Fitur sinkronisasi database penuh batch di DataWorks memungkinkan Anda menyinkronkan skema dan data seluruh database atau tabel tertentu dari sumber ke tujuan. Anda dapat melakukan sinkronisasi penuh atau inkremental secara berkala, yang menyediakan solusi efisien untuk migrasi data. Topik ini menjelaskan alur kerja umum untuk mengonfigurasi jenis tugas ini, dengan contoh migrasi seluruh database MySQL ke MaxCompute.
Prasyarat
Persiapan data source
Buat Data Source sumber dan tujuan. Untuk informasi lebih lanjut tentang cara mengonfigurasi Data Source, lihat Manajemen Data Source.
Pastikan Data Source mendukung sinkronisasi database penuh batch. Untuk informasi lebih lanjut, lihat Data source yang didukung.
Resource group: Beli dan konfigurasikan Serverless Resource Group.
Konektivitas jaringan: Bangun konektivitas jaringan antara Resource Group dan Data Source.
Lingkup
Anda dapat mengonfigurasi tugas sinkronisasi database penuh batch baik di DataStudio maupun di Data Integration. Fungsionalitas keduanya saling terhubung.
Konfigurasi konsisten: Antarmuka konfigurasi, pengaturan parameter, dan fitur dasar sama, baik Anda membuat tugas di Data Studio maupun Data Integration.
Sinkronisasi dua arah: Sistem secara otomatis menyinkronkan tugas yang dibuat di Data Integration ke direktori
data_integration_jobsdi Data Studio dan mengkategorikannya berdasarkan saluranjenis sumber-jenis tujuanuntuk manajemen terpadu.
Konfigurasi tugas sinkronisasi
Langkah 1: Buat tugas sinkronisasi
Masuk ke Konsol DataWorks. Pada bilah navigasi atas, pilih Wilayah yang diinginkan. Di panel navigasi sebelah kiri, pilih . Pada halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar tarik-turun, lalu klik Go to Data Integration.
Di panel navigasi kiri, klik Synchronization Task. Pada halaman yang muncul, klik Create Synchronization Task dan konfigurasikan informasi tugas.
Data Source Type:
MySQL.Data Source Type:
MaxCompute.Specific Type:
Batch full-database.Synchronization Mode: Pengaturan Synchronization steps dan Full and Incremental Control saling terkait. Anda dapat menggabungkan pengaturan ini untuk membuat solusi sinkronisasi yang berbeda. Untuk informasi lebih lanjut, lihat Full and Incremental Control.
Schema Migration: Secara otomatis membuat objek database (seperti tabel, bidang, dan tipe data) di tujuan yang sesuai dengan sumber, tetapi tidak mencakup data.
Full Synchronization (Opsional): Menyalin semua data historis dari objek sumber yang ditentukan (seperti tabel) ke tujuan dalam satu operasi. Biasanya digunakan untuk migrasi data awal atau inisialisasi.
Incremental Sync (Opsional): Setelah sinkronisasi penuh selesai, langkah ini terus-menerus menangkap dan menyinkronkan data baru dari sumber ke tujuan berdasarkan Incremental Condition.
Langkah 2: Konfigurasi data source dan resource waktu proses
Di bagian Source Data Source, pilih Data Source
MySQLdari ruang kerja. Di bagian Destination, pilih Data SourceMaxCompute.Di bagian Running Resources, pilih Resource Group untuk tugas sinkronisasi dan alokasikan Resource Group CUs. Jika tugas sinkronisasi Anda mengalami masalah Out of Memory (OOM) karena sumber daya tidak mencukupi, sesuaikan nilai penggunaan Resource Group CUs tersebut.
Pastikan kedua Data Source, baik sumber maupun tujuan, lulus Connectivity Check.
Langkah 3: Konfigurasi rencana sinkronisasi
1. Konfigurasi sumber
Pada langkah ini, pilih tabel yang akan disinkronkan dari area Source database and table dan klik ikon ![]() untuk memindahkannya ke area Selected di sebelah kanan.
untuk memindahkannya ke area Selected di sebelah kanan.
