Container Compute Service (ACS) menyediakan Komputasi GPU sesuai permintaan tanpa mengharuskan Anda mengelola perangkat keras atau konfigurasi node yang mendasarinya. ACS mudah diterapkan, mendukung penagihan bayar sesuai penggunaan, dan ideal untuk tugas inferensi model bahasa besar (LLM), yang membantu mengurangi biaya inferensi. Panduan ini akan memandu Anda melalui penerapan layanan ComfyUI di ACS dan penggunaan plugin deepgpu-comfyui untuk mempercepat pembuatan video teks-ke-video dan gambar-ke-video Wan2.1.
Pada akhir panduan ini, Anda akan:
Mengunduh file model Wan2.1 ke volume NAS persisten
Menyebarlayankan layanan ComfyUI pada kluster GPU ACS
Menjalankan alur kerja teks-ke-video yang dipercepat menggunakan node ApplyDeepyTorch
Latar Belakang
ComfyUI
ComfyUI adalah UI berbasis node sumber terbuka untuk menjalankan dan menyesuaikan pipeline Stable Diffusion. Alih-alih menulis kode, Anda membangun alur kerja generasi dengan menghubungkan node pada kanvas visual.
Model Wan
Tongyi Wanxiang, juga dikenal sebagai Wan, adalah model Seni AI dan teks-ke-gambar (AI-Generated Content (AIGC)) dari Tongyi Lab Alibaba. Model ini merupakan cabang generasi visual dari rangkaian model besar Tongyi Qianwen. Wan adalah model Seni AI pertama di dunia yang mendukung prompt dalam bahasa Tiongkok. Model ini memiliki kemampuan multimodal dan dapat menghasilkan karya seni berkualitas tinggi dari deskripsi teks, sketsa tangan, atau style transfer gambar.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Mendapatkan otorisasi akun ACS. Jika ini pertama kalinya Anda menggunakan ACS, tetapkan role default agar ACS dapat mengakses Elastic Compute Service (ECS), Object Storage Service (OSS), Apsara File Storage NAS, Cloud Parallel File Storage (CPFS), dan Server Load Balancer (SLB). Untuk detailnya, lihat Panduan cepat untuk pengguna ACS pertama kali.
Memiliki kluster GPU ACS dengan kartu GPU L20 (GN8IS) atau G49E.
Memiliki volume persisten NAS atau OSS untuk menyimpan file model. Panduan ini menggunakan volume NAS. Untuk instruksi penyiapan, lihat Buat sistem file NAS sebagai volume atau Gunakan volume OSS yang disediakan secara statis.
Menginstal Git di lingkungan lokal Anda. Lihat Unduhan Git.
Langkah 1: Siapkan data model
Jalankan perintah berikut di direktori tempat volume NAS dipasang.
Klon repositori ComfyUI.
git clone https://github.com/comfyanonymous/ComfyUI.gitUnduh tiga file model Wan2.1 ke direktori ComfyUI yang sesuai. File-file tersebut dihosting di proyek Wan_2.1_ComfyUI_repackaged di ModelScope.
Model penyebaran (
wan2.1_t2v_14B_fp16.safetensors):cd ComfyUI/models/diffusion_models wget https://modelscope.cn/models/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/master/split_files/diffusion_models/wan2.1_t2v_14B_fp16.safetensorsVAE (
wan_2.1_vae.safetensors):cd ComfyUI/models/vae wget https://modelscope.cn/models/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/master/split_files/vae/wan_2.1_vae.safetensorsPenyandi teks (
umt5_xxl_fp8_e4m3fn_scaled.safetensors):cd ComfyUI/models/text_encoders wget https://modelscope.cn/models/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/master/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors
Pengunduhan memerlukan waktu sekitar 30 menit. Jika koneksi Anda lambat, tingkatkan bandwidth publik puncak sebelum memulai.
Unduh dan ekstrak plugin ComfyUI-deepgpu.
cd ComfyUI/custom_nodes wget https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/nodes/20250513/ComfyUI-deepgpu.tar.gz tar zxf ComfyUI-deepgpu.tar.gz
Langkah 2: Terapkan layanan ComfyUI
Login ke Konsol ACS. Di panel navigasi kiri, pilih Clusters. Klik nama kluster target. Lalu pilih Workloads > Deployments dan klik Create from YAML.
Tempel manifes YAML berikut dan klik Create.
