Node dan workflow dalam proyek Anda sering kali perlu dijalankan secara berkala. Untuk menjalankannya sesuai jadwal, Anda harus mengonfigurasi properti penjadwalan seperti periode penjadwalan, dependensi penjadwalan, dan parameter penjadwalan di panel konfigurasi penjadwalan untuk setiap node atau workflow. Topik ini menjelaskan cara mengonfigurasi properti penjadwalan tersebut.
Prasyarat
Anda telah membuat sebuah node. Di DataWorks, node digunakan untuk mendefinisikan tugas. Tugas engine yang berbeda direpresentasikan oleh jenis node yang berbeda. Pilih jenis node yang sesuai dengan kebutuhan bisnis Anda. Untuk informasi selengkapnya, lihat Kembangkan node.
Sakelar penjadwalan untuk ruang kerja telah diaktifkan. Tugas dalam ruang kerja DataWorks hanya dapat berjalan secara otomatis berdasarkan konfigurasinya setelah Anda mengaktifkan sakelar Enable Periodic Scheduling untuk ruang kerja tersebut. Untuk melakukannya, buka halaman Scheduling Settings ruang kerja. Untuk informasi selengkapnya, lihat Pengaturan sistem.
Penting
Konfigurasi ini hanya berlaku setelah tugas dipublikasikan ke lingkungan produksi.
Waktu penjadwalan hanya menentukan waktu eksekusi yang diharapkan dari suatu tugas. Waktu eksekusi aktual juga bergantung pada status node leluhurnya. Untuk informasi selengkapnya tentang kondisi eksekusi tugas, lihat Diagnosis eksekusi tugas.
DataWorks mendukung dependensi antara berbagai jenis tugas. Sebelum mengonfigurasi dependensi, kami menyarankan Anda membaca Prinsip dan contoh konfigurasi penjadwalan dalam skenario dependensi kompleks untuk memahami perilaku dependensi default di DataWorks dalam skenario kompleks.
Di DataWorks, tugas terjadwal menghasilkan instance berulang yang sesuai berdasarkan jenis dan periode penjadwalannya. Misalnya, tugas per jam menghasilkan sejumlah instance per jam setiap hari. Instance-instance ini kemudian menjalankan tugas secara otomatis.
Saat Anda menggunakan parameter penjadwalan, waktu penjadwalan setiap eksekusi dan ekspresi parameter Anda menentukan nilai parameter yang diteruskan ke kode. Untuk informasi selengkapnya tentang cara mengonfigurasi dan mengganti parameter penjadwalan, lihat Sumber dan ekspresi parameter penjadwalan.
Workflow mencakup node workflow itu sendiri dan node internalnya, sehingga menciptakan dependensi yang kompleks. Topik ini hanya menjelaskan konfigurasi penjadwalan dan dependensi untuk node individual. Untuk informasi detail tentang dependensi penjadwalan workflow, lihat Orkestrasi workflow berulang.
Buka halaman konfigurasi penjadwalan
Buka halaman Workspaces di Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Temukan ruang kerja yang diinginkan dan pilih di kolom Actions.
Buka halaman konfigurasi penjadwalan.
Di antarmuka DataStudio, temukan node target dan buka halaman editor-nya.
Klik Scheduling Configuration di panel navigasi sisi kanan halaman editor node.
Konfigurasikan properti penjadwalan node
Di halaman konfigurasi penjadwalan node, Anda perlu mengonfigurasi Scheduling Parameters, Scheduling Policy, Scheduling Time, Scheduling Dependencies, dan Node Output Parameters node tersebut.
Parameter penjadwalan (opsional)
Jika Anda telah mendefinisikan variabel dalam kode node, Anda harus memberikan nilainya di sini.
Parameter penjadwalan secara otomatis diganti dengan nilai tertentu berdasarkan tanggal bisnis tugas terjadwal dan format ekspresi parameternya. Hal ini memungkinkan penggantian parameter dinamis saat runtime.