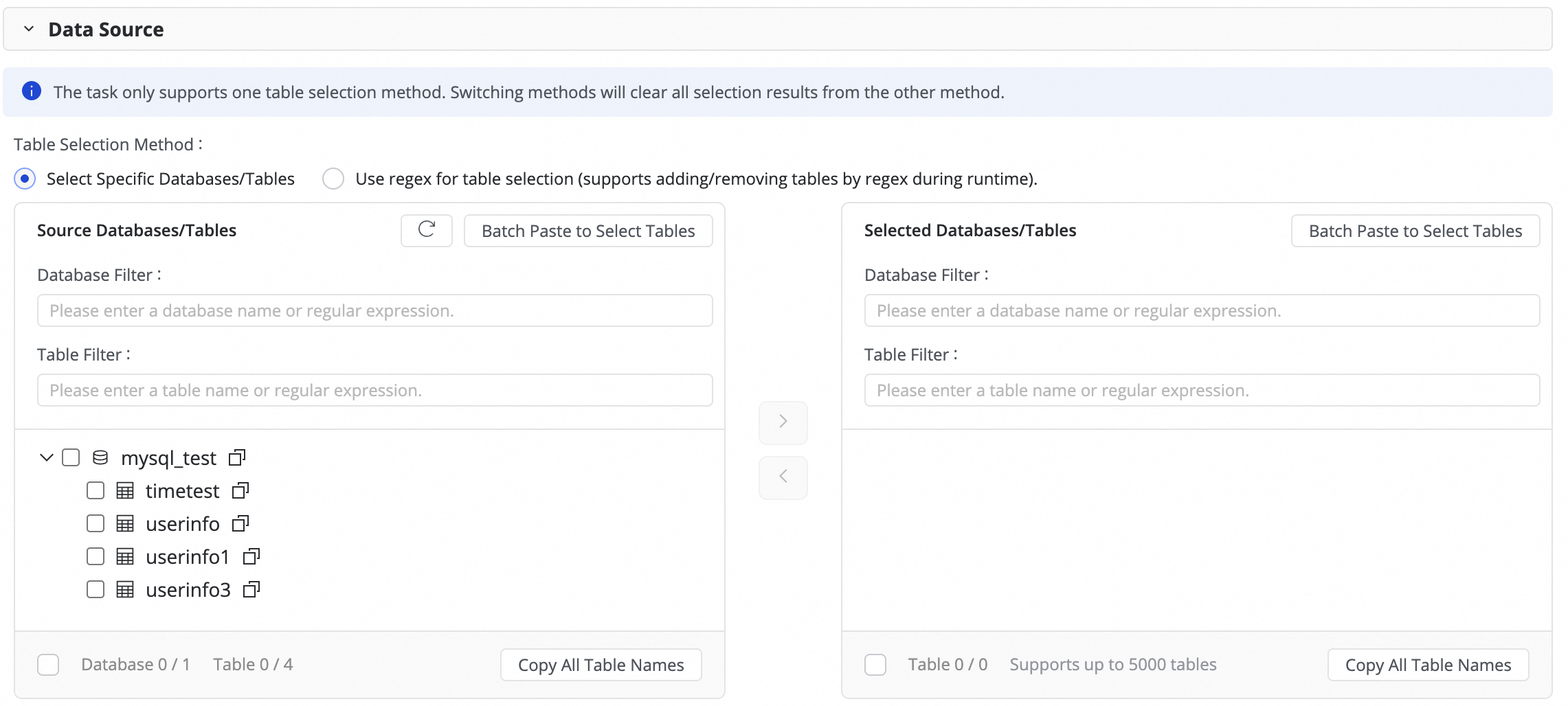
Jika terdapat banyak database dan tabel, Anda dapat menggunakan Database Filtering atau Table filtering serta mengonfigurasi ekspresi reguler untuk memilih tabel yang ingin disinkronkan.
2. Konfigurasi tujuan
Klik tombol Configuration di samping Partition Initialization Configuration untuk mengatur pengaturan partisi awal default untuk tabel tujuan baru. Perubahan yang dilakukan di sini akan menimpa pengaturan partisi untuk semua tabel tujuan baru, tetapi tidak memengaruhi tabel yang sudah ada.
3. Konfigurasi rencana (Kontrol penuh dan inkremental)
Konfigurasi frekuensi eksekusi tugas.
Jika Anda memilih Full Synchronization atau Incremental Synchronization: Anda dapat memilih untuk menjalankan tugas sebagai tugas One-time atau Recurring.