Ganti
persistentVolumeClaim.claimNamedengan nama klaim volume persisten (PVC) Anda. Contoh ini menggunakan image inference-nv-pytorch 25.07 dari wilayahcn-beijinguntuk meminimalkan waktu tarik image. Untuk menggunakan image ini dari wilayah lain, lihat Metode penggunaan dan perbarui path image dalam manifes. Gambar kontainer pada contoh ini telah memiliki plugin deepgpu-torch dan deepgpu-comfyui yang pra-instal. Untuk menggunakan plugin ini di lingkungan kontainer berbeda, hubungi solution architect (SA) untuk mendapatkan paket instalasi.apiVersion: apps/v1 kind: Deployment metadata: labels: app: wanx-deployment name: wanx-deployment-test namespace: default spec: replicas: 1 selector: matchLabels: app: wanx-deployment template: metadata: labels: alibabacloud.com/compute-class: gpu alibabacloud.com/compute-qos: default alibabacloud.com/gpu-model-series: L20 #Jenis kartu GPU yang didukung: L20 (instans GN8IS), G49E app: wanx-deployment spec: containers: - command: - sh - -c - DEEPGPU_PUB_LS=true python3 /mnt/ComfyUI/main.py --listen 0.0.0.0 --port 7860 image: acs-registry-vpc.cn-beijing.cr.aliyuncs.com/egslingjun/inference-nv-pytorch:25.07-vllm0.9.2-pytorch2.7-cu128-20250714-serverless imagePullPolicy: Always name: main resources: limits: nvidia.com/gpu: "1" cpu: "16" memory: 64Gi requests: nvidia.com/gpu: "1" cpu: "16" memory: 64Gi terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /dev/shm name: cache-volume - mountPath: /mnt #/mnt adalah path dalam pod tempat klaim volume NAS dipetakan name: data dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 volumes: - emptyDir: medium: Memory sizeLimit: 500G name: cache-volume - name: data persistentVolumeClaim: claimName: wanx-nas #wanx-nas adalah klaim volume yang dibuat dari volume NAS --- apiVersion: v1 kind: Service metadata: name: wanx-test spec: type: LoadBalancer ports: - port: 7860 protocol: TCP targetPort: 7860 selector: app: wanx-deploymentParameter utama dalam manifes ini:
Parameter Deskripsi alibabacloud.com/gpu-model-seriesJenis kartu GPU. Nilai yang didukung: L20(instans GN8IS) danG49E.nvidia.com/gpu: "1"Meminta satu GPU untuk kontainer. resources.limits/requestsMenetapkan CPU menjadi 16 core dan memori menjadi 64 GiB. /dev/shmemptyDir (sizeLimit: 500G)Volume memori bersama yang dipasang di /dev/shm. Diperlukan untuk inferensi model besar.mountPath: /mntPath di dalam pod tempat volume NAS dipasang. File ComfyUI dan model diakses dari path ini. persistentVolumeClaim.claimNameNama PVC Anda. Ganti wanx-nasdengan nama PVC aktual Anda.Pada dialog yang muncul, klik View untuk membuka halaman detail workload. Klik tab Logs. Saat layanan berhasil dimulai, output log akan tampak seperti ini:
Langkah 3: Akses antarmuka ComfyUI
Pada halaman detail workload, klik tab Access Method untuk mendapatkan titik akhir eksternal layanan, misalnya
8.xxx.xxx.114:7860.
Buka
http://8.xxx.xxx.114:7860/di browser.Pertama kali mengakses URL tersebut, mungkin memerlukan waktu sekitar 5 menit untuk dimuat.
Pada antarmuka ComfyUI, klik kanan di mana saja lalu klik Add Node untuk menelusuri node DeepGPU yang tersedia dari plugin. Node ApplyDeepyTorch mengoptimalkan inferensi model penyebaran dengan menerapkan akselerasi tingkat GPU. Sisipkan node ini setelah node terakhir yang memuat model dalam alur kerja Anda. Tampilan node tersebut seperti berikut:


Langkah 4: Jalankan alur kerja yang dipercepat
Unduh satu atau kedua alur kerja Wan2.1 berikut ke mesin lokal Anda:
Alur kerja gambar-ke-video:
https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/wan/workflows/workflow_image_to_video_wan_1.3b_deepytorch.jsonAlur kerja teks-ke-video:
https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/wan/workflows/workflow_text_to_video_wan_deepytorch.json
Langkah-langkah berikut menggunakan alur kerja teks-ke-video yang dipercepat sebagai contoh.
Di ComfyUI, pilih Workflow > Open lalu pilih file
workflow_text_to_video_wan_deepytorch.jsonyang telah diunduh.Temukan node Apply DeepyTorch to diffusion model. Atur parameter enable-nya menjadi true.
Alur kerja yang dipercepat DeepyTorch menyisipkan node ApplyDeepyTorch setelah node Load Diffusion Model.
