Qwen-Image-Edit supports multi-image input and output. It can modify text in images, add/delete/move objects, change subject actions, transfer styles, and enhance details.
Getting started
This example shows how to use qwen-image-2.0-pro to generate two edited images from three input images and a prompt.
Input prompt: The girl in Image 1 wears the black dress from Image 2 and sits in the pose from Image 3.
Input image 1 | Input image 2 | Input image 3 | Output images (multiple images) | |
|
|
|
|
|


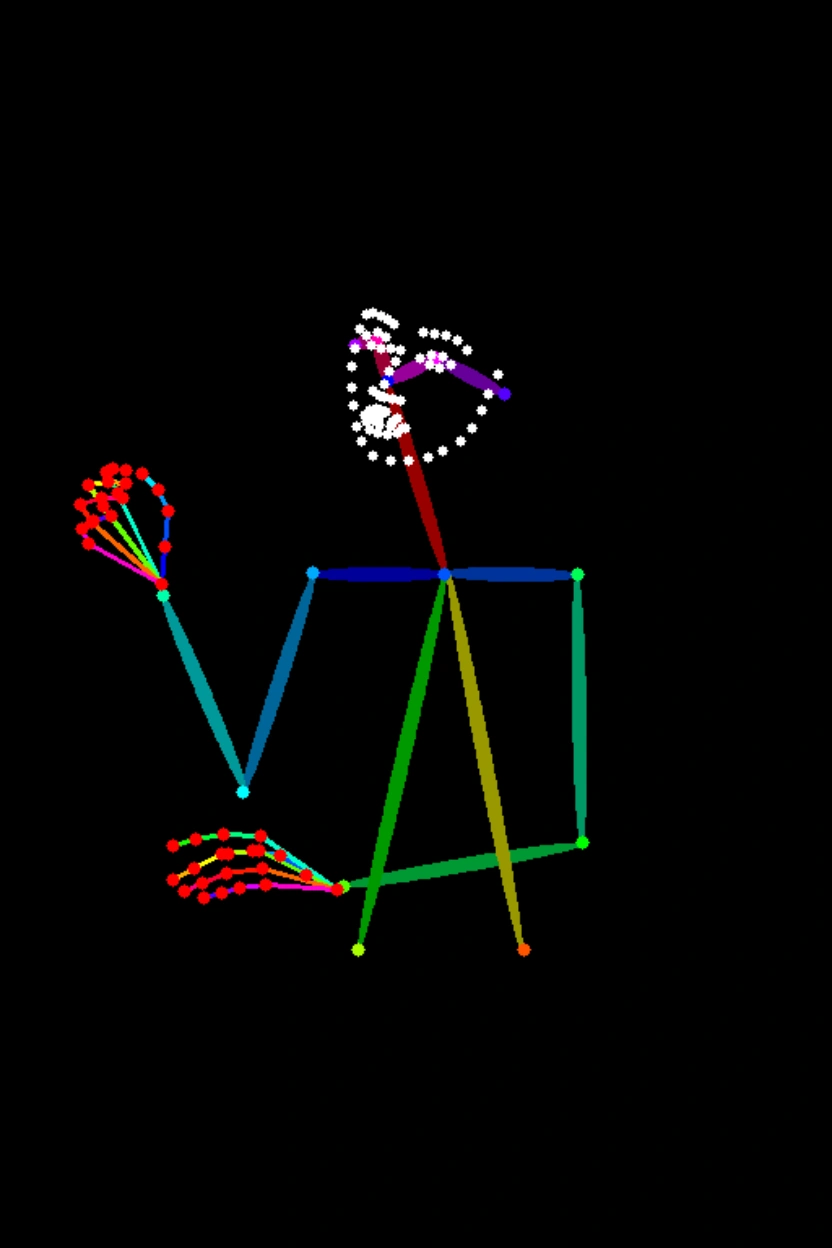


Before making a call, get an API key and export the API key as an environment variable.
To call the API using the SDK, install the DashScope SDK. The SDK is available for Python and Java.
The Qwen image editing models support one to three input images. The qwen-image-2.0, qwen-image-edit-max, and qwen-image-edit-plus series can generate one to six images. qwen-image-edit can generate only one image. The URLs for the generated images are valid for 24 hours. Download the images to your local device promptly.
Python
import json
import os
import dashscope
from dashscope import MultiModalConversation
# The following is the URL for the Singapore region. If you use a model in the Beijing region, replace the URL with: https://{WorkspaceId}.cn-beijing.maas.aliyuncs.com/api/v1
dashscope.base_http_api_url = 'https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/api/v1'
# The model supports one to three input images.
messages = [
{
"role": "user",
"content": [
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png"},
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png"},
{"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png"},
{"text": "The girl from Image 1 is wearing the black dress from Image 2 and sitting in the pose from Image 3."}
]
}
]
# The API keys for the Singapore and Beijing regions are different. To get an API key, see https://www.alibabacloud.com/help/en/model-studio/get-api-key.
# If you have not configured the environment variable, replace the next line with: api_key="sk-xxx"
api_key = os.getenv("DASHSCOPE_API_KEY")
# The qwen-image-2.0, qwen-image-edit-max, and qwen-image-edit-plus series support one to six output images. This example generates two.
response = MultiModalConversation.call(
api_key=api_key,
model="qwen-image-2.0-pro",
messages=messages,
stream=False,
n=2,
watermark=False,
negative_prompt=" ",
prompt_extend=True,
size="1024*1536",
)
if response.status_code == 200:
# To view the full response, uncomment the next line.
# print(json.dumps(response, ensure_ascii=False))
for i, content in enumerate(response.output.choices[0].message.content):
print(f"URL of output image {i+1}: {content['image']}")
else:
print(f"HTTP status code: {response.status_code}")
print(f"Error code: {response.code}")
print(f"Error message: {response.message}")
print("For more information, see https://www.alibabacloud.com/help/en/model-studio/error-code")
Java
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import com.alibaba.dashscope.utils.JsonUtils;
import com.alibaba.dashscope.utils.Constants;
import java.io.IOException;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.List;
public class QwenImageEdit {
static {
// The following URL is for the Singapore region. If you use a model in the Beijing region, replace the URL with https://{WorkspaceId}.cn-beijing.maas.aliyuncs.com/api/v1.
Constants.baseHttpApiUrl = "https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/api/v1";
}
// The API keys for the Singapore and Beijing regions are different. To obtain an API key, see https://www.alibabacloud.com/help/en/model-studio/get-api-key.
// If you have not configured the environment variable, replace the following line with your DashScope API key: apiKey="sk-xxx".
static String apiKey = System.getenv("DASHSCOPE_API_KEY");
public static void call() throws ApiException, NoApiKeyException, UploadFileException, IOException {
MultiModalConversation conv = new MultiModalConversation();
// The model supports one to three input images.
MultiModalMessage userMessage = MultiModalMessage.builder().role(Role.USER.getValue())
.content(Arrays.asList(
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png"),
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png"),
Collections.singletonMap("image", "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png"),
