Layanan DataStudio dari DataWorks memungkinkan Anda menentukan properti pengembangan dan penjadwalan tugas yang dipicu secara otomatis. DataStudio berintegrasi dengan Pusat Operasi untuk menyediakan antarmuka pengembangan visual bagi berbagai jenis mesin komputasi, seperti MaxCompute, Hologres, dan E-MapReduce (EMR). Melalui antarmuka ini, Anda dapat melakukan pengembangan kode cerdas, mengelola orkestrasi tugas multi-mesin dalam alur kerja, serta menerapkan tugas terstandarisasi. Dengan demikian, Anda dapat membangun gudang data offline, gudang data real-time, dan sistem analisis ad hoc guna memastikan produksi data yang efisien dan stabil. Topik ini menjelaskan istilah-istilah yang digunakan di DataStudio, kemampuan yang disediakannya, serta persiapan yang diperlukan sebelum memulai pengembangan data di DataStudio.
Buka halaman DataStudio
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi kiri, pilih . Pada halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down, lalu klik Go to Data Development.
DataStudio hanya didukung pada Chrome versi 69 atau lebih baru di PC.
Pengenalan modul
Ikhtisar kemampuan
Gambar berikut menunjukkan fitur utama yang disediakan oleh DataStudio. Untuk informasi selengkapnya, lihat bagian Lampiran: Istilah terkait pengembangan data dalam topik ini.
Fitur | Deskripsi |
Organisasi dan manajemen objek | DataStudio menyediakan mekanisme untuk mengorganisasi dan mengelola objek di DataWorks.
Untuk informasi selengkapnya, lihat Buat alur kerja dan bagian Mode manajemen dalam topik ini. Catatan Batasan jumlah maksimum alur kerja dan objek yang dapat Anda buat di DataStudio di setiap ruang kerja:
Jika jumlah alur kerja dan objek di ruang kerja saat ini mencapai batas atas, Anda tidak dapat lagi membuat alur kerja atau objek. |
Pengembangan tugas |
Untuk informasi tentang jenis node yang didukung oleh DataWorks, lihat Jenis node yang didukung. |
Penjadwalan tugas |
Untuk informasi selengkapnya tentang penjadwalan tugas, lihat Konfigurasi properti waktu dan Panduan konfigurasi dependensi penjadwalan. |
Debug tugas | Anda dapat melakukan debugging tugas atau alur kerja. Untuk informasi selengkapnya, lihat Prosedur debugging. |
Kontrol proses | DataStudio menyediakan mekanisme penerapan tugas terstandarisasi dan berbagai metode untuk melakukan kontrol proses. Anda dapat melakukan operasi yang mencakup namun tidak terbatas pada operasi berikut untuk kontrol proses:
|
Fitur lainnya |
|
Pengenalan halaman DataStudio
Anda dapat mengikuti instruksi dalam Fitur di halaman DataStudio untuk menggunakan fitur setiap modul di halaman tersebut.
Proses pengembangan
DataStudio DataWorks memungkinkan Anda membuat berbagai jenis tugas, termasuk tugas sinkronisasi real-time, tugas sinkronisasi batch, tugas pemrosesan batch, dan tugas yang dipicu secara manual. Untuk informasi selengkapnya tentang sinkronisasi data, lihat Data Integration. Persyaratan konfigurasi tugas berbeda-beda tergantung pada jenis mesin komputasi yang digunakan. Pastikan untuk memperhatikan peringatan dan instruksi terkait pengembangan tugas berbagai jenis mesin komputasi di DataWorks sebelum memulai pengembangan berdasarkan jenis tugas tersebut.
Instruksi pengembangan tugas berbagai jenis mesin komputasi: Anda dapat menambahkan berbagai sumber data ke DataWorks untuk mengembangkan tugas. Persyaratan konfigurasi tugas berbeda-beda tergantung pada jenis mesin komputasi. Untuk informasi selengkapnya, lihat topik-topik berikut:
Proses pengembangan umum: Tersedia dua mode ruang kerja: mode standar dan mode dasar. Proses pengembangan node berbeda tergantung pada mode ruang kerja yang digunakan.
