Untuk mengurangi biaya fine-tuning model, Anda dapat menggunakan grup penskalaan untuk secara otomatis menyediakan spot instans. Solusi ini memastikan kelangsungan pelatihan dengan secara otomatis membuat instans baru dan melanjutkan dari checkpoint terbaru ketika spot instans mengalami interruption and reclamation.
Ikhtisar solusi
Solusi ini menggunakan grup penskalaan untuk mengaktifkan fine-tuning model besar berbiaya rendah. Solusi ini menerapkan strategi prioritas spot instans dan menggunakan Object Storage Service (OSS) untuk menyimpan checkpoint secara persisten. Selama proses pelatihan:
Prioritaskan spot instans: Grup penskalaan memprioritaskan spot instans untuk tugas pelatihan dan menggunakan OSS untuk menyimpan file checkpoint.
Ketika spot instans terganggu dan ditarik kembali: Grup penskalaan pertama-tama mencoba menyediakan spot instans dari inventaris yang tersedia di zona ketersediaan lain. Jika inventaris spot tidak mencukupi, sistem secara otomatis menyediakan instans pay-as-you-go dan melanjutkan pelatihan dari checkpoint terbaru.
Setelah inventaris spot dipulihkan: Grup penskalaan secara otomatis mengganti instans pay-as-you-go dengan spot instans dan melanjutkan pelatihan dari checkpoint terbaru.
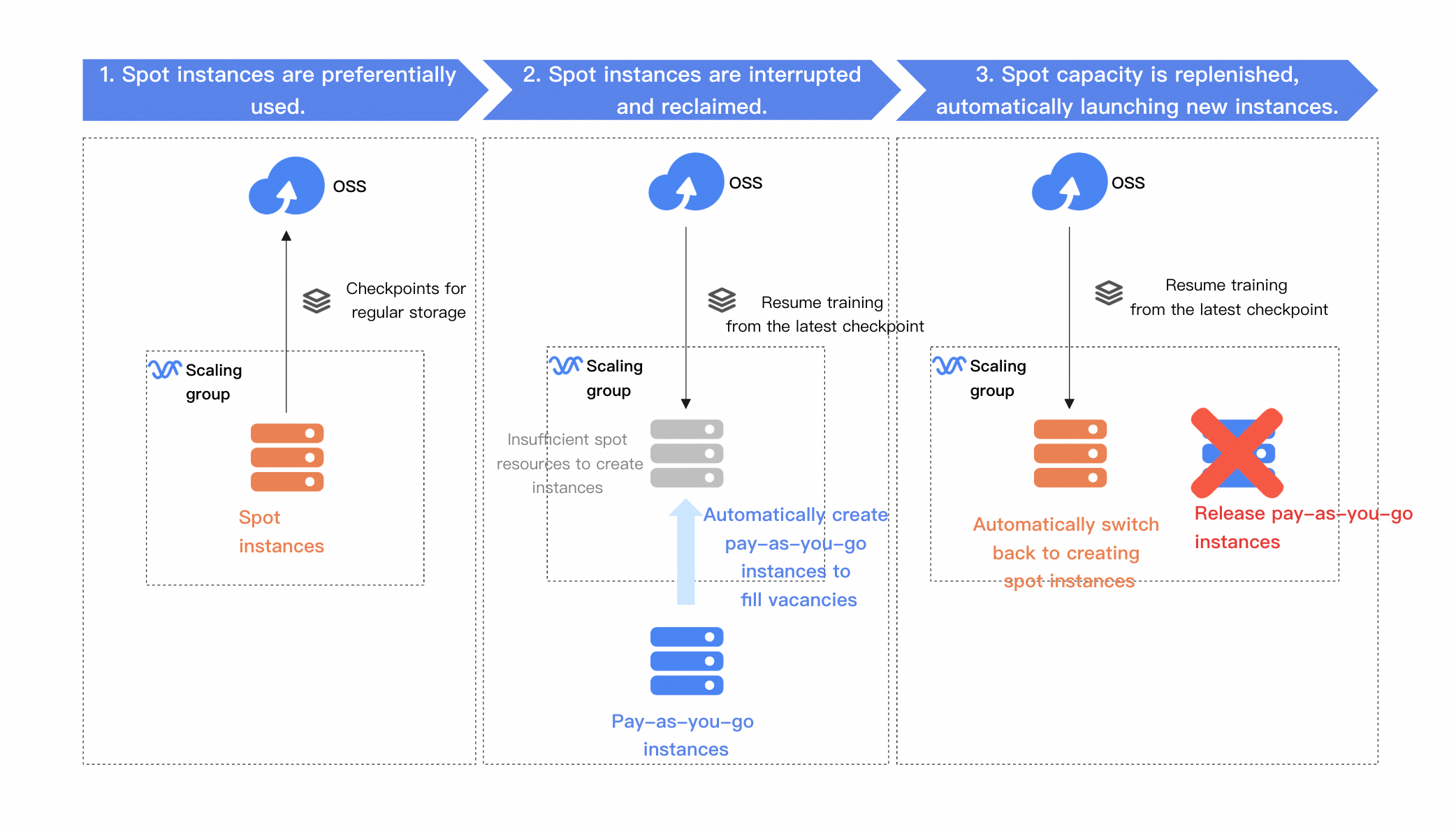
Jika Anda sensitif terhadap biaya dan dapat menerima waktu pelatihan yang lebih lama, Anda dapat mengonfigurasi grup penskalaan untuk hanya menggunakan spot instans. Dalam konfigurasi ini, pelatihan dijeda ketika spot instans tidak tersedia dan dilanjutkan secara otomatis ketika inventaris dipulihkan, sehingga memaksimalkan penghematan biaya Anda. Pelajari lebih lanjut tentang menggabungkan grup penskalaan dan spot instans.
