Elasticsearch Machine Learning adalah alat yang digunakan untuk mendeteksi anomali dan memprediksi pola dalam data di Elasticsearch menggunakan teknologi pembelajaran mesin. Alat ini secara otomatis mengidentifikasi pola serta anomali dalam data, menghasilkan fitur baru, dan memberikan hasil agregasi untuk mendukung analisis data. Dengan Elasticsearch Machine Learning, nilai dan ketersediaan data dapat ditingkatkan, menyediakan solusi analitik yang lebih cerdas dan efisien. Topik ini menjelaskan cara melakukan pembelajaran mesin tanpa pengawasan dan dengan pengawasan.
Informasi latar belakang
Elasticsearch Machine Learning mendukung dua mode pembelajaran: tanpa pengawasan dan dengan pengawasan.
Pembelajaran mesin tanpa pengawasan digunakan untuk mendeteksi anomali dalam skenario seperti deteksi berbasis metrik tunggal atau populasi. Mode ini tidak memerlukan pelatihan terlebih dahulu karena algoritma pembelajaran mesin secara otomatis mendeteksi pola anomali dalam data.
Pembelajaran mesin dengan pengawasan cocok untuk skenario seperti regresi dan klasifikasi, serta menyelesaikan masalah kompleks menggunakan algoritma regresi dan klasifikasi. Mode ini memerlukan pelatihan menggunakan data tertentu sebelum digunakan untuk mengklasifikasikan data baru dan membuat prediksi.
Kategori skenario | Skenario | Mode pembelajaran mesin | Deskripsi |
Deteksi anomali | Deteksi berbasis metrik tunggal | Tanpa pengawasan | Dalam skenario ini, anomali dideteksi hanya dalam satu deret waktu, dan analisis data dilakukan hanya pada satu bidang indeks. |
Deteksi berbasis multi-metrik | Tanpa pengawasan | Dalam skenario ini, anomali dideteksi berdasarkan satu atau lebih metrik, dan metrik mungkin dibagi untuk analisis berdasarkan kebutuhan bisnis. Analisis data dilakukan pada beberapa bidang indeks. | |
Populasi | Tanpa pengawasan | Perilaku aktual dibandingkan dengan perilaku dalam populasi untuk mendeteksi perilaku anomali. Populasi adalah kumpulan individu, hal, atau fenomena yang mungkin dipelajari dalam bidang tertentu. | |
Penggunaan lanjutan tugas pembelajaran mesin | Tanpa pengawasan | Opsi dan pengaturan tambahan disediakan, yang memungkinkan Anda menyesuaikan tugas pembelajaran mesin Anda untuk skenario dan jenis data yang berbeda serta mengoptimalkan tugas untuk skenario lanjutan. | |
Kategorisasi | Tanpa pengawasan | Dalam skenario ini, pembelajaran mesin tanpa pengawasan dapat digunakan untuk mengidentifikasi dan menganalisis fitur dan pola dalam pesan log, mengkategorikan pesan log, dan mendeteksi anomali dalam pesan log. | |
Analitik data frame | Deteksi pencilan | Tanpa pengawasan | Algoritma pengelompokan dan deteksi anomali digunakan untuk melatih tugas. Tugas-tugas ini dapat digunakan untuk dengan cepat mengidentifikasi perilaku anomali atau anomali yang terjadi dalam data. |
Regresi | Dengan pengawasan | Prediksi regresi dilakukan pada nilai data dalam dataset. | |
Klasifikasi | Dengan pengawasan | Prediksi klasifikasi dilakukan pada titik data dalam dataset untuk menentukan kategori dari titik data tersebut. |
Persiapan
Buat kluster Elasticsearch Alibaba Cloud. Dalam contoh ini, kluster Elasticsearch V8.5 dibuat. Untuk informasi lebih lanjut, lihat Buat Kluster Elasticsearch Alibaba Cloud.