Konfigurasikan parameter penjadwalan
Anda dapat mendefinisikan parameter penjadwalan dengan dua cara berikut.
Metode | Deskripsi | Contoh |
Add Parameter | Anda dapat mengonfigurasi beberapa parameter penjadwalan untuk satu tugas. Untuk menambahkan lebih banyak parameter, klik Add Parameter.
|
|
Load parameters from code | Fitur ini secara otomatis mengenali nama variabel yang didefinisikan dalam kode tugas dan menambahkannya sebagai parameter penjadwalan untuk digunakan dalam eksekusi terjadwal. Catatan Umumnya, variabel didefinisikan dalam kode menggunakan format Format definisi variabel untuk node PyODPS dan node Shell umum berbeda dari jenis node lainnya. Untuk detail format parameter penjadwalan berbagai jenis node, lihat Contoh konfigurasi parameter penjadwalan untuk berbagai jenis node. |
|
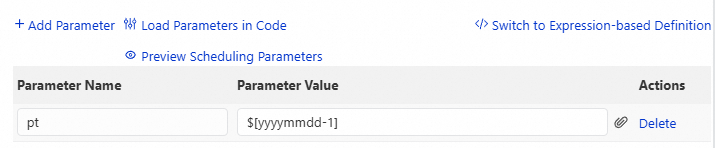

Format yang didukung untuk parameter penjadwalan
Untuk informasi selengkapnya, lihat Sumber dan ekspresi parameter penjadwalan.
Verifikasi parameter penjadwalan di lingkungan produksi
Untuk mencegah kegagalan tugas akibat parameter penjadwalan yang salah, kami menyarankan Anda membuka halaman Auto Triggered Task di Operation Center untuk memeriksa konfigurasi parameter penjadwalan tugas di lingkungan produksi setelah dipublikasikan. Untuk informasi selengkapnya tentang cara melihat Tugas Terpicu Otomatis, lihat Kelola Tugas Terpicu Otomatis.
Kebijakan penjadwalan
Kebijakan penjadwalan menentukan mode pembuatan instance, jenis penjadwalan, sumber daya komputasi, dan kelompok sumber daya untuk Tugas Terpicu Otomatis.
Parameter | Deskripsi |
Instance generation mode | Setelah node dipublikasikan ke sistem penjadwalan produksi, platform menghasilkan recurring instances otomatis berdasarkan Instance generation mode yang dikonfigurasi.
|
Scheduling type |
|
Timeout period | Jika Anda menetapkan periode timeout, tugas akan secara otomatis dihentikan jika durasi eksekusinya melebihi batas tersebut. Aturan berikut berlaku:
|
Rerun property | Menentukan apakah dan kapan node dapat dijalankan ulang. Anda harus menentukan properti rerun. Jenis yang didukung dan kasus penggunaannya sebagai berikut:
|
Automatic Rerun Upon Failure | Jika diaktifkan, ketika tugas gagal (tidak termasuk penghentian manual), sistem penjadwalan secara otomatis memicu rerun berdasarkan jumlah percobaan ulang dan interval percobaan ulang.
Catatan
|
Computing resource | Konfigurasikan sumber daya engine yang diperlukan untuk menjalankan tugas. Untuk membuat sumber daya baru, Anda dapat membuka kelola sumber daya komputasi. |
Computing quota | Anda dapat mengonfigurasi kuota komputasi yang diperlukan untuk menjalankan tugas di node MaxCompute SQL dan node Skrip MaxCompute. Kuota menyediakan sumber daya komputasi (CPU dan memori) untuk pekerjaan komputasi. |
Schedule resource group | Konfigurasikan kelompok sumber daya penjadwalan yang digunakan untuk menjalankan tugas. Pilih kelompok sumber daya sesuai kebutuhan.
|
Maximum parallel instances | Membatasi jumlah maksimum instance paralel untuk satu tugas guna memberikan kontrol konkurensi dan perlindungan sumber daya. Secara default, jumlah instance paralel tidak dibatasi. Saat batas ini diaktifkan, Anda dapat menetapkan jumlah instance paralel. Nilai default-nya adalah
|
Dataset | Klik
|
 untuk menambahkan
untuk menambahkan Waktu penjadwalan
Gunakan waktu penjadwalan untuk mengonfigurasi periode, waktu, dan informasi lainnya untuk eksekusi otomatis tugas terjadwal.
