PolarDB for PostgreSQL integrates the open-source graph engine Apache AGE, bringing graph database capabilities to your existing PostgreSQL cluster. Use openCypher — a declarative graph query language that is an open-source subset of the Cypher query language — to create, query, update, and delete graph data alongside standard SQL in the same cluster. PolarDB also supports Gremlin as a graph query language.
Graph databases model data as nodes and edges, making them well-suited for workloads involving complex relationships: social networks, knowledge graphs, fraud detection, and recommendation systems. If you have a SQL background, openCypher will feel familiar — its declarative syntax is similar to SQL's SELECT ... WHERE pattern.
Key concepts
Cypher uses ASCII-art syntax to represent graph structures visually. Round brackets () represent nodes — shaped like circles in a graph diagram. Square brackets with arrows -[]-> represent directed edges between nodes. This visual correspondence means you can often read a Cypher pattern the same way you would draw it on a whiteboard.
Graph: A data structure composed of nodes and edges. A social network is a classic example: each person is a node, and their relationships (friendships, follows, professional connections) are edges.

Node: A basic element that represents an entity, such as a person, company, or movie. Nodes can have properties — key-value pairs that store information about the entity. In Cypher, write a node as
(variable:Label {key: 'value'}).Edge: A connection between two nodes that represents a relationship. Edges can be directed or undirected and can carry properties such as weight or role. In Cypher, write a directed edge as
-[variable:TYPE {key: 'value'}]->.Label: A classification that categorizes nodes or edges. Labels add semantic meaning and make queries more precise. For example, nodes can have the label
PersonorMovie, and edges can have the labelACTED_INorDIRECTED.Property graph: A graph model in which both nodes and edges carry properties. The following figure shows a property graph of professional relationships.

Cypher syntax reference
Properties are key-value pairs enclosed in {}. The key is a string; the value can be a string, number, or array.
{name: 'Reeves'}
{title: 'The Matrix', released: 1997}Node syntax:
() -- anonymous, unlabeled node
(matrix) -- node with a variable
(:Movie) -- node with a label constraint
(matrix:Movie) -- variable + label
(matrix:Movie {title: 'The Matrix'}) -- variable + label + property
(matrix:Movie {title: 'The Matrix', released: 1997})Variables are scoped to a single statement. The label constraint :Movie limits pattern matches to nodes with that label.
Edge syntax:
-- -- undirected edge
--> -- directed edge (anonymous)
-[role]-> -- directed edge with a variable
-[:ACTED_IN]-> -- directed edge with a type label
-[role:ACTED_IN]-> -- variable + type
-[role:ACTED_IN {roles: ['Neo']}]-> -- variable + type + propertyQuery structure
In PolarDB, wrap Cypher queries in the cypher() function from the ag_catalog schema. The function returns a set of records.
SELECT * FROM cypher('graph_name', $$
/* Your Cypher query */
$$) AS (result1 agtype, result2 agtype);Prerequisites
Before you begin, ensure that you have:
A PolarDB for PostgreSQL cluster that meets the version requirements listed above
A privileged account on the cluster. For instructions, see Create a database account
Set up the extension
Install the AGE extension
You cannot create the age extension manually. Submit a ticket to have Alibaba Cloud create it for you.
After the extension is created, enable it:
CREATE EXTENSION age;Configure the connection
For each connection, add ag_catalog to the search_path and load the extension:
SET search_path = ag_catalog, "$user", public;
SELECT * FROM get_cypher_keywords() limit 0;To avoid repeating this for every connection, use a privileged account to set it permanently at the database level:
ALTER DATABASE <dbname> SET search_path = "$user", public, ag_catalog;
ALTER DATABASE <dbname> SET session_preload_libraries TO 'age';Compatibility issues may occur when you use Data Management (DMS) to configure the search_path. In such cases, you can use to execute related statements.
Grant access to regular users
Grant the USAGE permission on ag_catalog to allow regular users to query graph data:
GRANT USAGE ON SCHEMA ag_catalog TO <username>;If the user needs to create tables (read/write user), also grant the CREATE permission:
GRANT CREATE ON DATABASE <dbname> TO <username>;Work with graph data
This section walks through a complete graph workflow using a movie database. The examples build on each other — run them in order.
Create a graph
Create a graph named moviedb:
SELECT create_graph('moviedb');Insert data
Insert sample data representing movies and the people who worked on them:
SELECT * FROM cypher('moviedb', $$
CREATE (matrix:Movie {title: 'The Matrix', released: 1997})
CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964})
CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)
$$) AS (result1 agtype);This creates 6 nodes (3 Movie, 3 Person) and 3 edges (2 ACTED_IN, 1 DIRECTED):

Query data
Use MATCH to find nodes or edges that match a pattern, and RETURN to specify what to return.
