Export data from a MaxCompute table to Object Storage Service (OSS) or Hologres with UNLOAD statements, making it available to other compute engines such as Amazon Redshift and BigQuery.
Run UNLOAD statements on the following platforms:
How it works
UNLOAD reads data from a MaxCompute table or subquery and writes it to an OSS path or Hologres table. Output is split into multiple files with system-generated names.
Each UNLOAD run generates new files without overwriting existing ones.
Prerequisites
Before you begin:
-
SELECTpermission on the MaxCompute source table. MaxCompute permissions. -
Write access to the target OSS bucket or Hologres table, authorized through MaxCompute.
Authorize MaxCompute to access OSS
Use one-click authorization for higher security. STS authorization.
The examples in this topic use one-click authorization with the default role AliyunODPSDefaultRole.
Authorize MaxCompute to access Hologres
Create a RAM role, grant it access to MaxCompute, and add it to the Hologres instance. Create a Hologres foreign table in STS mode.
Export to OSS using a built-in StorageHandler
Export data as CSV or TSV using a built-in StorageHandler. The .csv or .tsv extension is appended to the file name automatically.
Syntax
UNLOAD FROM {<select_statement> | <table_name> [PARTITION (<pt_spec>)]}
INTO
LOCATION <external_location>
STORED BY <StorageHandler>
[WITH SERDEPROPERTIES ('<property_name>'='<property_value>', ...)];Parameters
| Parameter | Required | Description |
|---|---|---|
select_statement |
No | A SELECT clause that queries data from a partitioned or non-partitioned source table. SELECT syntax. |
table_name, pt_spec |
No | The table name or table-partition combination. No query fee is incurred. The pt_spec format is (partition_col1=partition_col_value1, partition_col2=partition_col_value2, ...). |
external_location |
Yes | The target OSS path in the format 'oss://<oss_endpoint>/<object>'. OSS endpoints. |
StorageHandler |
Yes | The built-in storage handler. Valid values: com.aliyun.odps.CsvStorageHandler and com.aliyun.odps.TsvStorageHandler. Configured the same as MaxCompute external tables. Create an OSS external table. |
property_name, property_value |
No | SERDEPROPERTIES key-value pairs, configured the same as MaxCompute external tables. Create an OSS external table. |
Key SERDEPROPERTIES for OSS:
| Property | Description |
|---|---|
'odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole' |
The ARN of the RAM role for STS authentication. |
'odps.text.option.gzip.output.enabled'='true' |
Compresses the output file in GZIP format. Only GZIP is supported. |
To control the number of output files, set the data size (MB) each worker reads from the source table:
SET odps.stage.mapper.split.size=256;Exported data is approximately 4x the compressed in-table size.
Examples
This example exports data from the sale_detail table:
+------------+-------------+-------------+------------+------------+
| shop_name | customer_id | total_price | sale_date | region |
+------------+-------------+-------------+------------+------------+
| s1 | c1 | 100.1 | 2013 | china |
| s2 | c2 | 100.2 | 2013 | china |
| s3 | c3 | 100.3 | 2013 | china |
| null | c5 | NULL | 2014 | shanghai |
| s6 | c6 | 100.4 | 2014 | shanghai |
| s7 | c7 | 100.5 | 2014 | shanghai |
+------------+-------------+-------------+------------+------------+Step 1: Log on to the OSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS console. Create the directory mc-unload/data_location/ in an OSS bucket in the oss-cn-hangzhou region. Create buckets.![]()
The OSS path for this bucket is:
oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_locationStep 2: Log on to the MaxCompute client and run the UNLOAD statement.
Example 1: Export all data as CSV with GZIP compression
-- Control output file count: set the data size (MB) per worker.
SET odps.stage.mapper.split.size=256;
-- Export all data from sale_detail as a GZIP-compressed CSV file.