Untuk node dalam workflow, Scheduling Time dan parameter terkait diatur di Scheduling Configuration halaman workflow. Untuk node yang tidak dalam workflow, Scheduling Time diatur di Scheduling Configuration masing-masing node.
Penting
Frekuensi penjadwalan tugas bersifat independen dari periode tugas leluhur
Frekuensi penjadwalan tugas bergantung pada periode penjadwalan yang ditentukan sendiri, bukan periode tugas leluhurnya.
DataWorks mendukung dependensi antara tugas dengan periode penjadwalan berbeda
Di DataWorks, tugas terjadwal menghasilkan instance berulang yang sesuai berdasarkan jenis dan periode penjadwalannya (misalnya, tugas per jam menghasilkan sejumlah instance per jam setiap hari) dan dijalankan melalui instance-instance tersebut. Dependensi yang ditetapkan antar tugas berulang pada dasarnya adalah dependensi antar instance yang dihasilkannya. Jumlah instance berulang dan hubungan dependensinya bervariasi untuk tugas leluhur dan turunan dengan jenis penjadwalan berbeda. Untuk informasi selengkapnya tentang dependensi antar tugas dengan periode penjadwalan berbeda, lihat Pilih metode dependensi penjadwalan (dependensi lintas siklus).
Tugas melakukan dry run di luar waktu penjadwalannya
Tugas non-harian (seperti mingguan atau bulanan) melakukan dry-run dan mengembalikan status sukses pada hari non-terjadwal. Hal ini memungkinkan tugas turunan harian berjalan secara normal sesuai jadwalnya sendiri.
Waktu eksekusi tugas
Bagian ini hanya mengonfigurasi waktu penjadwalan yang diharapkan untuk tugas. Waktu eksekusi aktual bergantung pada berbagai faktor, seperti waktu penyelesaian tugas leluhur, ketersediaan sumber daya, dan kondisi eksekusi aktual tugas. Untuk informasi selengkapnya, lihat Kondisi eksekusi tugas.
Konfigurasikan waktu penjadwalan
Parameter | Deskripsi |
Scheduling period | Periode penjadwalan menentukan seberapa sering tugas dijalankan secara otomatis. Ini menentukan seberapa sering logika kode dalam node dieksekusi di lingkungan produksi. Tugas terjadwal menghasilkan instance berulang yang sesuai berdasarkan jenis dan periode penjadwalannya (misalnya, tugas per jam menghasilkan sejumlah instance per jam setiap hari) dan dijalankan secara otomatis melalui instance berulang tersebut.
Penting Tugas mingguan, bulanan, dan tahunan tetap menghasilkan instance setiap hari di luar waktu eksekusi terjadwalnya. Instance-instance ini menunjukkan status sukses tetapi sebenarnya melakukan dry-run dan tidak mengeksekusi tugas. |
Effective date | Node terjadwal berlaku dan dijalankan secara otomatis dalam rentang tanggal efektifnya. Tugas yang melewati tanggal efektifnya tidak lagi dijadwalkan secara otomatis. Tugas-tugas ini dianggap kedaluwarsa. Anda dapat melihat jumlah tugas kedaluwarsa di Dasbor O&M dan mengambil tindakan seperti menonaktifkannya. |
Cron expression | Ekspresi ini dihasilkan secara otomatis berdasarkan pengaturan properti waktu dan tidak perlu dikonfigurasi. |
Dependensi penjadwalan
Di DataWorks, dependensi penjadwalan menentukan hubungan leluhur-turunan antar node. Node turunan hanya dijalankan setelah semua node leluhurnya berhasil dijalankan. Struktur ini mencegah node turunan mengakses data sebelum node leluhurnya selesai menghasilkannya, sehingga menghindari masalah konsistensi data.
