DataWorks supports PostgreSQL as a bidirectional data source for both offline (batch) and real-time synchronization. Use the codeless UI or the code editor to configure sync tasks.
Supported versions
Supported PostgreSQL versions: 10, 11, 12, 13, 14, 15, and 16.4.
To check your PostgreSQL version, run:
SHOW SERVER_VERSION;When to use real-time sync vs. offline sync
| Criteria | Recommended mode |
|---|---|
| You need to capture row deletions | Real-time sync |
| The database changes frequently and you need near-real-time data | Real-time sync |
| You need full CDC (change data capture) support | Real-time sync |
| You need a scheduled bulk transfer or one-time migration | Offline sync |
| The database does not support logical replication | Offline sync |
Real-time sync requires additional database-level prerequisites (Steps 2–4 in Prerequisites). Offline sync only requires Step 1.
Limitations
Offline read and write
Reading from views is supported.
-
Authentication: Password-based authentication is supported, including SCRAM-SHA-256. If the password or authentication method changes in the PostgreSQL database, update the data source configuration, test the connection, and manually re-run related tasks.
-
Special characters in table and field names: Table or field names that start with a digit, are case-sensitive, or contain a hyphen (
-) must be enclosed in double quotation marks (""). Because double quotation marks are a JSON keyword in the PostgreSQL Reader and Writer plugins, escape each one with a backslash (\). For example,123Testbecomes\"123Test\". Example (code editor):- Escape both the opening and closing double quotation marks. - The codeless UI does not support escaping. Switch to the code editor to escape characters.
"parameter": { "datasource": "abc", "column": [ "id", "\"123Test\"" // Escaped column name ], "where": "", "splitPk": "id", "table": "public.wpw_test" } -
Updates based on unique index: Not supported. Write data to a temporary table first, then use the
RENAMEoperation.
Real-time read
The following limitations apply to real-time sync tasks in Data Integration.
DDL operation support
| DDL operation | Supported | Notes |
|---|---|---|
ADD COLUMN |
Yes (with constraints) | Cannot be combined with other ADD COLUMN, DROP COLUMN, or DDL statements in the same transaction. Combining with DROP COLUMN or RENAME COLUMN causes the sync task to fail. |
ALTER TABLE |
No | — |
CREATE TABLE |
No | — |
TRUNCATE |
No | — |
| Other DDL operations | No | Data Integration cannot detect DDL operations other than ADD COLUMN. |
Other limitations
-
Unsupported table types: Replication of TEMPORARY, UNLOGGED, and Hyper tables is not supported. PostgreSQL does not provide a mechanism to parse logs for these table types.
-
Sequences: Replication of Sequences (
serial,bigserial,identity) is not supported. -
Large objects: Replication of large objects (Bytea) is not supported.
-
Views and foreign tables: Replication of views, materialized views, and foreign tables is not supported.
-
Table ownership: For single-table or whole-database real-time sync, only tables owned by the configured database user can be synchronized.
Supported data types
Most PostgreSQL data types are supported. For offline read and write, verify that your data types are in the list below — unsupported types are excluded from the sync.
| Category | PostgreSQL data types |
|---|---|
| Integer types | BIGINT, BIGSERIAL, INTEGER, SMALLINT, SERIAL |
| Floating-point types | DOUBLE PRECISION, MONEY, NUMERIC, REAL |
| String types | VARCHAR, CHAR, TEXT, BIT, INET |
| Date and time types | DATE, TIME, TIMESTAMP |
| Boolean type | BOOL |
| Binary type | BYTEA |
For the PostgreSQL Reader, castMONEY,INET, andBITto a compatible type using PostgreSQL cast syntax, for example:a_inet::varchar.
Prerequisites
The steps below prepare your PostgreSQL database for use with DataWorks. Steps 2–4 apply only to real-time sync.
Step 1: Create a database account and configure permissions
Create a database login account with REPLICATION and LOGIN permissions.
Real-time sync uses logical replication, which follows a publish-and-subscribe model. The subscriber pulls data changes from publications on the publisher node. Logical replication starts by copying a snapshot from the publisher database, then streams changes in real time.
-
Verify that the account has the
replicationpermission:SELECT userepl FROM pg_user WHERE usename='<username>';If the result is
False, grant the permission:ALTER USER <username> REPLICATION;
Step 2: Confirm the database is a primary (real-time sync only)
Real-time sync supports only primary databases. Run the following to check:
SELECT pg_is_in_recovery();The result must be False. If it returns True, the database is a standby. Update the data source configuration to use the primary database. For more information, see Configure a PostgreSQL data source.