UNLOAD FROM
(SELECT * FROM sale_detail)
INTO
LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location'
STORED BY 'com.aliyun.odps.CsvStorageHandler'
WITH SERDEPROPERTIES (
'odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole',
'odps.text.option.gzip.output.enabled'='true'
);Equivalent statement referencing the table directly (no query fee):
SET odps.stage.mapper.split.size=256;
UNLOAD FROM sale_detail
INTO
LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location'
STORED BY 'com.aliyun.odps.CsvStorageHandler'
WITH SERDEPROPERTIES (
'odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole',
'odps.text.option.gzip.output.enabled'='true'
);Example 2: Export a partition as TSV with GZIP compression
SET odps.stage.mapper.split.size=256;
UNLOAD FROM sale_detail PARTITION (sale_date='2013', region='china')
INTO
LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location'
STORED BY 'com.aliyun.odps.TsvStorageHandler'
WITH SERDEPROPERTIES (
'odps.properties.rolearn'='acs:ram::139699392458****:role/AliyunODPSDefaultRole',
'odps.text.option.gzip.output.enabled'='true'
);Step 3: Log on to the OSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS console to verify the exported files in the target directory.
-
Result for Example 1:
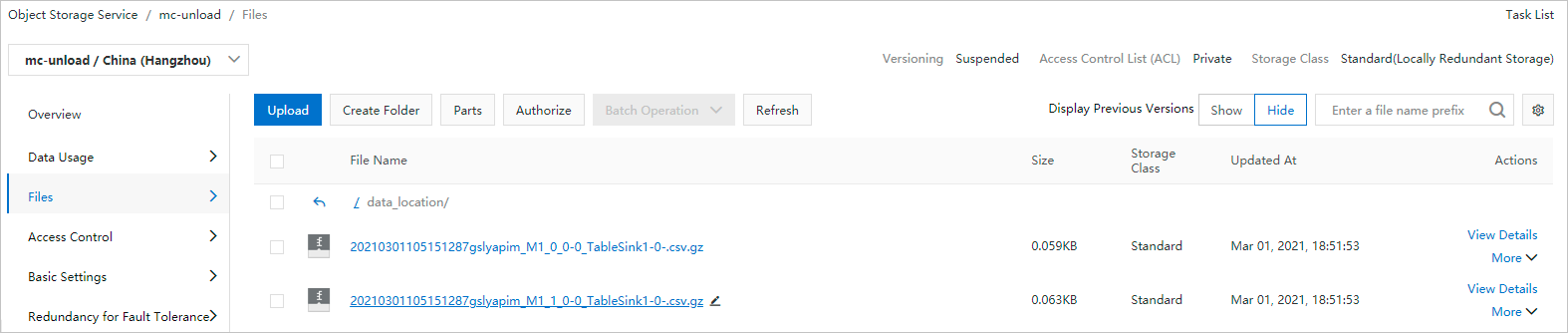
-
Result for Example 2:

Export to OSS in an open source format
Export data as ORC, Parquet, RCFILE, SEQUENCEFILE, TEXTFILE, or other open-source formats.
Syntax
UNLOAD FROM {<select_statement> | <table_name> [PARTITION (<pt_spec>)]}
INTO
LOCATION <external_location>
[ROW FORMAT SERDE '<serde_class>'
[WITH SERDEPROPERTIES ('<property_name>'='<property_value>', ...)]
]
STORED AS <file_format>
[PROPERTIES ('<tbproperty_name>'='<tbproperty_value>')];Parameters
| Parameter | Required | Description |
|---|---|---|
select_statement |
No | A SELECT clause that queries data from a partitioned or non-partitioned source table. SELECT syntax. |
table_name, pt_spec |
No | The table name or table-partition combination. No query fee is incurred. The pt_spec format is (partition_col1=partition_col_value1, partition_col2=partition_col_value2, ...). |
external_location |
Yes | The target OSS path in the format 'oss://<oss_endpoint>/<object>'. |
serde_class |
No | The SerDe class, configured the same as MaxCompute external tables. Create an OSS external table. |
property_name, property_value |
No | SERDEPROPERTIES key-value pairs, configured the same as MaxCompute external tables. Create an OSS external table. |
file_format |
Yes | The output file format: ORC, PARQUET, RCFILE, SEQUENCEFILE, or TEXTFILE. Configured the same as MaxCompute external tables. Create an OSS external table. |
tbproperty_name, tbproperty_value |
No | Table properties for compression or other settings. For example, 'mcfed.parquet.compression'='SNAPPY' or 'mcfed.parquet.compression'='LZO'. |
Key PROPERTIES for open source formats:
| Property | Description |
|---|---|
'mcfed.parquet.compression'='SNAPPY' |
Compresses Parquet output with Snappy. |
'mcfed.parquet.compression'='LZO' |
Compresses Parquet output with LZO. |
If the output is compressed with Snappy or LZO, the file name extension (.snappyor.lzo) is not shown in the file name.