Penting
Setelah dependensi node dikonfigurasi, secara default, salah satu syarat agar node turunan dijalankan adalah semua node leluhurnya telah berhasil dijalankan. Jika tidak, masalah kualitas data dapat terjadi saat tugas saat ini mengambil data.
Waktu eksekusi aktual tugas tidak hanya bergantung pada waktu penjadwalannya sendiri (waktu eksekusi yang diharapkan dalam skenario penjadwalan) tetapi juga pada waktu penyelesaian tugas leluhurnya. Tugas turunan tidak dijalankan meskipun waktu penjadwalannya lebih awal daripada tugas leluhur jika tugas leluhur belum menyelesaikan eksekusinya. Untuk informasi selengkapnya tentang kondisi eksekusi tugas, lihat Diagnosis eksekusi tugas.
Konfigurasikan dependensi penjadwalan
Dependensi tugas di DataWorks pada akhirnya dirancang untuk memastikan bahwa node turunan mengambil data dengan benar, yang dalam praktiknya berarti mereka bergantung pada alur data antara tabel leluhur dan turunan. Anda dapat memilih apakah akan mengonfigurasi dependensi penjadwalan berdasarkan alur data sesuai kebutuhan bisnis Anda. Proses mengonfigurasi dependensi penjadwalan node adalah sebagai berikut.

Dependensi menyiratkan hubungan alur data yang kuat, artinya output node turunan bergantung pada output node leluhur. Sebelum mengonfigurasi dependensi, pastikan hubungan ini diperlukan. Tanyakan: "Apakah tugas akan gagal atau menghasilkan data salah jika data leluhurnya belum siap?" Jika ya, maka dependensi kuat tersebut ada.
Langkah | Deskripsi |
① | Untuk menghindari waktu eksekusi tak terduga untuk tugas saat ini, pertama-tama evaluasi apakah terdapat dependensi kuat antar tabel untuk menentukan apakah Anda perlu mengonfigurasi dependensi penjadwalan berdasarkan alur data. |
② | Pastikan apakah datanya berasal dari tabel yang dihasilkan oleh Tugas Terpicu Otomatis. DataWorks tidak dapat memantau produksi data melalui status eksekusi tugas untuk tabel yang tidak dihasilkan oleh penjadwal berulangnya. Oleh karena itu, dependensi penjadwalan tidak dapat dikonfigurasi untuk beberapa tabel. Tabel yang tidak dihasilkan oleh penjadwal berulang DataWorks meliputi, namun tidak terbatas pada, jenis berikut:
|
③④ | Bergantung pada apakah Anda perlu bergantung pada data kemarin atau hari ini dari leluhur, atau apakah tugas per jam atau per menit perlu bergantung pada instance sebelumnya, pilih untuk bergantung pada siklus yang sama atau siklus sebelumnya dari leluhur.