Perbandingan biaya
Perbandingan biaya berikut hanya sebagai referensi. Penghematan aktual dapat bervariasi berdasarkan kondisi runtime.
Asumsikan total waktu pelatihan 12 jam, harga spot instans 3,5/jam, dan harga instans pay-as-you-go 10/jam. Perbandingan biayanya adalah sebagai berikut.
Mode | Hanya spot instans | Hibrida (spot dan pay-as-you-go) | Bayar Sesuai Pemakaian Saja |
Deskripsi | Ketika spot instans terganggu dan ditarik kembali, pelatihan dijeda. Spot instans baru secara otomatis diluncurkan untuk melanjutkan pelatihan setelah kapasitas dipulihkan. | Asumsikan dari total 12 jam pelatihan, 8 jam menggunakan spot instans dan 4 jam menggunakan instans pay-as-you-go akibat gangguan. | Seluruh pelatihan dilakukan pada instans pay-as-you-go. |
Biaya | 12 jam × 3,5/jam = 42 | 8 jam × 3,5/jam + 4 jam × 10/jam = 68 | 12 jam × 10/jam = 120 |
Penghematan vs. hanya pay-as-you-go | 65% | 43,33% | 0% |
Prosedur
Buat gambar kustom dengan lingkungan pelatihan dasar.
Gambar ini berfungsi sebagai gambar peluncuran untuk instans dalam grup penskalaan. Gambar ini mencakup skrip startup yang secara otomatis melanjutkan pelatihan, memastikan bahwa instans baru dapat segera memulai tugas tanpa intervensi manual.
Buat dan konfigurasikan grup penskalaan.
Grup penskalaan secara otomatis membuat instans spot atau pay-as-you-go baru setelah terjadi gangguan, memastikan tugas pelatihan berlanjut.
Mulai tugas pelatihan.
Mengaktifkan grup penskalaan memicu event scale-out, membuat instans yang secara otomatis memulai tugas pelatihan.
Simulasikan gangguan (verifikasi).
Lepaskan instans secara manual untuk mensimulasikan skenario gangguan atau penarikan kembali. Verifikasi bahwa instans baru diluncurkan dan tugas pelatihan dilanjutkan secara otomatis guna memastikan stabilitas dan keandalan.
1. Buat gambar pelatihan kustom
Topik ini menunjukkan cara melakukan fine-tuning self-cognition pada model DeepSeek-R1-Distill-Qwen-7B dengan menggunakan framework pelatihan Swift pada konfigurasi single-machine, single-GPU.
Pertama, buat instans dengan lingkungan pelatihan dan dependensi yang diperlukan. Kemudian, buat gambar kustom dari instans ini untuk dijadikan gambar peluncuran bagi grup penskalaan Anda, yang meningkatkan efisiensi startup. Gambar ini mencakup skrip pelatihan otomatis dan layanan boot-start untuk mengotomatiskan alur kerja. Arsitektur Instance ECS yang digunakan untuk membuat gambar ini ditunjukkan pada gambar berikut.
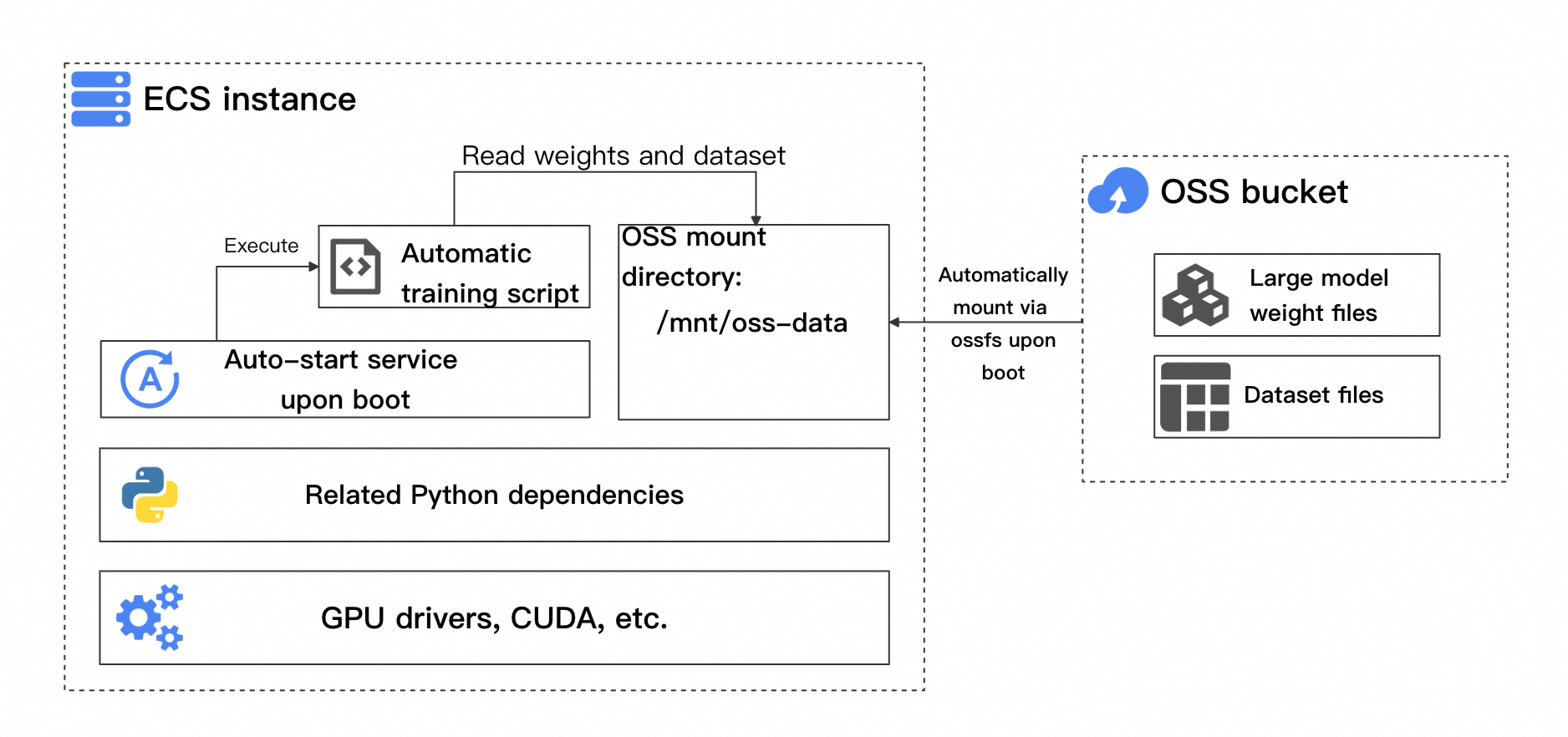
Komponen utama meliputi:
Dependensi lingkungan pelatihan dasar: Termasuk driver GPU, CUDA, dan dependensi Python terkait, yang bervariasi tergantung pada framework pelatihan.
