Untuk memenuhi berbagai kebutuhan skenario bisnis, StarRocks mendukung beberapa model data. Data yang disimpan di StarRocks harus diorganisasikan berdasarkan model tertentu. Topik ini menjelaskan konsep dasar, prinsip, konfigurasi sistem, dan skenario dari berbagai metode impor. Praktik terbaik serta FAQ juga tersedia dalam topik ini.
Informasi latar belakang
Fitur impor data memungkinkan Anda membersihkan dan mengonversi data mentah sesuai dengan model yang relevan, lalu mengimpor data tersebut ke StarRocks untuk keperluan kueri dan penggunaan lebih lanjut. StarRocks mendukung berbagai metode impor. Anda dapat memilih metode yang sesuai berdasarkan volume data atau frekuensi impor.
Gambar berikut menunjukkan sumber data yang berbeda beserta metode impor yang didukung oleh StarRocks. 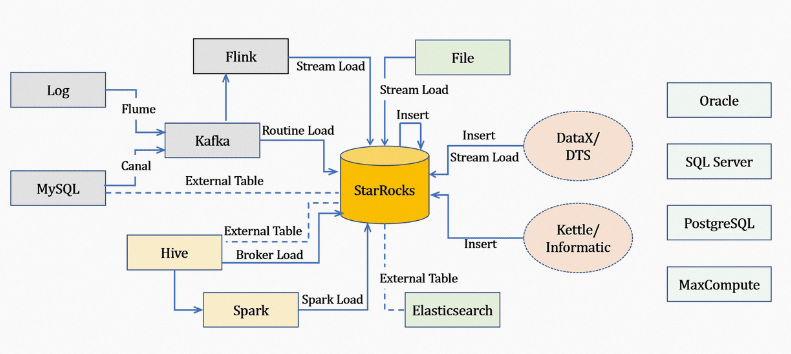
Anda dapat memilih metode impor berdasarkan sumber data yang digunakan:
Impor data offline: Jika sumber data Anda adalah Hive atau Hadoop Distributed File System (HDFS), kami merekomendasikan penggunaan metode Broker Load. Untuk sejumlah besar tabel data, Anda dapat menggunakan tabel eksternal Hive tanpa perlu migrasi data. Namun, performa tabel eksternal Hive lebih rendah dibandingkan dengan metode Broker Load.
Impor data real-time: Setelah menyinkronkan data log dan log biner database ke Kafka, gunakan metode Routine Load untuk mengimpor data ke StarRocks. Routine Load. Jika diperlukan operasi multi-tabel join dan ETL (extract, transform, load), gunakan Flink connector untuk memproses data terlebih dahulu, lalu tulis ke StarRocks menggunakan metode Stream Load.
Impor data dari program ke StarRocks: Gunakan metode Stream Load. Anda dapat merujuk pada contoh kode Java atau Python dalam dokumentasi Stream Load.
Impor file teks: Gunakan metode Stream Load.
Impor data dari MySQL: Gunakan tabel eksternal MySQL dan jalankan pernyataan
insert into new_table select * from external_tableuntuk mengimpor data.Impor data dalam StarRocks: Gunakan metode INSERT bersama dengan penjadwal eksternal untuk menerapkan pemrosesan ETL sederhana.
Gambar dan beberapa informasi dalam topik ini berasal dari Ikhtisar Pengunggahan Data dari StarRocks open source.
Catatan Penggunaan
Koneksi program sering kali digunakan untuk mengimpor data ke StarRocks. Perhatikan hal-hal berikut saat melakukan impor:
Pilih metode impor yang sesuai berdasarkan volume data, frekuensi impor, atau lokasi sumber data.
Sebagai contoh, jika data mentah disimpan di HDFS, gunakan metode Broker Load untuk mengimpor data.
Tentukan protokol untuk metode impor. Jika menggunakan Broker Load, sistem eksternal harus diizinkan untuk mengirimkan dan memantau pekerjaan impor secara berkala melalui protokol MySQL.
Tentukan mode impor data. Mode impor mencakup sinkron dan asinkron. Dalam mode asinkron, sistem eksternal harus menjalankan perintah untuk memantau status impor dan menentukan apakah impor berhasil.
Atur kebijakan pembuatan label. Kebijakan ini harus memastikan bahwa data yang diimpor dalam setiap pekerjaan unik dan statis.
