Topik ini menjawab beberapa pertanyaan umum terkait Elasticsearch open source.
Ikhtisar
Bagaimana cara mengonfigurasi ukuran thread pool untuk indeks?
Berapa lama waktu yang diperlukan untuk membuat snapshot yang akan disimpan di OSS?
Bagaimana cara mengubah zona waktu untuk visualisasi data di konsol Kibana?
Jenis data apa yang dapat di-query menggunakan term query di Elasticsearch?
Apa saja tindakan pencegahan dalam menggunakan alias di Elasticsearch?
Apa yang harus dilakukan jika pesan kesalahan too_many_buckets_exception dikembalikan selama query?
Apakah saya bisa mengubah nilai parameter script.painless.regex.enabled?
Apa yang harus dilakukan jika ingin menyimpan nilai suatu bidang?
Apa yang harus dilakukan jika ingin atau tidak ingin suatu bidang tertentu di-aggregasi?
Bagaimana cara mengonfigurasi ukuran thread pool untuk indeks?
Dalam file konfigurasi YML kluster Elasticsearch Anda, tentukan parameter thread_pool.write.queue_size untuk mengonfigurasi ukuran thread pool. Untuk informasi lebih lanjut, lihat Konfigurasikan file YML.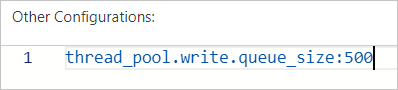
Untuk kluster Elasticsearch versi lebih awal dari 6.X, gunakan parameter thread_pool.index.queue_size untuk mengonfigurasi ukuran thread pool.
Apa yang harus saya lakukan jika terjadi OOM?
Jalankan perintah berikut untuk membersihkan cache. Kemudian, analisis penyebabnya, tingkatkan konfigurasi kluster Elasticsearch Anda, atau sesuaikan bisnis Anda. Untuk informasi lebih lanjut tentang cara meningkatkan konfigurasi kluster, lihat Tingkatkan konfigurasi kluster.
curl -u elastic:<password> -XPOST "localhost:9200/<index_name>/_cache/clear?pretty"Parameter | Deskripsi |
| Kata sandi yang digunakan untuk mengakses kluster Elasticsearch Anda. Kata sandi ditentukan saat Anda membuat kluster atau menginisialisasi Kibana. |
| Nama indeks. |
Bagaimana cara mengelola shard secara manual?
Gunakan API reroute atau Cerebro. Untuk informasi lebih lanjut, lihat Cluster reroute API dan Cerebro.
Apa kebijakan pembersihan cache untuk Elasticsearch?
Elasticsearch mendukung kebijakan pembersihan cache berikut:
Bersihkan cache semua indeks
curl localhost:9200/_cache/clear?prettyBersihkan cache indeks tertentu
curl localhost:9200/<index_name>/_cache/clear?prettyBersihkan cache beberapa indeks
curl localhost:9200/<index_name1>,<index_name2>,<index_name3>/_cache/clear?pretty
Bagaimana cara mengalihkan ulang shard indeks?
Jika beberapa shard hilang atau dialokasikan secara tidak tepat, jalankan perintah berikut untuk mengalihkan ulang shard:
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{
"commands" : [ {
"move" :
{
"index" : "test", "shard" : 0,
"from_node" : "node1", "to_node" : "node2"
}
},
{
"allocate" : {
"index" : "test", "shard" : 1, "node" : "node3"
}
}
]
}'Ketika saya menanyai sebuah indeks, pesan kesalahan "statusCode: 500" ditampilkan. Apa yang harus saya lakukan?
Kami merekomendasikan agar Anda menggunakan plug-in pihak ketiga, seperti Cerebro, untuk menanyai indeks.
Jika query berhasil, masalah tersebut disebabkan oleh nama indeks yang tidak valid. Dalam hal ini, ubah nama indeks. Nama indeks hanya boleh berisi huruf, garis bawah (_), dan angka.
Jika query gagal, masalah tersebut disebabkan oleh kesalahan pada indeks atau kluster Anda. Dalam hal ini, periksa apakah kluster Anda menyimpan indeks dan berjalan dalam keadaan normal.
Bagaimana cara mengubah nilai parameter auto_create_index?
Jalankan perintah berikut:
PUT /_cluster/settings
{
"persistent" : {
"action": {
"auto_create_index": "false"
}
}
}Nilai default parameter auto_create_index adalah false. Nilai ini menunjukkan bahwa sistem tidak secara otomatis membuat indeks. Dalam kebanyakan kasus, kami merekomendasikan agar Anda tidak mengubah nilai parameter ini. Jika tidak, indeks yang berlebihan dibuat, dan pemetaan atau pengaturan indeks tidak sesuai dengan harapan Anda.
