Di Data Map DataWorks, Anda dapat melihat informasi alur data terperinci untuk tabel dan API DataService Studio pada halaman detail masing-masing. Informasi ini berguna untuk pelacakan dan manajemen data. Konsol mengkategorikan komputasi dan metadata berdasarkan jenisnya, seperti EMR Hive, Data Lake Formation (DLF), dan Data Lake Formation (DLF-Legacy). Topik ini menggunakan kategorisasi yang sama dengan Data Map dan Data Studio untuk menjelaskan cara melihat alur data untuk setiap jenis.
Table Lineage
Titik masuk tampilan
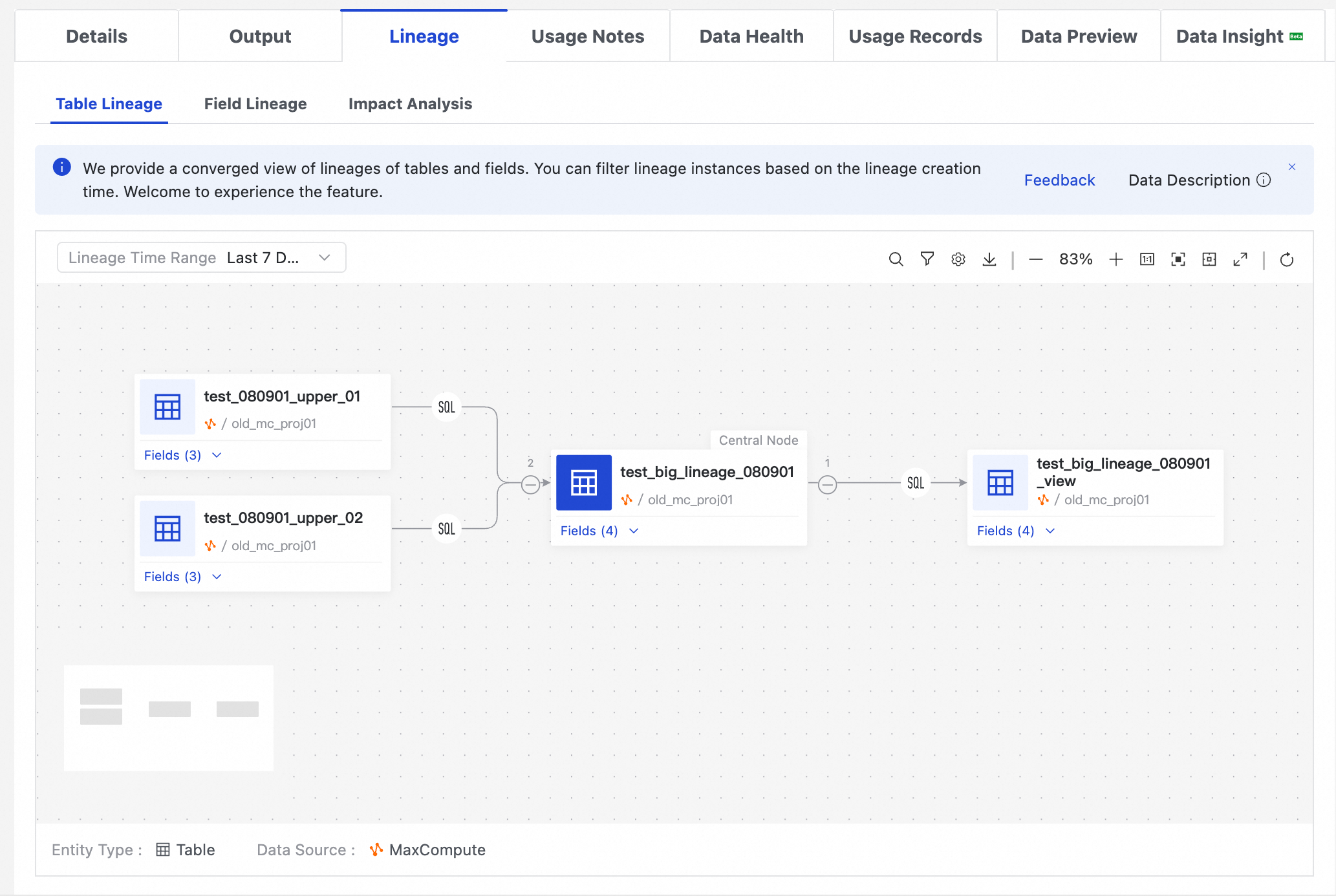
Di Data Map, temukan tabel dan buka halaman detailnya. Lalu, klik tab Lineage Information untuk melihat detail alur data tingkat tabel dan tingkat bidang. Anda juga dapat melakukan analisis dampak untuk mendapatkan daftar tabel turunan dari tabel tersebut. Daftar ini dapat diunduh sebagai file lokal atau dikirimkan melalui email sebagai notifikasi perubahan.
