Mixtral-8x7B is the latest large language model (LLM) released by Mistral AI, which outperforms the GPT-3.5 model on various benchmark tests and is one of the most advanced open source LLMs. Platform for AI (PAI) provides full support for the Mixtral-8x7B model. PAI allows developers and enterprise users to fine-tune and deploy the Mixtral-8x7B model based on Model Gallery in an efficient manner.
Model introduction
Mixtral-8x7B is a Sparse Mixture of Experts (SMoE) open source LLM based on the encoder (decoder-only) architecture and released by using the Apache 2.0 protocol. Mixtral-8x7B stands out due to its router network, which selects two out of eight expert groups to process each token, and accumulates and combines their outputs. As a result, only 13 billion are actively used per token even though Mixtral-8x7B has a total of 47 billion parameters. This improves the inference speed, which is comparable to a model with 13 billion parameters.
Mixtral-8x7B supports multiple languages, including French, German, Spanish, Italian, and English, and a context length of 32,000 tokens. Mixtral-8x7B matches or exceeds the performance of LLaMA2-70B and GPT-3.5 models across all evaluated benchmark tests. Mixtral-8x7B significantly outperforms the LLaMA2-70B model especially in mathematics, code generation, and multilingual benchmark tests.
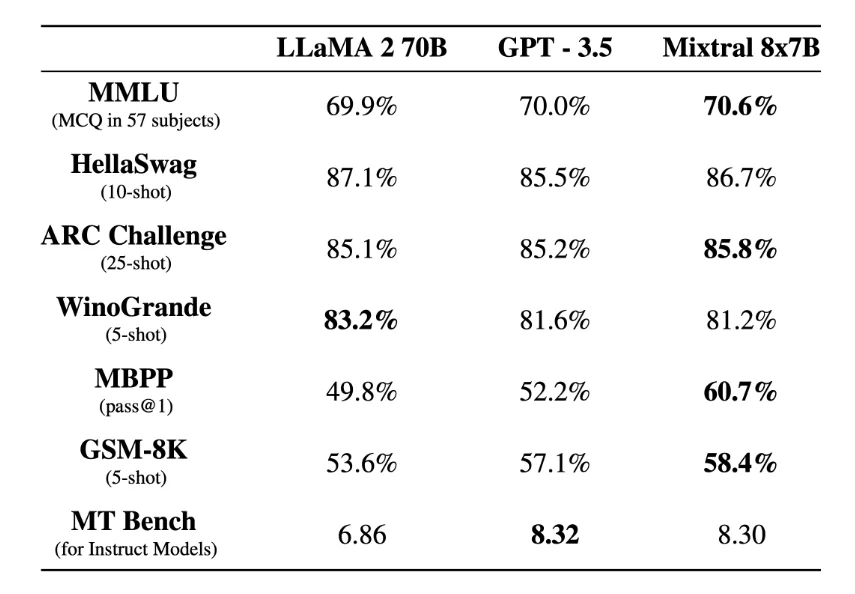
Source: https://arxiv.org/abs/2401.04088
Mistral AI also released Mixtral-8x7B-Instruct-v0.1, which is an instruction-tuned version of Mixtral-8x7B. This version is optimized by using supervised fine-tuning and Direct Preference Optimization (DPO). This makes Mixtral-8x7B-Instruct-v0.1 well follow human instructions and improves its conversational capabilities ahead of other open source instruction-tuned models.
