Scorecard prediction is a machine learning technique that applies a scorecard model to score new data and predict its future performance or risk. The model is typically generated by a scorecard training component. The scorecard prediction component uses this model to evaluate and score input data, which facilitates decision-making and risk management.
Configure the component
Method 1: Use the UI
In the Designer workflow, add the Scorecard Prediction component and configure its parameters in the pane on the right:
|
Parameter Type |
Parameter |
Description |
|
Field settings |
Feature columns |
Select the original feature columns for prediction. By default, all columns are selected. |
|
Write to the sink table without transformation |
Select columns to append to the prediction result table without any processing, such as ID and target columns. |
|
|
Output variable score |
Specifies whether to output the score for each feature variable. The final total prediction score is the sum of the intercept's score and all variable scores. |
|
|
Execution tuning |
Number of cores |
The number of CPU cores to use. The system allocates this automatically by default. |
|
Memory per core |
The amount of memory for each CPU core. The system allocates this automatically by default. |
Method 2: Use a PAI command
You can use a PAI command to configure the parameters for the Scorecard Prediction component. Use the SQL script component to call the PAI command. For more information, see SQL Script.
pai -name=lm_predict
-project=algo_public
-DinputFeatureTableName=input_data_table
-DinputModelTableName=input_model_table
-DmetaColNames=sample_key,label
-DfeatureColNames=fea1,fea2
-DoutputTableName=output_score_table|
Parameter |
Required |
Default value |
Description |
|
inputFeatureTableName |
Yes |
None |
The input feature data table. |
|
inputFeatureTablePartitions |
No |
The entire table |
The partitions to select from the input feature table. |
|
inputModelTableName |
Yes |
None |
The input model table. |
|
featureColNames |
No |
All columns |
The feature columns to select from the input table. |
|
metaColNames |
No |
None |
Data columns that are not transformed. The selected columns are output as is. Specify columns such as the label and sample_id here. |
|
outputFeatureScore |
No |
false |
Specifies whether to output variable scores in the prediction result. Valid values:
|
|
outputTableName |
Yes |
None |
The output prediction result table. |
|
lifecycle |
No |
None |
The lifecycle of the output table. |
|
coreNum |
No |
Calculated automatically |
The number of cores. |
|
memSizePerCore |
No |
Calculated automatically |
The memory size in MB. |
Component output
The Scorecard Prediction component outputs a scoring table, as shown in the following example: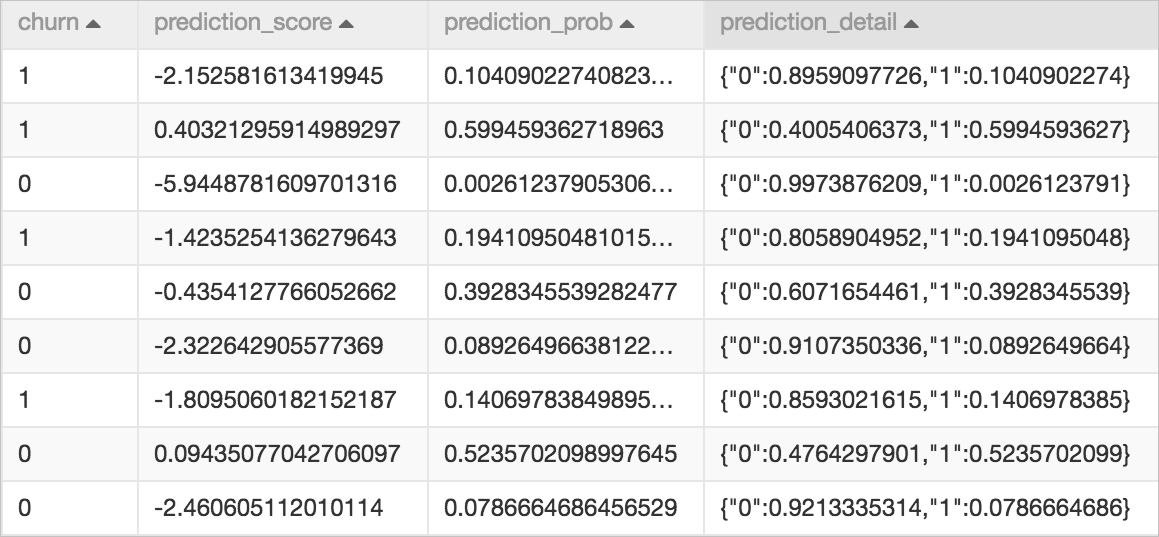 The churn column is added to the result table as is and is not related to the prediction result. The other three columns are prediction result columns, which are described in the following table.
The churn column is added to the result table as is and is not related to the prediction result. The other three columns are prediction result columns, which are described in the following table.
|
Column name |
Column type |
Column description |
|
prediction_score |
DOUBLE |
The prediction score column. In a linear model, this is the result of multiplying the feature values by the model weight values and then summing them. In a scorecard model, if the model performs score transformation, this column outputs the transformed score. |
|
prediction_prob |
DOUBLE |
In a binary classification scenario, this is the predicted probability value of the positive sample. This value is obtained by applying a Sigmoid transformation to the original score (before score transformation). |
|
prediction_detail |
STRING |
The probability values for each class, described in JSON format. 0 represents the negative class, and 1 represents the positive class. For example: {“0”:0.1813110520,”1”:0.8186889480}. |