Step 3: Verify that wal_level is set to logical (real-time sync only)
SHOW wal_level;The result must be logical. If it is not, logical replication is not supported on this database.
Step 4: Verify that wal_sender processes are available (real-time sync only)
-- Check the maximum number of wal_sender processes allowed.
SHOW max_wal_senders;
-- Check how many are currently in use.
SELECT COUNT(*) FROM pg_stat_replication;If max_wal_senders is greater than the count from pg_stat_replication, idle wal_sender processes are available. PostgreSQL starts a wal_sender process for each data synchronization program that sends logs to subscribers.
For each table you want to synchronize, run:
ALTER TABLE <table_name> REPLICA IDENTITY FULL;This is required. Without it, the real-time sync task reports an error.
After a real-time PostgreSQL sync task starts, DataWorks automatically creates a replication slot and a publication in the database:
-
Slot name format:
di_slot_<solution_id> -
Publication name format:
di_pub_<solution_id>After you stop or unpublish the real-time sync task, manually delete the slot and publication. If you do not, PostgreSQL Write-Ahead Logging (WAL) will continue to grow and may exhaust disk space.
Add a PostgreSQL data source
Add the PostgreSQL data source to DataWorks before developing a sync task. For instructions, see Data source management. Parameter descriptions are available in the DataWorks console when you add the data source.
If SSL authentication is enabled on your PostgreSQL database, also enable SSL authentication when adding the data source in DataWorks. For more information, see Appendix 2: Add SSL authentication to a PostgreSQL data source.
Configure a sync task
Offline sync (single table)
For a complete parameter reference and script example, see Appendix 1: Script examples and parameter descriptions.
Real-time sync and full database offline sync
FAQ
Why does data from a standby database differ from the primary?
In an active/standby disaster recovery setup, the standby continuously restores data from the primary, but a time lag exists. Network latency or high replication load can widen this gap significantly. Data synchronized from the standby is not a complete, up-to-date image of the primary. Configure the sync task to use the primary database to avoid this.
Can the PostgreSQL Reader guarantee data consistency across concurrent threads?
Not strictly. The PostgreSQL Reader uses a snapshot-based approach for single-threaded reads, so another process writing to the database during a sync does not affect the read. For concurrent reads using splitPk, each shard runs as a separate read transaction with no shared snapshot across threads, so the data is not from a single consistent point in time.
If consistency is critical, choose one of these approaches:
-
Use single-threaded sync (no
splitPk). This is slower but ensures a consistent read. -
Disable other writers during the sync window — for example, by locking tables. This affects online services.
How do I perform incremental sync?
The PostgreSQL Reader uses SELECT ... WHERE ... for data extraction. Two common patterns:
-
Timestamp-based: If your records have a
modified_ator similar field, set thewhereparameter to filter rows updated since the last sync timestamp. -
Auto-increment ID-based: Set the
whereparameter to filter rows with an ID greater than the maximum ID from the previous sync.
If your data has no field to distinguish new or updated rows, full sync is the only option.
What happens with encoding?
PostgreSQL supports only EUC_CN and UTF-8 for Simplified Chinese. The PostgreSQL Reader uses Java Database Connectivity (JDBC), which automatically detects and transcodes the encoding — no additional configuration is needed.
If the actual write encoding of the PostgreSQL database differs from its configured encoding, the Reader cannot detect or correct this, and the exported data may contain garbled characters.
Is the `querySql` parameter safe?
The querySql parameter lets you specify a custom SELECT statement. The PostgreSQL Reader does not perform any security checks on the query. Review the SQL before using this parameter in production.
