Gunakan pernyataan SQL untuk melakukan kueri dan menganalisis data secara cepat dari sumber seperti MaxCompute, EMR Hive, dan Hologres. Topik ini menjelaskan cara menjalankan kueri SQL terhadap sumber data.
Dokumen ini berlaku untuk versi baru DataAnalysis. Untuk versi sebelumnya, lihat kueri SQL (Lama). Anda dapat beralih antara versi baru dan lama DataAnalysis menggunakan bilah navigasi.
Sumber data yang didukung
Kueri SQL mendukung jenis sumber data berikut: MaxCompute, Hologres, EMR, CDH, ADB for PostgreSQL, ADB for MySQL, ClickHouse, StarRocks, MySQL, PostgreSQL, Oracle, SQL Server, Doris, dan SelectDB.
Hanya MaxCompute yang mendukung koneksi langsung maupun koneksi melalui sumber data. Semua jenis sumber data lain hanya mendukung koneksi ke sumber data yang telah ditambahkan ke ruang kerja Anda.
Izin akses sumber data
Cakupan sumber data
Mode koneksi sumber data: Anda hanya dapat memilih data dari sumber data dalam ruang kerja tempat Anda memiliki izin yang sesuai. Administrator ruang kerja harus terlebih dahulu menambahkan Anda ke ruang kerja sebagai Data Analyst, Developer, O&M Engineer, atau Workspace Administrator.
Mode koneksi langsung: Anda hanya dapat memilih proyek MaxCompute yang telah bergabung dengan Akun Alibaba Cloud Anda saat ini. Untuk informasi lebih lanjut mengenai izin proyek MaxCompute, lihat pengguna dan izin MaxCompute.
Izin akses sumber data
Anda dapat mengakses sumber data menggunakan salah satu dari dua mode identitas berikut.
Access Identity Mode | Deskripsi | Sumber data yang didukung | Otorisasi |
Executor identity | Identitas Akun Alibaba Cloud yang sedang masuk ke DataWorks. | MaxCompute dan Hologres. | Minta administrator proyek MaxCompute atau instans Hologres yang ditentukan untuk memberikan Anda izin akses sebagai anggota. |
Default access identity of the data source | Identitas akses yang dikonfigurasi saat sumber data dibuat. | Semua sumber data yang didukung oleh fitur ini. | Jika akun Anda saat ini bukan identitas akses default untuk sumber data tersebut, mintalah pengguna dengan izin Workspace Administrator untuk memberikan izin kepada Akun Alibaba Cloud Anda saat ini. |
Jika daftar putih alamat IP diaktifkan untuk proyek MaxCompute, tambahkan daftar putih DataAnalysis ke daftar putih alamat IP proyek MaxCompute tersebut.
Akses fitur
Masuk ke Konsol DataAnalysis DataWorks, alihkan ke wilayah tujuan, lalu klik Go to DataAnalysis.
Jika Anda melihat Go to New DataAnalysis di bilah navigasi, klik untuk beralih ke versi baru.
Jika Anda melihat Back to Old DataAnalysis di bilah navigasi, berarti Anda sudah berada di halaman versi baru.
Buat kueri SQL
Arahkan kursor ke dan klik
 > New SQL File di sebelah kanan.
> New SQL File di sebelah kanan.Anda juga dapat mengklik New Folder untuk membuat struktur folder kustom bagi file kueri SQL Anda.
Pada halaman editor SQL, tulis pernyataan kueri SQL Anda.
PentingAnda juga dapat menghasilkan pernyataan SQL dengan cara berikut:
Di halaman Katalog Data, setelah Anda menambahkan katalog data, temukan tabel target, klik kanan, lalu pilih Generate Query SQL.
Salin kueri SQL yang dibagikan kepada Anda dari folder Shared Files.
Setelah mengedit SQL, klik tombol Format di bagian atas untuk memformat kode.
Kueri SQL mendukung Copilot. Klik ikon Copilot (
 ) di pojok kanan atas bilah navigasi untuk menggunakan fitur seperti generasi kode dan koreksi kode guna membantu menyelesaikan kode Anda. Copilot juga mendukung penyelesaian kode otomatis di editor untuk meningkatkan efisiensi penulisan Anda.
