Anda dapat menggunakan Paimon untuk membangun data lake di HDFS atau OSS dan menganalisis datanya menggunakan mesin komputasi Spark. Topik ini menjelaskan cara menggunakan Spark SQL di EMR untuk membaca dari dan menulis ke tabel Paimon.
Prasyarat
Anda telah membuat kluster DataLake atau Custom EMR dengan Spark dan Paimon yang telah terinstal. Untuk informasi lebih lanjut, lihat Create a cluster.
Batasan
-
Anda dapat menggunakan Spark SQL untuk membaca dari dan menulis ke Paimon pada kluster EMR yang menjalankan EMR-3.46.0 atau versi lebih baru, atau EMR-5.12.0 atau versi lebih baru.
-
Hanya Spark SQL di Spark 3 yang dapat membaca dari dan menulis ke Paimon melalui katalog.
Prosedur
Langkah 1: Konfigurasikan katalog
Spark membaca dari dan menulis ke tabel Paimon melalui katalog. Terdapat dua jenis katalog yang tersedia: katalog Paimon dan spark_catalog. Anda dapat memilih salah satu berdasarkan kasus penggunaan Anda.
-
Katalog Paimon: Mengelola metadata dalam format Paimon. Anda hanya dapat menggunakannya untuk melakukan kueri dan menulis ke tabel Paimon.
-
spark_catalog: Katalog bawaan default di Spark. Biasanya mengelola metadata tabel internal di Spark SQL dan memungkinkan Anda melakukan kueri serta menulis ke tabel Paimon maupun non-Paimon.
Paimon catalog
Anda dapat menyimpan metadata di sistem file seperti HDFS atau layanan penyimpanan objek seperti OSS. Anda juga dapat menyinkronkan metadata ke DLF dan Hive agar Paimon dapat diakses oleh layanan lain.
Parameter spark.sql.catalog.paimon.warehouse menentukan path root gudang data. Jika path root belum ada, sistem akan membuatnya secara otomatis. Jika path root sudah ada, Anda dapat menggunakan katalog ini untuk mengakses tabel yang sudah ada di path tersebut.
-
Login ke node master kluster Anda melalui SSH. Untuk informasi lebih lanjut, lihat Log on to a cluster.
-
Pilih katalog yang akan dikonfigurasi berdasarkan jenis metadata. Jalankan perintah yang sesuai untuk memulai Spark SQL.
Filesystem catalog
Katalog filesystem menyimpan metadata di sistem file atau penyimpanan objek.
spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \ --conf spark.sql.catalog.paimon.metastore=filesystem \ --conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \ --conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensionsCatatan-
spark.sql.catalog.paimon: Mendefinisikan katalog bernama paimon. -
spark.sql.catalog.paimon.metastore: Menentukan jenis metastore untuk katalog tersebut. Mengatur nilainya kefilesystemberarti metadata disimpan di sistem file. -
spark.sql.catalog.paimon.warehouse: Mengonfigurasi lokasi gudang data. Ganti<yourBucketName>dengan nama bucket OSS Anda. Untuk informasi lebih lanjut tentang cara membuat bucket, lihat Create a bucket.
DLF catalog
Katalog DLF menyinkronkan metadata ke DLF.
PentingSaat membuat kluster, Metadata harus diatur ke DLF Unified Metadata.
spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \ --conf spark.sql.catalog.paimon.metastore=dlf \ --conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \ --conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensionsCatatan-
spark.sql.catalog.paimon: Mendefinisikan katalog bernama paimon. -
spark.sql.catalog.paimon.metastore: Menentukan jenis metastore untuk katalog tersebut. Mengatur nilainya kedlfberarti metadata disinkronkan ke Data Lake Formation (DLF). -
spark.sql.catalog.paimon.warehouse: Mengonfigurasi lokasi gudang data. Ganti<yourBucketName>dengan nama bucket OSS Anda. Untuk informasi lebih lanjut tentang cara membuat bucket, lihat Create a bucket.
