Container Service for Kubernetes (ACK) memungkinkan Anda menginstal managed Prometheus plug-in. Plug-in ini dapat digunakan untuk memantau sumber daya GPU. Solusi cGPU memungkinkan penjadwalan beberapa aplikasi pada satu GPU serta mengisolasi Memori GPU dan daya komputasi yang dialokasikan untuk setiap aplikasi. Topik ini menjelaskan cara memantau penggunaan Memori GPU klaster menggunakan managed Prometheus plug-in dan cara mengisolasi Memori GPU dengan cGPU.
Skenario
Topik ini berlaku untuk klaster Kubernetes khusus dengan cGPU diaktifkan dan klaster Kubernetes profesional dengan cGPU diaktifkan.
Prasyarat
- Klaster Kubernetes khusus dengan node akselerasi GPU telah dibuat. Versi Kubernetes adalah 1.16 atau lebih baru. Untuk informasi lebih lanjut, lihat Buat klaster ACK khusus dengan node akselerasi GPU.
- Application Real-Time Monitoring Service (ARMS) telah diaktifkan. Untuk informasi lebih lanjut, lihat Aktifkan ARMS.
- Managed Service for Prometheus telah diaktifkan untuk klaster. Untuk informasi lebih lanjut, lihat Aktifkan Managed Service for Prometheus.
- Model GPU adalah Tesla P4, Tesla P100, Tesla T4, atau Tesla V100 (16 GB).
Informasi Latar Belakang
Perkembangan AI didorong oleh daya komputasi tinggi, jumlah data besar, dan algoritma yang dioptimalkan. GPU NVIDIA menyediakan teknik komputasi heterogen umum yang menjadi dasar pembelajaran mendalam berperforma tinggi. Biaya GPU cukup tinggi. Jika setiap aplikasi menggunakan satu GPU khusus dalam skenario prediksi model, sumber daya komputasi mungkin terbuang. Berbagi GPU meningkatkan efisiensi penggunaan sumber daya. Anda harus mempertimbangkan cara mencapai laju query tertinggi dengan biaya terendah serta memenuhi service level agreement (SLA) aplikasi.
Gunakan managed Prometheus plug-in untuk memantau GPU khusus
- Masuk ke Konsol ARMS.
- Di panel navigasi sebelah kiri, klik Prometheus Monitoring.
- Di halaman Prometheus Monitoring, pilih wilayah tempat klaster diterapkan dan klik Install di kolom Actions.
- Di pesan Confirmation, klik OK.Instalasi Prometheus plug-in memerlukan waktu sekitar 2 menit. Setelah berhasil diinstal, plug-in akan muncul di kolom Installed Dashboards.
- Anda dapat menerapkan aplikasi sampel berikut menggunakan CLI. Untuk informasi lebih lanjut, lihat Buat aplikasi tanpa status menggunakan Deployment.
