Topik ini menjelaskan catatan rilis untuk training-nv-pytorch 25.10.
Fitur utama dan perbaikan bug
Fitur utama
Menyediakan dukungan multi-arsitektur untuk amd64 dan aarch64.
Memperbarui megatron-core ke versi 0.14.0 dan transformer_engine ke versi 2.4 untuk mengintegrasikan fitur dari komunitas.
Memperbarui vLLM ke versi 0.11.0 untuk mengintegrasikan fitur dari komunitas.
Perbaikan bug
Tidak ada
Isi
arsitektur aarch64 | arsitektur amd64 | |
Application Scenario | Training/Inference | Training/Inference |
Framework | PyTorch | PyTorch |
Requirements | NVIDIA Driver release >= 575 | NVIDIA Driver release >= 575 |
Core components | Ubuntu : 24.04 CUDA : 12.8 Python : 3.12.7+gc torch : 2.8.0.9+nv25.3 accelerate : 1.7.0+ali deepspeed : 0.16.9+ali diffusers : 0.34.0 flash_attn : 2.8.3 flash_attn_3 : 3.0.0b1 flashinfer-python : 0.2.5 gdb : 15.0.50.20240403-git grouped_gemm : 1.1.4 megatron-core : 0.14.0 mmcv : 2.1.0 mmdet : 3.3.0 mmengine : 0.10.3 opencv-python-headless : 4.11.0.86 peft : 0.16.0 pytorch-dynamic-profiler : 0.24.11 pytorch-triton : 3.4.0 ray : 2.50.1 timm : 1.0.20 transformer_engine : 2.4.0+3cd6870c transformers : 4.56.1+ali ultralytics : 8.3.96 vllm : 0.11.0 | Ubuntu : 24.04 CUDA : 12.8 Python : 3.12.7+gc torch : 2.8.0.9+nv25.3 accelerate : 1.7.0+ali deepspeed : 0.16.9+ali diffusers : 0.34.0 flash_attn : 2.8.3 flash_attn_3 : 3.0.0b1 flashinfer-python : 0.2.5 gdb : 15.0.50.20240403-git grouped_gemm : 1.1.4 megatron-core : 0.14.0 mmcv : 2.1.0 mmdet : 3.3.0 mmengine : 0.10.3 opencv-python-headless : 4.11.0.86 peft : 0.16.0 perf : 5.4.30 pytorch-dynamic-profiler : 0.24.11 ray : 2.50.1 timm : 1.0.20 transformer_engine : 2.4.0+3cd6870c transformers : 4.56.1+ali triton : 3.4.0 ultralytics : 8.3.96 vllm : 0.11.0 |
Aset
25.10
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.10-serverless
Citra VPC
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}menunjukkan wilayah tempat ACS Anda diaktifkan, seperti cn-beijing dan cn-wulanchabu.{image:tag}menunjukkan nama dan tag citra tersebut.
Saat ini, Anda hanya dapat menarik citra dari wilayah China (Beijing) melalui VPC.
Citra egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.10-serverless cocok untuk produk ACS dan Lingjun multi-tenant. Citra ini tidak cocok untuk produk Lingjun single-tenant. Jangan gunakan citra ini dalam skenario Lingjun single-tenant.
Persyaratan driver
Rilis 25.10 didasarkan pada CUDA 12.8.0 dan memerlukan NVIDIA driver versi 575 atau lebih baru. Namun, jika Anda menjalankannya pada GPU data center, seperti T4, Anda dapat menggunakan NVIDIA driver versi 470.57 (atau rilis R470 yang lebih baru), 525.85 (atau rilis R525 yang lebih baru), 535.86 (atau rilis R535 yang lebih baru), atau 545.23 (atau rilis R545 yang lebih baru).
Paket kompatibilitas driver CUDA hanya mendukung driver tertentu. Oleh karena itu, Anda harus melakukan upgrade jika menggunakan driver R418, R440, R450, R460, R510, R520, R530, R545, R555, atau R560. Driver-driver tersebut tidak kompatibel maju dengan CUDA 12.8. Untuk daftar lengkap driver yang didukung, lihat topik CUDA application compatibility. Untuk informasi lebih lanjut, lihat CUDA compatibility and upgrades.