Pastikan pengiriman tepat sekali. Sistem eksternal menjamin pengiriman setidaknya sekali, sedangkan mekanisme label StarRocks memastikan pengiriman paling banyak sekali. Dengan cara ini, pengiriman tepat sekali dapat dicapai untuk keseluruhan proses impor.
Istilah
Istilah | Deskripsi |
pekerjaan impor | Pekerjaan impor digunakan untuk membaca data dari sumber data yang ditentukan, membersihkan dan mengonversi data, dan kemudian mengimpor data ke StarRocks. Setelah data diimpor, data tersebut dapat di-query. |
Label | Label digunakan untuk mengidentifikasi pekerjaan impor. Setiap pekerjaan impor memiliki label. Anda dapat menentukan label untuk pekerjaan impor atau menggunakan label yang dihasilkan sistem. Label bersifat unik dalam sebuah database. Setiap label hanya dapat digunakan untuk satu pekerjaan impor. Setelah pekerjaan impor selesai, Anda tidak dapat menggunakan kembali label dari pekerjaan impor ini untuk mengirimkan pekerjaan impor lainnya. Hanya label dari pekerjaan impor yang gagal yang dapat digunakan kembali. Mekanisme ini memastikan bahwa data yang terkait dengan label tertentu hanya dapat diimpor sekali. Dengan cara ini, semantik paling banyak sekali diimplementasikan. |
atomicitas | Semua metode impor yang disediakan oleh StarRocks memastikan atomicitas. Atomicitas menunjukkan bahwa semua data yang memenuhi syarat dalam suatu pekerjaan harus diimpor atau tidak ada data yang memenuhi syarat yang diimpor. Perhatikan bahwa data yang memenuhi syarat tidak termasuk data yang difilter karena masalah kualitas, seperti kesalahan dalam konversi tipe data. |
Protokol MySQL dan HTTP | StarRocks memungkinkan Anda untuk mengirimkan pekerjaan impor dengan menggunakan protokol MySQL dan HTTP. |
Broker Load | Metode impor yang menggunakan broker yang telah diterapkan untuk membaca data dari sumber data eksternal, seperti HDFS, dan mengimpor data ke StarRocks. Proses broker menggunakan sumber daya komputasi untuk memproses dan mengimpor data. |
FE | Node frontend (FE) adalah node metadata dan penjadwalan StarRocks. Selama proses impor data, node FE digunakan untuk menghasilkan rencana eksekusi impor dan menjadwalkan pekerjaan impor. |
BE | Node backend (BE) adalah node komputasi dan penyimpanan StarRocks. Node BE digunakan untuk melakukan operasi ETL pada data dan menyimpan data. |
Tablet | Tablet adalah shard logis dari tabel StarRocks. Tabel StarRocks dapat dibagi menjadi beberapa tablet berdasarkan aturan partisi dan bucket. Untuk informasi lebih lanjut, lihat Apache StarRocks. |
Prinsip Dasar
Gambar berikut menunjukkan alur kerja pekerjaan impor.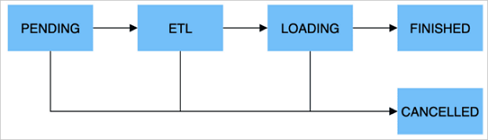
Tabel berikut menjelaskan tahapan pekerjaan impor.
Tahap | Deskripsi |
PENDING | Opsional. Pekerjaan dikirimkan dan menunggu untuk dijadwalkan oleh node FE. |
ETL | Opsional. Data diproses sebelumnya, termasuk pembersihan, partisi, pengurutan, dan agregasi. |
LOADING | Data dibersihkan, dikonversi, dan kemudian dikirim ke node BE untuk diproses. Setelah semua data diimpor, data tersebut berada dalam antrian dan menunggu untuk berlaku. Dalam hal ini, status pekerjaan tetap LOADING. |
FINISHED | Setelah data berlaku, status pekerjaan berubah menjadi FINISHED, dan data dapat di-query. FINISHED adalah status akhir dari pekerjaan impor. |
CANCELLED | Sebelum pekerjaan memasuki status FINISHED, Anda dapat membatalkan pekerjaan kapan saja. Jika terjadi kesalahan impor, StarRocks juga dapat secara otomatis membatalkan pekerjaan. CANCELLED juga merupakan status akhir dari pekerjaan impor. |
Tabel berikut menjelaskan tipe data yang didukung.
