MaxCompute provides a data lake analytics solution that lets you create management objects to define the metadata and data access methods for external data sources. An External Project or External Schema can map to an external data source's Catalog, Database, or Schema, allowing you to directly access all tables within them. This solution breaks down the silos between a data lake and a data warehouse. It combines the flexibility and rich multi-engine ecosystem of a data lake with the enterprise-grade capabilities of a data warehouse to build an integrated data management platform. This feature is in public preview.
Data warehouse and data lake
Category | Capabilities |
Data warehouse | A data warehouse emphasizes the management and constraints on structured and semi-structured data. It relies on strong management to achieve better computing performance and more standardized management capabilities. |
Data lake | A data lake emphasizes open data storage and common data formats. It supports multiple engines that produce or consume data as needed. To ensure flexibility, it provides only weak management capabilities. It is compatible with unstructured data and supports a schema-on-read approach, offering a more flexible way to manage data. |
MaxCompute data warehouse
MaxCompute is a cloud-native data warehouse based on a serverless architecture. You can perform the following operations:
Model a data warehouse using MaxCompute.
Use extract, transform, and load (ETL) tools to load and store data in modeled tables with defined schemas.
Process large-scale data in the data warehouse using a standard SQL engine, and analyze the data using the MaxQA or Hologres OLAP engine.
Scenarios for MaxCompute with data lakes and federated queries
In a data lake scenario, data resides in the lake and is produced or consumed by various engines. The MaxCompute computing engine can act as one of these engines to process and use the data. In this case, MaxCompute needs to read data produced by upstream sources in the data lake, be compatible with various mainstream open source data formats, perform calculations within its engine, and produce data for downstream workflows.
As a secure, high-performance, and cost-effective data warehouse that aggregates high-value data, MaxCompute also needs to retrieve metadata and data from the data lake. This allows for in-engine computation on external data and federated queries with internal data to extract value and consolidate it into the data warehouse.
In addition to data lakes, MaxCompute as a data warehouse also needs to retrieve data from various other external data sources, such as Hadoop and Hologres, to perform federated queries with its internal data. In federated query scenarios, MaxCompute must also support reading metadata and data from external systems.
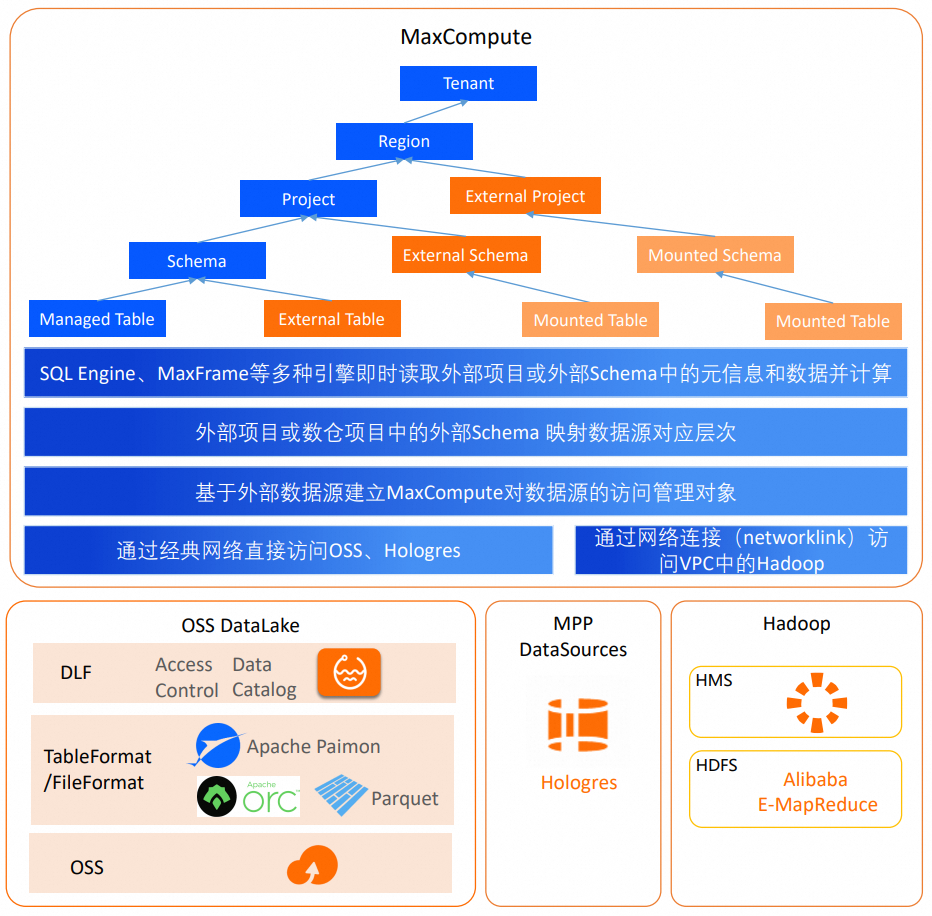
MaxCompute data lake analytics
MaxCompute data lake analytics is built on the MaxCompute computing engine.