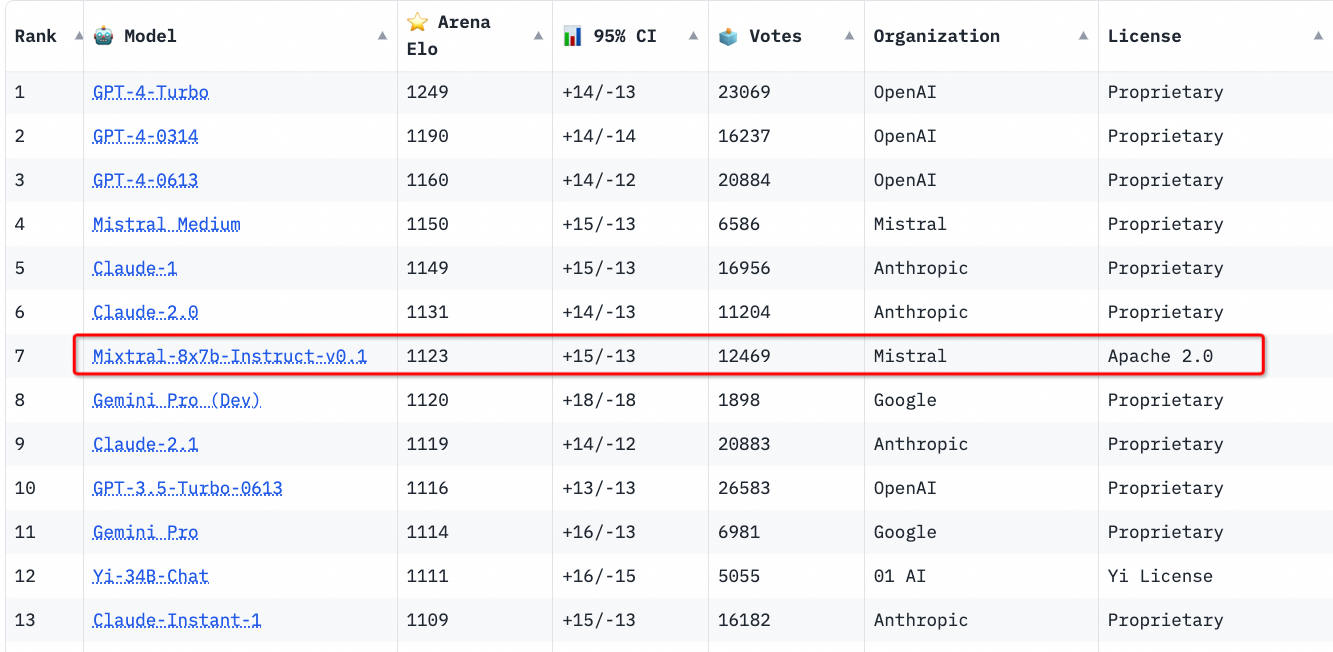
Source: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Prerequisites
Lingjun resources are purchased. For more information, see Create a resource group and purchase Lingjun resources.
Environment requirements
Mixtral-8x7B can be run only in the China (Ulanqab) region and on Lingjun clusters due to its large size.
We recommend that you use the GU108 (80 GB) GPU. At least two GPUs are required for inference and at least four GPUs are required for Low-Rank Adaptation (LoRA) fine-tuning.
Use a model in the PAI console
Deploy and call a model service
Go to the Model Gallery page.
Log on to the PAI console.
Select the China (Ulanqab) region.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
In the left-side navigation pane, choose QuickStart > Model Gallery.
In the model list of the Model Gallery page, click the Mixtral-8x7B-Instruct-v0.1 card.
On the model details page, click Deploy in the upper-right corner. In the Deploy panel, configure the Lingjun computing resources and click Deploy.
The model requires Lingjun resources for deployment. Make sure that you select a resource quota that has at least two GU108 GPUs.