CatatanMetode penggunaan teknologi pembelajaran mesin dalam versi kluster Elasticsearch yang berbeda mungkin bervariasi. Untuk informasi lebih lanjut, lihat Apa itu Elastic Machine Learning?
Masuk ke konsol Kibana kluster Elasticsearch. Untuk informasi lebih lanjut, lihat Masuk ke Konsol Kibana.
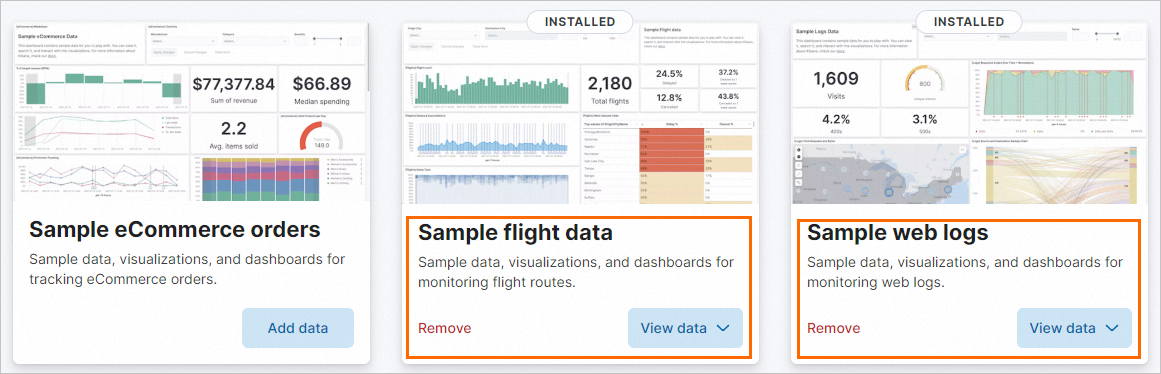
Tambahkan data sampel.
Di halaman utama konsol Kibana, klik Try sample data di bagian Get started by adding integrations.
Di tab Sample data, klik Other sample data sets.
Secara terpisah, klik Add data di kartu Sample flight data dan Sample web logs.
Jika Add data berubah menjadi View data, dataset telah ditambahkan. Setelah dataset ditambahkan, Kibana secara otomatis membuat indeks kibana_sample_data_flights dan indeks kibana_sample_data_logs.
Buat tugas pembelajaran mesin
Bagian ini menjelaskan praktik pembelajaran mesin tanpa pengawasan dan dengan pengawasan.
Buat tugas pembelajaran mesin berdasarkan metrik tunggal
Dalam contoh ini, tugas pembelajaran mesin tanpa pengawasan dibuat berdasarkan metrik tunggal untuk menganalisis data sampel dalam dataset Sample web logs yang disediakan oleh Kibana. Dataset ini menyediakan data simulasi akses ke server web. Anda dapat menggunakan tugas ini untuk menganalisis perilaku akses pengguna, mengoptimalkan kinerja situs web, dan mendeteksi perilaku akses anomali.
Kode berikut menunjukkan catatan data dalam dataset Sample web logs:
{
"_index": "kibana_sample_data_logs",
"_type": "_doc",
"_id": "n6GHI4gBmNQSVxOwNnPn",
"_version": 1,
"_score": null,
"_source": {
"agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24",
"bytes": 847,
"clientip": "122.62.233.59",
"extension": "",
"geo": {
"srcdest": "CN:CO",
"src": "CN",
"dest": "CO",
"coordinates": {
"lat": 31.24905556,
"lon": -82.39530556
}
},
"host": "www.elastic.co",
"index": "kibana_sample_data_logs",
"ip": "122.62.233.59",
"machine": {
"ram": 4294967296,
"os": "win xp"
},
"memory": null,
"message": "122.62.233.59 - - [2018-08-21T02:34:54.901Z] \"GET /logging HTTP/1.1\" 200 847 \"-\" \"Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24\"",
"phpmemory": null,
"referer": "http://twitter.com/success/paul-w-richards",
"request": "/logging",
"response": 200,
"tags": [
"success",
"info"
],
"timestamp": "2023-06-06T02:34:54.901Z",
"url": "https://www.elastic.co/solutions/logging",
"utc_time": "2023-06-06T02:34:54.901Z",
"event": {
"dataset": "sample_web_logs"
}
},
"fields": {
"@timestamp": [
"2023-06-06T02:34:54.901Z"
],
"utc_time": [
"2023-06-06T02:34:54.901Z"
],
"hour_of_day": [
2
],
"timestamp": [
"2023-06-06T02:34:54.901Z"
]
},
"sort": [
1686018894901
]
}Anda dapat menggunakan Transforms untuk mengagregasi data input menjadi statistik atau tingkat metrik yang lebih tinggi dan menyimpan hasil agregasi dalam indeks baru. Ini membantu meningkatkan kinerja kueri, mengurangi waktu respons, dan memberikan data dasar untuk analisis dan pembelajaran mesin selanjutnya.