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-3g-v1 labels: app: app-3g-v1 spec: replicas: 1 serviceName: "app-3g-v1" podManagementPolicy: "Parallel" selector: # definisikan cara deployment menemukan pods yang dikelola matchLabels: app: app-3g-v1 updateStrategy: type: RollingUpdate template: # definisikan spesifikasi pods metadata: labels: app: app-3g-v1 spec: containers: - name: app-3g-v1 image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - cuda_malloc - -size=4096 resources: limits: nvidia.com/gpu: 1Setelah aplikasi diterapkan, jalankan perintah berikut untuk menanyakan status aplikasi. Output yang diharapkan menunjukkan bahwa nama aplikasi adalah app-3g-v1-0.kubectl get podOutput yang Diharapkan:
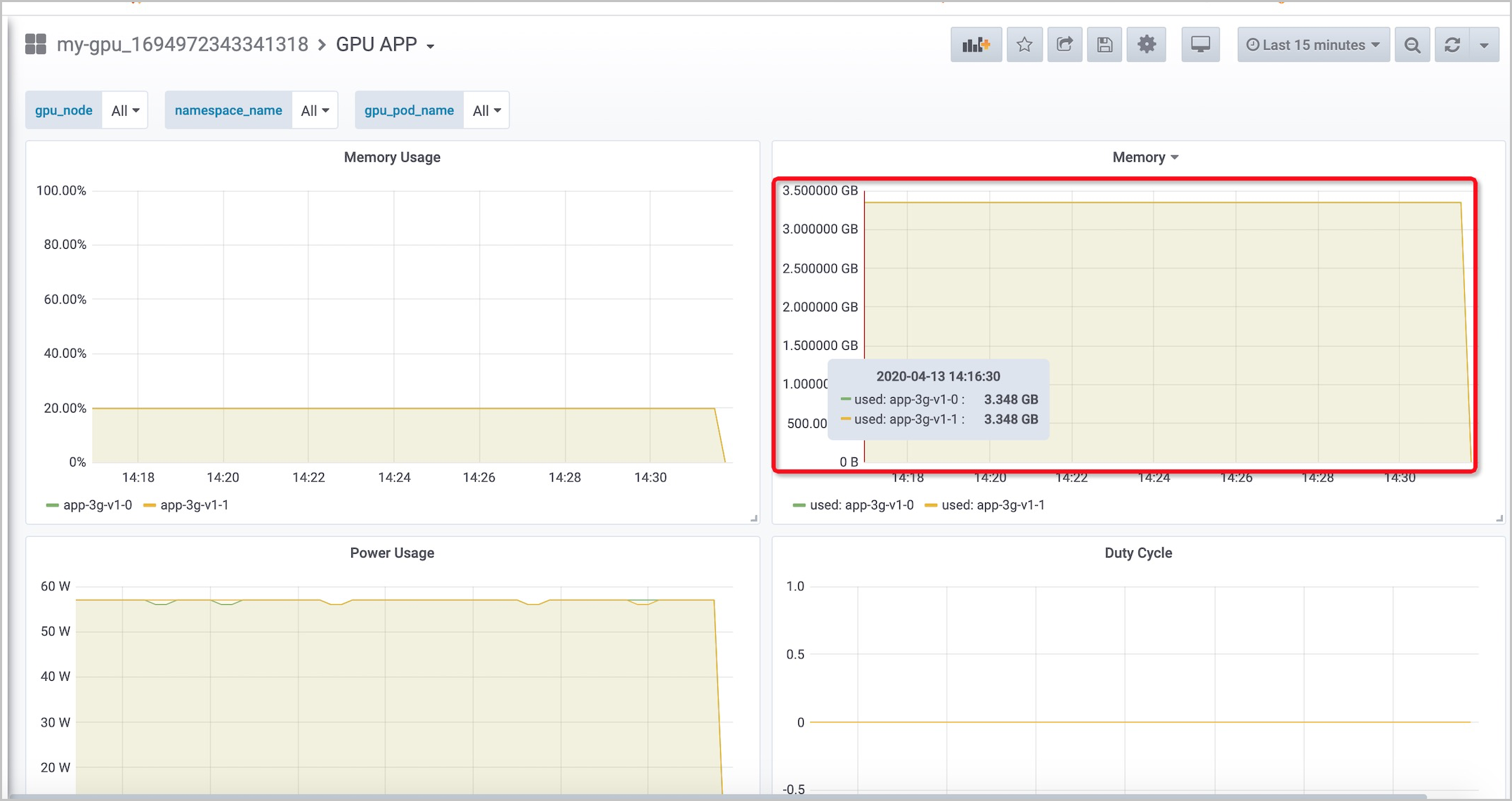
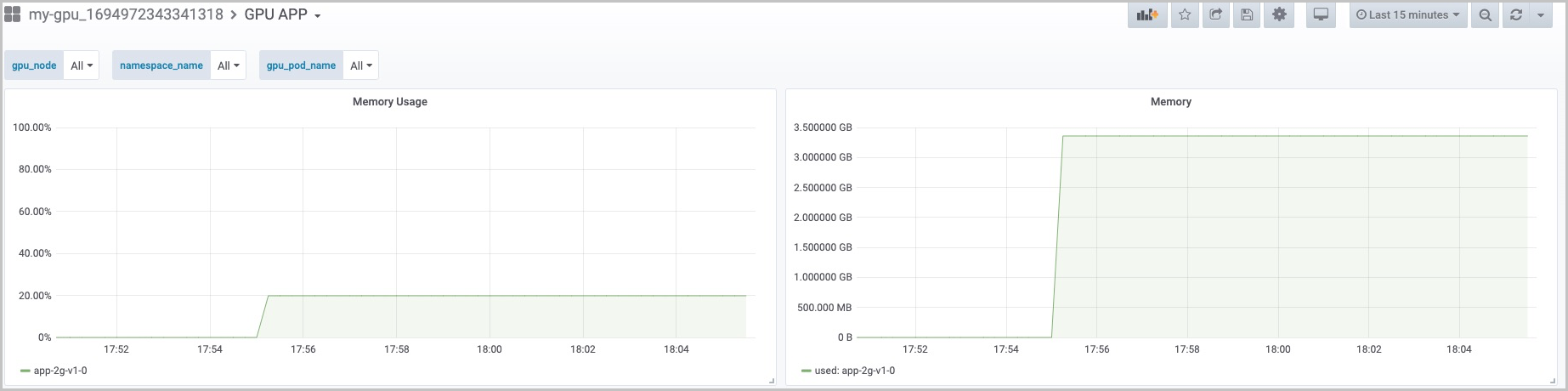
NAME READY STATUS RESTARTS AGE app-3g-v1-0 1/1 Running 1 2m56s - Temukan dan klik klaster tempat aplikasi diterapkan. Di halaman Dashboards, klik GPU APP di kolom Name.Gambar berikut menunjukkan bahwa aplikasi hanya menggunakan 20% dari Memori GPU, yang menunjukkan bahwa 80% dari Memori GPU terbuang. Total Memori GPU sekitar 16 GB. Namun, penggunaan memori stabil pada sekitar 3,4 GB. Jika Anda mengalokasikan satu GPU untuk setiap aplikasi, sejumlah besar sumber daya GPU terbuang. Untuk meningkatkan penggunaan sumber daya GPU, Anda dapat menggunakan cGPU untuk berbagi satu GPU di antara beberapa aplikasi.