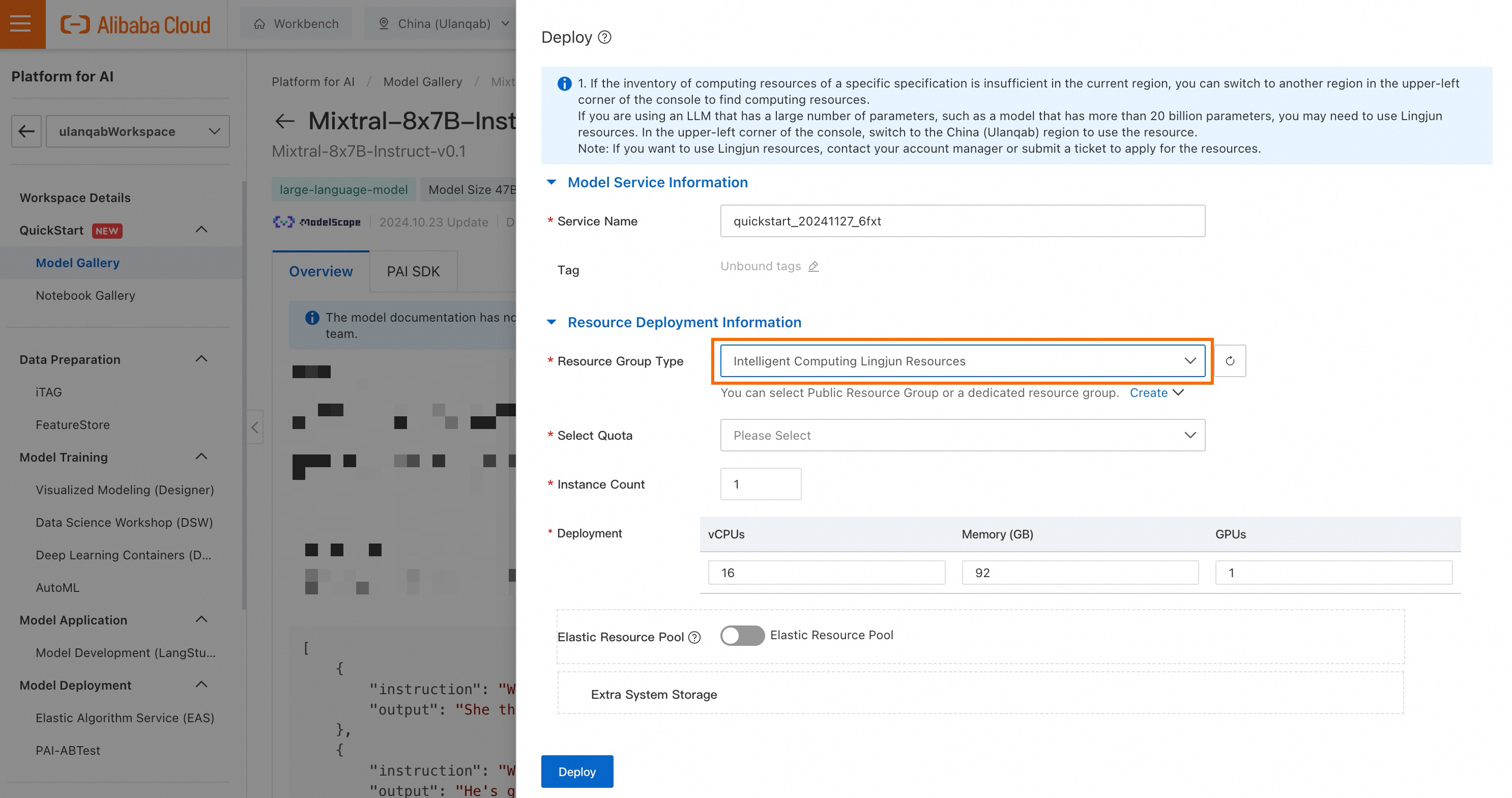
Call the model service.
Use the HTTP API
You can call the model service by using the OpenAI API. You can obtain the endpoint and token of the model service on the model service details page. The following sample code provides an example on how to call a model service by running curl commands:
# Replace <ENDPOINT> and <TOKEN> with the endpoint and token of your model service. export API_ENDPOINT="<ENDPOINT>" export API_TOKEN="<TOKEN>" # View the model list. curl $API_ENDPOINT/v1/models \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $API_TOKEN" # Call a general-purpose text generation API. curl $API_ENDPOINT/v1/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $API_TOKEN" \ -d '{ "model": "Mixtral-8x7B-Instruct-v0.1", "prompt": "San Francisco is a", "max_tokens": 256, "temperature": 0 }' curl $API_ENDPOINT/v1/chat/completions \ -H "Authorization: Bearer $API_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "model": "Mixtral-8x7B-Instruct-v0.1", "messages": [ {"role": "user", "content": "Introduce the history of Shanghai"} ] }'Use the SDK
Before you call a model service by using the OpenAI SDK, you must install the SDK.