Skrip pelatihan otomatis: Skrip ini harus secara otomatis memeriksa apakah akan melanjutkan dari checkpoint terbaru dan apakah pelatihan telah selesai.
Pemasangan bucket otomatis saat startup: Saat skrip pelatihan dimulai, skrip tersebut membaca bobot model, dataset, dan file checkpoint yang dihasilkan dari bucket OSS.
Layanan boot-start: Layanan ini memastikan bahwa skrip pelatihan berjalan secara otomatis setelah instans dimulai, membaca file yang diperlukan dari bucket untuk memulai atau melanjutkan pelatihan.
Setelah memahami komponen-komponen ini, ikuti langkah-langkah di bawah ini untuk membuat gambar.
1.1 Buat instans dan bangun lingkungan
Instans ini berfungsi sebagai templat untuk membuat gambar kustom. Nantinya, grup penskalaan akan menggunakan gambar ini untuk secara otomatis membuat instans baru.
Masuk ke Konsol ECS untuk membuat instance GPU.
Pertama, buat instans GPU berbayar sesuai penggunaan untuk menyiapkan lingkungan dasar. Tutorial ini menggunakan instans
ecs.gn7i-c8g1.2xlargedi Zona Ketersediaan J wilayah China (Hangzhou). Konfigurasikan instans sebagai berikut:1. Billing Method: Pay-As-You-Go.
②:Region. China (Hangzhou).
③④: Network and Zone. Pilih VPC dan vSwitch. Jika belum ada, Anda dapat membuatnya sesuai petunjuk di layar.
⑤⑥: Pilih tipe instans. Pilih
ecs.gn7i-c8g1.2xlarge.⑦⑧⑨: Images: Ubuntu 22.04 64-bit.
⑩: Instalasi otomatis driver GPU. Pilih versi: CUDA versi 12.4.1, Versi driver 550.127.08, dan CUDNN versi 9.2.0.82.
⑪: . 60 GiB.
⑫⑬⑭: Tetapkan alamat IPv4 publik agar instans dapat mengakses internet dan mengunduh file model. Untuk Bandwidth Billing Method, pilih Pay-by-traffic. Untuk Maximum Bandwidth, pilih 100 Mbps.
⑮⑯⑰: Buat kelompok keamanan dasar baru. Buka setidaknya port SSH (TCP: 22) dan ICMP (IPv4) untuk mengizinkan koneksi jarak jauh.
⑱⑲⑳: Logon Credential. Kredensial ini digunakan untuk login ke instans. Anda dapat memilih pasangan kunci atau kata sandi. Ikuti petunjuk di layar untuk menyelesaikan konfigurasi.
21:Instance Name. Tentukan nama untuk instans agar mudah diingat dan ditemukan. Topik ini menggunakan
ess-lora-deepseek7b-templatesebagai contoh.Setelah menyelesaikan konfigurasi, klik Confirm Order dan tunggu hingga instans dibuat.
Setelah instans dibuat, sambungkan ke instans tersebut dan tunggu hingga driver GPU selesai diinstal.
Buka Konsol ECS - Instans.
Temukan instans yang Anda buat pada langkah sebelumnya, lalu klik Connect di kolom Actions. Sambungkan ke instans menggunakan Workbench dan login sesuai permintaan.
Jika Anda tidak menemukan instans tersebut, wilayah yang sedang Anda gunakan mungkin tidak sesuai dengan wilayah instans. Anda dapat mengganti wilayah di pojok kiri atas.
Jika instans berhenti, refresh halaman dan tunggu hingga instans mulai.
Setelah terhubung ke instans, tunggu hingga instalasi driver GPU selesai. Setelah instalasi selesai, Anda akan diminta untuk menyambungkan ulang.
Jika antarmuka membeku, coba refresh halaman dan sambungkan ulang ke instans.
Welcome to Alibaba Cloud Elastic Compute Service ! Last login: Tue Mar 18 21:12:39 2025 from xxx % Total % Received % Xferd Average Speed Time Time Current Dload Upload Total Spent Left Speed 100 21 100 21 0 0 875 0 --:--:-- --:--:-- --:--:-- 913 Driver-xxx installing, it takes 0 minutes. Remaining installation time 11 to 15 minutes! [cuda-12.4.1. Installing, it tasks 2 to 5 minutes. Remaining installation time 9 to 12 minutes!
Instal dependensi Python.
Jalankan perintah berikut untuk menginstal dependensi yang diperlukan untuk pelatihan.
Gambar Ubuntu 22.04 64-bit yang digunakan dalam tutorial ini sudah mencakup Python 3.10, sehingga tidak diperlukan instalasi Python terpisah.