Klik ikon
 di sudut kiri atas konsol Kibana. Di panel navigasi sisi kiri, pilih Analytics > Machine Learning.
di sudut kiri atas konsol Kibana. Di panel navigasi sisi kiri, pilih Analytics > Machine Learning.Di panel navigasi sisi kiri halaman yang muncul, pilih .
Di halaman Anomaly Detection Jobs, klik Create job.
Pilih indeks kibana_sample_data_logs.
Di bagian Use a wizard halaman Create a job from the data view Kibana Sample Data Logs, klik Single metric untuk membuat tugas metrik tunggal.
Konfigurasikan tugas metrik tunggal.
Di langkah Rentang waktu, klik Use full data, lalu klik Next.
CatatanDataset sampel hanya menyediakan sejumlah kecil data. Dalam contoh ini, semua data dalam indeks kibana_sample_data_logs digunakan.
Di langkah Pilih bidang, pilih Count(Event rate) dari daftar drop-down, konfigurasikan parameter Rentang bucket dan Data jarang, lalu klik Next.
CatatanHitung(Laju event) adalah metrik dalam tampilan metrik tunggal. Nilai metrik ini mencerminkan jumlah kali server merespons permintaan dalam setiap detik. Metrik ini dapat digunakan sebagai tujuan deteksi anomali.
Rentang bucket: menentukan interval untuk analisis deret waktu. Parameter ini digunakan untuk membagi data deret waktu menjadi bagian-bagian berbeda untuk analisis dan prediksi selanjutnya. Anda dapat mengonfigurasi parameter ini berdasarkan kebutuhan bisnis Anda.
Data jarang: menentukan apakah akan mempertimbangkan data yang tidak memiliki nilai sebagai pengecualian. Dalam pembelajaran mesin, data jarang mengacu pada data yang tidak memiliki nilai atau data yang nilainya hilang.
Di langkah Detail tugas, masukkan ID di bidang Job ID dan deskripsi di bidang Job description. Lalu, klik Next.
Di langkah Validasi, jika validasi pada rentang waktu dan batas memori tugas berhasil, klik Next.
Di langkah Ringkasan, klik Create job di bagian bawah halaman.
Elasticsearch menampilkan data berdasarkan deret waktu, menganalisis dan mempelajari data, membuat tugas berdasarkan data, dan mengevaluasi data selanjutnya.
CatatanSaat Anda membuat tugas, diperlukan waktu tertentu untuk melakukan validasi. Waktu aktual yang dikonsumsi bervariasi berdasarkan ukuran data dalam indeks terkait.
Setelah tugas dibuat, klik View results di pojok kiri bawah halaman untuk melihat hasilnya.