# Install the SDK. python -m pip install openaiThe following sample code provides an example on how to call a model service by using an SDK:
import openai # Replace <ENDPOINT> and <TOKEN> with the endpoint and token of your model service that you obtained on the model service details page. openai.api_key = "<TOKEN>" openai.base_url = "<ENDPOINT>" + "/v1" # Call a chat API. completion = openai.chat.completions.create( model="Mixtral-8x7B-Instruct-v0.1", temperature=0.0, top_p=0.8, frequency_penalty=0.0, messages=[{"role": "user", "content": "Introduce yourself."}], # stream=True, ) # Print the output content. print(completion.choices[0].message.content)
Train a model
Model Gallery provides an out-of-the-box fine-tuning algorithm for the Mixtral-8x7B-Instruct-v0.1 model.
The fine-tuning algorithm supports inputs in the JSON format. Each data record consists of a query that is specified by the instruction field and a response that is specified by the output field. Example:
[
{
"instruction": "Write a poem on a topic 'On a Political Prisoner': \n",
"output": "She that but little patience knew,\r\nFrom childhood on, had now so much\r\nA grey gull lost its fear and flew\r\nDown to her cell and there alit,\r\nAnd there endured her fingers' touch\r\nAnd from her fingers ate its bit.\r\nDid she in touching that lone wing."
},
{
"instruction": "Write a poem on a topic 'To His Love': ",
"output": "He's gone, and all our plans\r\n Are useless indeed.\r\nWe'll walk no more on Cotswold\r\n Where the sheep feed\r\n Quietly and take no heed.\r\n His body that was so quick\r\n Is not as you\r\nKnew it, on Severn river\r\n Under the blue\r\n Driving our small boat through."
}
]On the model details page, click Train in the upper-right corner. In the Train panel, configure the following key parameters:
Dataset Configuration: You can specify the Object Storage Service (OSS) path that contains datasets you prepared or select a dataset file that is stored in File Storage NAS (NAS) or Cloud Parallel File Storage (CPFS). You can also select the default path to use the public datasets provided by PAI.
Computing resources: The fine-tuning algorithm requires 4 GU108 GPUs with 80 GB of memory. Make sure that the resource quota you use has sufficient computing resources.
Hyper-parameters: The following table describes the hyperparameters of the fine-tuning algorithm. Configure the hyperparameters based on your business requirements.
Hyperparameter
Type
Default value
Required
Description
learning_rate
float
5e-5
Yes
The learning rate, which controls the extent to which the model is adjusted.
num_train_epochs
int
1
Yes
The number of epochs. An epoch is a full cycle of exposing each sample in the training dataset to the algorithm.
per_device_train_batch_size
int
1
Yes
The number of samples that each GPU processes in one training iteration. A higher value results in higher training efficiency and memory usage.
seq_length
int
128
Yes
The sequence length. The length of the input data that the model processes at a time.
lora_dim
int
16
No
The inner dimensions of the low-rank matrices that are used in Low-Rank Adaptation (LoRA) or QLoRA training. Set this parameter to a value greater than 0.
lora_alpha
int
32
No
The LoRA or QLoRA weights. This parameter takes effect only if you set the lora_dim parameter to a value greater than 0.
load_in_4bit
bool
true
No
Specifies whether to load the model in 4-bit quantization.
load_in_8bit
bool
false
No
Specifies whether to load the model in 8-bit quantization.
gradient_accumulation_steps
int
8
No
The number of gradient accumulation steps.
apply_chat_template
bool
true
No
Specifies whether the algorithm combines the training data with the default chat template. For example:
Question:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n + instruction + <|eot_id|>Answer:
<|start_header_id|>assistant<|end_header_id|>\n\n + output + <|eot_id|>
Click Train. On the details page of the training job, you can view the status and logs of the training job.
Click the More drop-down list and select Tensorboard in the upper-right corner to view the convergence status of the model.