Appendix 1: Script examples and parameter descriptions
Reader script example
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "postgresql",
"parameter": {
"datasource": "", // Data source name
"column": [ // Columns to sync
"col1",
"col2"
],
"where": "", // Filter condition
"splitPk": "", // Column for data sharding (enables concurrent sync)
"table": "" // Table name
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "stream",
"parameter": {},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0" // Maximum number of error records
},
"speed": {
"throttle": true, // true: throttling enabled; false: mbps has no effect
"concurrent": 1, // Number of concurrent jobs
"mbps": "12" // Throttle rate (1 mbps = 1 MB/s)
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Reader parameters
| Parameter | Description | Required | Default |
|---|---|---|---|
datasource |
Name of the data source. Must match the name used when the data source was added. | Yes | None |
table |
Name of the table to sync. | Yes | None |
column |
Columns to sync, as a JSON array. Use ["*"] to sync all columns. Supports column subsets, reordering, constants, and expressions. |
Yes | None |
splitPk |
Column used for data sharding. Enables concurrent sync. Set to the primary key for even distribution. Only integer types are supported — non-integer values cause this parameter to be ignored and single-channel sync is used. If not specified, single-channel sync is used. | No | None |
splitFactor |
Number of shards per concurrent thread. Total shards = number of concurrent threads x splitFactor. Valid range: 1–100. A large value may cause an out-of-memory (OOM) error. |
No | 5 |
where |
Filter condition. The Reader builds a SELECT query using column, table, and where. If not set, the entire table is synced. |
No | None |
querySql |
Custom SQL query for advanced filtering (not available in the codeless UI). When set, table, column, and where are ignored. Example: SELECT a, b FROM table_a JOIN table_b ON table_a.id = table_b.id. |
No | None |
fetchSize |
Number of records fetched per batch from the database. Controls network round trips between Data Integration and the server. Values greater than 2048 may cause an OOM error. | No | 512 |
Writer script example
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "stream",
"parameter": {},
"name": "Reader",
"category": "reader"
},
{
"stepType": "postgresql",
"parameter": {
"datasource": "", // Data source name
"column": [ // Destination columns
"col1",
"col2"
],
"table": "", // Destination table name
"preSql": [], // SQL to run before the sync task
"postSql": [] // SQL to run after the sync task
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"throttle": true,
"concurrent": 1,
"mbps": "12"
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Writer parameters
| Parameter | Description | Required | Default |
|---|---|---|---|
datasource |
Name of the data source. Must match the name used when the data source was added. | Yes | None |
table |
Name of the destination table. | Yes | None |
column |
Destination columns to write to, as a JSON array. Use ["*"] to write to all columns in order. For example: ["id", "name", "age"]. |
Yes | None |
writeMode |
Write mode: insert or copy. insert (default): Uses INSERT INTO ... VALUES .... If a primary key or unique index conflict occurs, the row fails and becomes dirty data. copy: Uses COPY FROM to bulk-load data. Use this if you encounter performance issues with insert mode. |
No | insert |
preSql |
SQL statements to run before the sync task. The codeless UI supports one statement; the code editor supports multiple, for example to clear old data. | No | None |
postSql |
SQL statements to run after the sync task. The codeless UI supports one statement; the code editor supports multiple, for example to add a timestamp. | No | None |
batchSize |
Number of records submitted per batch. A larger value reduces network interactions with PostgreSQL and improves throughput, but setting it too high may cause an OOM error in Data Integration. | No | 1,024 |
pgType |
Type mappings for PostgreSQL-specific types. Supported: bigint[], double[], text[], jsonb, json. |
No | None |
`pgType` example:
{
"job": {
"content": [{
"reader": {},
"writer": {
"parameter": {
"column": [
"bigint_arr",
"double_arr",
"text_arr",
"jsonb_obj",
"json_obj"
],
"pgType": {
"bigint_arr": "bigint[]",
"double_arr": "double[]",
"text_arr": "text[]",
"jsonb_obj": "jsonb",
"json_obj": "json"
}
}
}
}]
}
}Appendix 2: Add SSL authentication to a PostgreSQL data source
SSL authentication files
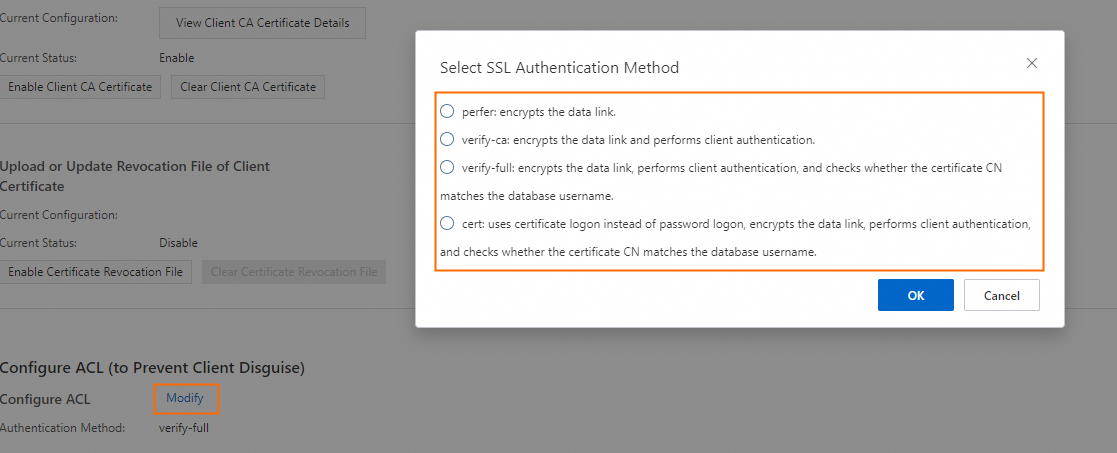
When creating or modifying a PostgreSQL data source connection in DataWorks, configure SSL authentication based on your Access Control List (ACL) mode.