Berapa lama waktu yang diperlukan untuk membuat snapshot yang akan disimpan di OSS?
Jika jumlah shard, penggunaan memori, penggunaan disk, dan utilisasi CPU kluster Anda normal, sekitar 30 menit diperlukan untuk membuat snapshot untuk 80 GB data indeks.
Bagaimana cara menentukan jumlah shard saat saya membuat indeks?
Anda dapat membagi total ukuran data dengan ukuran data setiap shard untuk mendapatkan jumlah shard. Kami merekomendasikan agar Anda membatasi ukuran data setiap shard hingga 30 GB. Jika ukuran data setiap shard melebihi 50 GB, kinerja query sangat terpengaruh.
Anda dapat secara tepat meningkatkan jumlah shard untuk mempercepat pembuatan indeks. Kinerja query terpengaruh baik jumlah shard kecil maupun besar.
Shard disimpan di node yang berbeda. Jika jumlah shard diatur ke nilai besar, lebih banyak file perlu dibuka, dan lebih banyak interaksi diperlukan di antara node. Ini menurunkan kinerja query.
Jika jumlah shard diatur ke nilai kecil, setiap shard menyimpan lebih banyak data. Ini juga menurunkan kinerja query.
Ketika saya menggunakan plug-in elasticsearch-repository-oss untuk memigrasikan data dari kluster Elasticsearch yang dikelola sendiri, pesan kesalahan berikut ditampilkan. Apa yang harus saya lakukan?
Pesan kesalahan: ERROR: This plugin was built with an older plugin structure. Contact the plugin author to remove the intermediate "elasticsearch" directory within the plugin zip.
Solusi: Ubah nama paket ZIP plug-in dari elasticsearch menjadi elasticsearch-repository-oss, dan salin paket ke direktori plugins.
Bagaimana cara mengubah zona waktu untuk visualisasi data di konsol Kibana?
Anda dapat mengubah zona waktu di konsol Kibana. Dalam contoh ini, kluster Elasticsearch 6.7.0 digunakan. Gambar berikut menunjukkan zona waktu yang dipilih.
Gambar berikut menunjukkan zona waktu yang dipilih.
Jenis data apa yang dapat saya lakukan query term Elasticsearch?
Query term adalah query tingkat kata yang dapat dilakukan pada data terstruktur, seperti angka, tanggal, dan kata kunci selain teks.
Ketika Anda melakukan query teks lengkap, sistem memisahkan kata-kata dalam teks. Ketika Anda melakukan query tingkat kata, sistem langsung mencari indeks terbalik yang berisi bidang terkait. Query tingkat kata umumnya dilakukan pada bidang tipe data numerik atau tanggal.
Apa saja tindakan pencegahan dalam menggunakan alias di Elasticsearch?
Jumlah total shard untuk indeks yang memiliki alias yang sama harus kurang dari 1.024.
Apa yang harus saya lakukan jika pesan kesalahan too_many_buckets_exception dikembalikan selama query?
Pesan kesalahan: "type": "too_many_buckets_exception", "reason": "Trying to create too many buckets. Must be less than or equal to: [10000] but was [10001].
Solusi: Anda dapat mengubah nilai parameter size untuk aggregasi bucket. Untuk informasi lebih lanjut, lihat Batasi jumlah bucket yang dapat dibuat dalam aggregasi. Anda juga dapat menyelesaikan masalah ini berdasarkan instruksi yang diberikan di Meningkatkan max_buckets untuk Visualisasi Tertentu.
Bagaimana cara menghapus beberapa indeks sekaligus?
Secara default, Elasticsearch tidak mengizinkan Anda menghapus beberapa indeks sekaligus. Anda dapat menjalankan perintah berikut untuk mengaktifkan penghapusan. Kemudian, gunakan wildcard untuk menghapus beberapa indeks sekaligus.
PUT /_cluster/settings
{
"persistent": {
"action.destructive_requires_name": false
}
}Apakah saya bisa mengubah nilai parameter script.painless.regex.enabled?
Dalam kebanyakan kasus, nilai default false digunakan untuk parameter script.painless.regex.enabled, dan kami merekomendasikan agar Anda tidak mengubah nilainya. Jika Anda ingin menggunakan ekspresi reguler dalam skrip Painless, Anda dapat mengatur parameter script.painless.regex.enabled ke true dalam file konfigurasi elasticsearch.yml. Ekspresi reguler mengonsumsi sejumlah besar sumber daya. Di Elasticsearch open source, nilai true tidak direkomendasikan untuk parameter script.painless.regex.enabled. Oleh karena itu, kami merekomendasikan agar Anda tidak mengatur parameter ini ke true jika tidak diperlukan.