Collections.singletonMap("text", "The girl from Image 1 is wearing the black dress from Image 2 and sitting in the pose from Image 3.")
)).build();
// The qwen-image-2.0, qwen-image-edit-max, and qwen-image-edit-plus series models support one to six output images. This example generates two images.
Map<String, Object> parameters = new HashMap<>();
parameters.put("watermark", false);
parameters.put("negative_prompt", " ");
parameters.put("n", 2);
parameters.put("prompt_extend", true);
parameters.put("size", "1024*1536");
MultiModalConversationParam param = MultiModalConversationParam.builder()
.apiKey(apiKey)
.model("qwen-image-edit-max")
.messages(Collections.singletonList(userMessage))
.parameters(parameters)
.build();
MultiModalConversationResult result = conv.call(param);
// To view the complete response, uncomment the following line.
// System.out.println(JsonUtils.toJson(result));
List<Map<String, Object>> contentList = result.getOutput().getChoices().get(0).getMessage().getContent();
int imageIndex = 1;
for (Map<String, Object> content : contentList) {
if (content.containsKey("image")) {
System.out.println("URL of output image " + imageIndex + ": " + content.get("image"));
imageIndex++;
}
}
}
public static void main(String[] args) {
try {
call();
} catch (ApiException | NoApiKeyException | UploadFileException | IOException e) {
System.out.println(e.getMessage());
}
}
}curl
The following command uses the URL for the Singapore region. If you use a model in the China (Beijing) region, replace the URL with: https://{WorkspaceId}.cn-beijing.maas.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation
curl --location 'https://{WorkspaceId}.ap-southeast-1.maas.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--data '{
"model": "qwen-image-2.0-pro",
"input": {
"messages": [
{
"role": "user",
"content": [
{
"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png"
},
{
"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png"
},
{
"image": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png"
},
{
"text": "The girl from Image 1 is wearing the black dress from Image 2 and sitting in the pose from Image 3."
}
]
}
]
},
"parameters": {
"n": 2,
"negative_prompt": " ",
"prompt_extend": true,
"watermark": false,
"size": "1024*1536"
}
}'Model recommendations
qwen-image-2.0-proseries (Recommended): A fused model for image generation and editing with enhanced capabilities in text rendering, realistic textures, and semantic adherence.qwen-image-2.0series: An accelerated version of the fused image generation and editing model that balances quality and performance.
For the models supported in each region, see Model list.
Input instructions
Input images (messages)
The messages parameter is an array that must contain a single object. This object must include the role and content properties. The role property must be set to user. The content property must include both image (one to three images) and text (one editing instruction).
The input images must meet the following requirements:
The supported image formats are JPG, JPEG, PNG, BMP, TIFF, WEBP, and GIF.
The output image is in PNG format. For animated GIFs, only the first frame is processed.
For best results, the image resolution should be between 384 and 3072 pixels for both width and height. A low resolution may result in a blurry output, while a high resolution increases processing time.
The size of a single image file cannot exceed 10 MB.
"messages": [
{
"role": "user",
"content": [
{ "image": "Public URL or Base64 data of Image 1" },
{ "image": "Public URL or Base64 data of Image 2" },
{ "image": "Public URL or Base64 data of Image 3" },
{ "text": "Your editing instruction, for example: 'The girl in Image 1 wears the black dress from Image 2 and sits in the pose from Image 3'" }
]
}
]Image input order
Image numbers in prompts correspond to array position: the first image is "image 1", the second is "image 2". You can also use markers like "[image 1]" and "[image 2]".
{
"content": [
{"text": "Editing instruction, for example: Place the alarm clock from image 1 next to the vase on the dining table in image 2"},
{"image": "https://example.com/image1.png"},
{"image": "https://example.com/image2.png"}
]
}Input image | Output image | ||
Image 1 |
Image 2 |
Prompt: Move image 1 onto image 2 |
Prompt: Move image 2 onto image 1 |




