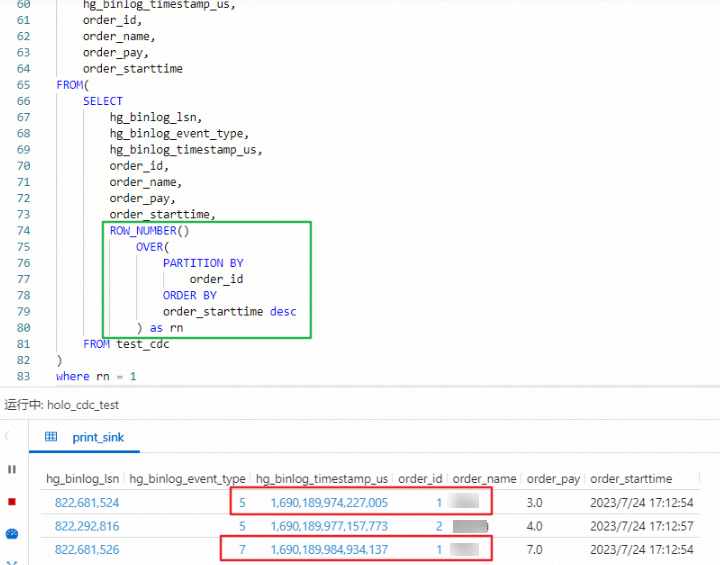
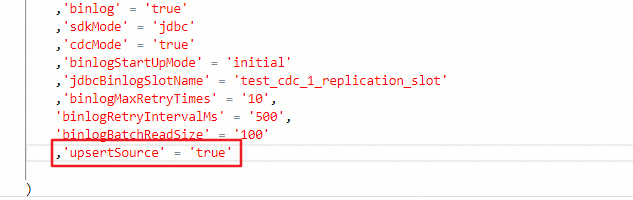
Sistem downstream menggunakan operator retraction (misalnya, ROW_NUMBER OVER WINDOW untuk deduplikasi), tetapi sumber Hologres tidak dikonfigurasi untuk mengeluarkan data dalam mode upsert. Tanpa mode upsert, sumber hanya mengeluarkan event insert-only yang tidak dapat diproses dengan benar oleh operator retraction.
Tambahkan 'upsertSource' = 'true' ke klausa WITH pada pernyataan DDL tabel sumber.
Bagaimana cara memecahkan masalah hasil yang tidak akurat?
-
Aktifkan profiling operator untuk memeriksa hasil antara tanpa mengubah logika pekerjaan.
-
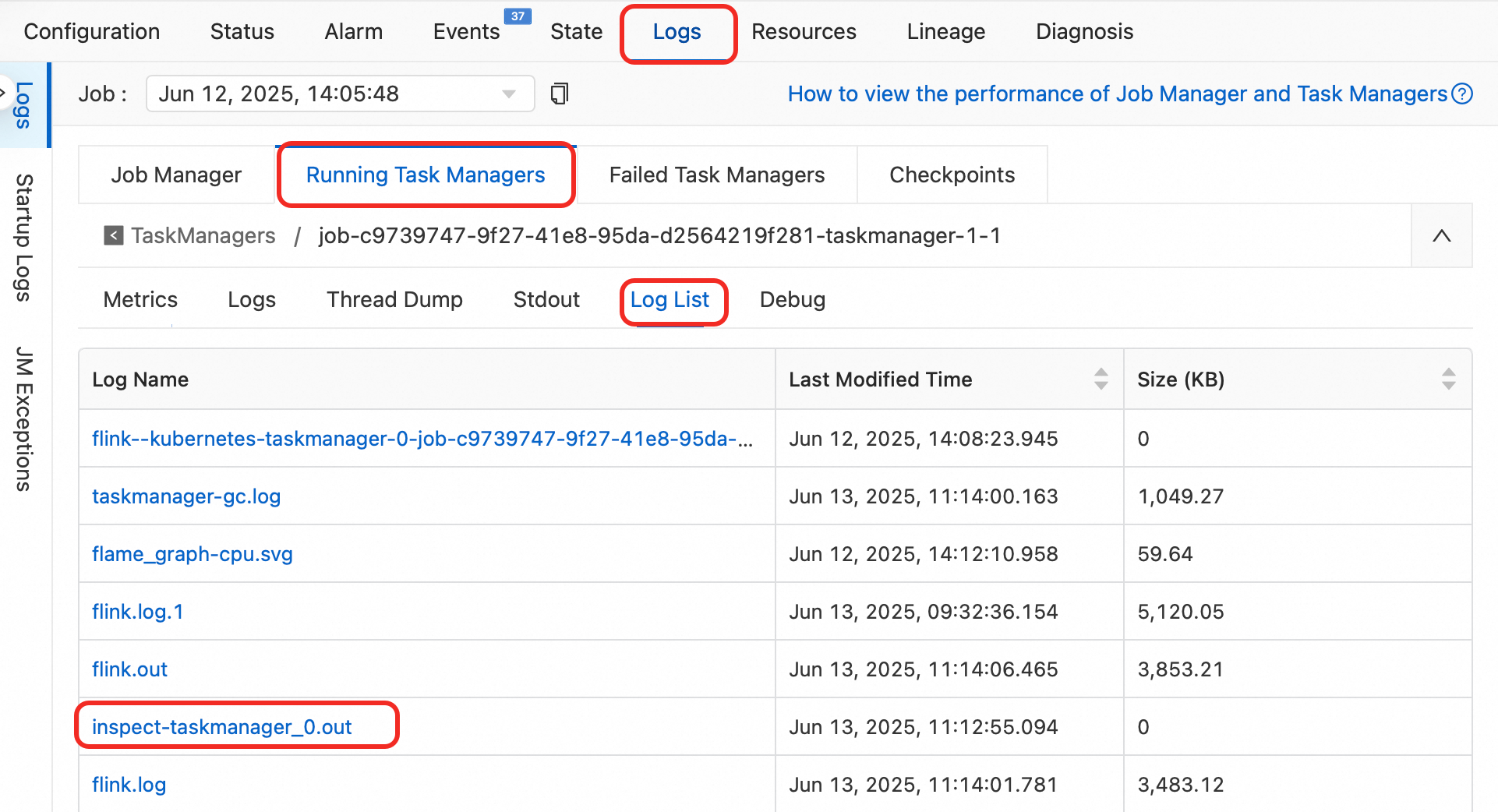
Analisis log waktu proses:
-
Klik nama deployment, lalu klik tab Status.
-
Di DAG, salin nama operator yang menghasilkan hasil salah.
-
Di daftar log, klik
inspect-taskmanager_0.outdi bawah Log Name dan cari nama operator tersebut.
-
-
Setelah mengidentifikasi akar penyebab, revisi logika operator, restart pekerjaan, dan verifikasi akurasi data.
Bagaimana cara memperbaiki error "doesn't support consuming update and delete changes which is produced by node TableSourceScan"?
Pesan error tersebut tampak seperti:
Table sink 'vvp.default.***' doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[vvp, default, ***]], fields=[id,b, content])
at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:286)
at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211)
at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:741)
at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522)
at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172)
at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331)
at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820)
at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37)
