This topic answers common questions about deploying and fine-tuning models in PAI-Model Gallery.
Q: How can I check if deep thinking is enabled for a model's evaluation in PAI-Model Gallery?
To determine if deep thinking is used for a model's evaluation, you need to check its default deployment configuration. This information is available on the model's description page in the PAI-Model Gallery. All models are evaluated using their default deployment settings.
Q: How do I deploy a model after training it in PAI-Model Gallery?
Navigate to PAI-Model Gallery > Task Management.
Find your completed training task and click to open its details page.
Click the Deploy button in the top-right corner.

Q: How can I troubleshoot a failed training task in PAI-Model Gallery?
When a training task fails, you can investigate the cause by checking the task diagnostics or viewing the logs. A common reason for failure is an incorrectly formatted dataset.
Here are two ways to find the error details:
Check Task Diagnostics: In PAI-Model Gallery, go to Task Management > Training Tasks. Click the failed task to open its Task Details page. Hover over the Failed status to view a summary of the error.

Check Task Logs: On the Task Management > Training Tasks, select the Task log tab to view the full error message.

The following table lists common error messages and their solutions:
Error type
Error message
Solution
Input/output errors
ValueError: output channel ${your OSS uri} must be directory
Verify that the output path specified in your training settings is a directory, not a file.
ValueError: train must be a file
Verify that the specified input path points to a file, not a directory.
FileNotFoundError
Ensure that a valid file exists at the specified input path.
JSONDecodeError
Verify that the input JSON file is correctly formatted.
ValueError: Input data must be a json file or a jsonl file!
Ensure the input file is in JSON or JSONL format.
KeyError: ${some key name}
This error often occurs with JSON datasets. Review the model's documentation and verify that all key-value pairs in your dataset match the required format.
ValueError: Unrecognized model in /ml/input/data/model/.
The model file is in a format that PyTorch does not recognize.
UnicodeDecoderError
Verify that the input file has the correct character encoding.
Input/output error
Ensure you have read permission for the input path and read/write permissions for the output path.
NotADirectoryError: [Errno 20] Not a directory:
Verify that the specified input or output path is a directory.
Hyperparameter settings
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -9) local_rank: 0 (pid: 51) of binary: /usr/bin/python (and there are no related subprocess logs)
The instance has insufficient memory (RAM), causing an Out of Memory (OOM) error when loading the model. Select an instance type with more memory.
torch.cuda.OutOfMemoryError: CUDA out of memory
The instance has insufficient GPU memory. To resolve this, choose a GPU instance type with more VRAM, or reduce memory-intensive hyperparameters like
lora_dimor
batch_sizeValueError: No closing quotation
The
system promptor another string parameter contains an unclosed quotation mark (
"), preventing the training command from being generated. Ensure all quotation marks are properly paired.
Resource configuration of an instance type
Exception: Current loss scale already at minimum - cannot decrease scale anymore. Exiting run
This error indicates a precision issue. The model uses the BF16 format, which requires a GPU with an Ampere or newer architecture (e.g., A10, A100). Training on an older GPU converts parameters to FP16, which can lead to this underflow error.
RuntimeError: CUDA error: uncorrectable ECC error encountered
This indicates a hardware fault on the underlying GPU instance. Retry the training task. If it fails again, try a different instance type or region.
MemoryError: WARNING Insufficient free disk space
The instance's disk is full. Select an instance type with more disk space.
User limit errors
failed to compose dlc job specs, resource limiting triggered, you are trying to use more GPU resources than the threshold
This indicates you've exceeded your GPU quota. By default, training tasks are limited to 2 concurrent GPUs. Wait for a running task to complete, or submit a ticket to request a quota increase.
Q: How do I perform online debugging for a model deployed with PAI-EAS?
Once your model is successfully deployed as a service on PAI-EAS (Elastic Algorithm Service), you can use the built-in online debugging tool.
Find your deployed service: Navigate to PAI-Model Gallery > Task Management > Deployment Tasks. This will redirect you to the PAI-EAS console where you can view the deployed service.

Open the Online Debugging tool: On the PAI-EAS page, locate your service. In the Operation column, click Online Debugging.