Image input methods
Public URL
You can provide a publicly accessible image URL that supports the HTTP or HTTPS protocol.
Example value:
https://xxxx/img.png.
Base64 encoding
Convert the image file to a Base64-encoded string and concatenate it in the following format: data:{mime_type};base64,{base64_data}.
{mime_type}: The media type of the image, which must correspond to the file format.{base64_data}: The Base64-encoded string of the file.Example value:
data:image/jpeg;base64,GDU7MtCZz...(The example is truncated for demonstration purposes.)
For complete code examples, see Python SDK call and Call using the Java SDK.
More parameters
Adjust the generation results using the following optional parameters:
n: The number of images to generate. The default value is 1. The qwen-image-2.0, qwen-image-edit-max, and qwen-image-edit-plus series of models support generating one to six images. The
qwen-image-editmodel supports generating only one image.negative_prompt: Describes content to exclude from the image, such as "blur" or "extra fingers". This parameter helps optimize the quality of the generated image.
watermark: Specifies whether to add a "Qwen-Image" watermark to the bottom-right corner of the image. The default value is
false. The following image shows the watermark style:
seed: The random number seed. The value must be an integer from
[0, 2147483647]. If this parameter is not specified, the algorithm generates a random number to use as the seed. Using the same seed value helps ensure consistent generation results.
The following optional parameters are available only for the qwen-image-2.0, qwen-image-edit-max, and qwen-image-edit-plus series of models:
size: The resolution of the output image. The format is
width*height, such as"1024*2048". For the qwen-image-2.0 series models, you can set the width and height freely. The total pixels of the output image must be between 512 × 512 and 2048 × 2048. By default, the resolution is the same as the input image (the last image if multiple are provided). For the qwen-image-edit-max and qwen-image-edit-plus series models, the width and height can range from 512 to 2048 pixels. By default, the output image has a resolution close to1024*1024and an aspect ratio similar to the original image.prompt_extend: Enables or disables the prompt rewriting feature. The default value is
true. If enabled, the model optimizes the prompt. This feature can significantly improve the results for simple or less descriptive prompts.
For a complete list of parameters, see Qwen-Image-Edit API reference.
Overview
Multi-image fusion
Input image 1 | Input image 2 | Input image 3 | Output image |
|
|
|
The girl in Image 1 wears the necklace from Image 2 and carries the bag from Image 3 on her left shoulder. |