| SSL link encryption | Client-based encryption | ACL mode | Files required |
|---|---|---|---|
| Enabled | Disabled | Not applicable | Truststore File (optional). If not configured, a regular connection is used. If configured, an SSL-encrypted connection is used. |
| Enabled | Enabled | prefer |
Keystore Certificate File and Private Key File (optional). The server does not enforce client verification. If Private Key File is encrypted, also configure Private Key Password. |
| Enabled | Enabled | verify-ca |
Keystore Certificate File (required), Private Key File (required), Private Key Password (required only if the private key is encrypted). |
prefer: The PostgreSQL server does not forcibly verify the client certificate. If no SSL files are configured, a regular connection is used.verify-ca: All three files are required. The server verifies the client certificate before establishing the connection.Obtain the SSL authentication files
This section uses an ApsaraDB RDS for PostgreSQL instance as an example.
Obtain the Truststore File
For full instructions, see Use a cloud certificate to quickly enable SSL encryption.
-
Go to the RDS Instances page, locate the RDS instance, and click the instance ID.
-
Select the connection string to protect.
- If a public endpoint is enabled, both an internal and a public endpoint are displayed. A cloud certificate can protect only one endpoint. Protect the public endpoint, as it is exposed to the internet; the internal endpoint is more secure within the VPC. See View internal and public endpoints. - To protect both endpoints, see Use a custom certificate to enable SSL encryption. - After configuring the cloud certificate, the instance Running Status changes to Modifying SSL for about three minutes. Wait until it returns to Running before continuing.
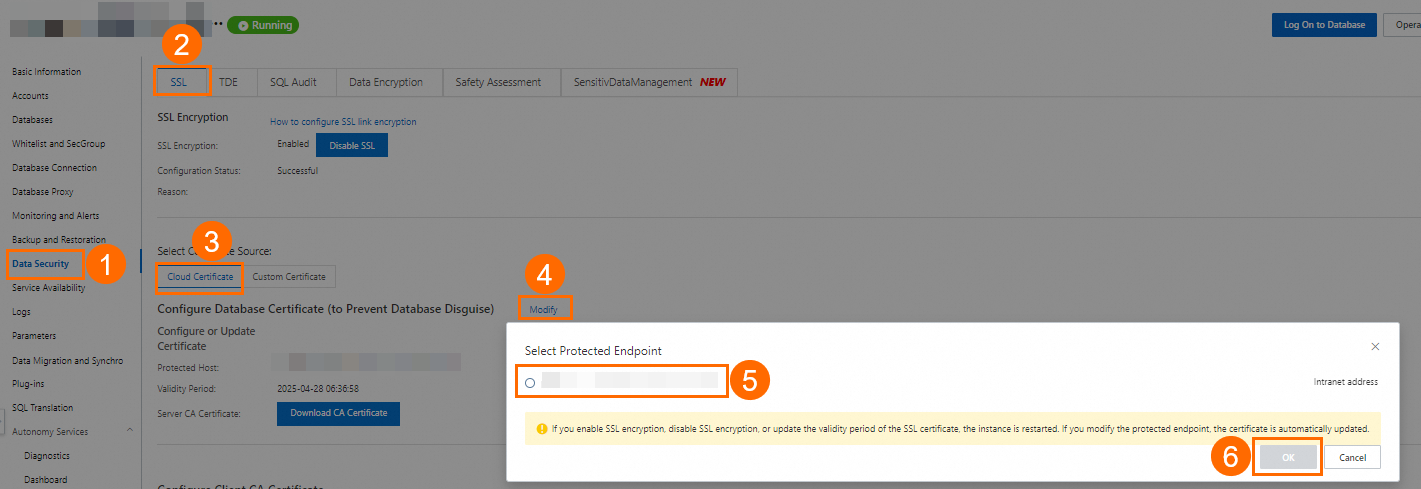
-
Click Download CA Certificate. The downloaded package contains three files. Upload the
.pemor.p7bfile to the Truststore File field in DataWorks.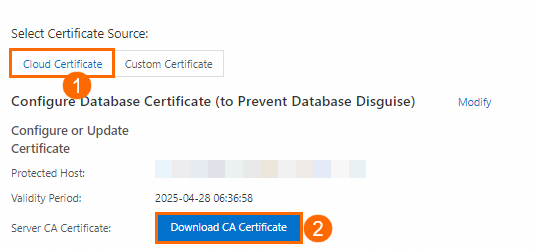
Obtain the Keystore File, Private Key File, and Private Key Password
Prerequisites: SSL encryption is enabled on the RDS instance (via cloud or custom certificate), and OpenSSL is installed.