# Gambar Ubuntu 22.04 sudah mencakup Python 3.10, sehingga tidak diperlukan instalasi tambahan. python3 -m pip install --upgrade pip # Beralih ke mirror PyPI internal Alibaba Cloud. pip config set global.index-url http://mirrors.cloud.aliyuncs.com/pypi/simple/ pip install modelscope==1.22.3 pip install openai==1.61.0 pip install tqdm==4.67.1 pip install "vllm>=0.5.1" -U pip install "lmdeploy>=0.5,<0.6.5" -U --no-deps pip install autoawq -U --no-deps pip install auto_gptq optimum bitsandbytes -U pip install ms-swift[all] pip install timm -U pip install deepspeed==0.14.* -U pip install qwen_vl_utils decord librosa pyav icecream -U
Sambil menunggu dependensi diinstal, Anda dapat mengklik ikondi pojok kanan atas untuk membuka multi-terminal dan melanjutkan ke Langkah 1.2 secara bersamaan.
1.2 Buat dan pasang bucket OSS
Pada langkah ini, buat bucket di OSS dan pasang sebagai disk data ke Instance ECS. Bucket ini akan menyimpan file bobot model, dataset, dan checkpoint yang dihasilkan selama pelatihan.
Buka Konsol OSS untuk membuat bucket.
Berikut adalah parameter konfigurasi utama. Gunakan nilai default untuk parameter yang tidak disebutkan.
2. Bucket. Anda akan menggunakan nama bucket ini saat memasang bucket nanti.
3. Region. Pilih Region-specific. Wilayah harus sesuai dengan wilayah Instance ECS. Dalam contoh ini, wilayahnya adalah China (Hangzhou).
Instance ECS dapat mengakses bucket OSS di wilayah yang sama melalui jaringan internal tanpa biaya trafik. Untuk informasi lebih lanjut, lihat Akses sumber daya OSS dari Instance ECS melalui jaringan internal.
Buat dan lampirkan peran RAM.
Peran RAM memberikan otorisasi kepada Instance ECS untuk mengakses bucket OSS Anda. Untuk membuat dan melampirkan peran RAM, ikuti langkah-langkah berikut:
Di RAM, buat peran RAM. Parameter konfigurasi utama dijelaskan di bawah ini.
Buka halaman Peran di konsol Resource Access Management (RAM) dan klik Create Role.
②: Jenis prinsipal. Pilih Cloud Service.
③: Nama prinsipal. Pilih ECS. Ini menentukan bahwa peran akan diberikan kepada Instance ECS.
④: Klik OK dan tetapkan nama untuk peran RAM sesuai permintaan.
Di RAM, buat kebijakan kustom berikut.
Buka halaman Kebijakan di konsol Resource Access Management (RAM) dan klik Create Policy.
Pilih tab Script Editor dan masukkan skrip kebijakan berikut.
③: Kebijakan ini memberikan akses penuh ke bucket tertentu. Skrip kebijakan adalah sebagai berikut.
PentingSaat menetapkan kebijakan, ganti
<bucket_name>dengan Bucket Anda.{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": "oss:*", "Resource": [ "acs:oss:*:*:<bucket_name>", "acs:oss:*:*:<bucket_name>/*" ] } ] }Setelah konfigurasi selesai, klik OK dan tetapkan nama untuk kebijakan sesuai permintaan.
Di RAM, berikan izin kepada peran RAM.
⑥: Principal. Pilih peran RAM yang telah Anda buat sebelumnya.
⑦: Permission Policy. Pilih kebijakan kustom yang telah Anda buat sebelumnya.
Setelah konfigurasi selesai, klik OK.
Buka Konsol ECS dan lampirkan peran RAM ke instans tersebut.
Jika Anda tidak menemukan instans tersebut, wilayah yang sedang Anda gunakan mungkin tidak sesuai dengan wilayah instans. Anda dapat mengganti wilayah di pojok kiri atas.
Di daftar instans pada Konsol ECS, temukan instans target dan lampirkan peran RAM yang Anda buat di Langkah 1.2 dari kolom Tindakan.
Pasang bucket ke Instance ECS.
Sambungkan ke instans yang dibuat di Langkah 1.1 dan jalankan perintah berikut untuk menginstal tool ossfs.
wget https://gosspublic.alicdn.com/ossfs/ossfs_1.91.5_ubuntu22.04_amd64.deb apt-get update DEBIAN_FRONTEND=noninteractive apt-get install gdebi-core DEBIAN_FRONTEND=noninteractive gdebi -n ossfs_1.91.5_ubuntu22.04_amd64.debJalankan perintah berikut untuk menyelesaikan operasi pemasangan. Pastikan untuk mengganti placeholder berikut dalam perintah:
<bucket_name>: Ganti dengan Bucket dari bucket yang Anda buat.<ecs_ram_role>: Ganti dengan nama Peran RAM yang telah Anda buat.<internal_endpoint>: Ganti denganoss-cn-hangzhou-internal.aliyuncs.com.PentingTutorial ini menggunakan bucket di wilayah China (Hangzhou), sehingga titik akhir internal VPC-nya adalah
oss-cn-hangzhou-internal.aliyuncs.com.
# Ganti dengan nama bucket, titik akhir internal, dan peran RAM Anda. BUCKET_NAME="<bucket_name>" ECS_RAM_ROLE="<ecs_ram_role>" INTERNAL_ENDPOINT="<internal_endpoint>" # Jalur pemasangan bucket BUCKET_MOUNT_PATH="/mnt/oss-data" # 1. Cadangkan file fstab sebelum memasang. cp /etc/fstab /etc/fstab.bak # 2. Buat direktori pemasangan. mkdir $BUCKET_MOUNT_PATH # 3. Pasang bucket ke instans. ossfs $BUCKET_NAME $BUCKET_MOUNT_PATH -ourl=$INTERNAL_ENDPOINT -oram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE # 4. Atur pemasangan otomatis saat startup. echo "ossfs#$BUCKET_NAME $BUCKET_MOUNT_PATH fuse _netdev,url=http://$INTERNAL_ENDPOINT,ram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE,allow_other 0 0" | sudo tee -a /etc/fstab
(Verifikasi) Uji apakah storage space tersedia.