Berbagi satu GPU di antara beberapa kontainer
- Tambahkan label ke node dengan akselerasi GPU.
Masuk ke Konsol ACK.
Di panel navigasi sebelah kiri Konsol ACK, klik Clusters.
Di halaman Clusters, temukan klaster yang ingin Anda kelola dan klik nama klaster tersebut, atau klik Applications di kolom Actions.
Di panel navigasi sebelah kiri halaman detail, pilih .
- Di halaman Nodes, klik Manage Labels and Taints di pojok kanan atas halaman.
- Di halaman Manage Labels and Taints, pilih node yang ingin Anda kelola dan klik Add Label.
- Di kotak dialog Add, atur Nama menjadi cgpu, atur Nilai menjadi true, lalu klik OK.Penting Jika sebuah worker node ditambahkan dengan label cgpu=true, sumber daya GPU nvidia.com/gpu tidak lagi eksklusif untuk pod di worker node tersebut. Untuk menonaktifkan cGPU untuk worker node, atur nilai cgpu menjadi false. Ini membuat sumber daya GPU nvidia.com/gpu eksklusif hanya untuk pod di worker node tersebut.
- Instal komponen cGPU.
Masuk ke Konsol ACK.
Di panel navigasi sebelah kiri Konsol ACK, pilih .
- Di halaman App Catalog, cari ack-cgpu dan klik ack-cgpu setelah muncul.
