Modifies the structure, properties, or partitions of an existing table.
See also: CREATE TABLE | DROP TABLE | TRUNCATE | DESC TABLE/VIEW | SHOW
Operations overview
| Category | Operation | Syntax pattern |
|---|---|---|
| Table metadata | Change owner | ALTER TABLE <t> changeowner TO <owner> |
| Change comment | ALTER TABLE <t> SET COMMENT '<comment>' | |
| Rename table | ALTER TABLE <t> RENAME TO <new_name> | |
| Update LastModifiedTime | ALTER TABLE <t> touch | |
| Lifecycle | Set lifecycle period | ALTER TABLE <t> SET LIFECYCLE <days> |
| Enable/disable lifecycle | ALTER TABLE <t> PARTITION [...] {enable|disable} LIFECYCLE | |
| Cluster properties | Add hash clustering | ALTER TABLE <t> clustered BY (...) [sorted BY (...)] INTO <n> buckets |
| Add range clustering | ALTER TABLE <t> RANGE clustered BY (...) [sorted BY (...)] [INTO <n> buckets] | |
| Remove clustering | ALTER TABLE <t> [PARTITION [...]] NOT clustered | |
| PK Delta Table | Update bucket count | ALTER TABLE <t> {SET|REWRITE} tblproperties("write.bucket.num"="<n>") |
| Update retention | ALTER TABLE <t> SET tblproperties("acid.data.retain.hours"="<hours>") | |
| Columns | Add columns | ALTER TABLE <t> ADD COLUMNS [IF NOT EXISTS] (<col> <type> ...) |
| Delete columns | ALTER TABLE <t> DROP COLUMN(S) <col> [, <col>...] | |
| Change column data type | ALTER TABLE <t> CHANGE [COLUMN] | |
| Reorder column | ALTER TABLE <t> CHANGE | |
| Rename column | ALTER TABLE <t> CHANGE COLUMN | |
| Change column comment | ALTER TABLE <t> CHANGE COLUMN <col> COMMENT '<comment>' | |
| Allow NULL values | ALTER TABLE <t> CHANGE COLUMN <col> NULL | |
| Partitions | Add partitions | ALTER TABLE <t> ADD [IF NOT EXISTS] PARTITION <pt_spec> [...] |
| Drop partitions | ALTER TABLE <t> DROP [IF EXISTS] PARTITION <pt_spec|filter> | |
| Rename partition | ALTER TABLE <t> PARTITION (...) rename TO PARTITION (...) | |
| Update partition LastModifiedTime | ALTER TABLE <t> touch PARTITION (<pt_spec>) | |
| Merge partitions | ALTER TABLE <t> MERGE [IF EXISTS] PARTITION (...) overwrite PARTITION (...) | |
| File management | Compact transactional table | ALTER TABLE <t> [PARTITION (...)] compact {minor|major} |
| Merge small files | ALTER TABLE <t> [PARTITION (...)] MERGE SMALLFILES |
Usage notes
Schema evolution — adding columns of complex data types, deleting columns, reordering columns, or changing column data types — alters the read and write behavior of a table. The following restrictions apply after schema evolution:
MapReduce 1.0: Graph tasks cannot read from or write to the modified table.
CUPID jobs: Only Spark-2.3.0-odps0.34.0 and Spark-3.1.1-odps0.34.0 can read from the table. Writing is not supported.
PAI jobs: Reading is supported. Writing is not supported.
Hologres jobs: If the Hologres version is earlier than 1.3, reading from and writing to the modified table as a foreign table is not supported.
CLONE TABLE: Not supported when schema evolution occurs.
Streaming Tunnel: An error is reported when schema evolution occurs.
Change the table owner
ALTER TABLE <table_name> changeowner TO <new_owner>;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table whose owner you want to change. |
new_owner | Yes | The account name of the new owner. |
Example:
-- Transfer ownership of the test1 table to ALIYUN$xxx@aliyun.com.
ALTER TABLE test1 changeowner TO 'ALIYUN$xxx@aliyun.com';Change the table comment
ALTER TABLE <table_name> SET COMMENT '<new_comment>';Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table whose comment you want to change. |
new_comment | Yes | The new comment text. |
Example:
ALTER TABLE sale_detail SET COMMENT 'new comments for table sale_detail';Run DESC <table_name> to verify the updated comment.