Unggah file apa pun ke bucket OSS.
Di Konsol OSS, buka halaman File bucket Anda. Klik Upload File dan unggah file uji untuk memverifikasi pemasangan.
Di instans, jalankan perintah berikut untuk memeriksa apakah Anda dapat melihat file dari bucket OSS di direktori tersebut.
ls /mnt/oss-data/Jika file terlihat, pemasangan berhasil.
root@ixxx:~# ls /mnt/oss-data/ test.txt
1.3 Siapkan model dan dataset
Bobot model dan dataset yang digunakan dalam tutorial ini diunduh dari komunitas ModelScope. Setelah Anda terhubung ke instans, ikuti langkah-langkah di bawah ini. Unduh model dan dataset ke direktori tempat bucket OSS dipasang dan tunggu hingga pengunduhan selesai.
Unduh dataset
# Jalur pemasangan bucket BUCKET_MOUNT_PATH="/mnt/oss-data" # Unduh dataset fine-tuning dari komunitas ModelScope # Gunakan tool modelscope yang diinstal di Langkah 1.1 modelscope download --dataset swift/self-cognition --local_dir $BUCKET_MOUNT_PATH/self-cognition modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-zh --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-zh modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-en --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-enJika progres pengunduhan berhenti, tekan Enter beberapa kali.
Unduh bobot model
PentingFile bobot model berukuran besar. Jika pengunduhan gagal atau Anda melihat pesan
please try again, ulangi perintah untuk melanjutkan pengunduhan.# Jalur pemasangan bucket BUCKET_MOUNT_PATH="/mnt/oss-data" # Unduh model DeepSeek-R1-Distill-Qwen-7B dari komunitas ModelScope modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7BJika progres pengunduhan berhenti, tekan Enter beberapa kali.
Uji bobot model
Setelah pengunduhan selesai, Anda dapat menjalankan perintah berikut untuk melakukan uji inferensi dengan model dan memverifikasi bahwa file bobot model lengkap.
# Jalur pemasangan bucket BUCKET_MOUNT_PATH="/mnt/oss-data" CUDA_VISIBLE_DEVICES=0 swift infer \ --model $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B \ --stream true \ --infer_backend pt \ --max_new_tokens 2048Setelah model dimuat, Anda dapat memulai percakapan dengan model bahasa besar. Jika bobot model gagal dimuat, unduh kembali.
[INFO:swift] Start time of running main: 2025-03-26 13:35:50.564493 [INFO:swift] request_config: RequestConfig(max_tokens=2048, temperature=None, top_k=None, top_p=None, repetition_penalty=None, num_beams=1, stop=[], seed=None, stream=True, logprobs=False, top_logprobs=None, n=1, best_of=None, presence_penalty=0.0, frequency_penalty=0.0, length_penalty=1.0) [INFO:swift] Input 'exit' or 'quit' to exit the conversation. [INFO:swift] Input 'multi-line' to switch to multi-line input mode. [INFO:swift] Input 'reset-system' to reset the system and clear the history. [INFO:swift] Input 'clear' to clear the history. <<< 你是谁?Setelah pengujian selesai, Anda dapat memasukkan
exituntuk mengakhiri percakapan.
1.4 Tulis skrip pelatihan otomatis
Tulis skrip pelatihan otomatis.
Jalankan perintah berikut untuk membuat skrip pelatihan otomatis dan berikan izin eksekusi. Skrip ini secara otomatis melanjutkan pelatihan dari checkpoint terbaru dan menentukan kapan pelatihan selesai.
# Buat skrip pelatihan otomatis. cat <<EOF > /root/train.sh #!/bin/bash # Jalur pemasangan bucket BUCKET_MOUNT_PATH="/mnt/oss-data" # Direktori penyimpanan untuk bobot model dan dataset MODEL_PATH="\$BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B" DATASET_PATH="\$BUCKET_MOUNT_PATH/alpaca-gpt4-data-zh#500 \$BUCKET_MOUNT_PATH/alpaca-gpt4-data-en#500 \$BUCKET_MOUNT_PATH/self-cognition#500" # Tetapkan direktori output OUTPUT_DIR="\$BUCKET_MOUNT_PATH/output" mkdir -p "\$OUTPUT_DIR" # Logika untuk memeriksa apakah pelatihan sudah selesai if [ -f "\$OUTPUT_DIR/logging.jsonl" ]; then last_line=\$(tail -n 1 "\$OUTPUT_DIR/logging.jsonl") if echo "\$last_line" | grep -q "last_model_checkpoint" && echo "\$last_line" | grep -q "best_model_checkpoint"; then echo "Pelatihan sudah selesai. Keluar." exit 0 fi fi # Inisialisasi argumen resume RESUME_ARG="" # Temukan checkpoint terbaru LATEST_CHECKPOINT=\$(ls -dt \$OUTPUT_DIR/checkpoint-* 2>/dev/null | head -1) if [ -n "\$LATEST_CHECKPOINT" ]; then RESUME_ARG="--resume_from_checkpoint \$LATEST_CHECKPOINT" echo "Lanjutkan pelatihan dari: \$LATEST_CHECKPOINT" else echo "Checkpoint tidak ditemukan. Memulai pelatihan baru." fi # Jalankan perintah pelatihan CUDA_VISIBLE_DEVICES=0 swift sft \\ --model \$MODEL_PATH \\ --train_type lora \\ --dataset \$DATASET_PATH \\ --torch_dtype bfloat16 \\ --num_train_epochs 1 \\ --per_device_train_batch_size 1 \\ --per_device_eval_batch_size 1 \\ --learning_rate 1e-4 \\ --lora_rank 8 \\ --lora_alpha 32 \\ --target_modules all-linear \\ --gradient_accumulation_steps 16 \\ --eval_steps 50 \\ --save_steps 10 \\ --save_total_limit 5 \\ --logging_steps 5 \\ --max_length 2048 \\ --output_dir "\$OUTPUT_DIR" \\ --add_version False \\ --overwrite_output_dir True \\ --system 'You are a helpful assistant.' \\ --warmup_ratio 0.05 \\ --dataloader_num_workers 4 \\ --model_author swift \\ --model_name swift-robot \\ \$RESUME_ARG EOF # Berikan izin eksekusi chmod +x /root/train.shBuat layanan Linux dan atur untuk mulai saat boot.