Proses pengembangan tugas di ruang kerja mode standar

Proses pengembangan tugas di ruang kerja mode dasar
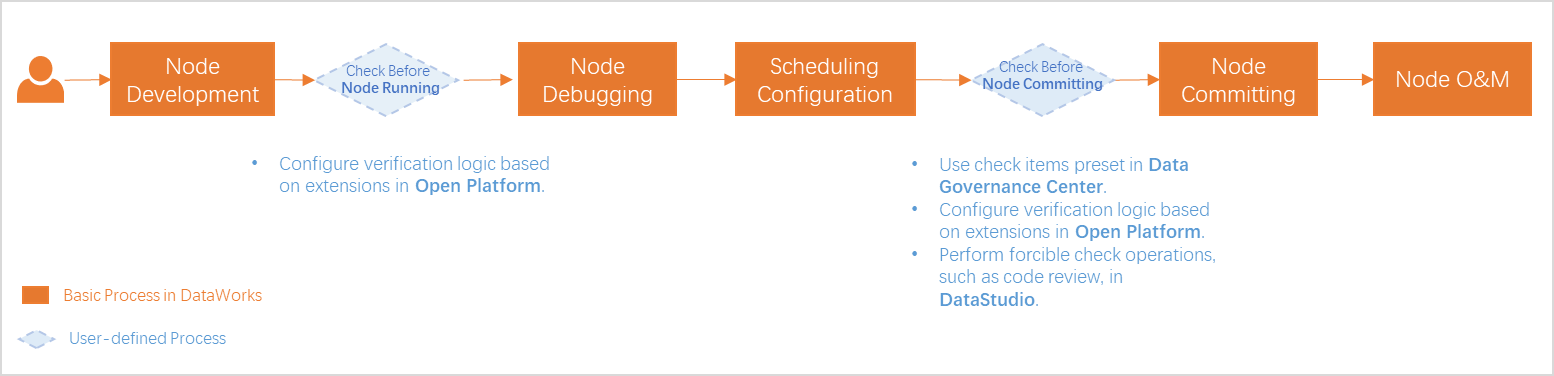
Proses dasar: Misalnya, jika Anda ingin mengembangkan tugas di ruang kerja mode standar, proses pengembangan mencakup tahapan berikut: pengembangan, debugging, konfigurasi pengaturan penjadwalan, commit tugas, penerapan tugas, dan O&M. Untuk informasi selengkapnya, lihat Proses pengembangan umum.
Kontrol proses: Selama pengembangan tugas, Anda dapat melakukan operasi seperti tinjauan kode dan pengujian asap yang disediakan oleh DataStudio, serta menggunakan item pemeriksaan yang telah ditentukan di Pusat Tata Kelola Data dan logika verifikasi yang disesuaikan melalui ekstensi di Open Platform untuk memastikan bahwa standar dan persyaratan tertentu dalam pengembangan tugas terpenuhi.
CatatanOperasi kontrol proses berbeda-beda tergantung pada mode ruang kerja. Operasi kontrol proses aktual yang berlaku mengikuti kondisi riil.
Mode manajemen
Alur kerja merupakan unit dasar untuk pengembangan kode dan manajemen sumber daya. Alur kerja adalah entitas bisnis abstrak yang memungkinkan Anda mengembangkan kode sesuai kebutuhan bisnis. Alur kerja dan node di ruang kerja berbeda dikembangkan secara terpisah. Untuk informasi selengkapnya tentang alur kerja, lihat Buat alur kerja.
Alur kerja dapat ditampilkan dalam bentuk pohon direktori atau panel. Mode tampilan ini memungkinkan Anda mengorganisasi kode dari perspektif bisnis serta menampilkan klasifikasi sumber daya dan logika bisnis secara lebih efisien.
Pohon direktori memungkinkan Anda mengorganisasi kode berdasarkan jenis tugas.
Panel menunjukkan logika bisnis dalam alur kerja.

Mulai menggunakan DataStudio
Persiapan lingkungan
Untuk menggunakan Pemodelan Data, DataStudio, atau menjadwalkan tugas secara berkala di Pusat Operasi, Anda harus mengasosiasikan sumber data atau kluster yang telah dibuat sebagai sumber daya komputasi di DataStudio. Hanya setelah sumber daya tersebut diasosiasikan, Anda dapat mengakses data dari sumber data atau kluster terkait dan melakukan operasi terkait. Jika tidak, Anda tidak akan dapat membuat node DataStudio apa pun.
Tambahkan sumber data atau kluster jenis tertentu sesuai dengan jenis tugas yang ingin Anda kembangkan dan jadwalkan.