Find all movies:
SELECT * FROM cypher('moviedb', $$
MATCH (m:Movie)
RETURN m
$$) AS (result1 agtype);Expected output (3 rows):
| result1 |
|---|
{"id": ..., "label": "Movie", "properties": {"title": "The Matrix", "released": 1997}}::vertex |
{"id": ..., "label": "Movie", "properties": {"title": "Cloud Atlas", "released": 2012}}::vertex |
{"id": ..., "label": "Movie", "properties": {"title": "Forrest Gump", "released": 1994}}::vertex |
Find all `ACTED_IN` edges:
SELECT * FROM cypher('moviedb', $$
MATCH (:Person)-[r:ACTED_IN]->(:Movie)
RETURN r
$$) AS (result1 agtype);Expected output (2 rows):
| result1 |
|---|
{"id": ..., "label": "ACTED_IN", "properties": {"roles": ["Forrest"]}}::edge |
{"id": ..., "label": "ACTED_IN", "properties": {"roles": ["Zachry"]}}::edge |
Filter results
Add a WHERE clause to filter results with a Boolean expression.
Find a specific movie by title:
SELECT * FROM cypher('moviedb', $$
MATCH (m:Movie)
WHERE m.title = 'The Matrix'
RETURN m
$$) AS (result1 agtype);Find actors in a specific movie:
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person)-[:ACTED_IN]->(m)
WHERE m.title = 'Forrest Gump'
RETURN p
$$) AS (result1 agtype);Find actors in movies released after 2000:
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person)-[:ACTED_IN]->(m)
WHERE m.released > 2000
RETURN p, m
$$) AS (result1 agtype, result2 agtype);Create a node or edge
Use CREATE to add new nodes or edges.
Add a person:
SELECT * FROM cypher('moviedb', $$
CREATE (:Person {name: 'Tom Tykwer', born: 1965})
$$) AS (result1 agtype);Add a directed edge between existing nodes:
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person), (m:Movie)
WHERE p.name='Tom Tykwer' AND m.title='Cloud Atlas'
CREATE (p)-[:DIRECTED]->(m)
$$) AS (result1 agtype);Use MERGE to avoid duplicate data
Running CREATE multiple times inserts duplicate records. Use MERGE instead to perform an upsert: if the node or edge already exists, MERGE returns it as-is; if not, it creates it.
Add a person (no duplicate if run again):
SELECT * FROM cypher('moviedb', $$
MERGE (:Person {name: 'Tom Cruise', born: 1962})
$$) AS (result1 agtype);Add an undirected friendship edge:
SELECT * FROM cypher('moviedb', $$
MATCH (t1:Person),(t2:Person)
WHERE t1.name='Tom Hanks' AND t2.name='Tom Cruise'
MERGE (t1)-[:FRIEND]-(t2)
$$) AS (result1 agtype);Update properties
Use SET to add or update properties on existing nodes or edges.
Update a property value:
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person {name: 'Tom Tykwer', born: 1965})
SET p.born = 1970
RETURN p
$$) AS (result1 agtype);Add a new property:
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person {name: 'Tom Tykwer', born: 1970})
SET p.gender = 'male'
RETURN p
$$) AS (result1 agtype);Delete nodes and edges
Delete an edge
Match the edge and then delete it:
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person)-[r:DIRECTED]->(m:Movie)
WHERE p.name='Tom Tykwer' AND m.title='Cloud Atlas'
DELETE r
$$) AS (result1 agtype);Delete a node
Match the node and then delete it. The node must have no associated edges before you can delete it.
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person {name: 'Tom Tykwer', born: 1970})
DELETE p
$$) AS (result1 agtype);Delete a node and its edges
Use DETACH DELETE to delete a node along with all its associated edges in one operation:
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person {name: 'Tom Hanks', born: 1956})
DETACH DELETE p
$$) AS (result1 agtype);Remove a property
Use REMOVE to delete a specific property from a node or edge:
SELECT * FROM cypher('moviedb', $$
MATCH (m:Movie {title: 'Cloud Atlas', released: 2012})
REMOVE m.released
RETURN m
$$) AS (result1 agtype);Explore graph relationships
The examples above cover individual CRUD operations. This section demonstrates what makes graph databases distinct: traversing relationships across multiple hops in a single query — something that requires complex joins in SQL.