Tipe Data | Deskripsi |
Bilangan bulat | TINYINT, SMALLINT, INT, BIGINT, dan LARGEINT. Contoh: 1, 1000, dan 1234. |
Bilangan titik mengambang | FLOAT, DOUBLE, dan DECIMAL. Contoh: 1.1, 0.23, dan 0.356. |
Tanggal | DATE dan DATETIME. Contoh: 2017-10-03 dan 2017-06-13 12:34:03. |
String | CHAR dan VARCHAR. Contoh: "Saya seorang siswa" dan "a". |
Metode Impor
Untuk memenuhi berbagai persyaratan impor data, StarRocks menyediakan metode berbeda untuk mengimpor data dari sumber seperti HDFS, Kafka, dan file lokal. StarRocks mendukung impor data dalam mode sinkron dan asinkron.
Semua metode impor mendukung format data CSV. Broker Load juga mendukung format Parquet dan ORC.
Metode impor data
Metode impor | Deskripsi | Mode impor |
Broker Load | Metode ini menggunakan proses broker untuk membaca data dari sumber eksternal dan membuat pekerjaan untuk mengimpor data ke StarRocks dengan menggunakan protokol MySQL. Pekerjaan yang dikirimkan dijalankan dalam mode asinkron. Anda dapat menjalankan perintah Metode ini cocok untuk skenario berikut: Data yang akan diimpor disimpan dalam sistem yang dapat diakses oleh proses broker, seperti HDFS, dan volume data berkisar antara puluhan hingga ratusan gigabyte. | Mode asinkron |
Stream Load | Metode ini mengimpor data ke StarRocks dalam mode sinkron. Anda dapat mengirim permintaan HTTP untuk mengimpor file lokal atau aliran data ke StarRocks dan menunggu sistem mengembalikan hasil impor. Anda dapat menentukan apakah impor berhasil berdasarkan hasil yang dikembalikan. Stream Load cocok untuk mengimpor file lokal atau data dari aliran data dengan menggunakan program. Untuk informasi lebih lanjut, lihat Stream Load. | Mode sinkron |
Routine Load | Metode ini secara otomatis mengimpor data dari sumber data yang ditentukan. Anda dapat mengirimkan pekerjaan impor rutin dengan menggunakan protokol MySQL. Kemudian, thread penduduk dihasilkan untuk terus membaca data dari sumber data, seperti Kafka, dan mengimpor data ke StarRocks. Untuk informasi lebih lanjut, lihat Routine Load. | Mode asinkron |
Insert Into | Metode ini digunakan dengan cara yang mirip dengan pernyataan INSERT dalam MySQL. StarRocks memungkinkan Anda menjalankan pernyataan | Mode sinkron |
Mode impor
Jika Anda mengimpor data menggunakan program eksternal, pilih metode impor sebelum menentukan logika impor.
Mode Sinkron
Dalam mode sinkron, setelah sistem eksternal membuat pekerjaan impor, StarRocks menjalankannya secara langsung. Saat pekerjaan selesai, StarRocks mengembalikan hasil impor. Sistem eksternal dapat menentukan keberhasilan impor berdasarkan hasil tersebut.
Prosedur:
Sistem eksternal membuat pekerjaan impor.
StarRocks mengembalikan hasil impor.
Sistem eksternal menentukan hasil impor. Jika pekerjaan gagal, buat pekerjaan baru.
Mode Asinkron
Dalam mode asinkron, setelah sistem eksternal membuat pekerjaan impor, StarRocks mengembalikan hasil yang menunjukkan bahwa pekerjaan telah dibuat. Ini tidak berarti data telah diimpor. Pekerjaan impor dijalankan secara asinkron. Setelah pekerjaan dibuat, sistem eksternal memantau statusnya dengan menjalankan perintah tertentu. Jika pekerjaan gagal dibuat, sistem eksternal dapat memutuskan apakah akan membuat pekerjaan baru berdasarkan informasi kegagalan.
Prosedur:
Sistem eksternal membuat pekerjaan impor.
StarRocks mengembalikan hasil pembuatan pekerjaan impor.