) di pojok kanan atas bilah navigasi untuk menggunakan fitur seperti generasi kode dan koreksi kode guna membantu menyelesaikan kode Anda. Copilot juga mendukung penyelesaian kode otomatis di editor untuk meningkatkan efisiensi penulisan Anda.
Setelah menulis kode kueri SQL, klik Run Settings di sebelah kanan. Konfigurasikan Data Source, Script Parameters, dan pengaturan lainnya untuk kueri SQL tersebut.
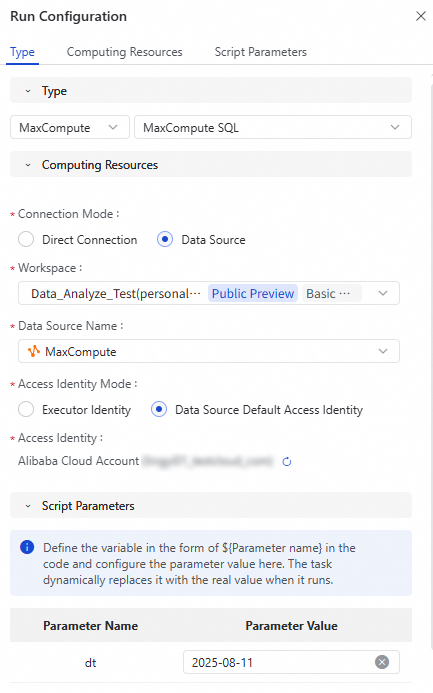
Type: Pilih jenis sumber data target untuk kueri SQL sesuai kebutuhan.
Computing Resource: Konfigurasikan sumber data target untuk kueri SQL. Hanya kueri MaxCompute yang mendukung koneksi langsung atau koneksi melalui sumber data. Jenis sumber data lain hanya mendukung kueri data dari sumber data dalam ruang kerja tempat Anda memiliki izin. Untuk informasi lebih lanjut mengenai izin, lihat Izin akses sumber data.
Script Parameters: Jika kueri SQL Anda berisi variabel parameter, tetapkan nilainya di sini saat waktu proses.
PentingJika penguraian gagal, buka Management > Settings di pojok kiri bawah. Cari parsing dan aktifkan item konfigurasi Enable dataworks Isp code parameter function.
Di bilah alat bagian atas halaman Editor SQL, klik Run. Klik ikon drop-down
 di sebelah kanan tombol Run untuk mengganti mode eksekusi. Pilih mode sesuai skenario Anda.
di sebelah kanan tombol Run untuk mengganti mode eksekusi. Pilih mode sesuai skenario Anda.Mode eksekusi
Skenario pengguna
Kondisi pemicu
Engine yang Berlaku
Query mode (LIMIT 10000)
Pratinjau data secara cepat dan validasi logika kueri. Cocok untuk eksplorasi data awal ketika Anda hanya perlu melihat sampel hasil yang kecil.
Hasil kueri menampilkan ≤ 10.000 baris dan ≤ 10 MB
Tidak ada batasan
Demand mode (full data)
Dapatkan set hasil lengkap untuk analisis atau ekspor. Sistem secara otomatis memicu mode ini saat Anda perlu memproses dan melihat seluruh data.
Hasil kueri menampilkan > 10.000 baris atau > 10 MB
Tidak ada batasan
Temporary table mode
Gunakan kembali hasil dalam kueri kompleks multi-langkah. Gunakan output dari satu kueri sebagai input untuk kueri berikutnya guna meningkatkan efisiensi pengembangan dan debugging.
Hasil kueri menampilkan ≤ 10.000 baris dan ≤ 10 MB, serta secara otomatis ditulis ke tabel temporary
Hanya MaxCompute
Setelah eksekusi SQL selesai, Anda dapat melihat Operational Log, Results, dan konten SQL yang sesuai di halaman hasil kueri.
Klik tombol di pojok kanan atas hasil kueri untuk mengganti tata letak halaman antara tampilan berdampingan dan tampilan atas-bawah.
Visualisasikan hasil kueri
Di bilah alat sebelah kiri hasil kueri, klik tombol  untuk menghasilkan grafik visual secara otomatis dari hasil tersebut.
untuk menghasilkan grafik visual secara otomatis dari hasil tersebut.