Rename a table
Renames a table without modifying its data.
ALTER TABLE <table_name> RENAME TO <new_table_name>;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The table to rename. |
new_table_name | Yes | The new name. An error is returned if a table with this name already exists. |
Example:
ALTER TABLE sale_detail RENAME TO sale_detail_rename;Update the LastModifiedTime of a table
The touch operation sets LastModifiedTime to the current time, which restarts the lifecycle calculation for the table.
ALTER TABLE <table_name> touch;Example:
ALTER TABLE sale_detail touch;Set the lifecycle period
Changes the lifecycle period of an existing partitioned or non-partitioned table.
ALTER TABLE <table_name> SET LIFECYCLE <days>;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table whose lifecycle period you want to change. |
days | Yes | The new lifecycle period, in days. Must be a positive integer. |
Example:
-- Set the lifecycle of sale_detail_rename to 50 days.
ALTER TABLE sale_detail_rename SET LIFECYCLE 50;Enable or disable the lifecycle
Enables or disables the lifecycle for a table or a specific partition.
ALTER TABLE <table_name> PARTITION [<pt_spec>] {enable|disable} LIFECYCLE;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table. |
pt_spec | No | The target partition. Format: partition_col1=val1, partition_col2=val2, .... For multi-level partitioned tables, specify all partition values. |
enable | — | Reapplies lifecycle reclamation to the table and its partitions using their current lifecycle configurations. Update lifecycle configurations before enabling if needed to prevent unintended data reclamation. |
disable | — | Prevents the table and all its partitions from being reclaimed. This takes priority over any partition-level enable setting. Lifecycle configurations and partition-level flags are preserved and can still be modified while the lifecycle is disabled. |
Examples:
-- Example 1: Disable the lifecycle for the sale_detail_rename table.
ALTER TABLE sale_detail_rename disable LIFECYCLE;
-- Example 2: Add test partitions.
ALTER TABLE sale_detail_rename ADD IF NOT EXISTS
PARTITION (sale_date='201910', region='shanghai') PARTITION (sale_date='201911', region='shanghai')
PARTITION (sale_date='201912', region='shanghai') PARTITION (sale_date='202001', region='shanghai')
PARTITION (sale_date='202002', region='shanghai') PARTITION (sale_date='201910', region='beijing')
PARTITION (sale_date='201911', region='beijing') PARTITION (sale_date='201912', region='beijing')
PARTITION (sale_date='202001', region='beijing') PARTITION (sale_date='202002', region='beijing');
-- Disable the lifecycle for a single partition.
ALTER TABLE sale_detail_rename PARTITION (sale_date='201912', region='shanghai') disable LIFECYCLE;Change the cluster properties of a table
Adds or removes cluster properties for a partitioned table.
Cluster properties can only be changed for partitioned tables. Non-partitioned tables cannot change cluster properties after creation. The change affects only new partitions (including those created by INSERT OVERWRITE). Old partitions retain their original cluster properties. Because this statement affects only new partitions, you cannot specify a partition in this statement.
Syntax:
-- Add hash cluster properties.
ALTER TABLE <table_name> [clustered BY (<col_name> [, <col_name>, ...]) [sorted BY (<col_name> [ASC | DESC]
[, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> buckets];
-- Remove hash or range cluster properties from a table.
ALTER TABLE <table_name> NOT clustered;
-- Add range cluster properties (bucket count is optional; the system auto-determines the optimal count).
ALTER TABLE <table_name> [RANGE clustered BY (<col_name> [, <col_name>, ...]) [sorted BY (<col_name> [ASC | DESC]
[, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> buckets];
-- Remove range cluster properties from a partition.
ALTER TABLE <table_name> PARTITION [<pt_spec>] NOT clustered;Parameters are the same as those in CREATE TABLE.
Example:
-- Create a partitioned table.
CREATE TABLE IF NOT EXISTS sale_detail(
shop_name STRING,
customer_id STRING,
total_price DOUBLE)
PARTITIONED BY (sale_date STRING, region STRING);
-- Add hash cluster properties. New partitions are stored with these settings.