Subject consistency
Input image | Output image 1 | Output image 2 | Output image 3 |
|
Change the image to an ID photo with a blue background. The person is wearing a white shirt, a black suit, and a striped tie. |
The person is wearing a white shirt, a gray suit, and a striped tie. One hand rests on the tie. The background is light-colored. |
The person is wearing a black hoodie with "Qwen Image" in a thick brushstroke font. They are leaning on a guardrail with sunlight in their hair. A bridge and the sea are in the background. |
|
The air conditioner is placed in a living room next to a sofa. |
Mist is added from the air conditioner's vent, extending over the sofa. Green leaves are also added. |
The white handwritten text "Natural Fresh Air Enjoy Breathing" is added at the top. |








Sketch creation
Input image | Output image | |
|
Generate an image that matches the detailed shape outlined in Image 1 and follows this description: A young woman smiles on a sunny day. She wears round brown sunglasses with a leopard print frame. Her hair is neatly tied up, she wears pearl earrings, a dark blue scarf with purple star patterns, and a black leather jacket. |
Generate an image that matches the detailed shape outlined in Image 1 and follows this description: An elderly man smiles at the camera. His face is wrinkled, his hair is messy in the wind, and he wears round-framed reading glasses. He has a worn-out red scarf with star patterns around his neck and is wearing a cotton-padded jacket. |



Creative product generation
Input image | Output image | ||
|
Make this bear sit under the moon (represented by a light gray crescent outline on a white background), holding a guitar, with small stars and speech bubbles with phrases such as "Be Kind" floating around. |
Print this design on a T-shirt and a paper tote bag. A female model is displaying these items. The woman is also wearing a baseball cap with "Be kind" written on it. |
A hyper-realistic 1/7 scale character model, designed as a commercial finished product, is placed on a desk with an iMac that has a white keyboard. The model stands on a clean, round, transparent acrylic base with no labels or text. Professional studio lighting highlights the sculpted details. On the iMac screen in the background, the ZBrush modeling process for the same model is displayed. Next to the model, place a packaging box with a transparent window on the front, showing only the clear plastic shell inside. The box is slightly taller than the model and reasonably sized to hold it. |
This bear is wearing an astronaut suit and pointing into the distance. |
This bear is wearing a gorgeous ball gown, with its arms spread in an elegant dance pose. |
This bear is wearing sportswear, holding a basketball, with one leg bent. | |







Generate image from depth map
Input image | Output image | |
|
Generate an image that matches the depth map outlined in Image 1 and follows this description: A blue bicycle is parked in a side alley, with a few weeds growing from cracks in the stone in the background. |
Generate an image that matches the depth map outlined in Image 1 and follows this description: A worn-out red bicycle is parked on a muddy path, with a dense primeval forest in the background. |