Bagaimana cara mengubah konfigurasi pemetaan, jumlah shard utama, dan jumlah shard replika untuk indeks di kluster Elasticsearch?
Jika Anda ingin memodifikasi konfigurasi pemetaan untuk indeks yang ada, kami merekomendasikan agar Anda mengindeks ulang data.
CatatanUntuk informasi tentang tipe bidang yang didukung dalam konfigurasi pemetaan, lihat Tipe Bidang Data.
Anda tidak dapat mengubah jumlah shard utama untuk indeks yang ada. Jika jumlah shard utama tidak dapat memenuhi persyaratan bisnis Anda, Anda dapat memanggil API reindex untuk mengindeks ulang data.
CatatanUntuk mencegah penyesuaian setelah indeks dibuat, kami merekomendasikan agar Anda merencanakan jumlah shard utama dan shard replika sebelum Anda membuat indeks.
Jika Anda ingin mengubah jumlah shard replika untuk setiap shard utama dalam indeks yang ada, Anda dapat menjalankan perintah berikut:
PUT test/_settings { "number_of_replicas": 0 }
Apa yang harus saya lakukan jika saya ingin menyimpan nilai suatu bidang?
Secara default, Elasticsearch tidak menyimpan nilai untuk bidang, kecuali bidang _source. Jika Anda ingin menyimpan nilai untuk suatu bidang, Anda dapat mengatur properti store dalam konfigurasi pemetaan indeks terkait ke true untuk bidang tersebut.
Bidang _sourceberisi dokumen JSON asli dan memungkinkan Anda mencari bidang apa pun dari dokumen. Untuk mengurangi ruang disk yang digunakan, kami merekomendasikan agar Anda tidak mengaktifkan penyimpanan untuk nilai bidang.
Kode berikut memberikan contoh tentang cara menyimpan nilai bidang my_field:
PUT / my_index {
"mappings": {
"properties": {
"my_field": {
"type": "text",
"store": true
}
}
}
}Apa yang harus saya lakukan jika saya ingin atau tidak ingin suatu bidang tertentu di-aggregasi?
Apakah suatu bidang dapat di-aggregasi bergantung pada tipe data bidang dan apakah data bidang terkait (doc_values atau fielddata) ada.
Secara default, bidang tipe numerik, tanggal, atau kata kunci dapat di-aggregasi berdasarkan doc_values.
Catatandoc_values menunjukkan model penyimpanan berorientasi kolom, yang dioptimalkan untuk pengurutan, agregasi, dan operasi skrip.
Secara default, bidang tipe teks tidak dapat di-aggregasi. Jika Anda perlu mengagregasi bidang tersebut, Anda harus mengaktifkan fielddata dalam konfigurasi pemetaan.
CatatanSetelah fielddata diaktifkan, semua data teks dimuat ke dalam memori. Ini secara signifikan meningkatkan penggunaan memori.
PUT /my_index{ "mappings": { "properties": { "my_text_field": { "type": "text", "fielddata": true } } } }Jika Anda tidak ingin suatu bidang di-aggregasi, Anda dapat menggunakan salah satu metode berikut untuk mengimplementasikannya. Anda dapat memilih metode berdasarkan logika aplikasi Anda.
Atur properti enabled ke false untuk bidang tersebut.
Keluarkan bidang dari dokumen terkait.
Apa yang harus saya lakukan jika pesan kesalahan "Unknown char_filter type [stop] for **" ditampilkan ketika saya mengonfigurasi Elasticsearch?
Jika pesan kesalahan "Unknown char_filter type [stop] for ** " ditampilkan ketika Anda mengonfigurasi Elasticsearch, tipe stop ditentukan di bagian char_filter. Namun, filter tipe stop adalah token filter bukan character filter.
Solusi:
Perbaiki lokasi konfigurasi: Jika Anda ingin menggunakan filter stopword, pindahkan konfigurasi stop dari
char_filterke bagian filter konfigurasi analyzer. Filter stopword digunakan untuk menghapus stopwords yang ditentukan dari aliran token.Contoh:
"settings": { "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "standard", "filter": [ // Tentukan tipe filter dalam array filter. "lowercase", "stop" // Gunakan token filter tipe stop. ] } }, "filter": { // Definisikan konfigurasi untuk token filter tipe stop jika perlu. "stop": { "type": "stop", "stopwords": "_english_" // Definisikan stopwords berdasarkan persyaratan bisnis Anda. } } } }Periksa nama tipe filter: Periksa apakah nama tipe filter yang valid ditentukan dalam konfigurasi seperti
tokenizerdanchar_filter.Anda dapat memodifikasi konfigurasi berdasarkan persyaratan bisnis Anda untuk memastikan bahwa tipe komponen yang valid ditentukan dalam konfigurasi
char_filter,tokenizer, danfilter.