ALTER TABLE sale_detail clustered BY (customer_id) sorted BY (customer_id) INTO 10 buckets;For details on clustering types, see Hash Clustering and Range Clustering.
Change the properties of a PK Delta Table
-- Update the bucket count for a partitioned PK Delta Table.
ALTER TABLE <table_name> SET tblproperties("write.bucket.num"="64");
-- Update the bucket count for a non-partitioned PK Delta Table.
-- Existing data is redistributed based on the new bucket count.
ALTER TABLE <table_name> REWRITE tblproperties("write.bucket.num"="128");
-- Update the retain property: the time range (in hours) for Time Travel queries.
ALTER TABLE <table_name> SET tblproperties("acid.data.retain.hours"="60");Enable schema evolution
The following column operations require schema evolution to be enabled at the project level: adding columns, deleting columns, reordering columns, and changing column data types.
To enable schema evolution, run:
setproject odps.schema.evolution.enable=true;Requirements:
Permissions: You must be the project owner, or hold the project-level Super_Administrator or Admin role. For details, see Assign built-in management roles to a user.
Effective period: The setting takes effect approximately 10 minutes after it is applied.
Add columns
Adds one or more columns to an existing non-partitioned or partitioned table. New columns are appended to the end of the column list. MaxCompute supports complex column types such as STRUCT<x: STRING, y: BIGINT> and MAP<STRING, STRUCT<x: DOUBLE, y: DOUBLE>>.
See the schema evolution scope for read and write behavior changes after adding columns.
Prerequisite: Enable schema evolution.
Syntax:
ALTER TABLE <table_name>
ADD COLUMNS [IF NOT EXISTS]
(<col_name1> <type1> [COMMENT '<col_comment>']
[, <col_name2> <type2> [COMMENT '<col_comment>']...]
);Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table to add columns to. New columns are added to the end of the table by default. |
col_name | Yes | The name of the new column. |
type | Yes | The data type of the new column. |
col_comment | No | A comment for the new column. |
Examples:
-- Add two columns to the sale_detail table.
ALTER TABLE sale_detail ADD COLUMNS IF NOT EXISTS (customer_name STRING, education BIGINT);
-- Add two columns with comments.
ALTER TABLE sale_detail ADD COLUMNS (customer_name STRING COMMENT 'Customer', education BIGINT COMMENT 'Education');
-- Add a column of a complex data type.
ALTER TABLE sale_detail ADD COLUMNS (region_info STRUCT<province:STRING, area:STRING>);
-- If the column already exists, IF NOT EXISTS prevents an error. The column is not added again.
ALTER TABLE sale_detail ADD COLUMNS IF NOT EXISTS (id BIGINT);
-- Add a column to a Delta table.
CREATE TABLE delta_table_test (pk BIGINT NOT NULL PRIMARY KEY, val BIGINT)
TBLPROPERTIES ("transactional"="true");
ALTER TABLE delta_table_test ADD COLUMNS (val2 BIGINT);Delete columns
Deletes one or more columns from an existing non-partitioned or partitioned table.
See the schema evolution scope for read and write behavior changes after deleting columns.
Prerequisite: Enable schema evolution.
Syntax:
-- Delete a single column.
ALTER TABLE <table_name> DROP COLUMN <col_name>;
-- Delete multiple columns.
ALTER TABLE <table_name> DROP COLUMNS <col_name1>[, <col_name2>...];Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table from which to delete columns. |
col_name | Yes | The name of the column to delete. |
Example:
-- Delete the customer_id column (enter yes to confirm).
ALTER TABLE sale_detail DROP COLUMN customer_id;
-- Delete the customer_id column using DROP COLUMNS.
ALTER TABLE sale_detail DROP COLUMNS customer_id;
-- Delete multiple columns in one statement.
ALTER TABLE sale_detail DROP COLUMNS shop_name, customer_id;Change column data types
Changes the data type of an existing column.
See the schema evolution scope for read and write behavior changes after modifying column data types.
Prerequisite: Enable schema evolution.
Syntax:
ALTER TABLE <table_name> CHANGE [COLUMN] <old_column_name> <new_column_name> <new_data_type>;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table. |
old_column_name | Yes | The name of the column whose data type you want to change. |
new_column_name | Yes | The column name after the change. Can be the same as old_column_name to keep the name unchanged. Must not match any other existing column name. |
new_data_type | Yes | The new data type for the column. |
Example:
-- Change the data type of the id column from BIGINT to STRING.