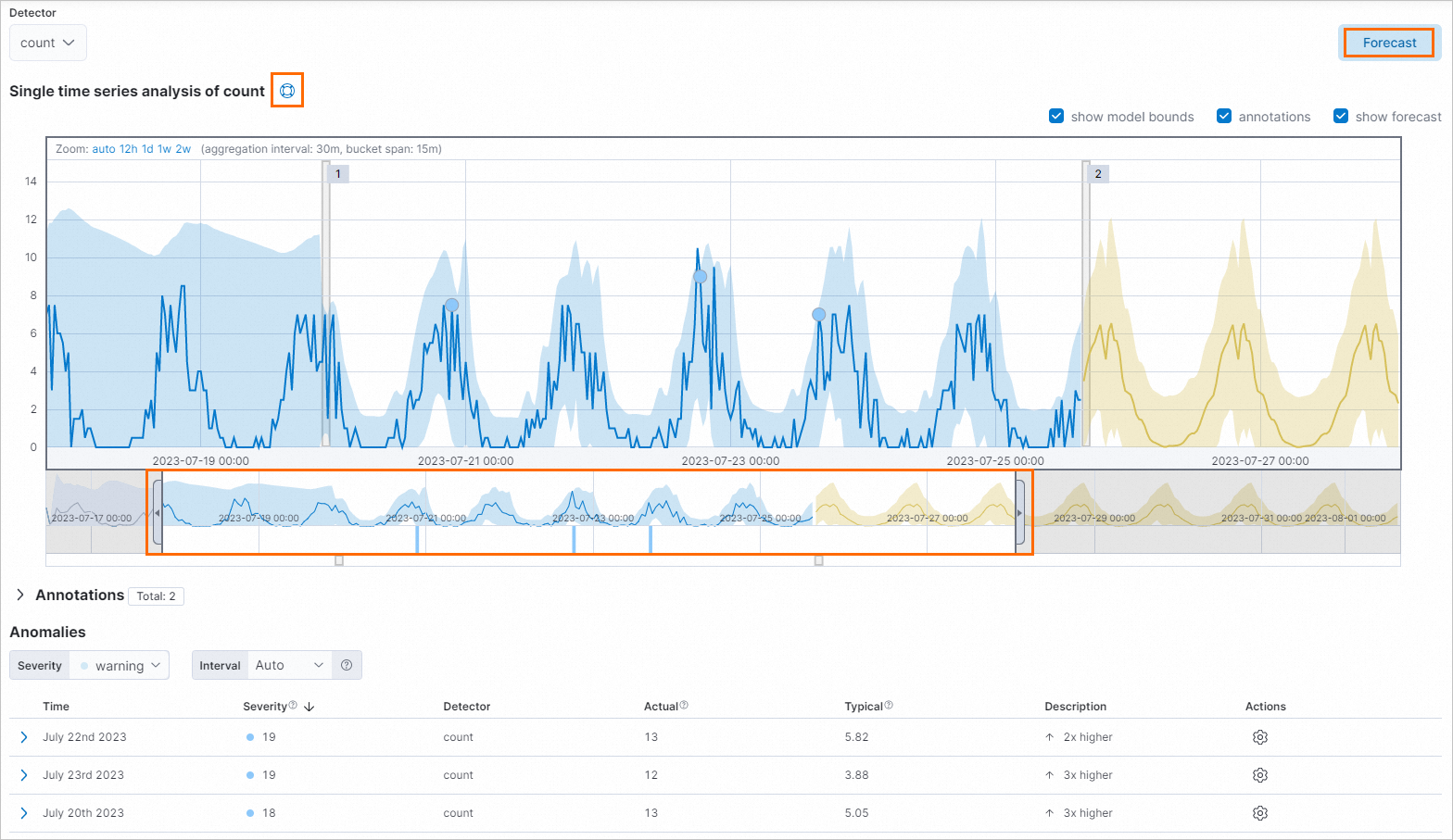
Di halaman Single Metric Viewer, klik ikon
 di sebelah Single time series analysis of count untuk melihat deskripsi analisis deret waktu tunggal.
di sebelah Single time series analysis of count untuk melihat deskripsi analisis deret waktu tunggal.Geser tepi kiri atau kanan garis waktu atau geser garis waktu untuk memilih rentang waktu di mana Anda ingin melakukan deteksi anomali.