Catatan Untuk detail tentang mengonfigurasi skenario dependensi berdasarkan alur data, lihat Pilih metode dependensi penjadwalan (dependensi siklus yang sama). |
⑤⑥⑦ | Setelah mengonfigurasi dependensi dan mempublikasikannya ke lingkungan produksi, Anda dapat memeriksa hubungan dependensi tugas di Auto Triggered Task di Operation Center untuk memverifikasi kebenarannya. |
Konfigurasikan dependensi node kustom
Jika tidak terdapat dependensi alur data kuat antar tugas di DataWorks (misalnya, tugas tidak bergantung kuat pada partisi tertentu dari leluhur tetapi hanya mengambil partisi terbaru saat ini), atau jika data yang digantungkan bukan berasal dari tabel yang dihasilkan oleh Tugas Terpicu Otomatis (misalnya, data tabel yang diunggah secara lokal), Anda dapat menyesuaikan dependensi node tersebut. Konfigurasi dependensi kustom adalah sebagai berikut:
Bergantung pada node root ruang kerja
Untuk skenario seperti tugas sinkronisasi di mana data sumber berasal dari database bisnis lain, atau tugas SQL yang memproses data tabel yang dihasilkan oleh tugas sinkronisasi real-time, Anda dapat langsung memilih untuk mengaitkan dependensi ke node root ruang kerja.
Bergantung pada node beban nol
Saat ruang kerja berisi banyak proses bisnis kompleks, Anda dapat menggunakan node beban nol untuk mengelolanya. Dengan mengaitkan dependensi node yang memerlukan kontrol terpadu ke node beban nol tertentu, Anda dapat membuat jalur alur data dalam ruang kerja menjadi lebih jelas. Misalnya, Anda dapat mengontrol waktu penjadwalan keseluruhan atau mengaktifkan/menonaktifkan penjadwalan (membekukan) seluruh proses bisnis.
Parameter output node
Anda dapat meneruskan nilai dari node leluhur ke node turunan. Untuk melakukannya, definisikan parameter output di node leluhur, lalu buat parameter input di node turunan yang mereferensinya.
Penting
output parameter node hanya dapat digunakan sebagai parameter input untuk node turunan (Anda menambahkan parameter di bagian parameter penjadwalan node turunan dan mengikatnya ke parameter leluhur dengan mengklik ikon
 ). Beberapa node tidak dapat langsung meneruskan hasil kueri ke node turunan. Jika Anda perlu meneruskan hasil kueri dari node leluhur ke node turunan, Anda dapat menggunakan node assignment. Untuk informasi selengkapnya, lihat Node assignment.
). Beberapa node tidak dapat langsung meneruskan hasil kueri ke node turunan. Jika Anda perlu meneruskan hasil kueri dari node leluhur ke node turunan, Anda dapat menggunakan node assignment. Untuk informasi selengkapnya, lihat Node assignment.Node yang mendukung parameter output adalah: node
EMR Hive,EMR Spark SQL,ODPS Script,Hologres SQL,AnalyticDB for PostgreSQL, danMySQL.
Konfigurasikan parameter output node
Nilai Node Output Parameter dapat berupa Constant atau Variable.
Setelah mendefinisikan parameter output dan mengirimkan node saat ini, Anda dapat Bind The Output Parameter Of The Ancestor Node sebagai parameter input untuk node turunan saat mengonfigurasi parameter penjadwalannya.
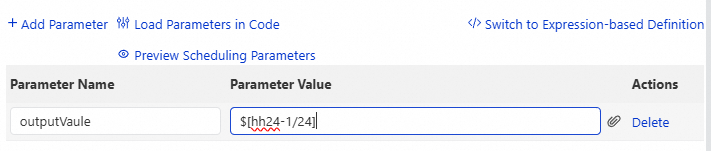
Nama parameter: Nama parameter output yang didefinisikan.
Nilai parameter: Nilai parameter output. Jenis nilainya meliputi konstanta dan variabel:
Konstanta adalah string tetap.
Variabel mencakup variabel global yang didukung sistem, parameter penjadwalan bawaan, dan parameter kustom.
Konfigurasi peran terkait untuk node
Linked role DataWorks memungkinkan Anda menetapkan peran RAM preset ke node tugas tertentu. Saat tugas dijalankan, tugas tersebut secara dinamis memperoleh kredensial akses temporary untuk peran tersebut melalui Alibaba Cloud Security Token Service (STS). Hal ini memungkinkan kode Anda mengakses sumber daya cloud lain tanpa perlu menyertakan AccessKey (AK) permanen dalam teks biasa.