Jalankan perintah berikut untuk membuat layanan dan mengonfigurasi skrip pelatihan agar berjalan otomatis saat boot.
# Buat direktori penyimpanan log mkdir -p /root/train-service-log # Tulis file konfigurasi Layanan cat <<EOF > /etc/systemd/system/train.service [Unit] Description=Train AI Model Script After=network.target local-fs.target remote-fs.target Requires=local-fs.target remote-fs.target [Service] ExecStart=/root/train.sh WorkingDirectory=/root/ User=root Environment="PATH=/usr/bin:/usr/local/bin" Environment="CUDA_VISIBLE_DEVICES=0" StandardOutput=append:/root/train-service-log/train.log StandardError=append:/root/train-service-log/train_error.log [Install] WantedBy=multi-user.target EOF # Muat ulang konfigurasi systemd systemctl daemon-reload # Konfigurasikan train.service untuk mulai saat boot systemctl enable train.servicePerintah mengembalikan output berikut setelah selesai:
Created symlink /etc/systemd/system/multi-user.target.wants/train.service → /etc/systemd/system/train.service.
1.5 Bangun gambar kustom
Setelah menyelesaikan semua langkah sebelumnya, buat gambar kustom dari instans yang telah dikonfigurasi. Gambar ini berfungsi sebagai gambar peluncuran untuk instans baru selama scale-out, sehingga menghilangkan kebutuhan untuk menginstal ulang dependensi.
Buka halaman Instans di Konsol ECS.
Buat gambar seperti dijelaskan di bawah ini.
Di daftar instans pada Konsol ECS, temukan instans target. Di kolom Tindakan, klik More > Disks and Images > Create Custom Image. Selesaikan pembuatan gambar sesuai permintaan.
Tunggu hingga gambar selesai dibuat. Proses ini memakan waktu sekitar 5 menit. Anda dapat memeriksa progres pembuatan di halaman Gambar di Konsol ECS.
Setelah gambar dibuat, Anda dapat melepas instans yang dibuat di Langkah 1.1.
2. Buat grup penskalaan
Konfigurasikan grup penskalaan untuk mengotomatiskan manajemen instans. Grup penskalaan memastikan bahwa setelah instans terganggu, instans spot atau pay-as-you-go baru secara otomatis dibuat untuk melanjutkan tugas pelatihan. Ketika spot instans tersedia kembali, instans tersebut secara otomatis menggantikan instans pay-as-you-go untuk menghemat biaya.
2.1 Buat grup penskalaan
Pertama, Anda perlu membuat grup penskalaan. Ikuti langkah-langkah berikut.
Buka Konsol Auto Scaling untuk membuat grup penskalaan.
PentingPastikan grup penskalaan berada di wilayah yang sama dengan instans yang dibuat di Langkah 1.1.
Konfigurasikan grup penskalaan sebagai berikut. Untuk deskripsi parameter terperinci, lihat Parameter.
Konfigurasikan parameter berikut: Tetapkan Nama Grup Penskalaan menjadi ess-lora-deepseek-7b, Jenis menjadi ECS, dan Sumber untuk Konfigurasi Instans menjadi Instans yang Ada. Tetapkan Instans Minimum menjadi 0, Instans Maksimum menjadi 1, dan biarkan Waktu Tunda Default pada 300 detik.
PentingSaat Anda memilih VPC dan vSwitch di ⑤⑥, kami menyarankan Anda memilih vSwitch di beberapa zona ketersediaan. Hal ini memungkinkan grup penskalaan menyediakan sumber daya lintas zona, meningkatkan probabilitas keberhasilan pembuatan spot instans.
PentingJika Anda ingin memaksimalkan penghematan biaya dengan hanya menggunakan spot instans untuk pelatihan, nonaktifkan Use Pay-as-you-go Instances to Supplement Spot Capacity dan Replace Pay-as-you-go Instances with Spot Instances.
Setelah konfigurasi selesai, klik Create. Anda kemudian dapat melanjutkan untuk membuat konfigurasi penskalaan sesuai permintaan.