Klik Forecast di halaman Single Metric Viewer untuk melakukan prediksi pada data selanjutnya.
Buat tugas pembelajaran mesin inferensi
Latih tugas prediksi penundaan penerbangan
Dalam contoh ini, tugas pembelajaran mesin dengan pengawasan untuk prediksi penundaan penerbangan dilatih menggunakan algoritma regresi berdasarkan data historis tertentu dalam dataset sampel yang disediakan oleh Kibana. Dataset sampel bernama Sample flight data dan menyediakan data penerbangan simulasi. Tugas ini dapat memberikan informasi referensi penting untuk maskapai dan penumpang serta membantu penumpang lebih baik menjadwalkan perjalanan dan penerbangan.
Kode berikut menunjukkan catatan data dalam dataset Sample flight data:
{
"_index": "kibana_sample_data_flights",
"_type": "_doc",
"_id": "7b0aeogBmNQSVxOwslB_",
"_version": 1,
"_score": null,
"_source": {
"FlightNum": "QYX9S3I",
"DestCountry": "CH",
"OriginWeather": "Berawan",
"OriginCityName": "Chicago",
"AvgTicketPrice": 824.8516378170061,
"DistanceMiles": 4442.909325899777,
"FlightDelay": false,
"DestWeather": "Petir & Guntur",
"Dest": "Bandara Zurich",
"FlightDelayType": "Tidak Ada Penundaan",
"OriginCountry": "US",
"dayOfWeek": 4,
"DistanceKilometers": 7150.1694661808515,
"timestamp": "2023-06-02T07:28:15",
"DestLocation": {
"lat": "47.464699",
"lon": "8.54917"
},
"DestAirportID": "ZRH",
"Carrier": "Logstash Airways",
"Cancelled": false,
"FlightTimeMin": 420.59820389299125,
"Origin": "Bandara Internasional Chicago O'Hare",
"OriginLocation": {
"lat": "41.97859955",
"lon": "-87.90480042"
},
"DestRegion": "CH-ZH",
"OriginAirportID": "ORD",
"OriginRegion": "US-IL",
"DestCityName": "Zurich",
"FlightTimeHour": 7.009970064883188,
"FlightDelayMin": 0
}
}Klik ikon
 di sudut kiri atas konsol Kibana. Di panel navigasi sisi kiri, pilih Analytics > Machine Learning.
di sudut kiri atas konsol Kibana. Di panel navigasi sisi kiri, pilih Analytics > Machine Learning.Di panel navigasi sisi kiri halaman yang muncul, pilih .
Di halaman Data Frame Analytics Jobs, klik Create job.
Di halaman New analytics job / Choose a source data view, pilih indeks kibana_sample_data_logs.
Di langkah Configuration halaman Create job, konfigurasikan informasi dasar untuk tugas.
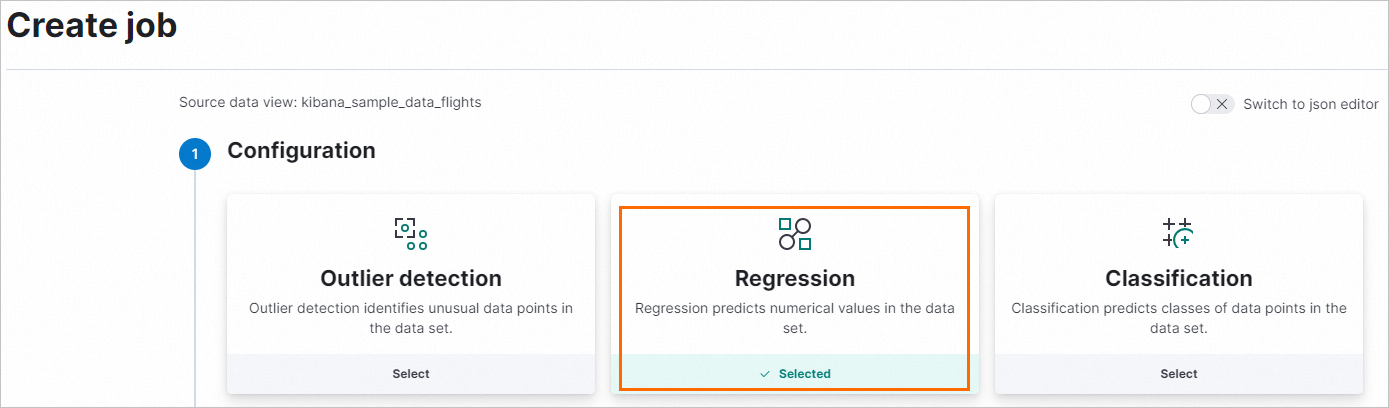
Pilih Regression.