Jika Anda memilih Full Synchronization dan Incremental Synchronization: Sistem menggunakan mode bawaan One-time full sync first, then recurring incremental sync. Opsi ini tidak dapat diubah.
Synchronization steps
Full and incremental control
Data writing behavior
Use cases
Full Synchronization
One-time
Setelah tugas dimulai, tugas tersebut menyinkronkan semua data dari tabel sumber ke tabel tujuan atau partisi tertentu dalam satu kali jalan.
Inisialisasi data, migrasi sistem.
Recurring
Berdasarkan Siklus Penjadwalan yang dikonfigurasi, tugas tersebut secara berkala menyinkronkan semua data dari tabel sumber ke tabel tujuan atau partisi tertentu.
Rekonsiliasi data, snapshot lengkap T+1.
Incremental Synchronization
One-time
Setelah tugas dimulai, tugas tersebut menyinkronkan data inkremental sekali ke partisi tertentu berdasarkan Incremental Condition Anda.
Memperbaiki manual batch data tertentu.
Recurring
Setelah tugas dimulai, tugas tersebut secara berkala menyinkronkan data inkremental ke partisi tertentu berdasarkan Scheduling Cycle dan Incremental Condition yang dikonfigurasi.
ETL harian, membangun tabel dimensi yang berubah lambat.
Full Synchronization & Incremental Synchronization
(Mode bawaan, tidak dapat dipilih)
Jalankan pertama kali: Secara otomatis melakukan inisialisasi skema satu kali dan sinkronisasi penuh data historis.
Jalankan berikutnya: Berdasarkan Scheduling Cycle dan Incremental Condition yang dikonfigurasi, tugas tersebut secara berkala menyinkronkan data inkremental ke partisi tertentu.
Pemasukan data warehouse atau data lake satu klik.
CatatanUntuk sinkronisasi database penuh batch, sistem menghasilkan instance untuk penjadwalan berkala dengan metode Generate immediately after publishing. Untuk informasi lebih lanjut, lihat Metode pembuatan instance: Generate immediately after publishing.
Anda dapat menentukan cara pembuatan partisi pada langkah Value assignment. Anda dapat menggunakan konstanta atau menghasilkan partisi secara dinamis dengan menggunakan variabel yang telah ditentukan sistem dan parameter penjadwalan berkala.
Konfigurasi untuk Scheduling Cycle, Incremental Condition, dan metode pembuatan partisi saling terkait. Untuk informasi lebih lanjut, lihat 6. Konfigurasi Incremental Condition.
Konfigurasi parameter penjadwalan berkala.
Jika tugas Anda melibatkan sinkronisasi berkala, klik Scheduling Parameters for Periodical Scheduling untuk mengonfigurasinya. Gunakan parameter ini untuk mengonfigurasi Incremental Condition dan Value assignment dalam pemetaan tabel tujuan.
4. Pemetaan tabel tujuan
Pada langkah ini, Anda menentukan aturan pemetaan antara tabel sumber dan tujuan, serta menentukan metode penulisan data menggunakan Recurring Schedule dan Incremental Condition.

Action | Description | ||||||||||||
Refresh mapping | Sistem secara otomatis mencantumkan tabel sumber yang Anda pilih. Namun, Anda harus merefresh pemetaan untuk menerapkan properti spesifik tabel tujuan.