2.2 Buat konfigurasi penskalaan
Konfigurasi penskalaan menentukan spesifikasi, gambar, dan informasi lain untuk instans dalam grup penskalaan. Setelah Anda mengonfigurasinya, grup penskalaan secara otomatis membuat instans baru berdasarkan pengaturan ini. Di halaman Buat Konfigurasi Penskalaan, selesaikan konfigurasi berikut:
1. Scaling Configuration Name: ②: Billing Method: Spot Instance. |
③ dan ④: Image. Pilih Custom Images, lalu pilih gambar kustom yang Anda buat di Langkah 1.5. ⑤: Instance Configuration Mode. Pilih Specify Instance Type. 6. Instance Usage Duration. Pilih 1 Hour. Setelah instance berjalan selama satu jam, sistem akan mulai memeriksa apakah instance tersebut akan diinterupsi dan ditarik kembali. Jika Anda memilih Tanpa Durasi Penggunaan Tertentu, Anda dapat menggunakan spot instans dengan biaya lebih rendah, tetapi memiliki probabilitas gangguan yang lebih tinggi. Hal ini dapat menyebabkan instans ditarik kembali sebelum checkpoint yang valid dapat dibuat, sehingga memperlambat progres pelatihan. Untuk informasi lebih lanjut tentang perbedaan antara kedua opsi ini, lihat Gunakan spot instans dalam grup penskalaan untuk mengurangi biaya. ⑦: Harga tertinggi per instans. Pilih Use Automatic Bid untuk secara otomatis menawar berdasarkan harga pasar. 8. Select an instance type. Pilih tipe instans yang Anda tetapkan saat membuat instans di Langkah 1.1, yaitu |
9. Security Group. Pilih grup keamanan yang Anda konfigurasi saat membuat instans di Langkah 1.1. Tutorial ini merupakan solusi pelatihan offline, sehingga tidak perlu menetapkan alamat IP publik. |
⑩:Logon Credential. Pilih Use Predefined Password. |
⑪⑫⑬: . Pilih peran RAM yang dibuat di Langkah 1.2. Saat grup penskalaan secara otomatis membuat instans, peran RAM ini akan secara otomatis dilampirkan ke instans baru. |
Setelah Anda mengklik Create, Anda mungkin melihat prompt tentang kekuatan konfigurasi penskalaan tidak mencukupi. Klik Continue.
Setelah membuat konfigurasi penskalaan, aktifkan konfigurasi penskalaan dan aktifkan grup penskalaan sesuai permintaan.
Setelah konfigurasi penskalaan berhasil dibuat, klik Enable Configuration di kotak dialog yang muncul. | Di kotak dialog konfirmasi Select Scaling Configuration, klik OK. | Di kotak dialog konfirmasi Enable Scaling Group, klik OK untuk mengaktifkan grup penskalaan. |
3. Mulai tugas pelatihan
Setelah grup penskalaan dikonfigurasi, sesuaikan jumlah instans yang diharapkan menjadi 1. Langkah-langkahnya sebagai berikut.
Buka halaman detail grup penskalaan dan lihat Ikhtisar Penskalaan Instans. Jumlah instans saat ini semuanya 0. | Klik Modify di bagian Ikhtisar Penskalaan Instans. Aktifkan sakelar Jumlah Instans yang Diharapkan, tetapkan nilainya menjadi 1, lalu klik OK. Grup penskalaan akan secara otomatis membuat spot instans. |
Grup penskalaan kemudian secara otomatis membuat instans baru dan memulai tugas pelatihan.
Grup penskalaan secara berkala memeriksa apakah jumlah instans dalam grup sesuai dengan jumlah instans yang diharapkan. Karena jumlah saat ini adalah 0, scale-out secara otomatis dipicu untuk membuat instans baru.
Setelah Anda menyesuaikan jumlah instans yang diharapkan, mungkin terjadi penundaan dalam pembuatan instans. Anda dapat melihat aktivitas yang sedang berlangsung di tab Scaling Activities.
Setelah instans dibuat dan dimulai, Anda dapat menemukan folder
outputdi bucket OSS Anda. Folder ini menyimpan file checkpoint yang dihasilkan selama pelatihan.
4. Simulasikan gangguan (verifikasi)
Setelah instans memulai tugas pelatihan, periksa direktori output di bucket OSS Anda untuk melihat apakah folder seperti checkpoint-10 telah dibuat. Setelah checkpoint dihasilkan, Anda dapat melepaskan instans pelatihan secara manual untuk mensimulasikan gangguan. Langkah-langkah untuk melepaskan instans secara manual adalah sebagai berikut:
Lepaskan instans secara manual.
Pertama, buka tab Instances pada grup penskalaan, lalu klik Instance ID untuk membuka halaman Instance Details yang sesuai.
Di halaman detail instans, klik di pojok kanan atas dan ikuti petunjuk untuk melepaskan instans.
Periksa apakah pelatihan dilanjutkan dari checkpoint terbaru.
Tunggu hingga grup penskalaan membuat instans baru. Setelah instans dibuat, sambungkan ke instans tersebut dan lihat log tugas.
Buka tab Instances pada grup penskalaan, lalu klik Instance ID untuk membuka halaman Instance Details yang sesuai.
Klik Connect di pojok kanan atas dan sambungkan ke instans sesuai permintaan.
Jalankan perintah berikut untuk melihat log pelatihan model. Jalur output log ini telah ditetapkan untuk layanan boot-start di Langkah 1.4.
cat /root/train-service-log/train.logSeperti yang terlihat, tugas pelatihan dilanjutkan dari checkpoint terbaru.
root@ixxx:~# cat train-service-log/train.log Resume training from: /mnt/oss-data/output/checkpoint-10 run sh: /usr/bin/python3 /usr/local/lib/python3.10/dist-packages/xxx s-data/self-cognition#500 --torch_dtype bfloat16 --num_train_epochs xxx --eval_steps 50 --save_steps 10 --save_total_limit 5 --logging_steps xxx --num_workers 4 --model_author swift --model_name swift-robot --resume xxx
Langkah selanjutnya
Gunakan model yang telah difine-tuning untuk inferensi
Lepaskan sumber daya
Rekomendasi untuk lingkungan produksi
Sebelum menggunakan solusi ini di produksi, sesuaikan berdasarkan kebutuhan bisnis Anda dan rekomendasi berikut.