- Di bagian Deploy di sebelah kanan halaman, pilih klaster yang Anda buat, pilih namespace tempat Anda ingin menerapkan ack-cgpu, lalu klik Create.
- Masuk ke Node master dan jalankan perintah berikut untuk menanyakan sumber daya GPU.
Untuk informasi lebih lanjut, lihat Dapatkan file kubeconfig klaster dan gunakan kubectl untuk terhubung ke klaster.
kubectl inspect cgpuOutput yang Diharapkan:
NAME IPADDRESS GPU0(Allocated/Total) GPU Memory(GiB) cn-hangzhou.192.168.2.167 192.168.2.167 0/15 0/15 ---------------------------------------------------------------------- Allocated/Total GPU Memory In Cluster: 0/15 (0%)Catatan Output menunjukkan bahwa sumber daya GPU beralih dari GPU ke Memori GPU.
- Terapkan beban kerja yang berbagi sumber daya GPU.
- Ubah file YAML yang digunakan untuk menerapkan aplikasi sampel.
- Ubah jumlah pod replika dari 1 menjadi 2. Ini memungkinkan Anda menerapkan dua pod untuk menjalankan aplikasi. Sebelum mengaktifkan cGPU, GPU bersifat eksklusif untuk satu-satunya pod. Setelah mengaktifkan cGPU, GPU dibagikan oleh dua pod.
- Ubah tipe sumber daya dari
nvidia.com/gpumenjadialiyun.com/gpu-mem. Unit sumber daya GPU diubah menjadi GB.
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-3g-v1 labels: app: app-3g-v1 spec: replicas: 2 serviceName: "app-3g-v1" podManagementPolicy: "Parallel" selector: # definisikan cara deployment menemukan pods yang dikelola matchLabels: app: app-3g-v1 template: # definisikan spesifikasi pods metadata: labels: app: app-3g-v1 spec: containers: - name: app-3g-v1 image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - cuda_malloc - -size=4096 resources: limits: aliyun.com/gpu-mem: 4 # Setiap pod meminta 4 GB Memori GPU. Dua pod replika dikonfigurasi. Oleh karena itu, total 8 GB Memori GPU diminta oleh aplikasi. - Buat ulang beban kerja berdasarkan konfigurasi yang dimodifikasi.Output menunjukkan bahwa kedua pod dijadwalkan ke node yang sama dengan akselerasi GPU.
kubectl inspect cgpu -dOutput yang Diharapkan:
NAME: cn-hangzhou.192.168.2.167 IPADDRESS: 192.168.2.167 NAME NAMESPACE GPU0(Allocated) app-3g-v1-0 default 4 app-3g-v1-1 default 4 Allocated : 8 (53%) Total : 15 -------------------------------------------------------- Allocated/Total GPU Memory In Cluster: 8/15 (53%) - Jalankan perintah berikut untuk masuk ke dua kontainer satu per satu.Output menunjukkan bahwa batas Memori GPU adalah 4.301 MiB, yang berarti setiap kontainer dapat menggunakan maksimal 4.301 MiB Memori GPU.
- Jalankan perintah berikut untuk masuk ke kontainer app-3g-v1-0:
kubectl exec -it app-3g-v1-0 nvidia-smiOutput yang Diharapkan:
Mon Apr 13 01:33:10 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 37C P0 57W / 300W | 3193MiB / 4301MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+ - Jalankan perintah berikut untuk masuk ke kontainer app-3g-v1-1:
kubectl exec -it app-3g-v1-1 nvidia-smiOutput yang Diharapkan:
Mon Apr 13 01:36:07 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 38C P0 57W / 300W | 3193MiB / 4301MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+
- Jalankan perintah berikut untuk masuk ke kontainer app-3g-v1-0:
- Masuk ke node dengan akselerasi GPU untuk memeriksa penggunaan GPU.Output menunjukkan bahwa total Memori GPU yang digunakan adalah 6.396 MiB, yaitu jumlah dari memori yang digunakan oleh dua kontainer. Ini menunjukkan bahwa cGPU telah mengisolasi Memori GPU di antara kontainer. Jika Anda masuk ke kontainer dan meminta lebih banyak sumber daya GPU, kesalahan alokasi memori dilaporkan.