Examples
This example uses the same sale_detail table as the previous section.
Step 1: Log on to the OSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS console. Create the directory mc-unload/data_location/ in your OSS bucket. Create buckets.![]()
Step 2: Log on to the MaxCompute client and run the UNLOAD statement.
Example 1: Export all data as Parquet with Snappy compression
SET odps.stage.mapper.split.size=256;
UNLOAD FROM
(SELECT * FROM sale_detail)
INTO
LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location'
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole')
STORED AS PARQUET
PROPERTIES ('mcfed.parquet.compression'='SNAPPY');Example 2: Export a partition as Parquet with Snappy compression
SET odps.stage.mapper.split.size=256;
UNLOAD FROM sale_detail PARTITION (sale_date='2013', region='china')
INTO
LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-unload/data_location'
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::139699392458****:role/AliyunODPSDefaultRole')
STORED AS PARQUET
PROPERTIES ('mcfed.parquet.compression'='SNAPPY');Step 3: Log on to the OSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS consoleOSS console to verify the exported files.
-
Result for Example 1:
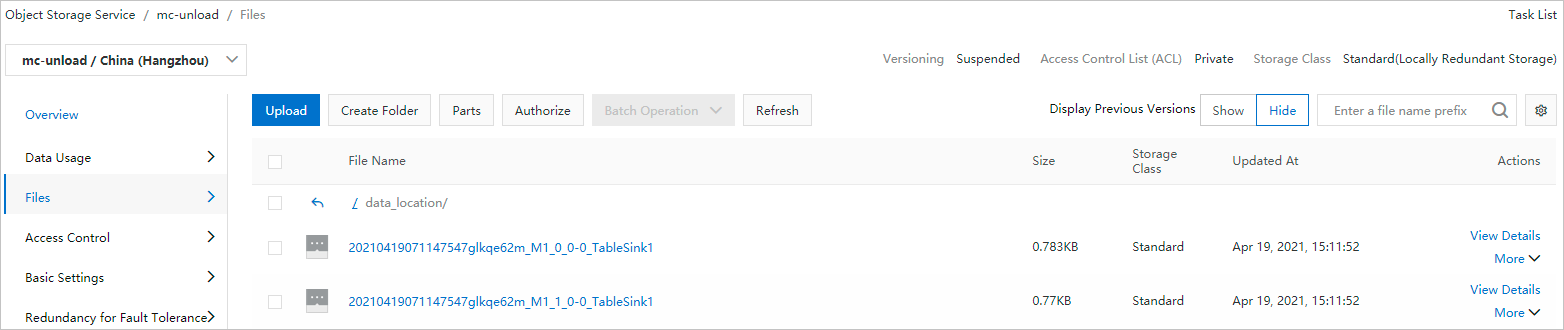
-
Result for Example 2:

Export to Hologres
Export MaxCompute data to a non-partitioned Hologres table over JDBC.
Syntax
UNLOAD FROM {<select_statement> | <table_name>}
INTO
LOCATION <external_location>
STORED BY 'com.aliyun.odps.jdbc.JdbcStorageHandler'
WITH SERDEPROPERTIES (
'odps.properties.rolearn'='<ram_arn>',
'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver',
'odps.federation.jdbc.target.db.type'='holo'
);Parameters
| Parameter | Required | Description |
|---|---|---|
select_statement |
No | A SELECT clause that queries data from a non-partitioned source table. SELECT syntax. |
table_name |
No | The table name. No query fee is incurred. |
external_location |
Yes | The Hologres JDBC connection URL in the format: 'jdbc:postgresql://<endpoint>:<port>/<database>?ApplicationName=MaxCompute&[currentSchema=<schema>&][useSSL={true|false}&]table=<holo_table_name>/'. Create a Hologres external table. |
Required SERDEPROPERTIES for Hologres:
| Property | Description |
|---|---|
'odps.properties.rolearn'='<ram_arn>' |
The ARN of the RAM role for STS authentication. Find it on the Roles page in the RAM console under Basic Information. |
'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver' |
The JDBC driver class for connecting to Hologres. |
'odps.federation.jdbc.target.db.type'='holo' |
Sets the target database type to Hologres. |
The data types of fields in the Hologres destination table must match those in the MaxCompute source table. For the type mapping, see Data type mappings between MaxCompute and Hologres.