Jenis sumber data atau kluster
Deskripsi
Pertama kali Anda menambahkan sumber data MaxCompute ke DataWorks, DataWorks secara otomatis mengasosiasikan sumber data tersebut dengan DataStudio. Anda tidak perlu mengikuti instruksi dalam topik ini untuk mengasosiasikan sumber data tersebut secara manual dengan DataStudio. Untuk sumber data MaxCompute yang ditambahkan kemudian, Anda harus mengasosiasikan sumber data tersebut secara manual dengan DataStudio.
Setelah Anda menambahkan sumber data salah satu jenis ini, Anda harus mengikuti instruksi dalam topik ini untuk mengasosiasikan sumber data tersebut secara manual dengan DataStudio.
Setelah Anda mendaftarkan kluster ke DataWorks, DataWorks mengasosiasikan kluster tersebut dengan DataStudio. Anda tidak perlu mengikuti instruksi dalam topik ini untuk mengasosiasikan kluster tersebut secara manual dengan DataStudio.
Cloudera's Distribution Including Apache Hadoop (CDH) atau Cloudera Data Platform (CDP)
Buka halaman DataStudio.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Di panel navigasi kiri, pilih . Pada halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down, lalu klik Go to Data Development.
Di panel navigasi kiri, klik Sumber Daya Komputasi.
Jika modul Computing Resource tidak ditampilkan di panel navigasi kiri, buka tab Personal Settings dan aktifkan opsi Computing Resource di bagian Modul DataStudio agar modul tersebut muncul di panel navigasi kiri halaman DataStudio. Untuk informasi selengkapnya, lihat Konfigurasikan pengaturan di bagian Modul DataStudio.
Asosiasikan sumber data atau kluster.
Di halaman Computing Resource, cari sumber data atau kluster yang diinginkan berdasarkan computing resource name atau computing resource type, lalu klik Associate. Setelah sumber data atau kluster diasosiasikan dengan DataStudio, Anda dapat membaca data dari sumber tersebut berdasarkan informasi koneksi dan melakukan operasi pengembangan data terkait.
CatatanJika informasi sumber data atau kluster berubah tetapi data di halaman saat ini tidak diperbarui tepat waktu, segarkan halaman untuk memperbarui data cache.

Sumber data atau kluster mungkin gagal diasosiasikan dengan DataStudio dalam skenario berikut:
Konfigurasi sumber data atau kluster jenis tertentu tidak mendukung asosiasi dengan DataStudio. Misalnya, sumber data yang ditambahkan menggunakan Pasangan Kunci Akses tidak dapat diasosiasikan dengan DataStudio. Untuk informasi selengkapnya tentang batasan asosiasi, lihat deskripsi yang ditampilkan di Konsol DataWorks saat Anda mengasosiasikan sumber data atau kluster.
Konfigurasi di lingkungan pengembangan atau produksi tidak tersedia.
Sumber data MaxCompute tidak dapat diasosiasikan dengan beberapa ruang kerja DataWorks secara bersamaan.
CatatanAlasan ketidakberhasilan asosiasi sumber data atau kluster dengan DataStudio bervariasi tergantung pada jenis sumber data atau kluster tersebut. Anda dapat melakukan troubleshooting berdasarkan pesan yang ditampilkan saat mencoba mengasosiasikan sumber data atau kluster.
Hanya jenis sumber data atau kluster berikut yang dapat diasosiasikan dengan DataStudio: MaxCompute, EMR, Hologres, AnalyticDB for MySQL, ClickHouse, CDH, CDP, dan AnalyticDB for PostgreSQL.
Jenis dan jumlah sumber data atau kluster yang dapat diasosiasikan dengan DataStudio bervariasi tergantung pada edisi DataWorks. Untuk informasi selengkapnya, lihat Fitur edisi DataWorks.
Memulai
Anda dapat merujuk ke Memulai dengan DataStudio untuk mempelajari operasi dasar dalam pengembangan data dan proses pengembangan data.
Jenis node yang didukung oleh DataStudio
Layanan DataStudio dari DataWorks memungkinkan Anda membuat berbagai jenis node. Anda dapat mengonfigurasi DataWorks untuk menjadwalkan instance yang dihasilkan dari node tersebut secara berkala. Anda juga dapat memilih jenis node tertentu sesuai kebutuhan bisnis Anda. Untuk informasi selengkapnya tentang jenis node yang didukung oleh DataWorks, lihat Jenis node yang didukung.