Data Map menampilkan alur data antar tabel dan bidang yang diurai dari pekerjaan penjadwalan dan informasi penerusan data. Alur data dari operasi manual, seperti kueri sementara, tidak disertakan. Alur data untuk data offline diperbarui dengan basis T+1.
Untuk melihat alur data kompleks bersusun banyak dalam area yang lebih luas, klik tombol Open in new page (ikon layar penuh) di bilah alat di pojok kanan atas graf alur data. Hal ini memungkinkan Anda menjelajahi alur data di halaman terpisah. Tombol ini tersedia di tab alur data untuk tabel, set data, API DataService Studio, dan aset AI.
Jika fitur alur data belum diaktifkan untuk ruang kerja atau penyewa Anda, halaman langganan akan muncul saat Anda membuka tab alur data. Ikuti petunjuk di layar untuk membeli atau mengaktifkan fitur tersebut.
Batasan untuk setiap sumber data
EMR Hive, DLF, dan DLF-Legacy
-
EMR Hive: Untuk mengelola metadata kluster EMR di DataWorks, Anda harus terlebih dahulu mengonfigurasi EMR-HOOK pada kluster tersebut. Jika EMR-HOOK tidak dikonfigurasi, alur data tidak dapat ditampilkan di DataWorks. Untuk informasi selengkapnya, lihat Konfigurasi EMR-HOOK untuk Hive.
-
DLF dan DLF-Legacy: Untuk tabel di Data Lake Formation (DLF) dan Data Lake Formation (DLF-Legacy), alur data dapat ditampilkan di Data Map setelah metadata dikumpulkan. Ini didukung ketika pekerjaan komputasi menggunakan metadata DLF yang sesuai dengan mesin Serverless Spark, Serverless StarRocks, atau Serverless Flink. Untuk mesin atau skenario lainnya, tampilan alur data bergantung pada kemampuan akuisisi dan penguraian metadata. Untuk informasi selengkapnya, lihat Akuisisi metadata.
PentingMesin Serverless Spark, Serverless StarRocks, dan Serverless Flink harus disambungkan ke ruang kerja DataWorks. Jika tidak, alur data yang sesuai dianggap tidak relevan dengan DataWorks dan diabaikan.
-
Untuk kluster komputasi EMR Hive: Penampilan alur data tidak didukung untuk kluster EMR on ACK Spark, tetapi didukung untuk kluster EMR Serverless Spark.
-
Untuk kluster komputasi EMR Hive: Alur data tidak tersedia untuk tugas yang dijalankan pada node EMR Presto.
-
Mesin EMR Impala: Akuisisi alur data untuk pekerjaan EMR Impala bergantung pada log alur data Impala itu sendiri. Di konsol kluster EMR, buka Layanan Kluster > Impala > Configuration. Atur parameter
lineage_event_log_dirmenjadi/mnt/disk1/log/impala/lineage_logdan restart layanan Impala. Setelah langkah-langkah ini dilakukan, Data Map DataWorks dapat menampilkan alur data tingkat tabel dan tingkat bidang untuk pekerjaan EMR Impala.Catatan-
Hanya pekerjaan Impala pada kluster EMR DataLake yang didukung. Metadata Hive Metastore (HMS) (sesuai dengan jenis sumber data EMR Hive) dan DLF (sesuai dengan jenis sumber data DLF) didukung.
-
Tidak ada persyaratan khusus untuk versi kluster EMR atau versi Impala, selama Impala telah dideploy pada kluster tersebut.