Pilih FlightDelayMin dari daftar drop-down Variabel dependen. Variabel dependen adalah variabel di mana prediksi perlu dilakukan.
Di bagian bidang yang disertakan, hapus Cancelled, FlightDelay, dan FlightDelayType di kolom Nama bidang.
Bidang Cancelled, FlightDelay, dan FlightDelayType tidak berguna untuk prediksi penundaan penerbangan. Untuk memastikan bahwa tugas tidak terpengaruh oleh faktor yang tidak perlu dan meningkatkan akurasi prediksi, kami sarankan Anda mengecualikan bidang-bidang ini.
Di bagian Persentase pelatihan, geser tombol untuk mengubah persentase data yang digunakan untuk pelatihan.
Anda dapat mengubah persentase berdasarkan kebutuhan bisnis Anda. Dalam contoh ini, persentase diatur ke 90%.
CatatanJika sejumlah besar data digunakan untuk pelatihan, Anda perlu memperhatikan waktu yang diperlukan untuk melatih tugas. Semakin banyak data memerlukan waktu pelatihan yang lebih lama. Jika Anda memiliki sejumlah besar data, kami sarankan Anda menentukan persentase kecil, seperti 50% atau kurang. Lalu, Anda dapat mengubah persentase berdasarkan kebutuhan bisnis Anda untuk mendapatkan akurasi yang sesuai.
Klik Continue. Konfigurasikan pengaturan di langkah Additional options.
Atur Feature importance values ke 5. Dengan cara ini, lima fitur teratas yang paling signifikan memengaruhi hasil prediksi ditentukan. Ini membantu Anda mengidentifikasi fitur mana yang paling berdampak pada hasil prediksi, dan membantu Anda memilih fitur yang paling sesuai dan mengoptimalkan tugas.
Atur Prediction field name ke FlightDelayMin_prediction. Parameter ini menentukan nama variabel tempat Anda ingin melakukan prediksi.
Nonaktifkan Use estimated model memory limit dan atur Model memory limit ke 500 MB. Parameter Batas memori model menentukan batas atas untuk ukuran memori yang dapat digunakan oleh tugas pembelajaran mesin. Jika ukuran data dataset Anda besar dan tugas pembelajaran mesin Anda kompleks, sejumlah besar memori mungkin dikonsumsi. Jika ukuran memori yang digunakan melebihi batas atas, pelatihan tugas pembelajaran mesin mungkin gagal, atau kinerja tugas menurun. Anda harus menentukan batas atas yang sesuai berdasarkan ukuran data dataset Anda dan kompleksitas tugas pembelajaran mesin Anda.
Atur Maximum number of threads ke 1. Parameter ini menentukan jumlah maksimum thread yang dapat digunakan untuk melatih tugas pembelajaran mesin. Jika Anda menentukan sejumlah besar thread, memori mungkin tidak cukup, atau sistem mungkin berhenti merespons.
Klik Continue, lalu konfigurasikan parameter pada langkah Detail Pekerjaan dengan mengatur ID Pekerjaan menjadi flightdelaymin_job.
Klik Continue. Sistem memvalidasi tugas.
