Feature engineering is a process used in recommendation algorithms to process raw datasets, such as user, item, and behavior tables, and generate new feature tables. These tables are then used for subsequent retrieval and sorting.
Prerequisites
-
Platform for AI (PAI) Machine Learning Designer is activated and a default workspace is created. For more information, see Activate PAI and create a default workspace.
-
A MaxCompute resource is attached to the workspace. For more information, see Manage compute resources for a workspace.
-
A MaxCompute data source is created and attached as the engine for the workspace. For more information, see Create a MaxCompute data source.
Datasets
To demonstrate feature engineering, this topic uses a script to simulate and generate user, item, and behavior tables. These tables are samples and do not contain real data.
User table: pai_online_project.rec_sln_demo_user_table
|
Field |
Type |
Description |
|
user_id |
bigint |
unique ID of the user. |
|
gender |
string |
Gender. |
|
age |
bigint |
Age. |
|
city |
string |
City. |
|
item_cnt |
bigint |
number of created content items. |
|
follow_cnt |
bigint |
number of users followed. |
|
follower_cnt |
bigint |
number of followers. |
|
register_time |
bigint |
registration time. |
|
tags |
string |
user tags. |
|
ds |
string |
partition key column of the table. |
Item table: pai_online_project.rec_sln_demo_item_table
|
Field |
Type |
Description |
|
item_id |
bigint |
item ID. |
|
duration |
double |
video duration. |
|
title |
string |
title. |
|
category |
string |
level-1 category. |
|
author |
bigint |
author. |
|
click_count |
bigint |
total number of clicks. |
|
praise_count |
bigint |
total number of likes. |
|
pub_time |
bigint |
publication time. |
|
ds |
string |
partition key column of the table. |
Behavior table: pai_online_project.rec_sln_demo_behavior_table
|
Field |
Type |
Description |
|
request_id |
bigint |
instrumentation ID or request ID. |
|
user_id |
bigint |
unique ID of the user. |
|
exp_id |
string |
experiment ID. |
|
page |
string |
page. |
|
net_type |
string |
network type. |
|
event_time |
bigint |
time when the behavior event occurred. |
|
item_id |
bigint |
item ID. |
|
event |
string |
event type of the behavior. |
|
playtime |
double |
playback or reading duration. |
|
ds |
string |
partition key column of the table. |
Feature engineering
Step 1: Go to the Designer page
-
Log on to the PAI console.
-
In the navigation pane on the left, click Workspace Management. On the Workspace Management page, click the name of the workspace that you want to manage.
-
In the navigation pane on the left of the workspace page, choose Model Development and Training > Machine Learning Designer to open the Designer page.
Step 2: Build a workflow
-
On the Designer page, click the Preset Templates tab.
-
In the Recommendation Solution - Feature Engineering section, click Create.
-
In the Create Workflow dialog box, configure the parameters. use the default values.
Set Workflow Data Storage to an OSS Bucket path. This path is used to store temporary data and models generated during the workflow run.
-
Click OK.
Wait for about 10 seconds for the workflow to be created.
-
In the workflow list, double-click the Recommendation Solution - Feature Engineering workflow to open it.
-
system automatically builds the workflow based on the preset template, as shown in the following figure.
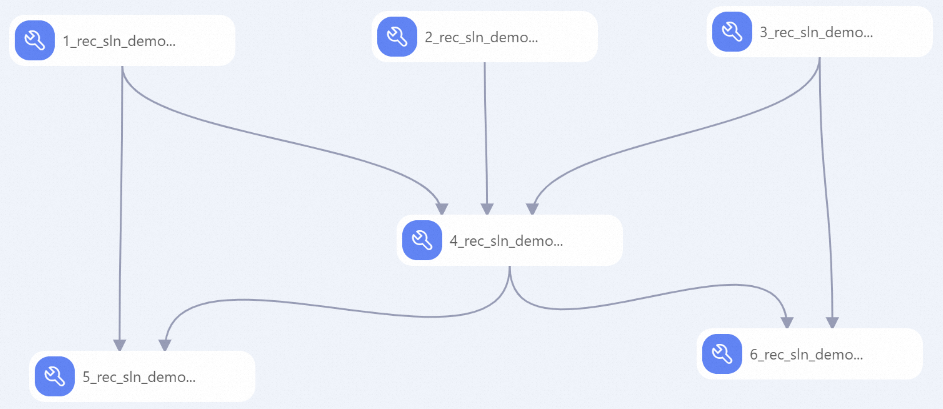
Node
Description
1
Pre-process the item table:
-
Replace the separator for tag features with
chr(29)for use in subsequent feature generation (FG) steps. -
Indicates whether the output is a feature of a newly listed item.