-
Fitur ini saat ini sedang dalam rilis bertahap. Untuk menggunakannya, Anda harus mengajukan tiket atau menghubungi dukungan teknis Alibaba Cloud agar fitur ini diaktifkan.
-
AnalyticDB for MySQL
-
Jalankan perintah SQL
set adb_config RC_LINEAGE_INFO_LOG_ENABLE=truepada engine untuk mengaktifkan fitur alur data untuk instans AnalyticDB for MySQL. -
Jika sumber metadata adalah AnalyticDB for Spark, akuisisi otomatis didukung.
-
Jika sumber metadata adalah AnalyticDB for Spark, Anda harus mengonfigurasi parameter Spark
spark.sql.queryExecutionListeners = com.aliyun.dataworks.meta.lineage.LineageListeneruntuk mendukung alur data real-time.
Untuk tabel AnalyticDB for MySQL, beberapa perintah SQL tidak mendukung pembuatan alur data di Data Map. Berikut batasan-batasannya.
-
Perintah SQL yang tidak didukung:
SQL yang Tidak Didukung
Contoh
JOIN,UNION, dan kata kunci seperti*tidak didukung.Misalnya, perintah SQL berikut menggunakan
*. Data Map tidak dapat menampilkan alur datanya.INSERT INTO test SELECT * FROM test1, test2 WHERE test1.id = test2.idSubkueri tidak didukung.
Misalnya, perintah SQL berikut berisi subkueri. Data Map tidak dapat menampilkan alur datanya.
SELECT column1, column2 FROM table1 WHERE column3 IN (SELECT column4 FROM table2 WHERE column5 = 'value') -
Contoh perintah SQL yang mendukung alur data:
-
Contoh 1: Buat tabel bernama A tanpa menentukan informasi kolom dan pilih kolom tertentu (tidak termasuk *) dari tabel B untuk mengisi tabel A. Misalnya:
CREATE TABLE test AS SELECT id,name FROM test1; -
Contoh 2: Masukkan data dari kolom tertentu (tidak termasuk *) tabel A yang memenuhi kondisi `column1 = value1` ke tabel B tanpa menentukan informasi kolom. Misalnya:
INSERT INTO test SELECT id,name FROM test1 WHERE name='test'; -
Contoh 3: Timpa tabel B di database dengan data dari kolom tertentu (tidak termasuk *) tabel A. Misalnya:
INSERT OVERWRITE INTO db_name.test SELECT id,name FROM test1;
-
CDH
Untuk menampilkan lineage tabel untuk proses transformasi data node CDH Spark SQL dan CDH Spark di Data Map, Anda harus mengonfigurasi parameter Spark untuk modul transformasi data tertentu di .
Login ke Konsol DataWorks. Di wilayah target, klik di panel navigasi sebelah kiri. Pilih ruang kerja dari daftar drop-down dan klik Go to Management Center.
-
Di panel navigasi sebelah kiri, klik Cluster Management, lalu temukan kluster CDH target yang telah Anda buat.
-
Klik Edit Spark Parameters.

-
Tambahkan parameter Spark berdasarkan modul transformasi data tertentu.
Misalnya, untuk menampilkan lineage tabel untuk proses transformasi data node CDH Spark SQL dan CDH Spark di modul Operation Center - Recurring Instances di Data Map, tambahkan parameter berikut untuk modul tersebut:
-
Spark Property Name:
spark.sql.queryExecutionListeners. -
Spark Property Value:
com.aliyun.dataworks.meta.lineage.LineageListener.
-
-
Klik Confirm untuk menyelesaikan pengeditan.
Lindorm
Informasi alur data hanya dapat dikumpulkan dalam mode instans. Informasi ini tidak dapat dikumpulkan dalam mode string koneksi.
Untuk menampilkan lineage tabel untuk proses transformasi data node Lindorm Spark dan Lindorm Spark SQL di Data Map, Anda harus mengonfigurasi parameter Spark untuk modul transformasi data tertentu di .
Login ke Konsol DataWorks. Di wilayah target, klik di panel navigasi sebelah kiri. Pilih ruang kerja dari daftar drop-down dan klik Go to Management Center.
-
Di panel navigasi sebelah kiri, klik Computing Resources, lalu temukan sumber daya komputasi Lindorm yang telah Anda buat.
-
Klik Edit Spark Parameters.