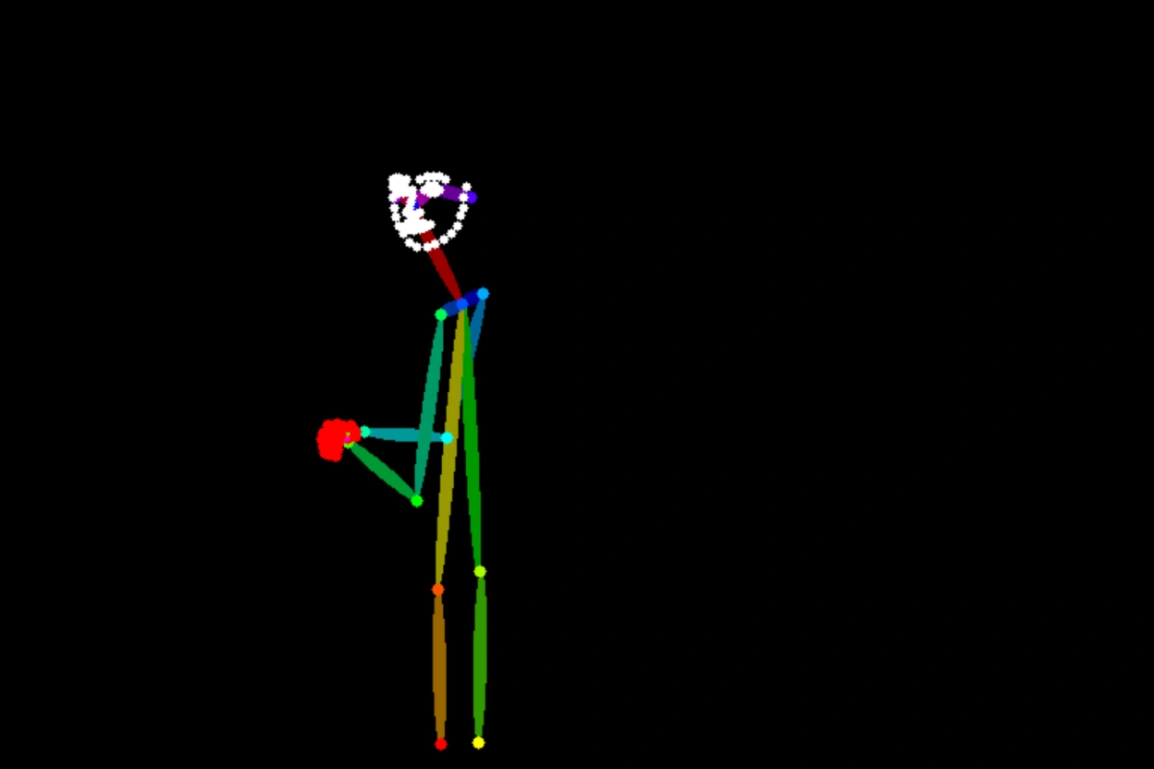
Generate image from keypoints
Input image | Output image | |
|
Generate an image that matches the human pose outlined in Image 1 and follows this description: A Chinese woman in a Hanfu is holding an oil-paper umbrella in the rain, with a Suzhou garden in the background. |
Generate an image that matches the human pose outlined in Image 1 and follows this description: A young man stands on a subway platform. He wears a baseball cap, a T-shirt, and jeans. A train is speeding by behind him. |


Text editing
Input image | Output image | Input image | Output image |
|
Replace 'HEALTH INSURANCE' on the Scrabble tiles with 'Tomorrow Will Be Better'. |
|
Change the phrase "Take a Breather" on the note to "Relax and Recharge". |




Input image | Output image | ||
|
Change "Qwen-Image" to a black ink-drip font. |
Change "Qwen-Image" to a black handwriting font. |
Change "Qwen-Image" to a black pixel font. |
Change "Qwen-Image" to red. |
Change "Qwen-Image" to a blue-purple gradient. |
Change "Qwen-Image" to candy colors. | |
Change the material of "Qwen-Image" to metal. |
Change the material of "Qwen-Image" to clouds. |
Change the material of "Qwen-Image" to glass. | |










Add and delete
Capability | Input image | Output image |
Add element |
|
Add a small wooden sign in front of the penguin that says "Welcome to Penguin Beach". |
Delete element |
|
Remove the hair from the plate. |




Viewpoint transformation
Input image | Output image | Input image | Output image |
|
Get a front view. |
|
Face left. |
|
Get a rear view. |
|
Face right. |








Old photo processing
Capability | Input image | Output image |
Old photo restoration and colorization |
|
Restore the old photo, remove scratches, reduce noise, enhance details, high resolution, realistic image, natural skin tone, clear facial features, no distortion. |
|
Intelligently colorize the image based on its content to make it more vivid. |




Billing and rate limiting
See Model list and pricing for the free quota, pricing, and rate limits.
Billing details:
Billing is based on successfully generated images only. Failed calls do not incur fees or consume the free quota.
Enable 'Free quota only' to avoid charges after the quota is depleted. See Free quota for new users.
API reference
See Qwen-Image Edit for API parameters.
Error codes
If the model call fails and returns an error message, see Error codes for resolution.
FAQ
Q: What languages does the Qwen Image Editing model support?
A: The model currently supports Simplified Chinese and English. You can try other languages, but performance is not guaranteed.
Q: How do I view model invocation metrics?
A: One hour after a model invocation completes, go to the Monitoring (Singapore) or Monitoring (China (Beijing)) page to view metrics such as invocation count and success rate. For more information, see Billing and cost management.
Q: How do I get the domain name whitelist for image storage?
A: Images generated by models are stored in OSS. The API returns a temporary public URL. To configure a firewall whitelist for this download URL, note the following: The underlying storage may change dynamically. This topic does not provide a fixed OSS domain name whitelist to prevent access issues caused by outdated information. If you have security control requirements, contact your account manager to obtain the latest OSS domain name list.
See the Image generation FAQ.