Batasan kelompok sumber daya: Hanya didukung untuk node yang dijalankan pada kelompok sumber daya Serverless.
Batasan jenis node: Hanya didukung untuk node Python, Shell, Notebook, PyODPS 2, dan PyODPS 3.
1. Konfigurasikan linked role di node DataWorks
Di sisi kanan halaman pengeditan node, temukan dan klik Run Configuration.
Di panel pengaturan penjadwalan, alihkan ke tab Linked Role.
Dari daftar drop-down RAM Role, pilih peran RAM yang telah Anda siapkan.
PentingJika daftar drop-down kosong atau Anda tidak menemukan peran yang diperlukan, lihat Konfigurasikan linked role untuk mengakses layanan cloud lain menggunakan STS guna menyelesaikan konfigurasi peran RAM.
Setelah konfigurasi selesai, kirimkan node tersebut. Konfigurasi ini hanya berlaku untuk debug runs.
2. Peroleh dan gunakan kredensial temporary di kode Anda
Setelah Anda mengonfigurasi linked role, DataWorks menyuntikkan kredensial temporary yang diperoleh ke lingkungan runtime saat tugas dijalankan. Anda dapat memperolehnya di kode Anda dengan dua cara berikut.
Metode 1: Baca variabel lingkungan (direkomendasikan untuk Shell dan Python)
Sistem secara otomatis menetapkan tiga variabel lingkungan berikut. Anda dapat membacanya langsung di kode Anda.
LINKED_ROLE_ACCESS_KEY_ID: ID AccessKey temporary.LINKED_ROLE_ACCESS_KEY_SECRET: Rahasia AccessKey temporary.LINKED_ROLE_SECURITY_TOKEN: Token keamanan temporary.
Contoh kode (Python):
Untuk kasus ini, Anda harus memilih gambar Python kustom dengan oss2 yang diinstal untuk lingkungan runtime. Untuk informasi selengkapnya, lihat Gambar kustom.
import os
import oss2
# 1. Peroleh kredensial temporary dari variabel lingkungan.
access_key_id = os.environ.get('LINKED_ROLE_ACCESS_KEY_ID')
access_key_secret = os.environ.get('LINKED_ROLE_ACCESS_KEY_SECRET')
security_token = os.environ.get('LINKED_ROLE_SECURITY_TOKEN')
# Periksa apakah kredensial berhasil diperoleh.
if not all([access_key_id, access_key_secret, security_token]):
raise Exception("Gagal memperoleh kredensial linked role dari variabel lingkungan.")
# 2. Gunakan kredensial temporary untuk menginisialisasi klien OSS.
# Asumsikan Anda telah memberikan izin peran untuk mengakses 'your-bucket-name'.
auth = oss2.StsAuth(access_key_id, access_key_secret, security_token)
bucket = oss2.Bucket(auth, 'http://oss-<regionID>-internal.aliyuncs.com', 'your-bucket-name')
# 3. Gunakan klien untuk mengakses sumber daya OSS.
try:
# Daftar objek dalam bucket.
for obj in oss2.ObjectIterator(bucket):
print('object name: ' + obj.key)
print("Berhasil mengakses OSS dengan linked role.")
except oss2.exceptions.OssError as e:
print(f"Error mengakses OSS: {e}")Contoh kode (Shell):
#!/bin/bash
access_key_id=${LINKED_ROLE_ACCESS_KEY_ID}
access_key_secret=${LINKED_ROLE_ACCESS_KEY_SECRET}
security_token=${LINKED_ROLE_SECURITY_TOKEN}
# Untuk mengakses OSS, ganti regionID, bucket_name, dan file_name dengan informasi aktual Anda.
echo "ID: "$access_key_id
echo "token: "$security_token
ls -al /home/admin/usertools/tools/
# Contoh ini menunjukkan cara menggunakan ossutil untuk mengunduh file dari path OSS tertentu ke file lokal test_dw.py lalu mencetak isi file tersebut.