Fitur dan peningkatan utama
Optimasi kompilasi PyTorch
Fitur optimasi kompilasi yang diperkenalkan di PyTorch 2.0 cocok untuk pelatihan skala kecil pada satu GPU. Namun, pelatihan LLM memerlukan optimasi memori GPU dan framework terdistribusi, seperti FSDP atau DeepSpeed. Akibatnya, torch.compile() tidak memberikan manfaat bagi pelatihan Anda atau bahkan dapat berdampak negatif.
Mengontrol granularitas komunikasi dalam framework DeepSpeed membantu kompilator memperoleh graf komputasi lengkap untuk cakupan optimasi kompilasi yang lebih luas.
PyTorch yang dioptimalkan:
Antarmuka depan kompilator PyTorch dioptimalkan untuk memastikan kompilasi tetap berjalan meskipun terjadi gangguan graf dalam graf komputasi.
Kemampuan pencocokan mode dan bentuk dinamis ditingkatkan untuk mengoptimalkan kode hasil kompilasi.
Setelah optimasi di atas, throughput E2E meningkat sebesar 20% saat melatih model LLM 8B.
Optimasi memori GPU untuk recomputation
Kami memprediksi dan menganalisis konsumsi memori GPU model dengan menjalankan pengujian kinerja pada model yang diterapkan di kluster berbeda atau dikonfigurasi dengan parameter berbeda serta mengumpulkan metrik sistem, seperti pemanfaatan memori GPU. Berdasarkan hasil tersebut, kami merekomendasikan jumlah optimal lapisan recomputation aktivasi dan mengintegrasikannya ke dalam PyTorch. Hal ini memungkinkan pengguna untuk dengan mudah memperoleh manfaat dari optimasi memori GPU. Saat ini, fitur ini dapat digunakan dalam framework DeepSpeed.
Evaluasi manfaat kinerja E2E
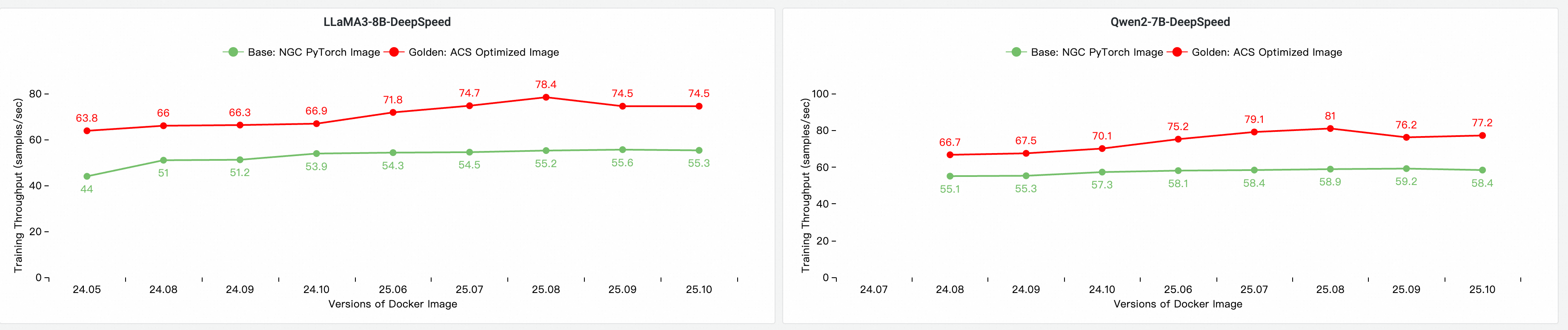
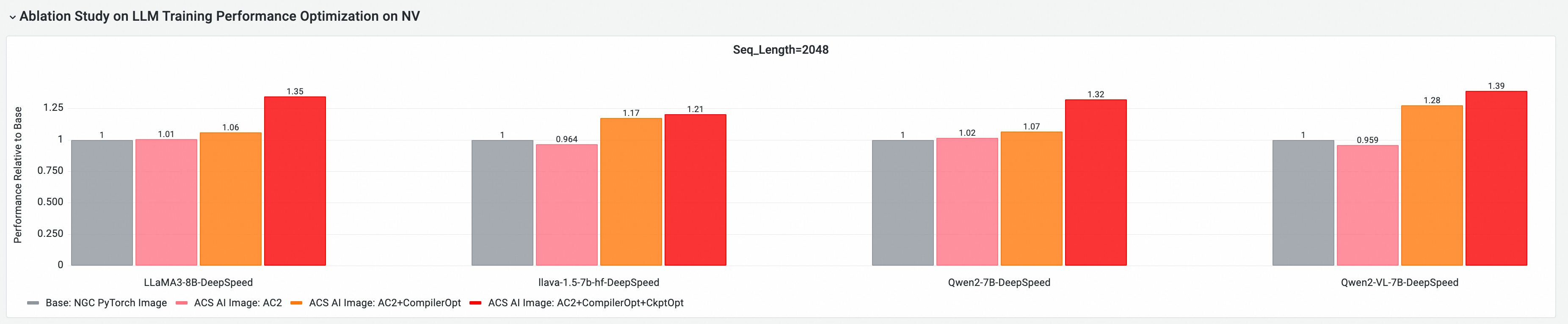
Menggunakan tool evaluasi dan analisis kinerja AI cloud-native CNP, kami melakukan perbandingan kinerja end-to-end (E2E) secara komprehensif terhadap model open source utama dan konfigurasi framework dibandingkan dengan citra dasar standar. Kami juga melakukan eksperimen ablation untuk mengevaluasi kontribusi setiap komponen optimasi terhadap kinerja pelatihan model secara keseluruhan.
Perbandingan citra: Citra dasar & evaluasi iterasi
Analisis kontribusi kinerja E2E komponen GPU inti