| ||||||||||||
Edit Mapping of Field Data Types (Opsional) | Sistem menyediakan pemetaan default antara tipe bidang sumber dan tujuan. Anda dapat mengklik Edit Mapping of Field Data Types di pojok kanan atas tabel untuk menyesuaikan pemetaan tipe bidang. Setelah dikonfigurasi, klik Apply and Refresh Mapping. Saat mengedit pemetaan tipe bidang, pastikan aturan konversi tipe valid. Jika tidak, kesalahan konversi tipe dapat menghasilkan data kotor dan menyebabkan kegagalan tugas. | ||||||||||||
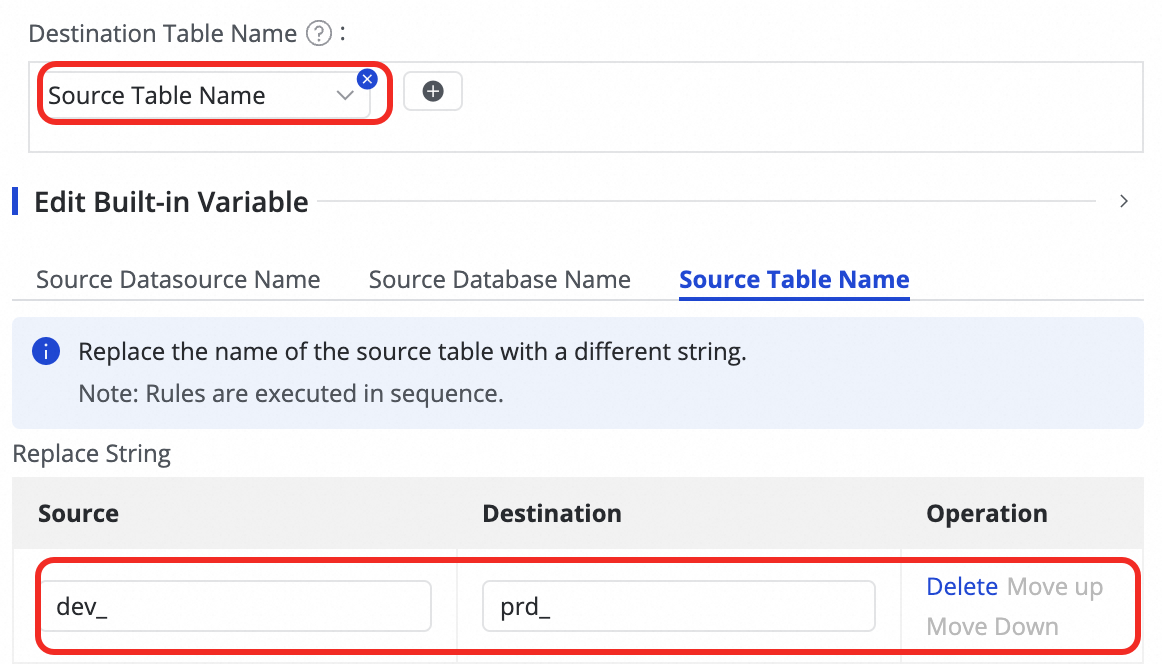
Customize Mapping Rules for Destination Table Names (Opsional) | Sistem memiliki aturan default untuk menghasilkan nama tabel:
Fitur ini mendukung kasus penggunaan berikut:
| ||||||||||||
Customize mapping rules for destination database names (Opsional) | Jenis Data Source tujuan tertentu, seperti Hologres, memungkinkan Anda menentukan aturan pemetaan untuk database tujuan. Metode konfigurasinya mirip dengan Customize Mapping Rules for Destination Table Names. | ||||||||||||
Customize mapping rules for destination schema names (Opsional) | Jenis Data Source tujuan tertentu, seperti Hologres, memungkinkan Anda menentukan aturan pemetaan untuk skema tujuan. Metode konfigurasinya mirip dengan Customize Mapping Rules for Destination Table Names. | ||||||||||||
Edit destination table schema (Opsional) | Sistem secara otomatis menghasilkan skema tabel tujuan berdasarkan skema tabel sumber. Dalam kebanyakan kasus, tidak diperlukan intervensi manual. Jika diperlukan, Anda dapat menyesuaikan skema sebagai berikut:
| ||||||||||||
Value assignment | Sistem secara otomatis memetakan bidang standar jika memiliki nama yang sama di tabel sumber dan tujuan. Anda harus menetapkan nilai secara manual untuk bidang partisi dan bidang yang baru ditambahkan. Ikuti langkah-langkah berikut:
Anda dapat menetapkan konstanta dan variabel menggunakan Value Type untuk bidang tabel dan bidang partisi. Mode yang didukung adalah:
Sistem secara otomatis mengganti variabel dan parameter penjadwalan berkala dengan nilai spesifik tanggal saat waktu proses. | ||||||||||||
Set source sharding column | Dari daftar drop-down source sharding column, Anda dapat memilih bidang dari tabel sumber atau memilih Disable. Bidang ini membagi tugas sinkronisasi menjadi beberapa subtugas untuk memungkinkan pembacaan data batch secara konkuren. Kami menyarankan Anda menggunakan primary key tabel sebagai source sharding column. Tipe string, floating-point, dan tanggal tidak didukung. Source sharding column hanya tersedia untuk sumber MySQL. | ||||||||||||
Configure Advanced Parameters | Anda dapat mengatur writer configurations dan runtime configurations untuk setiap subtugas. Ubah parameter ini hanya jika Anda benar-benar memahami tujuannya untuk mencegah masalah tak terduga seperti latensi tugas, konsumsi sumber daya berlebihan yang menghambat tugas lain, atau kehilangan data. | ||||||||||||
Table type | MaxCompute mendukung tabel standar, PK Delta Tables, dan Append Delta Tables. Jika tabel tujuan belum dibuat, Anda dapat memilih tipe tabel saat mengedit skema tabel tujuan. Anda tidak dapat mengubah tipe tabel yang sudah ada. Untuk informasi lebih lanjut tentang Delta Tables, lihat Delta Table. |
 dan menggabungkan nilai dari Manually enter dan Built-in Variable. Variabel tersebut mencakup nama Data Source sumber, nama database sumber, dan nama tabel sumber.