Jika validasi berhasil, klik Continue.
Di langkah Create, klik Create.
Sistem memerlukan waktu tertentu untuk menghasilkan tugas. Waktu aktual yang dikonsumsi ditentukan oleh jumlah data yang digunakan untuk pelatihan.
Setelah tugas dibuat, klik View Results untuk melihat hasil running tugas.
Di bagian Model evaluation halaman yang muncul, lihat metrik yang menunjukkan keandalan tugas.
Kesalahan generalisasi: mengukur kinerja tugas pada data baru, yang mencerminkan kemampuan generalisasi tugas. Kesalahan generalisasi yang lebih kecil menunjukkan kemampuan generalisasi yang lebih baik. Tugas dengan kemampuan generalisasi yang lebih baik dapat melakukan prediksi yang lebih akurat pada data baru.
Kesalahan pelatihan: mencerminkan kinerja tugas pada pelatihan berbasis dataset dan kesalahan yang dihasilkan selama proses pembelajaran tugas. Nilai yang lebih kecil menunjukkan kinerja tugas yang lebih baik pada pelatihan berbasis dataset.
Deskripsi metrik evaluasi:
Mean squared error: metrik penting yang mengukur kinerja tugas regresi. Nilai yang lebih kecil menunjukkan hasil prediksi yang lebih akurat. Nilai ini diperoleh dengan menghitung rata-rata kuadrat dariperbedaan antara nilai aktual dan nilai prediksi yang diberikan oleh tugas regresi.
R squared: metrik penting yang mengukur kinerja tugas regresi. Nilai yang lebih dekat dengan 1 menunjukkan bahwa tugas lebih sesuai dengan nilai aktual. Nilai lebih dari 0,8 menunjukkan bahwa tugas memiliki tingkat kesesuaian yang tinggi.
Mean squared logarithmic error: Nilai yang lebih kecil menunjukkan efek prediksi yang lebih baik. Nilai ini diperoleh dengan menghitung nilai rata-rata dari jumlah kesalahan kuadrat setelah logaritma nilai prediksi dan nilai aktual dikembalikan.
CatatanSaat Anda membandingkan beberapa tugas regresi, Anda harus memperhatikan nilai metrik Mean squared error dan nilai metrik R squared. Ini dapat membantu Anda menentukan tugas optimal atau tugas yang cocok untuk dataset tertentu.
Dalam kebanyakan kasus, nilai metrik Mean squared error tidak mungkin menjadi 0, dan nilai metrik R squared tidak mungkin menjadi 1. Alasannya adalah hasil prediksi tugas dipengaruhi oleh banyak faktor. Anda mungkin tidak dapat mempertimbangkan semua faktor ini dan menghilangkan kesalahan.
Nilai NaN dari metrik Mean squared logarithmic error menunjukkan bahwa hasil prediksi atau nilai aktual adalah angka non-positif atau 0.
Untuk informasi lebih lanjut, lihat Evaluasi Analitik Data Frame.
Gunakan tugas prediksi penundaan penerbangan
Anda dapat menggunakan tugas prediksi penundaan penerbangan berdasarkan prosesor inferensi yang disediakan oleh Kibana.
Klik ikon
di sudut kiri atas konsol Kibana. Di panel navigasi sisi kiri, pilih Management > Dev Tools.Di tab Console, jalankan perintah berikut untuk melihat dan mencatat nilai parameter model_id:
GET _ml/inference/flightdelaymin_job*?human=truePerintah ini digunakan untuk menanyakan semua hasil inferensi dan analisis tugas yang ID-nya adalah flightdelaymin_job dan mengembalikan hasil dalam format yang mudah dibaca manusia. flightdelaymin_job dalam perintah menentukan ID tugas yang dibuat untuk melatih tugas regresi dan inferensi.
Buat pipeline berdasarkan tugas regresi dan inferensi serta prosesor inferensi.
CatatanAnda harus mengganti nilai parameter model_id dalam perintah berikut dengan nilai yang Anda peroleh pada langkah sebelumnya.