-
Tambahkan parameter Spark berdasarkan modul transformasi data tertentu.
Misalnya, untuk menampilkan lineage tabel untuk proses transformasi data node Lindorm Spark dan Lindorm Spark SQL di modul Operation Center - Recurring Instances di Data Map, tambahkan parameter berikut untuk modul tersebut:
-
Spark Property Name:
spark.sql.queryExecutionListeners. -
Spark Property Value:
com.aliyun.dataworks.meta.lineage.LineageListener.
-
-
Klik Confirm untuk menyimpan konfigurasi parameter Spark.
Ringkasan dukungan alur data berdasarkan sumber data
Sumber data E-MapReduce asli telah dibagi menjadi EMR Hive, DLF, dan DLF-Legacy di Data Map berdasarkan sumber metadata. Tabel berikut mencantumkan dukungan alur data untuk setiap kategori sumber data sebagaimana ditampilkan di konsol saat ini.
|
Sumber data |
Data Integration |
Data Development |
||
|
Alur data tingkat tabel |
Alur data tingkat bidang |
Alur data tingkat tabel |
Alur data tingkat bidang |
|
|
AnalyticDB for MySQL
|
|
|
|
|
|
AnalyticDB for PostgreSQL
|
|
|
|
|
|
ClickHouse
|
|
|
|
|
|
CDH/CDP
|
|
|
Hive, Impala, Spark, Spark SQL
|
Hive, Impala, Spark, Spark SQL
|
|
EMR Hive
|
(OSS, Hive)
|
(OSS, Hive)
|
Dukungan untuk mesin EMR, Serverless Spark, Serverless StarRocks, dan Serverless Flink, serta mesin EMR Impala (hanya untuk kluster EMR DataLake; fitur ini sedang dalam rilis bertahap dan memerlukan Anda menghubungi dukungan teknis Alibaba Cloud untuk mengaktifkannya).
|
Dukungan untuk mesin EMR, Serverless Spark, Serverless StarRocks, dan Serverless Flink, serta mesin EMR Impala (hanya untuk kluster EMR DataLake; fitur ini sedang dalam rilis bertahap dan memerlukan Anda menghubungi dukungan teknis Alibaba Cloud untuk mengaktifkannya).
|
|
DLF-Legacy
|
(OSS, Hive)
|
(OSS, Hive)
|
Dukungan untuk mesin EMR, Serverless Spark, Serverless StarRocks, dan Serverless Flink, serta mesin EMR Impala (hanya untuk kluster EMR DataLake; fitur ini sedang dalam rilis bertahap dan memerlukan Anda menghubungi dukungan teknis Alibaba Cloud untuk mengaktifkannya).
|
Dukungan untuk mesin EMR, Serverless Spark, Serverless StarRocks, dan Serverless Flink, serta mesin EMR Impala (hanya untuk kluster EMR DataLake; fitur ini sedang dalam rilis bertahap dan memerlukan Anda menghubungi dukungan teknis Alibaba Cloud untuk mengaktifkannya).
|
|
DLF
|
(OSS, Hive)
|
(OSS, Hive)
|
Dukungan untuk mesin Serverless Spark, Serverless StarRocks, dan Serverless Flink, serta mesin EMR Impala (hanya untuk kluster EMR DataLake; fitur ini sedang dalam rilis bertahap dan memerlukan Anda menghubungi dukungan teknis Alibaba Cloud untuk mengaktifkannya).
|
Dukungan untuk mesin Serverless Spark, Serverless StarRocks, dan Serverless Flink, serta mesin EMR Impala (hanya untuk kluster EMR DataLake; fitur ini sedang dalam rilis bertahap dan memerlukan Anda menghubungi dukungan teknis Alibaba Cloud untuk mengaktifkannya).