Sistem eksternal menentukan langkah selanjutnya berdasarkan hasil yang dikembalikan. Jika pekerjaan berhasil dibuat, lanjutkan ke Langkah 4. Jika gagal, kembali ke Langkah 1 dan buat pekerjaan baru.
Sistem eksternal memantau status pekerjaan hingga status berubah menjadi FINISHED atau CANCELLED.
Skema
Skenario | Deskripsi |
Impor data dari HDFS | Jika Anda ingin mengimpor data yang disimpan di HDFS dan volume data berkisar antara puluhan hingga ratusan gigabyte, Anda dapat menggunakan Broker Load untuk mengimpor data ke StarRocks. Dalam hal ini, sumber data HDFS harus dapat diakses oleh proses broker yang telah diterapkan. Pekerjaan impor dijalankan dalam mode asinkron. Anda dapat menjalankan perintah |
Impor file lokal | Jika data Anda disimpan dalam file lokal dan volume data kurang dari 10 GB, Anda dapat menggunakan Stream Load untuk dengan cepat mengimpor data ke StarRocks. Anda dapat membuat pekerjaan impor dengan menggunakan protokol HTTP dan menjalankan pekerjaan impor dalam mode sinkron. Kemudian, Anda dapat menentukan apakah impor berhasil berdasarkan hasil yang dikembalikan dari permintaan HTTP. |
Impor data dari Kafka | Jika Anda ingin mengimpor data dari sumber data streaming, seperti Kafka, ke StarRocks secara real-time, Anda dapat menggunakan Routine Load. Untuk memungkinkan StarRocks terus membaca dan mengimpor data dari Kafka, Anda dapat membuat pekerjaan impor rutin dengan menggunakan protokol MySQL. |
Impor data dengan menggunakan pernyataan INSERT INTO | Anda dapat menggunakan pernyataan INSERT INTO untuk menulis data ke tabel StarRocks saat Anda melakukan pengujian atau memproses data sementara. Pernyataan INSERT INTO tbl SELECT ...; digunakan untuk membaca data dari tabel StarRocks dan mengimpor data ke tabel lain. Pernyataan |
Batasan memori
Anda dapat mengonfigurasi parameter untuk membatasi ukuran memori pekerjaan impor tunggal. Hal ini mencegah pekerjaan impor menggunakan memori berlebihan yang dapat menyebabkan kesalahan kehabisan memori (OOM). Metode pembatasan memori bervariasi berdasarkan metode impor. Untuk detail lebih lanjut, lihat topik terkait untuk setiap metode impor.
Dalam banyak kasus, pekerjaan impor dijalankan pada beberapa node BE. Anda dapat mengonfigurasi parameter untuk membatasi ukuran memori pekerjaan impor pada node BE tunggal. Anda juga dapat menentukan ukuran memori maksimum yang dapat digunakan oleh pekerjaan impor pada setiap node BE. Untuk informasi lebih lanjut, lihat topik Konfigurasi Sistem Umum dalam topik ini.
Menentukan ukuran memori yang terlalu kecil dapat memengaruhi efisiensi impor karena data sering ditulis ke disk saat penggunaan memori mencapai batas atas. Sebaliknya, menentukan ukuran memori yang terlalu besar dapat menyebabkan kesalahan OOM akibat konkurensi impor yang tinggi. Konfigurasikan parameter terkait memori sesuai dengan kebutuhan bisnis Anda.
Konfigurasi sistem umum
Konfigurasi node FE
Tabel berikut menjelaskan parameter sistem node FE. Anda dapat memodifikasi parameter dalam file konfigurasi fe.conf.