at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622)
at java.lang.Thread.run(Thread.java:834)Tabel sink berada dalam mode append-only dan tidak dapat mengonsumsi event update atau delete dari sumber. Ganti dengan sink yang mendukung upsert, seperti Upsert Kafka.
Bagaimana cara memperbaiki penimpaan atau penghapusan data yang tidak diharapkan saat menggunakan konektor Lindorm?
Secara default, konektor Lindorm menggunakan operator upsert materialize (default: AUTO) untuk mengelola urutan penulisan. Operator ini menghasilkan DELETE diikuti INSERT untuk primary key yang sama. Dua karakteristik Lindorm membuat ini bermasalah:
-
Presisi timestamp milidetik: Lindorm memberi versi data menggunakan timestamp milidetik. Beberapa catatan dengan primary key yang sama yang ditulis dalam satu milidetik yang sama mungkin tiba tidak berurut, menyebabkan konflik versi.
-
Tidak mendukung DELETE asli: Lindorm hanya mendukung semantik UPSERT — penghapusan bersifat ireversibel. Oleh karena itu, logika pemeliharaan urutan
upsert materializetidak efektif dan dapat menyebabkan anomali data akibat urutan DELETE + INSERT.
Saat penulisan konkuren terjadi dalam milidetik yang sama, operasi DELETE dan INSERT yang dihasilkan dapat menghasilkan data salah atau kehilangan data diam-diam.
Solusi: Nonaktifkan secara eksplisit operator upsert materialize dengan menambahkan konfigurasi berikut ke konfigurasi parameter runtime pekerjaan atau kode SQL Anda:
SET 'table.exec.sink.upsert-materialize' = 'NONE';Pengaturan ini berlaku untuk pekerjaan apa pun yang menulis ke Lindorm melalui Flink.
Setelah menonaktifkan operator ini, hanya konsistensi akhir yang dijamin. Pastikan konsistensi akhir dapat diterima untuk kasus penggunaan Anda sebelum menerapkan perubahan ini.