Hive catalog
Katalog Hive menyinkronkan metadata ke Hive Metastore. Tabel yang dibuat di katalog Hive dapat langsung dikueri di Hive. Untuk informasi lebih lanjut tentang cara melakukan kueri Paimon dari Hive, lihat Integrate Paimon with Hive.
spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \ --conf spark.sql.catalog.paimon.metastore=hive \ --conf spark.sql.catalog.paimon.uri=thrift://master-1-1:9083 \ --conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \ --conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensionsCatatan-
spark.sql.catalog.paimon: Mendefinisikan katalog bernama paimon. -
spark.sql.catalog.paimon.metastore: Menentukan jenis metastore untuk katalog tersebut. Mengatur nilainya kehiveberarti metadata disinkronkan ke Hive Metastore. -
spark.sql.catalog.paimon.uri: Alamat dan port layanan Hive Metastore. Nilaithrift://master-1-1:9083berarti Spark SQL terhubung ke layanan Hive Metastore yang berjalan di hostmaster-1-1dan mendengarkan pada Port 9083 untuk mendapatkan metadata. -
spark.sql.catalog.paimon.warehouse: Mengonfigurasi lokasi gudang data. Ganti<yourBucketName>dengan nama bucket OSS Anda. Untuk informasi lebih lanjut tentang cara membuat bucket, lihat Create a bucket.
-
spark_catalog
-
Login ke node master kluster Anda melalui SSH. Untuk informasi lebih lanjut, lihat Log on to a cluster.
-
Jalankan perintah berikut untuk mengonfigurasi katalog dan memulai Spark SQL.
spark-sql --conf spark.sql.catalog.spark_catalog=org.apache.paimon.spark.SparkGenericCatalog \ --conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensionsCatatan-
spark.sql.catalog.spark_catalog: Mendefinisikan katalog bernama spark_catalog. -
Path root gudang data untuk
spark_catalogditentukan oleh parameterspark.sql.warehouse.dir. Dalam kebanyakan kasus, Anda tidak perlu mengubah parameter ini.
-
Langkah 2: Baca dan tulis tabel Paimon
Jalankan pernyataan Spark SQL berikut untuk membuat tabel di katalog, lalu baca dan tulis data ke tabel tersebut.
Paimon catalog
Untuk mengakses tabel Paimon, gunakan format paimon.<db_name>.<tbl_name>, di mana <db_name> adalah nama database dan <tbl_name> adalah nama tabel.
-- Create a database.
CREATE DATABASE IF NOT EXISTS paimon.ss_paimon_db;
-- Create a Paimon table.
CREATE TABLE paimon.ss_paimon_db.paimon_tbl (id INT, name STRING) USING paimon;
-- Write data to the Paimon table.
INSERT INTO paimon.ss_paimon_db.paimon_tbl VALUES (1, "apple"), (2, "banana"), (3, "cherry");
-- Query the write result.
SELECT * FROM paimon.ss_paimon_db.paimon_tbl ORDER BY id;
-- Drop the database.
DROP DATABASE paimon.ss_paimon_db CASCADE;Jika Anda menerima error metastore: Failed to connect to the Metastore Server saat membuat database setelah mengonfigurasi katalog Hive, artinya layanan Hive Metastore tidak sedang berjalan. Anda harus menjalankan perintah berikut untuk memulai layanan tersebut. Setelah layanan berjalan, jalankan kembali perintah untuk mengonfigurasi katalog Hive.
hive --service metastore &Jika Anda memilih DLF Unified Metadata saat membuat kluster, kami menyarankan Anda mengonfigurasi katalog DLF untuk menyinkronkan metadata ke DLF.
spark_catalog
Anda dapat menggunakan spark_catalog.<db_name>.<tbl_name> untuk mengakses tabel Paimon maupun non-Paimon. Karena spark_catalog merupakan katalog bawaan default di Spark, Anda dapat menghilangkan nama katalog dan langsung mengakses tabel menggunakan <db_name>.<tbl_name>. Dalam format ini, <db_name> adalah nama database dan <tbl_name> adalah nama tabel.
-- Create databases.
CREATE DATABASE IF NOT EXISTS ss_paimon_db;
CREATE DATABASE IF NOT EXISTS ss_parquet_db;
-- Create a Paimon table and a Parquet table.