Klik tombol Copilot di atas grafik untuk menggunakan fitur generasi grafik cerdas dan insight DataWorks Copilot.
Klik tombol Edit Chart untuk menyesuaikan gaya grafik.
Ekspor dan bagikan
Untuk mengekspor data ke file lokal lalu mengimpornya ke sumber data lain, gunakan tugas sinkronisasi offline di Data Integration. Metode ini menyediakan migrasi dan sinkronisasi data yang lebih efisien dan stabil.
Di sisi kanan hasil kueri SQL, klik Export. Opsi ekspor berikut didukung:
Local File: Mengunduh hasil kueri ke komputer lokal Anda sebagai file CSV. Poin-poin penting sebagai berikut:
Item
Deskripsi
Batas unduh
Hanya mesin MaxCompute dan EMR yang didukung. Untuk informasi lebih lanjut, lihat Batas unduh data.
Jika mekanisme perlindungan data diaktifkan untuk proyek MaxCompute (yang melarang pengunduhan data), pengunduhan data melalui DataAnalysis akan gagal.
Download scope
Anda dapat memilih untuk mengunduh Only data displayed in the table atau All data.
Only data displayed in the table: Mengunduh hanya data yang ditampilkan di halaman saat ini, dengan batas maksimum default
10000baris.All data: Mengekspor seluruh hasil kueri dalam batas ekspor.
Metode unduh
Mendukung Download with Approval dan Download without Approval.
Download with Approval: Memungkinkan Anda mengidentifikasi risiko dalam operasi pengunduhan data dengan menetapkan aturan Pendeteksian Penipuan. Saat mengunduh data, Anda harus mengajukan permintaan persetujuan unduh untuk memastikan kepatuhan dan keamanan data.
CatatanHanya Edisi Perusahaan DataWorks yang mendukung pengaturan dan pengaktifan aturan Pendeteksian Penipuan.
Download without Approval: Ini adalah metode default. Tidak diperlukan permintaan izin selama proses pengunduhan.
Object Storage Service (OSS): Mengekspor hasil kueri ke bucket Object Storage Service (OSS) Alibaba Cloud dalam format tertentu, seperti CSV atau Parquet. Opsi ini cocok untuk pengarsipan volume data besar atau integrasi dengan produk cloud lainnya.
Pertama kali menggunakan fitur ini, berikan izin DataWorks untuk mengakses sumber daya OSS Anda. Di daftar drop-down File Path, klik tautan one-click authorization dalam prompt dan ikuti petunjuk di layar untuk menyelesaikan otorisasi RAM.
Item konfigurasi
Deskripsi
File path
Klik tombol folder di sebelah kanan untuk memilih Bucket OSS dan direktori tempat Anda ingin menyimpan file hasil.
File name
Sistem secara otomatis menghasilkan nama file. Anda juga dapat mengubahnya secara manual.
Text Type
Pilih format file untuk ekspor. Format yang didukung termasuk
csv,text,orc, danparquet.Separator
Tentukan pembatas antar kolom. Nilai default adalah koma (
,).Encoding format
Pilih format encoding untuk file, seperti
UTF-8atauGBK.CU
Konfigurasikan jumlah unit komputasi (CU) untuk tugas ekspor ini. Nilai default adalah 1 CU.
Resource group
Pilih kelompok sumber daya Serverless untuk menjalankan tugas ekspor ini. Jika tidak dipilih, kelompok sumber daya integrasi data yang ditetapkan di DataAnalysis > System Administration akan digunakan secara default.
Setelah menyelesaikan konfigurasi, klik OK untuk memulai tugas ekspor. Anda dapat melihat progres ekspor, log operasional, dan detail konfigurasi di halaman tugas yang sedang berjalan. Setelah tugas berhasil, buka konsol OSS untuk mengunduh file objek yang diekspor ke komputer lokal Anda.
DingTalk Sheet: Anda dapat mengekspor hasil ke DingTalk Sheet.
Workbook/Workbook and Share: Anda dapat menyimpan hasil ke buku kerja untuk analisis data kueri lebih lanjut. Anda juga dapat membagikan hasil analisis terbaru dari buku kerja tersebut kepada orang lain.