2
Pre-process the behavior table: Generate derived time-based features for behaviors, such as day_h and week_day.
3
Pre-process the user table:
-
output is a feature that indicates whether the user is newly registered.
-
Replace the separator for tag features with
chr(29)for use in subsequent FG steps.
4
Associate the behavior, user, and item tables to form a wide behavior log table with statistical properties.
5
Generate an item feature table that contains statistical features of items over a period:
-
item__{event}_cnt_{N}d: The number of times a specific event occurred on the item within N days. This indicates the item's popularity. -
item__{event}_{itemid}_dcnt_{N}d: The number of unique users who performed a specific event on the item within N days. This indicates the item's popularity. -
item__{min|max|avg|sum}_{field}_{N}d: The statistical distribution of a user's numeric property for positive events on the item within N days. This indicates the preferences of users with specific numeric properties. -
item__kv_{cate}_{event}_{N}d: The statistics of a user's categorical property for a specific event on the item within N days. This indicates the preferences of users with specific categorical properties.
6
Generate a user feature table that contains statistical features of users over a period.
-
Step 3: Add a function
-
Create a business flow. For more information, see Create a business flow.
-
Right-click MaxCompute under the new business flow and choose to create a Python script resource named count_cates_kvs.py. For more information, see Create and use MaxCompute resources.
-
Right-click MaxCompute under the new business flow and choose New Function. Create a MaxCompute function named COUNT_CATES_KVS. Set Class Name to
count_cates_kvs.CountCatesKVSand Resource List tocount_cates_kvs.py. For more information, see Create and use a user-defined function.
Step 4: Run the workflow and view the output
By default, this dataset uses 45 days of data, and the run may take a long time. To complete the run faster, perform the following operations:
-
Update the execution time window parameter to use data from a shorter time period.
-
Click each of the following nodes. In the Parameter Settings tab on the right, change the Execution Time Window parameter from the default
(-45,0]to(-9,0]:-
1_rec_sln_demo_item_table_preprocess_v2 -
2_rec_sln_demo_behavior_table_preprocess_ v2 -
3_rec_sln_demo_user_table_preprocess_v2 -
4_rec_sln_demo_behavior_table_preprocess_wide_v2
-
-
Click each of the following nodes. In the Parameter Settings tab on the right, change the Execution Time Window parameter from the default
(-31,0]to(-8,0]:-
5_rec_sln_demo_item_table_preprocess_all_feature_v2 -
6_rec_sln_demo_user_table_preprocess_all_feature_v2
-
-
-
Modify the SQL script to select a subset of users.
-
Click the
2_rec_sln_demo_behavior_table_preprocess_ v2node. In the Parameter Settings tab on the right, change line 32 of the SQL Script parameter fromWHERE ds = '${pai.system.cycledate}'toWHERE ds = '${pai.system.cycledate}' and user_id %10=1. -
Click the
3_rec_sln_demo_user_table_preprocess_v2node. In the Parameter Settings tab on the right, change line 38 of the SQL Script parameter fromWHERE ds = '${pai.system.cycledate}'toWHERE ds = '${pai.system.cycledate}' and user_id %10=1.
-
-
Click the Run button
 on the toolbar above the Designer canvas.
on the toolbar above the Designer canvas. -
After the workflow finishes running, verify that the following MaxCompute tables contain 30 days of data:
-
Item feature table:
rec_sln_demo_item_table_preprocess_all_feature_v2 -
Wide behavior log table:
rec_sln_demo_behavior_table_preprocess_v2 -
User feature table:
rec_sln_demo_user_table_preprocess_all_feature_v2
query the data in the preceding tables on the SQL query page. For more information, see Connect using DataWorks.
Noteproject prohibits full table scans on partitioned tables. specify a partition condition in your query. If a full table scan is necessary, add the
set odps.sql.allow.fullscan=true;statement before your SQL statement and run them together. A full table scan reads more data and can result in higher costs. -