Lampiran: Istilah terkait pengembangan data
Istilah terkait pengembangan tugas
Istilah
Deskripsi
Solusi
Kumpulan alur kerja. Solusi adalah sekelompok alur kerja yang didedikasikan untuk tujuan bisnis tertentu. Sebuah alur kerja dapat ditambahkan ke beberapa solusi. Setelah Anda mengembangkan solusi dan menambahkan alur kerja ke dalam solusi tersebut, pengguna lain dapat mereferensi dan memodifikasi alur kerja tersebut dalam solusi mereka untuk pengembangan kolaboratif.
Alur kerja
Entitas bisnis abstrak dan kumpulan tugas, tabel, sumber daya, dan fungsi untuk kebutuhan bisnis tertentu. Tugas dalam alur kerja jenis ini dipicu untuk dijalankan sesuai jadwal.
Alur kerja yang dipicu secara manual
Kumpulan tugas, tabel, sumber daya, dan fungsi untuk kebutuhan bisnis tertentu.
Tugas dalam alur kerja jenis ini dipicu secara manual untuk dijalankan.
DAG
Singkatan dari
directed acyclic graph. DAG digunakan untuk menampilkan node dan dependensinya. Di DataStudio, semua tugas dalam alur kerja ditampilkan dalam DAG yang sama. Hal ini memudahkan pengembangan tugas dan konfigurasi dependensi.Tugas
Unit eksekusi dasar DataWorks. DataWorks menjalankan tugas secara berurutan berdasarkan dependensi antar tugas.
Node
Tugas dalam DAG. DataWorks menjalankan node secara berurutan berdasarkan dependensi antar node.
Istilah terkait penjadwalan tugas
Istilah
Deskripsi
Dependensi
Digunakan untuk menentukan urutan eksekusi tugas. Jika Node B hanya dapat dijalankan setelah Node A selesai dijalankan, maka Node A adalah node leluhur dari Node B, dan Node B bergantung pada Node A. Dalam DAG, dependensi direpresentasikan oleh panah antar node.
Nama output
Identifier yang digunakan untuk membedakan node saat ini dari node lainnya. Nama output bersifat unik secara global. Sebuah node dapat memiliki beberapa nama output. Dependensi penjadwalan antar node dikonfigurasi berdasarkan nama output.
Nama tabel output
Kami menyarankan Anda menggunakan nama tabel yang dihasilkan oleh tugas saat ini sebagai nama tabel output. Konfigurasi nama tabel output yang tepat dapat membantu memeriksa apakah data berasal dari tabel leluhur yang diharapkan saat Anda mengonfigurasi dependensi untuk node turunan. Kami menyarankan Anda tidak memodifikasi secara manual nama tabel output yang dihasilkan berdasarkan penguraian otomatis. Nama tabel output hanya berfungsi sebagai identifier. Memodifikasi nama tabel output tidak memengaruhi nama tabel yang sebenarnya dihasilkan saat mengeksekusi pernyataan SQL. Nama tabel yang benar-benar dihasilkan mengikuti logika SQL.
Catatanoutput name harus unik secara global. Namun, batasan tersebut tidak berlaku untuk output table name.
Kelompok sumber daya untuk penjadwalan
Kelompok sumber daya yang digunakan untuk penjadwalan tugas. Untuk informasi selengkapnya tentang kelompok sumber daya, lihat Ikhtisar.
Parameter penjadwalan
Dikonfigurasi untuk sebuah node saat node tersebut dijadwalkan untuk dijalankan. Nilai parameter penjadwalan diganti secara dinamis pada waktu penjadwalan node. Jika Anda ingin memperoleh informasi tentang lingkungan runtime, seperti tanggal dan waktu, selama eksekusi kode berulang, Anda dapat memberikan nilai variabel dalam kode secara dinamis berdasarkan definisi parameter penjadwalan di DataWorks.
Waktu data
Hari sebelum waktu penjadwalan (waktu saat Anda ingin menjadwalkan node). Dalam skenario komputasi offline, waktu data merepresentasikan tanggal transaksi bisnis dilakukan. Nilai waktu data akurat hingga hari. Misalnya, jika Anda mengumpulkan data statistik omset hari sebelumnya pada hari ini, maka hari sebelumnya adalah tanggal transaksi bisnis dilakukan dan merepresentasikan waktu data.
Waktu penjadwalan
Waktu saat Anda ingin menjadwalkan tugas untuk memproses data bisnis. Waktu penjadwalan akurat hingga detik. Waktu penjadwalan dapat berbeda dari waktu aktual saat tugas dijadwalkan untuk dijalankan. Waktu aktual eksekusi tugas dipengaruhi oleh berbagai faktor.