dan menggabungkan nilai dari Manually enter dan Built-in Variable. Variabel tersebut mencakup nama Data Source sumber, nama database sumber, dan nama tabel sumber.



 di kolom Target Table untuk menambahkan bidang.
di kolom Target Table untuk menambahkan bidang. .
.5. Recurring schedule
Jika Anda mengatur Incremental Synchronization ke Recurring, Anda harus mengonfigurasi Recurring Schedule untuk tabel tujuan. Ini mencakup pengaturan seperti Scheduling Frequency, Data Timestamp, dan Resource Group for Scheduling. Konfigurasi penjadwalan untuk tugas sinkronisasi konsisten dengan konfigurasi node di Data Studio. Untuk informasi lebih lanjut tentang parameter tersebut, lihat Konfigurasi penjadwalan node.
Jika tugas sinkronisasi satu kali melibatkan banyak tabel, kami menyarankan Anda mengatur waktu eksekusi secara bergilir saat mengonfigurasi penjadwalan untuk mencegah backlog tugas dan konflik sumber daya.
6. Incremental condition
Jika tugas perlu menyinkronkan data inkremental, Anda harus mengonfigurasi Incremental Condition. Kondisi ini menentukan data mana yang disinkronkan oleh setiap instance terjadwal.
Fungsi dan sintaks
Fungsi: Incremental Condition adalah klausa
WHEREyang memfilter data sumber.Sintaks: Saat mengonfigurasi kondisi, masukkan hanya ekspresi kondisional yang mengikuti kata kunci
WHERE. Jangan sertakan kata kunciWHEREitu sendiri.
Gunakan parameter penjadwalan untuk sinkronisasi inkremental
Untuk menerapkan sinkronisasi inkremental berkala, Anda dapat menggunakan parameter penjadwalan dalam Kondisi Inkremental. Sebagai contoh, konfigurasikan kondisi tersebut sebagai
<span data-tag="ph" id="codeph_rtz_ohk_wy5"><code code-type="xCode" data-tag="code" id="68c36d2fd9h4l">STR_TO_DATE('${bizdate}', '%Y%m%d') <= columnName AND columnName < DATE_ADD(STR_TO_DATE('${bizdate}', '%Y%m%d'), INTERVAL 1 DAY)</span> untuk menyinkronkan data yang dihasilkan pada hari sebelumnya.Menulis ke partisi tertentu
Dengan menggabungkan Incremental Condition dengan bidang partisi tabel tujuan, Anda dapat menulis setiap batch data inkremental ke partisi yang tepat.
Misalnya, jika Incremental Condition diatur seperti pada langkah sebelumnya, Anda dapat mengatur bidang partisi menjadi
ds=${bizdate}dan mempartisi tabel tujuan berdasarkan hari. Dengan cara ini, setiap instance harian hanya menyinkronkan data untuk tanggal yang sesuai dari sumber dan menuliskannya ke partisi tujuan dengan nama yang sama.
Dengan menggabungkan dengan tepat rentang waktu dari Incremental Condition, interval waktu untuk pembuatan partisi, dan Scheduling Cycle dari penjadwalan berkala, Anda dapat membuat pipeline ETL inkremental T+n otomatis yang secara ketat menyelaraskan logika bisnis dengan partisi fisik.