It supports access to Alibaba Cloud metadata services or object storage services over the interconnected cloud product network. If a data source is in a VPC, you can use a leased line to access the external data source.
It lets you create management objects to define the metadata and data access methods for external data sources. An External Project or External Schema can map to an external data source's Catalog, Database, or Schema, allowing you to directly access all tables within that scope.
Network connectivity
For more information about Networklink, see Network Connection Flow. MaxCompute can use a network connection to access data sources in VPCs, such as E-MapReduce (EMR) clusters and ApsaraDB RDS instances (available soon). Data Lake Formation (DLF), Object Storage Service (OSS), and Hologres are located in an interconnected network of cloud services. MaxCompute can directly access data in these services without configuring Networklink.
Foreign Server
A Foreign Server contains metadata and data access information, including its credentials, location, and connection protocol. MaxCompute uses a Foreign Server to connect to and use the metadata and data from a data source. A Foreign Server is a tenant-level management object defined by the tenant administrator.
External Schema
An External Schema is a special type of schema in a MaxCompute data warehouse project. As shown in the preceding figure, it can map to a data source's Database (for DLF_legacy or Hive scenarios) or Schema (for Hologres scenarios). This allows you to directly access tables and data within that scope. Tables that are not created in MaxCompute metadata but are mapped from an external data source through an External Schema are known as federated foreign tables (Mounted Tables).
A federated foreign table does not store metadata within MaxCompute. Instead, MaxCompute retrieves the metadata in real time from the metadata service specified in the Foreign Server object. When you run a query, you do not need to create an external table using a DDL statement. You can directly reference the original table by using the project name and External Schema name as a namespace. If the table structure or data in the source changes, the federated foreign table immediately reflects the latest state. The data source level an External Schema maps to depends on the data source's hierarchy and the access level defined in the Foreign Server.
External Project
In Data Lakehouse Solution 1.0, an External Project used a two-layer model. Similar to an External Schema, it mapped to a data source's Database (for DLF_legacy or Hive scenarios) or Schema (for Hologres scenarios) and required a data warehouse project as the runtime environment to read and compute external data. However, mapping a Database or Schema at the project level resulted in too many External Projects. Additionally, MaxCompute now recommends a three-layer project model to better align with the three-layer Catalog hierarchy of external data sources. The two-layer External Projects from Data Lakehouse Solution 1.0 are not compatible with the new three-layer data warehouse projects. Therefore, MaxCompute is phasing out External Projects from Data Lakehouse Solution 1.0. You can migrate existing External Projects to External Schemas. For migration details, see Migrate External Projects in Data Lakehouse Solution 1.0 to External Schemas in Data Lakehouse 2.0.
In data lake analytics, the new External Project directly maps to a three-layer data source's Catalog (for DLF scenarios) or Database (for Hologres scenarios). This provides direct visibility into the Databases under a DLF Catalog or the Schemas under a Hologres Database. This intermediate level, which is mapped directly without being created in MaxCompute, is called a Mounted Schema. You can then access the source tables as federated foreign tables.
Data source type | Foreign server hierarchy | External schema mapping | External project mapping | Legacy external project mapping | Authentication method |
DLF_legacy+OSS | Region-level DLF and OSS services | DLF Catalog.Database | Not supported | DLF Catalog.Database | RAMRole |
Hive+HDFS | E-MapReduce instance | Hive Database | Not supported | Hive Database | No authentication |
Hologres | Database of a Hologres instance | Schema | - | Not supported | RAMRole |
- | Database | Not supported | SLR and current user identity authentication | ||
DLF | Region-level DLF service | Not supported | DLF Catalog | Not supported | SLR and current user identity authentication |
Filesystem Catalog | Paimon Catalog-level directory on OSS | Not supported | Catalog parsed from a Paimon Catalog-level directory | Not supported | RAMRole |
Different data sources support various types of authentication. MaxCompute will support more authentication methods in future releases, such as using the current user's identity to access Hologres or using Kerberos authentication to access Hive.