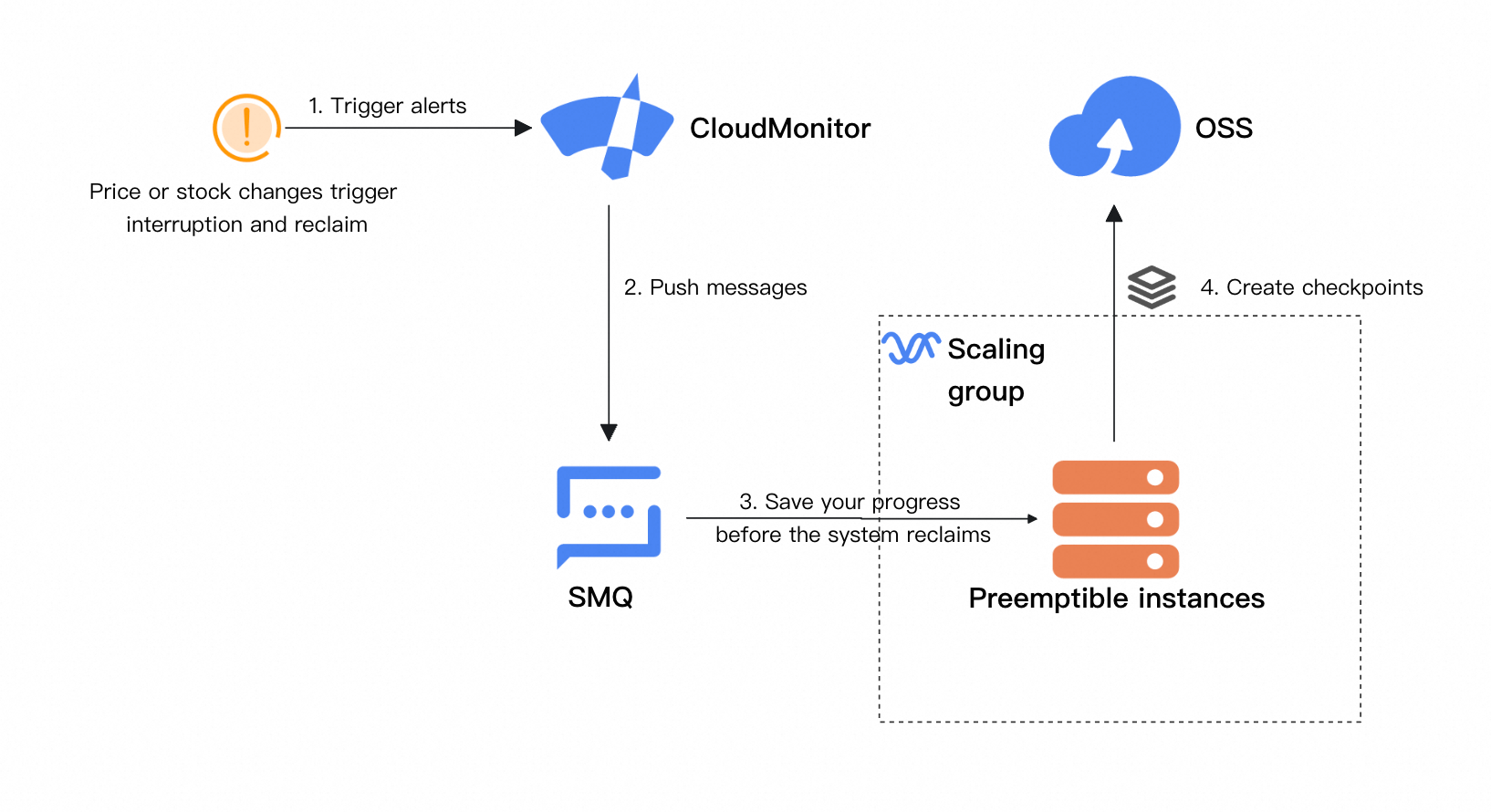
Integrasikan CloudMonitor untuk penanganan gangguan
Saat menerapkan solusi ini di lingkungan produksi, kami menyarankan Anda mengintegrasikan CloudMonitor ke dalam kode pelatihan Anda untuk mendeteksi dan merespons event gangguan spot instans. Menyimpan checkpoint lima menit sebelum gangguan mengurangi kehilangan progres saat melanjutkan pelatihan. Arsitektur yang ditingkatkan adalah sebagai berikut:
Buat mekanisme pemulihan tugas
Dalam contoh tutorial ini, pelatihan dilanjutkan secara otomatis dari checkpoint terbaru tanpa memeriksa validitasnya. Dalam aplikasi produksi, disarankan untuk menerapkan mekanisme deteksi anomali untuk mengecualikan checkpoint yang tidak valid dan secara otomatis melanjutkan pelatihan dari checkpoint valid terbaru.
Tingkatkan proses penyelesaian tugas
Anda dapat menambahkan logika ke dalam kode pelatihan Anda untuk menentukan kapan tugas selesai. Setelah selesai, gunakan CLI atau SDK untuk memanggil API grup penskalaan dan mengubah jumlah instans yang diharapkan menjadi 0. Grup penskalaan kemudian secara otomatis melepaskan instans berlebih, menghindari biaya yang tidak perlu.
Selain itu, saat tugas selesai, Anda dapat melaporkan event kustom ke CloudMonitor. Hal ini memungkinkan Anda menerima notifikasi tentang hasil pelatihan melalui email, SMS, atau chatbot DingTalk.
Gunakan sistem file berkinerja-tinggi
Saat Anda melatih model dengan jumlah parameter yang besar, OSS dapat menjadi bottleneck sistem. Kami menyarankan Anda menggunakan sistem file ber-throughput tinggi dan latensi rendah seperti CPFS sebagai sistem file yang dipasang untuk meningkatkan kinerja.
Konfigurasikan vSwitch multi-AZ untuk ketersediaan lebih tinggi
Jika Anda mengonfigurasi vSwitch hanya di satu zona ketersediaan, grup penskalaan hanya dapat membuat instans di zona tersebut, yang dapat dengan mudah menyebabkan kegagalan scale-out akibat kapasitas tidak mencukupi. Kami menyarankan Anda mengonfigurasi vSwitch di beberapa zona ketersediaan. Saat spot instans ditarik kembali, sistem secara otomatis mencoba membuat instans baru di zona lain, meningkatkan ketersediaan spot instans.