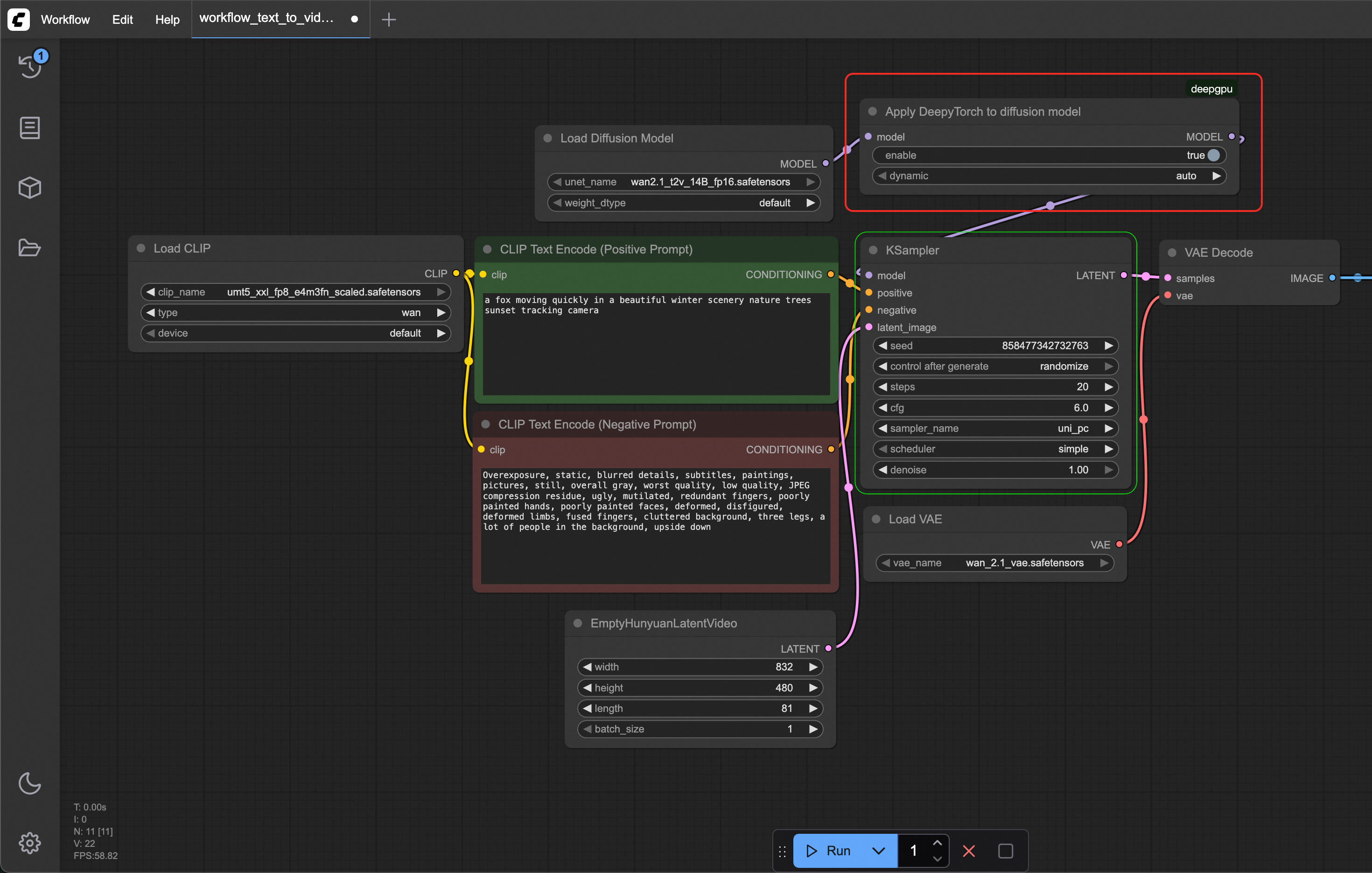
Klik Run dan tunggu hingga video dihasilkan.
Klik tombol Queue di sebelah kiri untuk melihat waktu pembuatan dan pratinjau output.
Jalur pertama memerlukan waktu lebih lama daripada jalur berikutnya karena model melakukan pemanasan. Jalankan alur kerja dua atau tiga kali lagi untuk melihat kinerja yang stabil.

(Opsional) Untuk membandingkan waktu pembuatan tanpa akselerasi, restart layanan ComfyUI dan jalankan alur kerja tanpa akselerasi:
https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/wan/workflows/workflow_text_to_video_wan.json