Example
This example exports data from the data_test table in MaxCompute to a Hologres table named mc_2_holo:
+------------+------+
| id | name |
+------------+------+
| 3 | rgege |
| 4 | Gegegegr |
+------------+------+Step 1: Create the Hologres table mc_2_holo in the test database. Run the following statement in HoloWeb.
CREATE TABLE mc_2_holo (id INT, name TEXT);Step 2: Log on to the MaxCompute client and run the UNLOAD statement:
UNLOAD FROM
(SELECT * FROM data_test)
INTO
LOCATION 'jdbc:postgresql://hgprecn-cn-5y**********-cn-hangzhou-internal.hologres.aliyuncs.com:80/test?ApplicationName=MaxCompute¤tSchema=public&useSSL=false&table=mc_2_holo/'
STORED BY 'com.aliyun.odps.jdbc.JdbcStorageHandler'
WITH SERDEPROPERTIES (
'odps.properties.rolearn'='acs:ram::13**************:role/aliyunodpsholorole',
'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver',
'odps.federation.jdbc.target.db.type'='holo'
);Step 3: Query the exported data in Hologres to verify the result:
SELECT * FROM mc_2_holo;Expected output:
id name
4 Gegegegr
3 rgegeControl file naming
By default, MaxCompute generates file names without extensions (except CSV/TSV from built-in StorageHandlers). Add these properties to the PROPERTIES clause to customize naming.
| Property | Description |
|---|---|
'odps.external.data.prefix'='<prefix>' |
A custom prefix for all exported file names. Maximum 10 characters. |
'odps.external.data.enable.extension'='true' |
Displays the file name extension based on the file format and SerDe class. |
File name extensions by format:
| File format | SerDe | Extension |
|---|---|---|
| SEQUENCEFILE | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
.sequencefile |
| TEXTFILE | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
.txt |
| RCFILE | org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe |
.rcfile |
| ORC | org.apache.hadoop.hive.ql.io.orc.OrcSerde |
.orc |
| PARQUET | org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe |
.parquet |
| AVRO | org.apache.hadoop.hive.serde2.avro.AvroSerDe |
.avro |
| JSON | org.apache.hive.hcatalog.data.JsonSerDe |
.json |
| CSV | org.apache.hadoop.hive.serde2.OpenCSVSerde |
.csv |
Example: Export as TEXTFILE with `mf_` prefix and `.txt` extension
SET odps.sql.hive.compatible=true;
SET odps.sql.split.hive.bridge=true;
UNLOAD FROM (SELECT col_tinyint, col_binary FROM mf_fun_datatype LIMIT 1)
INTO
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/mfosscostfee/demo6/'
STORED AS textfile
PROPERTIES (
'odps.external.data.prefix'='mf_',
'odps.external.data.enable.extension'='true'
);Example: Export as CSV with `mf_` prefix and `.csv` extension
SET odps.sql.hive.compatible=true;
SET odps.sql.split.hive.bridge=true;
UNLOAD FROM (SELECT col_tinyint, col_binary FROM mf_fun_datatype LIMIT 2)
INTO
LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/mfosscostfee/demo6/'
STORED BY 'com.aliyun.odps.CsvStorageHandler'
PROPERTIES (
'odps.external.data.prefix'='mf_',
'odps.external.data.enable.extension'='true'
);Limits
-
File names are auto-generated. Customize with a prefix or extension via Control file naming.
-
Dual-signature authentication is not supported for Hologres exports.
-
Partitioned Hologres tables are not supported as export targets.
-
Open-source format output omits file extensions by default. Set
odps.external.data.enable.extension=trueto enable them.
Billing
-
The
UNLOADoperation itself is free. Any subquery (SELECTclause) is charged as a standard SQL job. -
Specifying a table name directly instead of a subquery incurs no query fee.
-
Storing structured data in OSS can reduce costs compared to MaxCompute storage. MaxCompute storage costs USD 0.018 per GB-month (charged on compressed size at ~5:1 ratio). OSS Standard storage also costs USD 0.018 per GB-month. For OSS IA, Archive, and Cold Archive pricing, see Storage fees. Estimate the actual compression ratio and access costs before migrating data to avoid unexpected charges.
-
MaxCompute compresses table data internally. Exported data is approximately 4x the compressed in-table size.
What's next
To import CSV or open-source format data from an external store into MaxCompute, use LOAD.