Langkah 4: Konfigurasi pengaturan lanjutan
Parameter lanjutan
Anda dapat memodifikasi parameter lanjutan untuk menyesuaikan tugas dan memenuhi kebutuhan sinkronisasi kustom.
Di pojok kanan atas halaman, klik Configure Advanced Parameters untuk membuka halaman konfigurasi parameter lanjutan.
Ubah nilai parameter sesuai petunjuk di layar. Setiap parameter mencakup deskripsi fungsinya.
Anda juga dapat menggunakan AI untuk membantu konfigurasi. Masukkan instruksi bahasa alami, seperti menyesuaikan konkurensi tugas, dan model AI akan menghasilkan nilai parameter yang direkomendasikan. Anda kemudian dapat menerima atau menolak parameter yang dihasilkan AI tersebut.
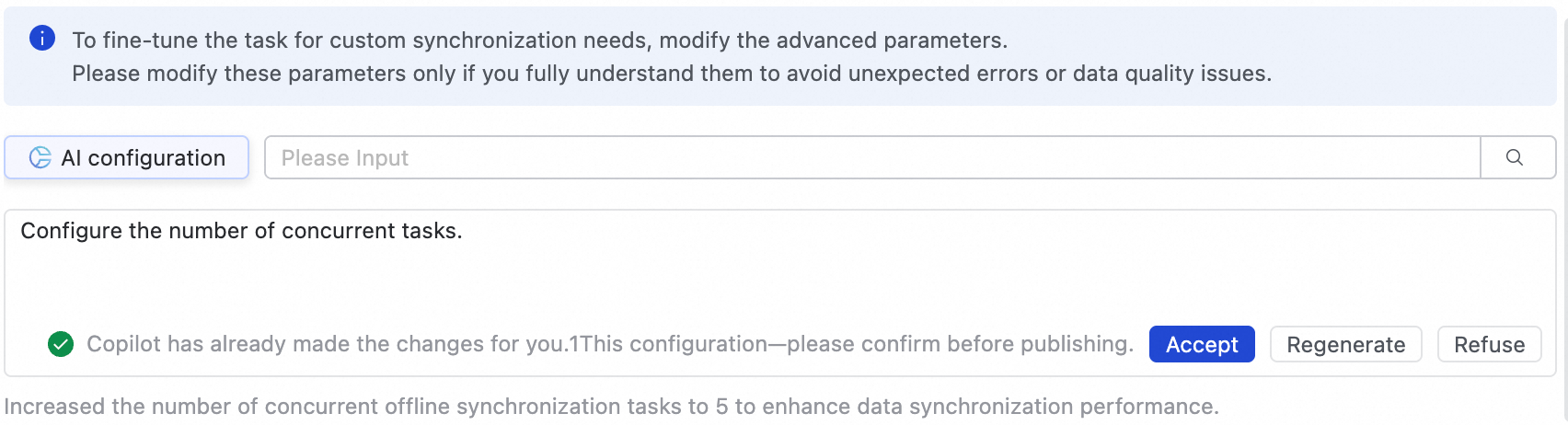
Ubah parameter ini hanya jika Anda benar-benar memahami tujuannya untuk mencegah masalah tak terduga seperti latensi tugas, konsumsi sumber daya berlebihan yang menghambat tugas lain, atau kehilangan data.
Parameter engine
Parameter engine biasanya tidak perlu dikonfigurasi. Jika diperlukan, gunakan hanya dengan panduan ahli. Untuk bantuan, hubungi dukungan teknis.
Langkah 5: Terapkan dan jalankan tugas
Setelah menyelesaikan konfigurasi, klik Save di bagian bawah halaman.
Anda tidak dapat melakukan debug tugas sinkronisasi database penuh batch secara langsung. Anda harus menerapkannya ke Operation Center untuk menjalankannya. Oleh karena itu, Anda harus Deploy tugas baru atau yang telah diedit untuk menerapkan perubahan.
Saat menerapkan tugas, jika Anda memilih Start immediately after deployment, tugas akan mulai berjalan segera setelah diterapkan. Jika tidak, setelah penerapan, Anda harus membuka halaman dan menjalankan tugas secara manual dari kolom Actions.