Configure and send a request:
First, find the required request format on the model's description page in PAI-Model Gallery. For example, a model deployed using the BladeLLM method might expect a POST request to a specific path like
/v1/chat/completions, with a defined JSON body.

Next, in the Online Debugging UI, append the path (e.g.,
/v1/chat/completions) to the Request URL.
Finally, populate the Request Body using the example from the model's description page and click Send Request.
Q: Why am I getting a 503 "no healthy upstream" error when calling my PAI-EAS deployed model?
A 503 Service Unavailable error with the message no healthy upstream indicates that the service instance is out of resources and cannot process new requests.
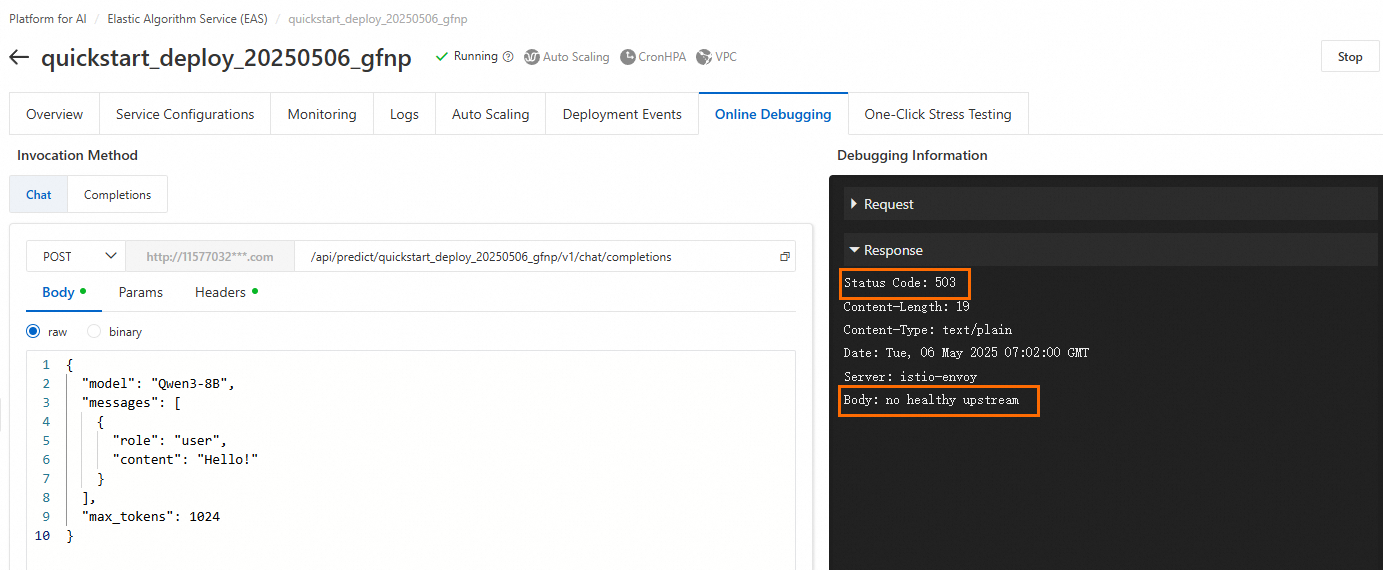
Cause: The instance's resources (CPU, memory, or GPU memory) are fully utilized, leaving no capacity for new requests.
Solution: The correct action depends on your resource type:
Public Resources: The shared resource pool is temporarily overloaded. Try again during off-peak hours, or redeploy your model to a different region or with a different instance specification.
Dedicated Resources (EAS Resource Group): Your resource group is underscaled. Ensure the group has sufficient CPU, memory, and GPU memory to handle the load. As a best practice, maintain at least a 20% resource buffer.
Q: Why do I get the "SupportsDistributedTraining false, please set InstanceCount=1" error during model training?
Cause: This error occurs because the selected model does not support distributed training, but the task was configured to run on more than one node (
InstanceCount > 1).Solution: Set the Number of Nodes to
1in your training task configuration and restart the task.