|
|
Hologres
|
|
|
|
|
|
Kafka
|
(dari Kafka ke MaxCompute atau Hologres) |
|
|
|
|
Lindorm
|
|
|
|
|
|
MaxCompute
|
|
|
|
|
|
MySQL
|
(dari MySQL ke MaxCompute atau Hologres) |
|
|
|
|
Oracle
|
|
|
|
|
|
OceanBase
|
|
|
|
|
|
OSS
|
|
|
|
|
|
PolarDB for MySQL
|
|
|
|
|
|
PolarDB for PostgreSQL
|
|
|
|
|
|
PostgreSQL
|
|
|
|
|
|
StarRocks
|
|
|
|
|
|
SQL Server
|
|
|
|
|
|
Tablestore (OTS)
|
|
|
|
|
 Halaman produk
Halaman produk Sinkronisasi real-time
Sinkronisasi real-timeAlur data API DataService Studio
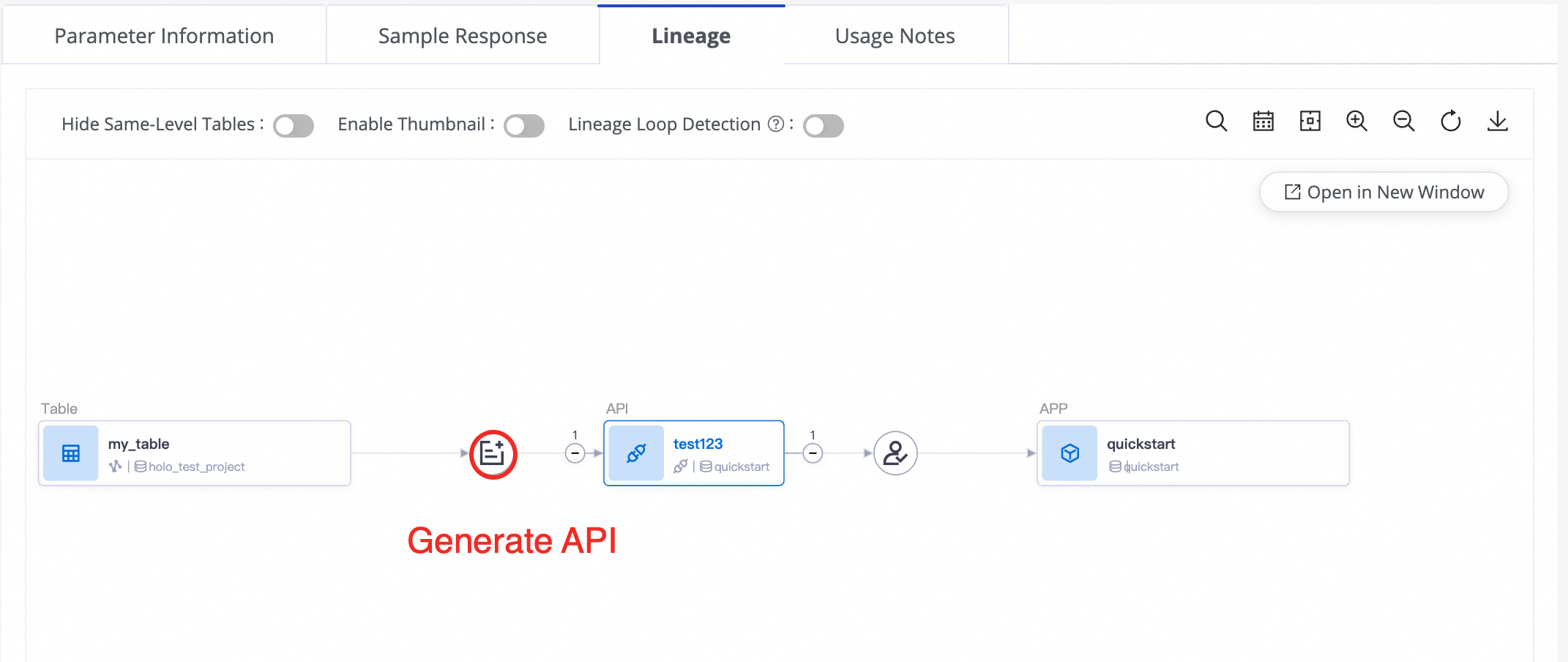
Temukan API DataService Studio dan buka halaman detailnya. Lalu, klik tab Lineage Information untuk melihat detail alur data API tersebut.
Silsilah aset AI
Layanan alur data aset AI memungkinkan Anda melacak alur data antara set data masukan, set hasil keluaran, dan model yang digunakan dalam pelatihan model. Untuk deskripsi lengkap mengenai alur data aset AI, lihat Lihat aset AI.