Di daftar Tasks, klik Name/ID tugas untuk melihat informasi eksekusi terperinci.
Langkah 6: Konfigurasi aturan alert
Anda harus mengonfigurasi aturan alert untuk subtugas yang sesuai dari tugas sinkronisasi database penuh batch di Operation Center.
Di halaman , temukan dan salin Task ID dari tugas target.
Di , gunakan Task ID untuk menemukan subtugas yang sesuai. Misalnya, jika Task ID-nya adalah
34862, subtugas sinkronisasi inkremental mungkin bernamaoffline_odps_cyc_sync_mysql_test_timetest_to_mysql_test_timetest_34862. Di kolom Actions untuk tugas tersebut, klik untuk membuka halaman manajemen aturan.Klik Create Custom Rule dan atur Rule Object, Trigger Method, dan Alert Details. Untuk informasi lebih lanjut, lihat Manajemen aturan.
Anda dapat mencari ID subtugas di bidang Rule Object untuk menemukan tugas target dan mengatur alert untuknya.
Kelola tugas sinkronisasi
Edit tugas
Di halaman , temukan tugas yang ingin diedit. Di kolom Operation, klik More lalu klik Edit. Langkah pengeditan sama dengan langkah konfigurasi awal.
Untuk tugas yang tidak berjalan, Anda dapat memodifikasi konfigurasi, menyimpannya, lalu menerapkannya untuk menerapkan perubahan.
Untuk tugas yang berjalan, jika Anda mengedit dan menerapkannya tanpa memilih Start immediately after deployment, tombol aksi asli berubah menjadi Apply Updates. Anda harus mengklik tombol ini untuk menerapkan perubahan ke lingkungan produksi.
Setelah Anda mengklik Apply Updates, sistem menjalankan proses tiga langkah pada konten yang dimodifikasi: Stop, Deploy, dan Restart.
Jika Anda menambahkan tabel:
Setelah menerapkan pembaruan, sistem menambahkan subtugas sinkronisasi untuk tabel baru tersebut. Schema Migration dan one-time full synchronization untuk subtugas ini dimulai segera. Selanjutnya, Incremental Synchronization berjalan sesuai jadwal.
Jika Anda mengganti tabel tujuan (setara dengan menghapus tabel lama dan menambahkan yang baru):
Setelah menerapkan pembaruan, sistem menghapus subtugas untuk tabel lama dan menghasilkan subtugas untuk tabel baru. Schema Migration dan one-time full synchronization untuk subtugas baru dimulai segera. Tugas baru kemudian melanjutkan sinkronisasi inkremental sesuai jadwal.
Jika Anda memodifikasi informasi lain:
Schema Migration dan one-time full synchronization untuk tabel tidak terpengaruh. Konfigurasi yang diperbarui berlaku untuk instance Incremental Synchronization baru. Tidak memengaruhi instance yang telah dihasilkan sebelumnya.
Proses ini tidak memengaruhi atau menjalankan ulang tabel yang tidak dimodifikasi.
Lihat tugas
Setelah membuat tugas sinkronisasi, Anda dapat melihat daftar tugas yang telah dibuat beserta informasi dasarnya di halaman Synchronization Task.

Di kolom Actions, Anda dapat Start atau Stop tugas sinkronisasi. Di menu More, Anda dapat melakukan tindakan lain seperti Edit dan View.
Untuk tugas yang sedang berjalan, Anda dapat melihat status dasarnya di bagian Execution Overview. Anda juga dapat mengklik area ikhtisar untuk melihat detail eksekusi.