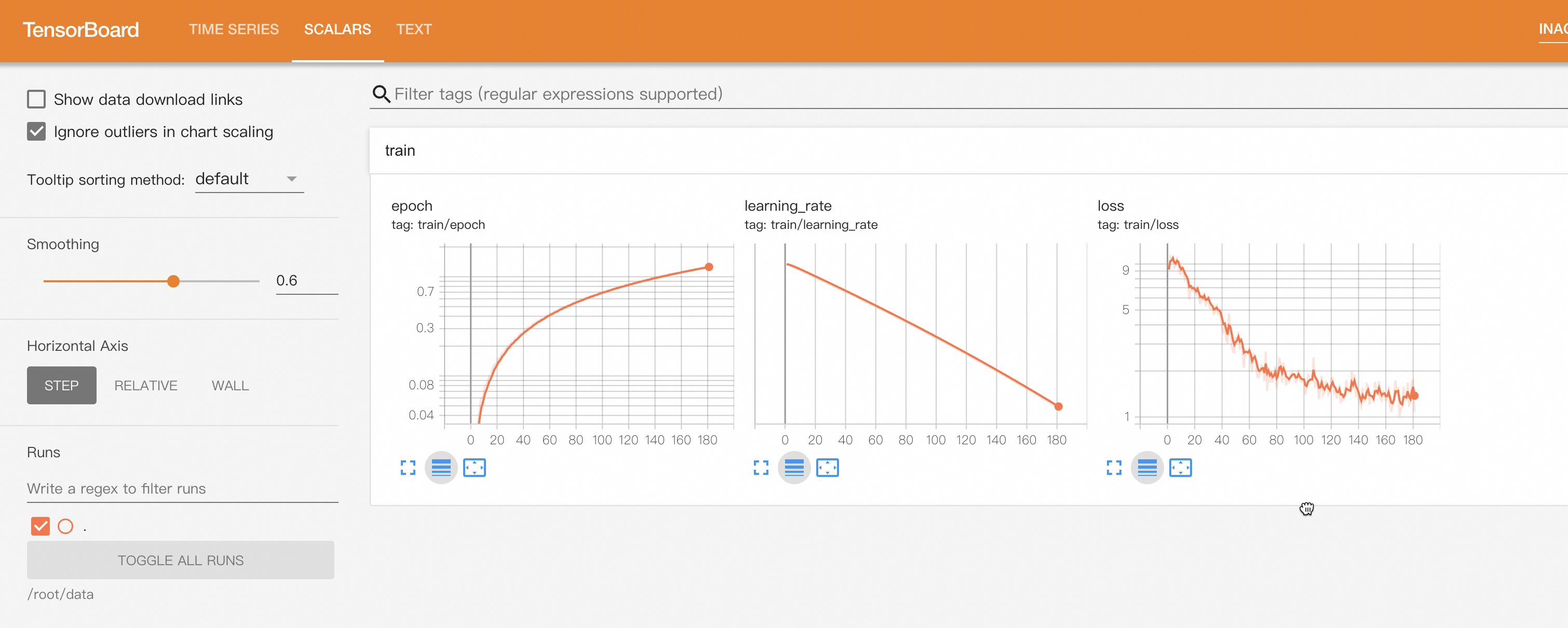
The trained model is automatically registered to Models of the AI Asset Management module. You can view or deploy the model. For more information, see Register and manage models.
Use a model in PAI SDK for Python
You can call pre-trained models in Model Gallery by using PAI SDK for Python. Before you call a model, you must install and configure PAI SDK for Python. Sample code:
# Install PAI SDK for Python.
python -m pip install alipai --upgrade
# Interactively configure the required information, such as your AccessKey pair and PAI workspace.
python -m pai.toolkit.config
For information about how to obtain the required information, such as your AccessKey pair and PAI workspace, see Install and configure PAI SDK for Python.
Deploy and call a model service
Inference service configurations are preset on the models in Model Gallery. You need to only provide the resource information and service name to deploy the Mixtral model to Elastic Algorithm Service (EAS) in an efficient manner.
from pai.session import get_default_session
from pai.model import RegisteredModel
from pai.common.utils import random_str
from pai.predictor import Predictor
session = get_default_session()
# Obtain the model from Model Gallery.
m = RegisteredModel(
model_name="Mixtral-8x7B-Instruct-v0.1",
model_provider="pai",
)
# View the default deployment configurations of the model.
print(m.inference_spec)
# Deploy a model as an inference service.
# Provide a resource quota that is created on Lingjun resources, which has at least two GU108 GPUs with 80 GB of memory.
predictor = m.deploy(
service_name="mixtral_8_7b_{}".format(random_str(6)),
options={
# The ID of the resource quota.
"metadata.quota_id": "<LingJunResourceQuotaId>",
"metadata.quota_type": "Lingjun",
"metadata.workspace_id": session.workspace_id,
}
)
# Obtain the endpoint and token of the model service.
endpoint = predictor.internet_endpoint
token = predictor.access_token
For information about how to call the model service, see Deploy and call a model service. You can also call the model service by using PAI SDK for Python.