CREATE TABLE ss_paimon_db.paimon_tbl (id INT, name STRING) USING paimon;
CREATE TABLE ss_parquet_db.parquet_tbl USING parquet AS SELECT 3, "cherry";
-- Write data to the Paimon table.
INSERT INTO ss_paimon_db.paimon_tbl VALUES (1, "apple"), (2, "banana");
INSERT INTO ss_paimon_db.paimon_tbl SELECT * FROM ss_parquet_db.parquet_tbl;
-- Query the write result.
SELECT * FROM ss_paimon_db.paimon_tbl ORDER BY id;
-- Drop the databases.
DROP DATABASE ss_paimon_db CASCADE;
DROP DATABASE ss_parquet_db CASCADE;Kueri mengembalikan hasil berikut:
1 apple
2 banana
3 cherry FAQ
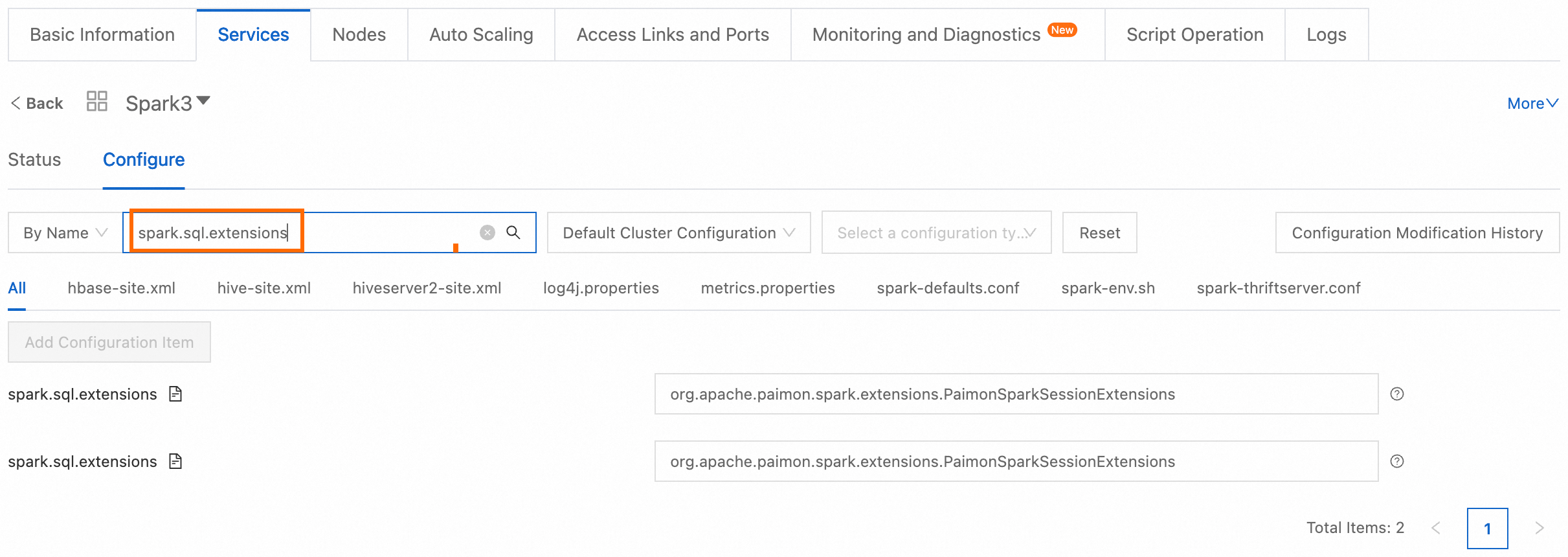
Ya. Setelah Anda menambahkan layanan Paimon ke kluster, ikuti langkah-langkah berikut untuk melihat konfigurasinya:
-
Buka tab Services kluster target.
-
Lihat konfigurasi layanan Spark.
-
Di sebelah kanan layanan Spark, klik Configure.
-
Di kotak pencarian By Name, cari spark.sql.extensions untuk melihat konfigurasinya.
-
Dokumentasi terkait
Untuk informasi lebih lanjut tentang penggunaan dan konfigurasi Paimon, lihat dokumentasi Apache Paimon.