- Jalankan perintah berikut untuk masuk ke node dengan akselerasi GPU:
kubectl exec -it app-3g-v1-1 bash - Jalankan perintah berikut untuk menanyakan penggunaan GPU:
cuda_malloc -size=1024Output yang Diharapkan:
gpu_cuda_malloc starting... Detected 1 CUDA Capable device(s) Device 0: "Tesla V100-SXM2-16GB" CUDA Driver Version / Runtime Version 10.1 / 10.1 Total amount of global memory: 4301 MBytes (4509925376 bytes) Try to malloc 1024 MBytes memory on GPU 0 CUDA error at cgpu_cuda_malloc.cu:119 code=2(cudaErrorMemoryAllocation) "cudaMalloc( (void**)&dev_c, malloc_size)"
- Jalankan perintah berikut untuk masuk ke node dengan akselerasi GPU:
- Ubah file YAML yang digunakan untuk menerapkan aplikasi sampel.
- GPU APP: Anda dapat melihat jumlah dan persentase Memori GPU yang digunakan oleh setiap aplikasi.
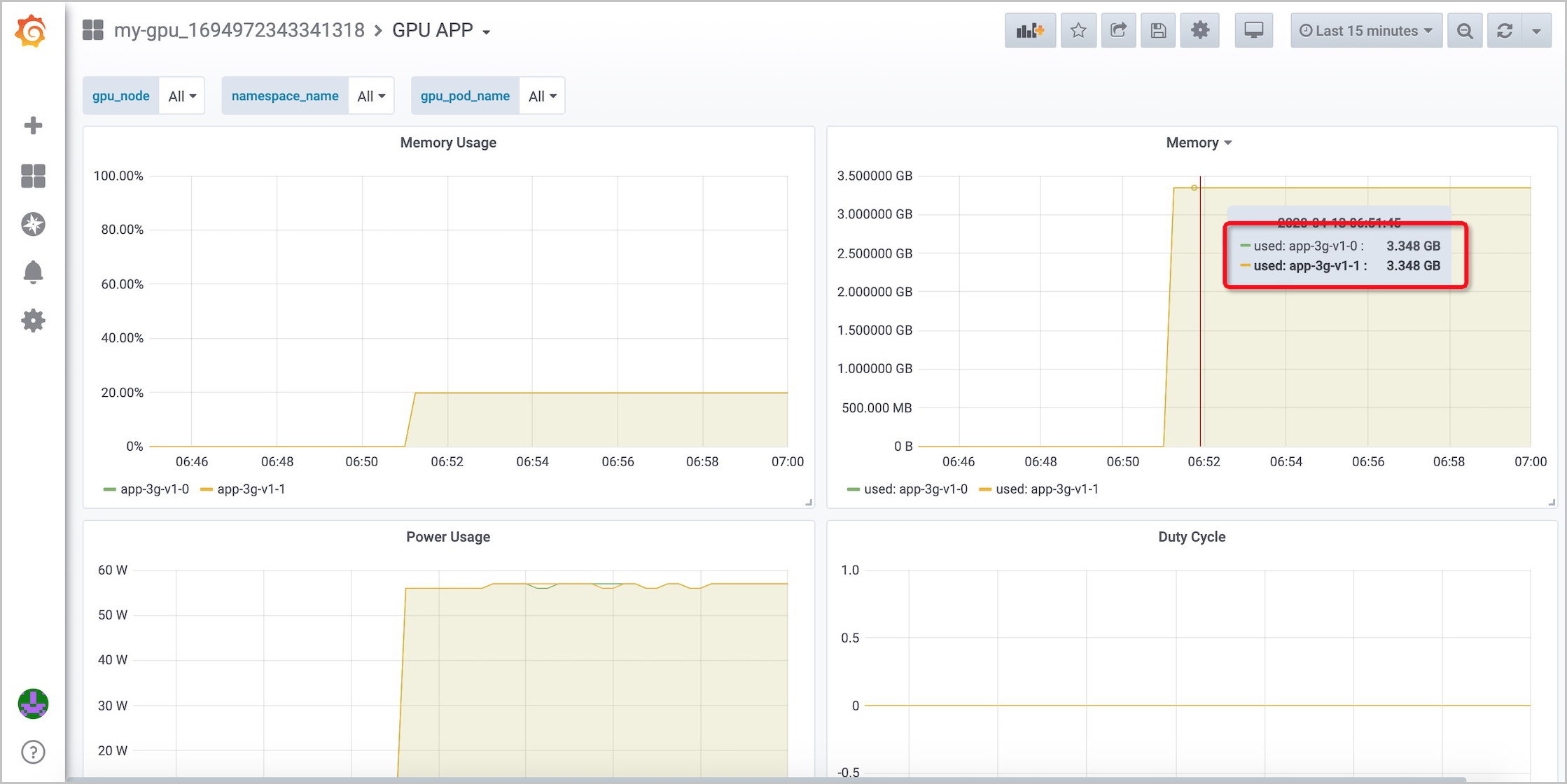
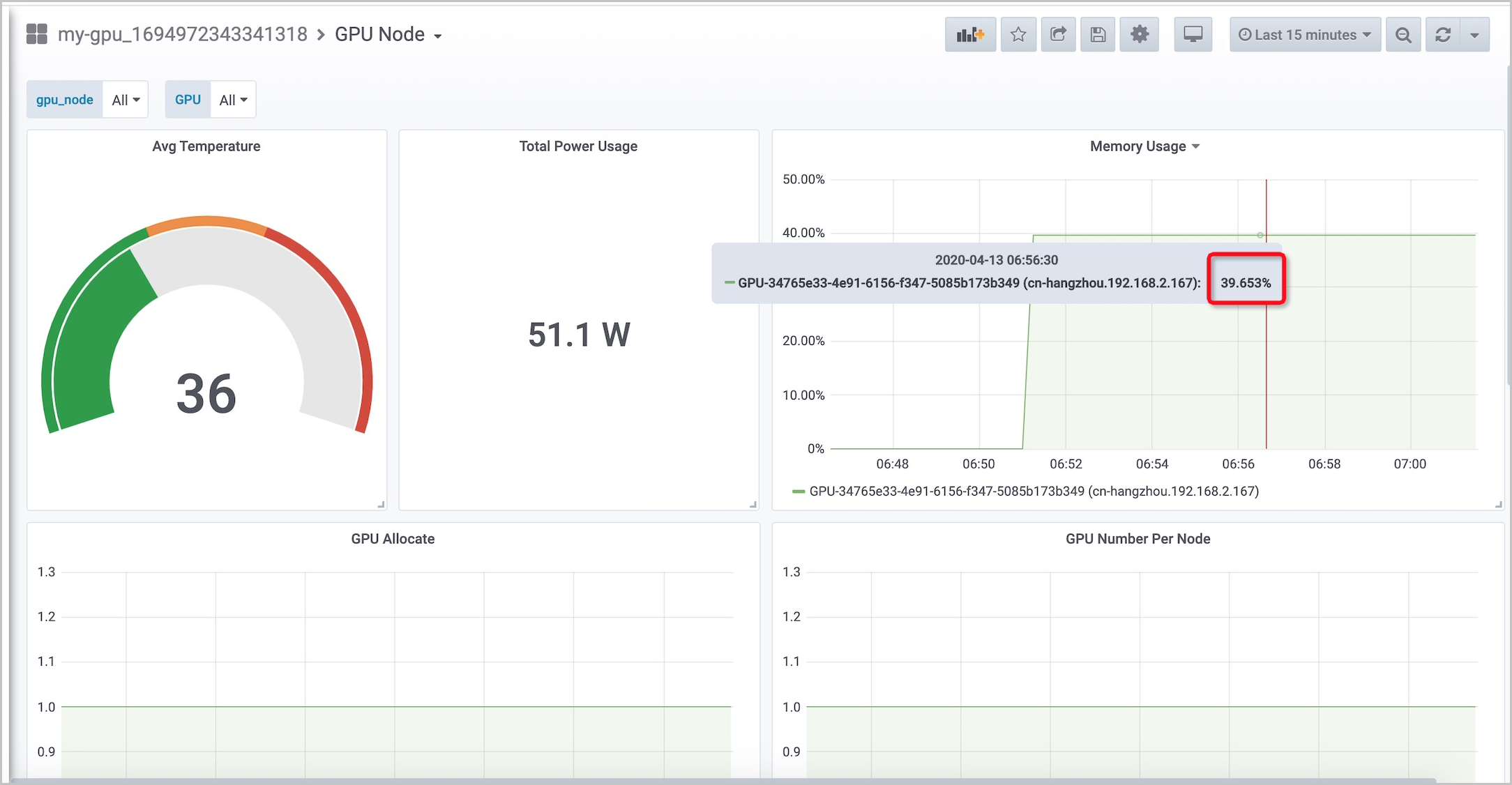
- GPU Node: Anda dapat melihat penggunaan memori setiap GPU.