PUT _ingest/pipeline/flight_flightDelayMin_predict { "description": "Prediksi jumlah menit penundaan untuk setiap penerbangan", "processors": [ { "inference": { "model_id": "flightDelayMin_job-168609891****", "inference_config": { "regression": {} }, "field_map": {}, "tag": "flightDelayMin_prediction" } } ] }Lakukan analisis data dan prediksi pada variabel FlightDelayMin berdasarkan data dalam indeks kibana_sample_data_flights.
POST _ingest/pipeline/flight_flightDelayMin_predict/_simulate { "docs": [ { "_source": { "FlightNum": "EDGSV3T", "DestCountry": "CN", "OriginWeather": "Angin Merusak", "OriginCityName": "Durban", "AvgTicketPrice": 1065.7037805199147, "DistanceMiles": 7273.460817641552, "FlightDelay": true, "DestWeather": "Hujan", "Dest": "Bandara Internasional Pudong Shanghai", "FlightDelayType": "Penundaan Operator", "OriginCountry": "ZA", "dayOfWeek": 5, "DistanceKilometers": 11705.500526106527, "timestamp": "2023-06-03T09:34:00", "DestLocation": { "lat": "31.14340019", "lon": "121.8050003" }, "DestAirportID": "PVG", "Carrier": "Maskapai Kibana", "Cancelled": false, "FlightTimeMin": 881.1071804361806, "Origin": "Bandara Internasional King Shaka", "OriginLocation": { "lat": "-29.61444444", "lon": "31.11972222" }, "DestRegion": "SE-BD", "OriginAirportID": "DUR", "OriginRegion": "SE-BD", "DestCityName": "Shanghai", "FlightTimeHour": 14.685119673936343, "FlightDelayMin": 45 } } ] }Gambar berikut menunjukkan hasilnya.
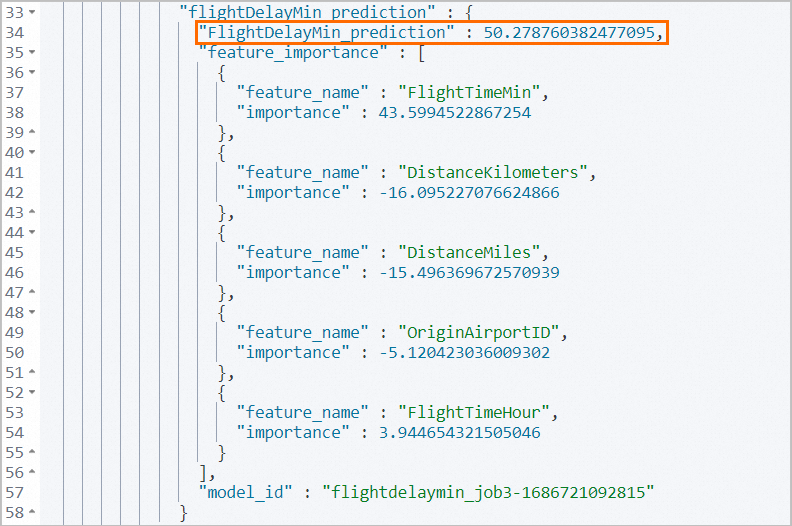
Nilai aktual variabel FlightDelayMin adalah 45 menit. Nilai variabel FlightDelayMin_prediction yang diperoleh dalam prediksi adalah 50,28 menit, yang mendekati nilai aktual.
Parameter feature_importance mengembalikan lima faktor teratas yang paling signifikan memengaruhi hasil prediksi penundaan penerbangan: FlightTimeMin, DistanceKilometers, DistanceMiles, OriginAirportID, dan FlightTimeHour. Anda dapat mengubah nilai faktor-faktor ini untuk mendapatkan hasil prediksi yang berbeda. Dengan cara ini, tugas dapat memprediksi waktu penundaan setiap penerbangan dengan cara yang lebih akurat.