Pengujian berikut didasarkan pada versi 25.10 dan dilakukan pada kluster GPU multi-node untuk evaluasi dan perbandingan kinerja pelatihan end-to-end (E2E). Item-item berikut dibandingkan:
Base: NGC PyTorch Image.
ACS AI Image: AC2: Citra emas menggunakan AC2 BaseOS tanpa optimasi yang diaktifkan.
ACS AI Image: AC2+CompilerOpt: Citra emas menggunakan AC2 BaseOS dengan hanya optimasi torch compile yang diaktifkan.
ACS AI Image: AC2+CompilerOpt+CkptOpt: Citra emas menggunakan AC2 BaseOS dengan optimasi torch compile dan selective gradient checkpoint yang diaktifkan.
Quick start
Contoh berikut menunjukkan cara menarik citra training-nv-pytorch menggunakan Docker.
Untuk menggunakan citra training-nv-pytorch di ACS, pilih citra tersebut dari halaman Artifacts saat membuat workload di Konsol, atau tentukan referensi citra dalam file YAML.
1. Pilih citra
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. Panggil API untuk mengaktifkan kompiler dan recomputation untuk optimasi memori GPU
Aktifkan optimasi kompilasi
Gunakan API transformers Trainer:

Aktifkan recomputation untuk optimasi memori GPU
export CHECKPOINT_OPTIMIZATION=true
3. Mulai kontainer
Citra ini mencakup tool pelatihan model bawaan ljperf. Contoh berikut menunjukkan cara memulai kontainer dan menjalankan pekerjaan pelatihan dengan tool ini.
Model LLM
# Mulai dan masuk ke kontainer
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# Jalankan demo pelatihan
ljperf benchmark --model deepspeed/llama3-8b 4. Rekomendasi
Citra ini mencakup versi modifikasi library seperti PyTorch dan DeepSpeed. Untuk menghindari konflik, jangan instal ulang library tersebut.
Biarkan parameter zero_optimization.stage3_prefetch_bucket_size dalam konfigurasi DeepSpeed kosong atau atur ke auto.
Variabel lingkungan
NCCL_SOCKET_IFNAMEtelah dikonfigurasi sebelumnya dalam citra ini dan harus disesuaikan secara dinamis berdasarkan skenario:Jika satu pod hanya meminta 1, 2, 4, atau 8 GPU untuk tugas pelatihan atau inferensi, atur
NCCL_SOCKET_IFNAME=eth0. Ini adalah konfigurasi default dalam citra ini.Jika satu pod meminta semua 16 GPU pada sebuah node untuk tugas pelatihan atau inferensi, Anda harus mengatur
NCCL_SOCKET_IFNAME=hpn0. Pengaturan ini memungkinkan Anda menggunakan jaringan berkinerja-tinggi HPN.