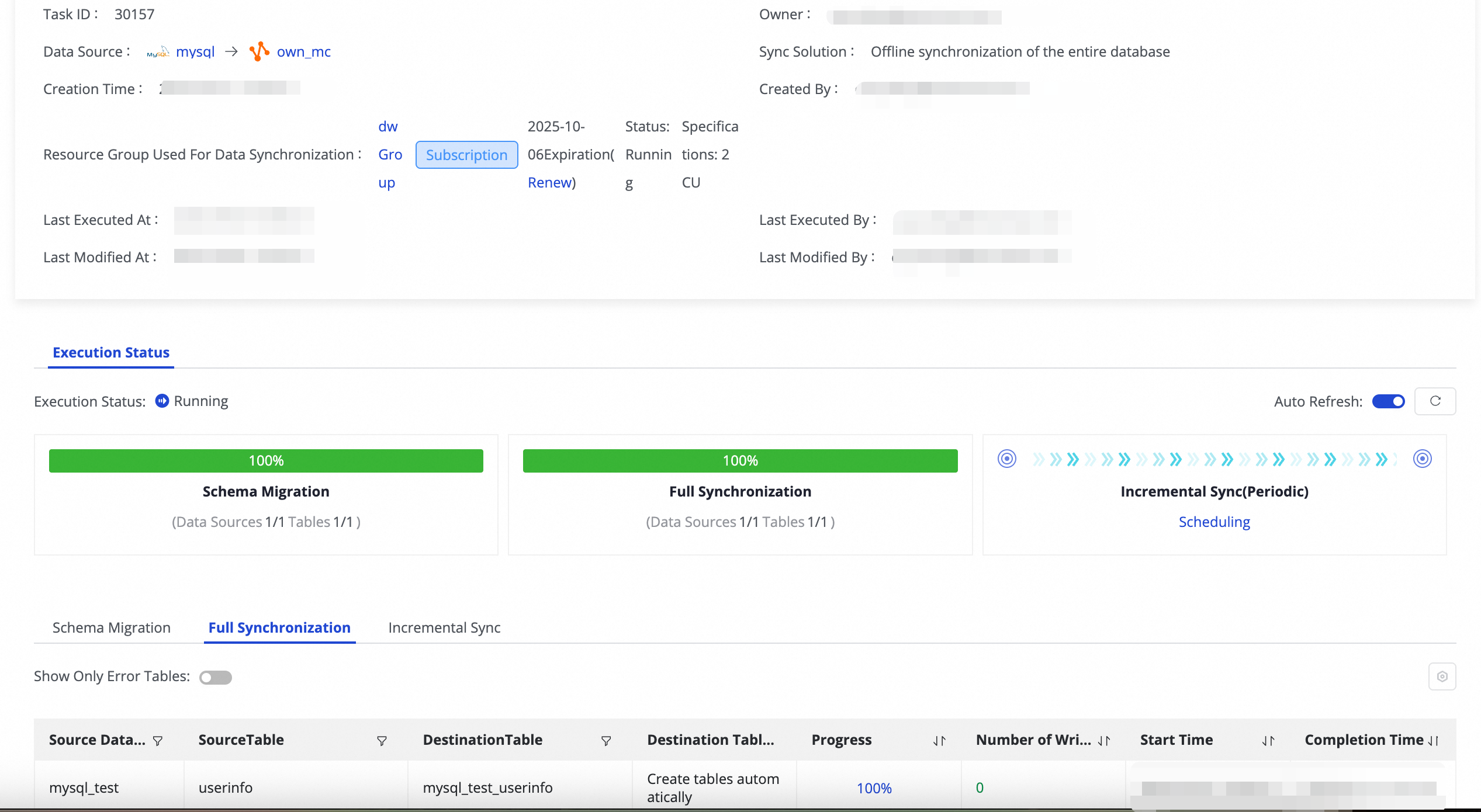
Kuota dan batasan
Batasan debugging: Anda tidak dapat melakukan debug tugas sinkronisasi database penuh batch secara langsung di antarmuka Data Integration atau Data Studio. Anda harus Deploy tugas ke Operation Center untuk menjalankannya.
Batasan kolom sharding: Fitur Set source sharding column saat ini hanya didukung ketika sumbernya adalah MySQL. Bidang kolom sharding harus bertipe numerik; tipe string, floating-point, dan tanggal tidak didukung.
Batasan perubahan skema: Saat Anda Edit destination table schema, Anda tidak dapat mengganti nama kolom. Untuk tabel tujuan yang sudah ada, Anda tidak dapat mengubah Table type.
Langkah selanjutnya
Setelah tugas dimulai, Anda dapat mengklik nama tugas untuk melihat detail eksekusinya dan melakukan operasi dan penyetelan tugas.
FAQ
Untuk pertanyaan umum tentang tugas sinkronisasi database penuh batch, lihat FAQ tentang tugas Sinkronisasi Penuh dan Inkremental.