Linux includes OpenSSL by default. For Windows, download and install the OpenSSL package.
For full instructions, see Configure a client CA certificate.
-
Generate a self-signed certificate (
ca1.crt) and private key (ca1.key):openssl req -new -x509 -days 3650 -nodes -out ca1.crt -keyout ca1.key -subj "/CN=root-ca1" -
Generate a client certificate signing request (CSR) and client private key. Set the CN value to the database username:
openssl req -new -nodes -text -out client.csr -keyout client.key -subj "/CN=<client_username>" -
Generate the client certificate (
client.crt):openssl x509 -req -in client.csr -text -days 365 -CA ca1.crt -CAkey ca1.key -CAcreateserial -out client.crt -
If the RDS server needs to verify the client CA certificate, open
ca1.crt, copy its content, and paste it into the Enter Public Key from Client Certificate Authority dialog box.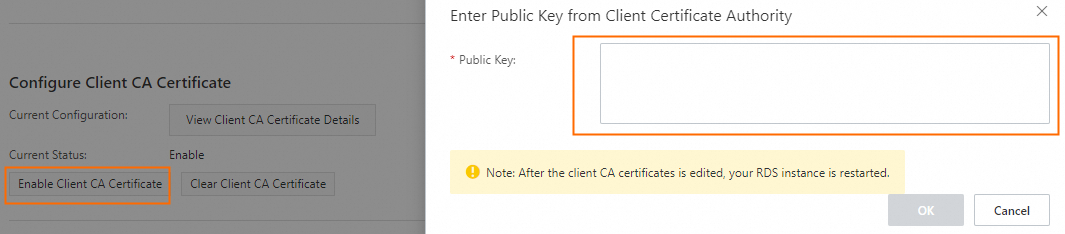
-
Convert the client private key to PKCS#8 format (
client.pk8). Upload this file to the Private Key File field in DataWorks.cp client.key client.pk8 -
(Optional) To password-protect the private key, run:
openssl pkcs8 -topk8 -inform PEM -in client.key -outform der -out client.pk8 -v1 PBE-MD5-DESYou will be prompted to set a password. Use the same password for the Private Key Password field in the DataWorks PostgreSQL data source configuration.
Configure SSL authentication files in DataWorks
Upload the certificate files when creating or editing the PostgreSQL data source:
-
Truststore File: Upload the
.pemor.p7bfile from step 3 of Obtain the Truststore File. -
Keystore File: Upload
client.crtfrom step 3 of Obtain the Keystore File, Private Key File, and Private Key Password. -
Private Key File: Upload
client.pk8from step 5 of Obtain the Keystore File, Private Key File, and Private Key Password. -
Private Key Password: The password set in step 6 (if applicable).
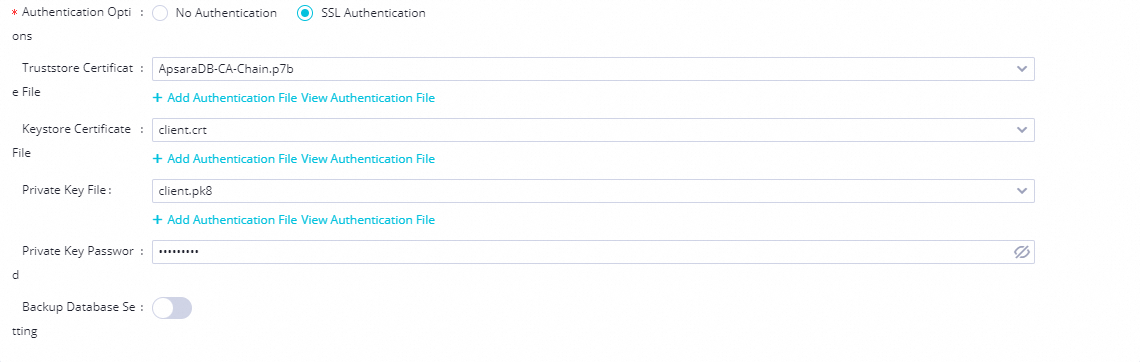
To set the Configure ACL mode: Go to the RDS Instances page, click the instance ID, then go to Data Security > Configure ACL. For more information, see Force clients to use SSL connections.
prefer: The PostgreSQL server does not forcibly verify the client certificate.verify-ca: Upload the correct client certificate in DataWorks so the server can verify the client's identity.