from pai.predictor import Predictor
p = Predictor("<MixtralServiceName>")
res = p.raw_predict(
path="/v1/chat/completions",
method="POST",
data={
"model": "Mixtral-8x7B-Instruct-v0.1",
"messages": [
{"role": "user", "content": "Introduce the history of Shanghai"}
]
}
)
print(res.json())
After you call the model service, you need to delete the model service to release resources in the PAI console or by using PAI SDK for Python.
# Delete a model service.
predictor.delete_service()Train a model
After you obtain a pre-trained model from Model Gallery by using PAI SDK for Python, you can view the fine-tuning algorithm of the model, including hyperparameter configurations supported by the algorithm and input and output data of the algorithm.
from pai.model import RegisteredModel
# Obtain the Mixtral-8x7B-Instruct-v0.1 model from Model Gallery.
m = RegisteredModel(
model_name="Mixtral-8x7B-Instruct-v0.1",
model_provider="pai",
)
# Obtain the fine-tuning algorithm for the model.
est = m.get_estimator()
# View the hyperparameters supported by the algorithm and the input and output information of the algorithm.
print(est.hyperparameter_definitions)
print(est.input_channel_definitions)
The fine-tuning algorithm provided by the Mixtral-8x7B-Instruct-v0.1 model supports only Lingjun resources. You need to obtain the ID of the current resource quota and configure the resource information required by the training job in the PAI console. Before you submit a training job, you can configure appropriate hyperparameters for the training job.
# Configure the ID of the Lingjun resource quota used by the training job.
est.resource_id = "<LingjunResourceQuotaId>"
# Configure hyperparameters for the training job.
hps = {
"learning_rate": 1e-5,
"per_device_train_batch_size": 2,
}
est.set_hyperparameters(**hps)
The fine-tuning algorithm supports the following inputs:
model: the pre-trained Mixtral-8x7B-Instruct-v0.1 model.train: the training dataset used for model training.validation: the validation dataset used for model training.
For information about the format of a dataset, see Train a model. You can upload objects to an OSS bucket in the PAI console or by using OSSUtils. You can also use an SDK to upload objects to an OSS bucket.
from pai.common.oss_utils import upload
# View the input information of the fine-tuning algorithm.
# Obtain the input data of the fine-tuning algorithm, including the model and the public-read dataset for model training.
training_inputs = m.get_estimator_inputs()
print(training_inputs)
# {
# "model": "oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/models/Mixtral-8x7B-Instruct-v0.1/main/",
# "train": "oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/datasets/llm_instruct/en_poetry_train_mixtral.json",
# "validation": "oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/datasets/llm_instruct/en_poetry_test_mixtral.json",
# }
# Upload user data. Use the actual on-premises file path and OSS bucket path.
train_data_uri = upload("/path/to/local/train.json", "path/of/train/data")
validation_data_uri = upload("/path/to/local/validation.json", "path/of/validation/data")
# Use the developer training data.
# training_inputs["train"] = train_data_uri
# training_inputs["validation"] = validation_data_uri
You can refer to the preceding training data format to prepare data. Replace train and validation with your training and validation datasets to submit a training job. You can view the status and log of the training job in the PAI console by using the URL, of the training job, provided by PAI SDK for Python. You can also view the progress and model convergence of the training job by using TensorBoard.
from pai.common.oss_utils import download
# Submit the training job and print the URL of the training job.
est.fit(
inputs=training_inputs,
wait=False,
)
# Open TensorBoard to view the training progress.
est.tensorboard()
# Wait for the training job to complete.
est.wait()
# View the model path saved in the OSS bucket.
print(est.model_data())
# You can download the model to your on-premises machine by using OSSUtils or a convenient method provided by PAI SDK for Python.
download(est.model_data())
For more information about how to use the pre-trained models in Model Gallery by using PAI SDK for Python, see Use a pre-trained model with PAI SDK for Python.