Find all people connected to a movie through any relationship (actors, directors, and so on):
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person)-[r]->(m:Movie {title: 'Forrest Gump'})
RETURN p.name, type(r)
$$) AS (name agtype, relationship agtype);Expected output:
| name | relationship |
|---|---|
"Tom Hanks" | "ACTED_IN" |
"Robert Zemeckis" | "DIRECTED" |
Find people who share a connection to the same movie (two-hop traversal):
SELECT * FROM cypher('moviedb', $$
MATCH (p1:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(p2:Person)
RETURN p1.name AS actor, m.title AS movie, p2.name AS director
$$) AS (actor agtype, movie agtype, director agtype);Expected output:
| actor | movie | director |
|---|---|---|
"Tom Hanks" | "Forrest Gump" | "Robert Zemeckis" |
This kind of pattern traversal — finding actors and directors connected through a shared movie — requires a single Cypher MATCH clause. In SQL, it would require multiple self-joins on separate tables.
Visualization
PolarDB for PostgreSQL integrates Apache AGE, letting you use standard SQL and openCypher in the same cluster to store, query, and analyze graph data. The built-in visualization tool renders query results as graphs, making it easier to explore complex relationships.
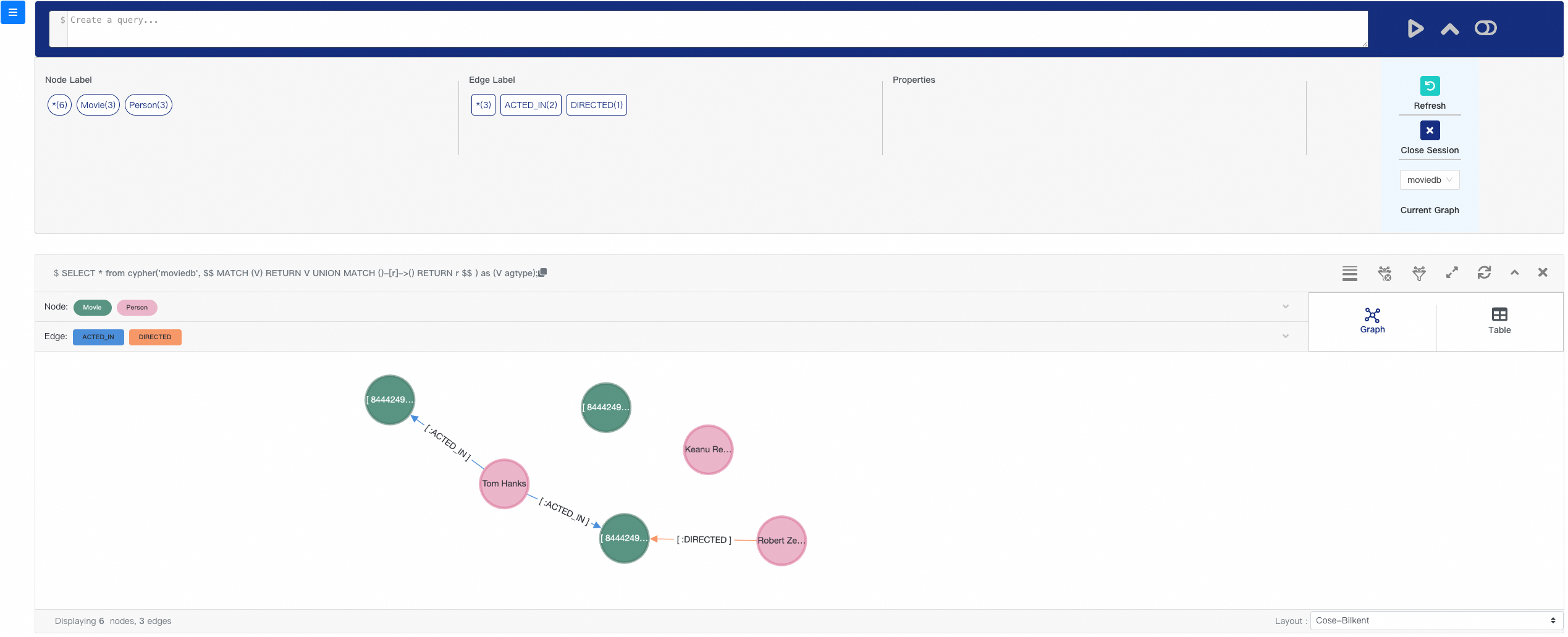
For more information, see Graph applications.
What's next
Explore the full openCypher clause reference in the Graph applications documentation
View the minor engine version to verify your cluster meets the requirements
Upgrade the minor engine version if needed