Parameter | Deskripsi |
max_load_timeout_second | Periode timeout impor maksimum dan minimum. Unit: detik. Secara default, periode timeout maksimum adalah tiga hari, dan periode timeout minimum adalah 1 detik. Periode timeout impor yang Anda tentukan harus berada dalam rentang ini. Parameter ini valid untuk semua jenis pekerjaan impor. |
min_load_timeout_second | |
desired_max_waiting_jobs | Jumlah maksimum pekerjaan impor yang dapat ditampung oleh antrian tunggu. Nilai default: 100. Sebagai contoh, jika jumlah pekerjaan impor dalam status PENDING pada node FE mencapai nilai parameter ini, permintaan impor baru ditolak. Status PENDING menunjukkan bahwa pekerjaan impor menunggu untukdijalankan. Parameter ini hanya valid untuk pekerjaan impor asinkron. Jika jumlah pekerjaan impor asinkron dalam status PENDING mencapai batas atas, permintaan berikutnya untuk membuat pekerjaan impor akan ditolak. |
max_running_txn_num_per_db | Jumlah maksimum pekerjaan impor yang sedang berjalan yang diizinkan di setiap database. Nilai default: 100. Ketika jumlah pekerjaan impor yang berjalan di database mencapai jumlah maksimum yang Anda tentukan, pekerjaan impor berikutnya tidak akan dijalankan. Dalam situasi ini, jika pekerjaan impor sinkron dikirimkan, pekerjaan tersebut akan ditolak. Jika pekerjaan impor asinkron dikirimkan, pekerjaan tersebut akan menunggu dalam antrian. |
label_keep_max_second | Periode retensi catatan sejarah untuk pekerjaan impor. StarRocks menyimpan catatan pekerjaan impor yang telah selesai dan berada dalam status FINISHED atau CANCELLED selama periode tertentu. Anda dapat mengatur periode retensi dengan menggunakan parameter ini. Periode retensi default adalah tiga hari. Parameter ini valid untuk semua jenis pekerjaan impor. |
Konfigurasi node BE
Tabel berikut menjelaskan parameter sistem node BE. Anda dapat memodifikasi parameter dalam file konfigurasi be.conf.
Parameter | Deskripsi |
push_write_mbytes_per_sec | Kecepatan tulis maksimum per tablet pada node BE. Nilai default adalah 10, yang menunjukkan kecepatan tulis 10 MB/s. Dalam banyak kasus, kecepatan tulis maksimum berkisar antara 10 MB/s hingga 30 MB/s berdasarkan skema dan sistem yang digunakan. Anda dapat memodifikasi nilai parameter ini untuk mengontrol kecepatan impor data. |
write_buffer_size | Ukuran blok memori maksimum. Data yang diimpor pertama kali ditulis ke blok memori pada node BE. Ketika jumlah data yang diimpor mencapai ukuran blok memori maksimum yang Anda tentukan, data ditulis ke disk. Ukuran default adalah 100 MB. Jika ukuran blok memori maksimum terlalu kecil, sejumlah besar file kecil mungkin dihasilkan pada node BE. Anda dapat meningkatkan ukuran blok memori maksimum untuk mengurangi jumlah file yang dihasilkan. Jika ukuran blok memori maksimum terlalu besar, panggilan prosedur jarak jauh (RPC) mungkin mengalami timeout. Untuk informasi lebih lanjut, lihat deskripsi parameter tablet_writer_rpc_timeout_sec. |
tablet_writer_rpc_timeout_sec | Periode timeout RPC untuk mengirim batch data (1024 baris) selama proses impor. Nilai default: 600. Unit: detik. Sebuah RPC mungkin melibatkan operasi menulis blok memori dari beberapa tablet ke disk. Dalam hal ini, timeout RPC mungkin terjadi karena operasi penulisan disk. Anda dapat menyesuaikan periode timeout RPC untuk mengurangi kesalahan timeout, seperti kesalahan send batch fail. Jika Anda mengatur parameter write_buffer_size ke nilai yang lebih tinggi, Anda juga harus meningkatkan nilai parameter tablet_writer_rpc_timeout_sec. |
streaming_load_rpc_max_alive_time_sec | Periode timeout menunggu untuk setiap thread Writer. Selama proses impor data, StarRocks memulai thread Writer untuk menerima data dari dan menulis data ke setiap tablet. Nilai default: 600. Unit: detik. Jika proses Writer tidak menerima data apa pun dalam periode timeout menunggu yang Anda tentukan, StarRocks secara otomatis menghancurkan thread Writer. Saat sistem memproses data dengan kecepatan rendah, thread Writer mungkin tidak menerima batch data berikutnya dalam waktu lama dan oleh karena itu melaporkan kesalahan |
load_process_max_memory_limit_percent | Jumlah maksimum dan persentase tertinggi memori yang dapat dikonsumsi untuk semua pekerjaan impor pada setiap node BE. StarRocks mengidentifikasi konsumsi memori yang lebih kecil di antara nilai dua parameter sebagai konsumsi memori akhir yang diizinkan.
|
load_process_max_memory_limit_bytes |