/home/admin/usertools/tools/ossutil64 cp --access-key-id $access_key_id --access-key-secret $access_key_secret --sts-token $security_token --endpoint http://oss-<regionID>-internal.aliyuncs.com oss://<bucket_name>/<file_name> test_dw.py
echo "************************ Sukses ************************, mencetak hasil"
cat test_dw.pyMetode 2: Gunakan Credentials Client (direkomendasikan untuk Python)
Contoh kode (Python):
Untuk kasus ini, Anda harus memilih gambar Python kustom dengan oss2 dan alibabacloud_credentials yang diinstal untuk lingkungan runtime. Untuk informasi selengkapnya, lihat Gambar kustom.
from alibabacloud_credentials.client import Client as CredentialClient
import oss2
# 1. Gunakan SDK untuk memperoleh kredensial secara otomatis.
# SDK secara otomatis mencari informasi kredensial seperti LINKED_ROLE_* di variabel lingkungan.
cred_client = CredentialClient()
credential = cred_client.get_credential()
access_key_id = credential.get_access_key_id()
access_key_secret = credential.get_access_key_secret()
security_token = credential.get_security_token()
if not all([access_key_id, access_key_secret, security_token]):
raise Exception("Gagal memperoleh kredensial linked role melalui SDK.")
# 2. Gunakan kredensial untuk menginisialisasi klien OSS.
auth = oss2.StsAuth(access_key_id, access_key_secret, security_token)
bucket = oss2.Bucket(auth, 'http://oss-cn-hangzhou.aliyuncs.com', 'your-bucket-name')
# 3. Akses OSS.
print("Mencantumkan objek dalam bucket...")
for obj in oss2.ObjectIterator(bucket):
print(' - ' + obj.key)
print("Berhasil mengakses OSS dengan linked role melalui SDK.")3. Jalankan dan verifikasi tugas
Shell dan Python: Saat tugas dijalankan, tugas tersebut menggunakan peran RAM yang ditentukan untuk mengakses layanan cloud lain.
PyODPS: Saat mengakses layanan cloud lain seperti OSS, tugas menggunakan identitas peran RAM yang Anda tetapkan. Namun, saat mengakses data MaxCompute, tugas tetap secara otomatis menggunakan identitas akses yang dikonfigurasi untuk sumber daya komputasi di tingkat proyek.
Konfigurasikan properti penjadwalan
Setelah selesai men-debug node, Anda harus menyinkronkan Run Configuration di Run Configurations ke pengaturan di Scheduling Configurations. Setelah dipublikasikan, tugas akan dijalankan sebagai peran tersebut.
Jika Anda mengonfigurasi gambar kustom di Run Configuration, Anda juga harus menyinkronkan pengaturan ini ke pengaturan penjadwalan.
Lihat peran eksekusi di Operation Center
Setelah tugas dijalankan, lihat detail instance tugas di Operation Center untuk memastikan peran yang ditentukan telah digunakan.
Buka .
Temukan instance node yang telah Anda jalankan dan klik untuk membuka halaman detailnya.
Di bagian Properties halaman detail instance, lihat bidang Execution Identity. Bidang ini menampilkan Nama Sumber Daya Alibaba Cloud (ARN) dari linked role yang benar-benar digunakan dalam eksekusi tersebut.
ARN adalah pengidentifikasi sumber daya unik. Untuk informasi selengkapnya, lihat Elemen dasar kebijakan.
Referensi
Parameter penjadwalan: Referensi format parameter penjadwalan.
Kebijakan penjadwalan:
Waktu penjadwalan: Referensi waktu penjadwalan.
Dependensi penjadwalan:
Parameter output node: Konfigurasikan dan gunakan parameter konteks node.
Referensi lain: Dampak perubahan waktu daylight saving terhadap eksekusi tugas terjadwal.