Gunakan managed Prometheus plug-in untuk memantau berbagi GPU
Jika jumlah Memori GPU yang diminta oleh aplikasi melebihi batas atas, modul isolasi Memori GPU cGPU dapat mencegah aplikasi lain terpengaruh.
- Terapkan aplikasi baru yang menggunakan GPU bersama.Aplikasi meminta 4 GB Memori GPU. Namun, penggunaan memori aktual aplikasi adalah 6 GB.
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-6g-v1 labels: app: app-6g-v1 spec: replicas: 1 serviceName: "app-6g-v1" podManagementPolicy: "Parallel" selector: # definisikan cara deployment menemukan pods yang dikelola matchLabels: app: app-6g-v1 template: # definisikan spesifikasi pods metadata: labels: app: app-6g-v1 spec: containers: - name: app-6g-v1 image: registry.cn-shanghai.aliyuncs.com/tensorflow-samples/cuda-malloc:6G resources: limits: aliyun.com/gpu-mem: 4 # Setiap pod meminta 4 GB Memori GPU. Satu pod replika dikonfigurasi untuk aplikasi. Oleh karena itu, total 4 GB Memori GPU diminta oleh aplikasi. - Jalankan perintah berikut untuk menanyakan status pod.Pod yang menjalankan aplikasi baru tetap dalam keadaan CrashLoopBackOff. Dua pod yang ada berjalan normal.
kubectl get podOutput yang Diharapkan:
NAME READY STATUS RESTARTS AGE app-3g-v1-0 1/1 Running 0 7h35m app-3g-v1-1 1/1 Running 0 7h35m app-6g-v1-0 0/1 CrashLoopBackOff 5 3m15s - Jalankan perintah berikut untuk memeriksa kesalahan dalam log kontainer.Output menunjukkan bahwa kesalahan cudaErrorMemoryAllocation telah terjadi.
kubectl logs app-6g-v1-0Output yang Diharapkan:
CUDA error at cgpu_cuda_malloc.cu:119 code=2(cudaErrorMemoryAllocation) "cudaMalloc( (void**)&dev_c, malloc_size)" - Gunakan dashboard GPU APP yang disediakan oleh managed Prometheus plug-in untuk melihat status kontainer.Gambar berikut menunjukkan bahwa kontainer yang ada tidak terpengaruh setelah aplikasi baru diterapkan.