ALTER TABLE sale_detail CHANGE COLUMN id id STRING;Data type conversion table:
Y = supported. N = not supported. – = not applicable. Y() = supported if the condition in parentheses is met.
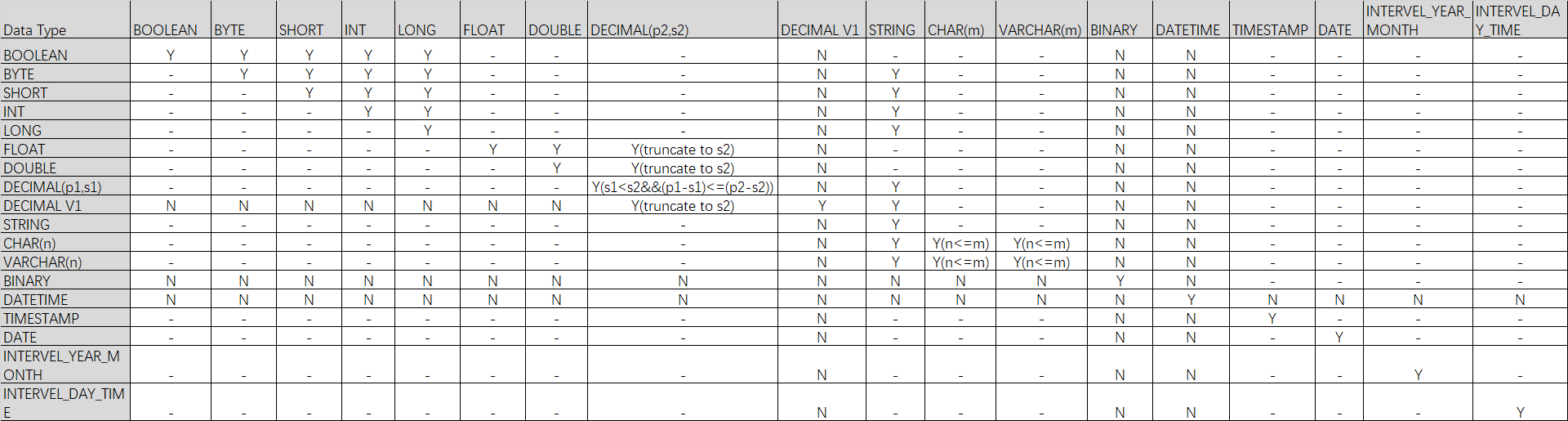
Change the column order
Moves a column to a different position in an existing non-partitioned or partitioned table.
See the schema evolution scope for read and write behavior changes after reordering columns.
Prerequisite: Enable schema evolution.
Syntax:
ALTER TABLE <table_name> CHANGE <old_column_name> <new_column_name> <column_type> AFTER <column_name>;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table. |
old_column_name | Yes | The current name of the column to move. |
new_column_name | Yes | The new name for the column. Can be the same as old_column_name to keep the name unchanged. Must not match any other existing column name. |
column_type | Yes | The data type of the column. This cannot be changed by this statement. |
column_name | Yes | The column after which to place the moved column. |
Examples:
-- Rename the customer column to customer_id and move it after total_price.
ALTER TABLE sale_detail CHANGE customer customer_id STRING AFTER total_price;
-- Move customer_id after total_price without changing its name.
ALTER TABLE sale_detail CHANGE customer_id customer_id STRING AFTER total_price;Rename a column
Renames a column in an existing non-partitioned or partitioned table.
Syntax:
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> RENAME TO <new_col_name>;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table. |
old_col_name | Yes | The name of the column to rename. The column must exist. |
new_col_name | Yes | The new column name. Must be unique within the table. |
Example:
-- Rename customer_name to customer.
ALTER TABLE sale_detail CHANGE COLUMN customer_name RENAME TO customer;Change a column comment
Updates the comment of a column in an existing non-partitioned or partitioned table.
Syntax:
ALTER TABLE <table_name> CHANGE COLUMN <col_name> COMMENT '<col_comment>';Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table. |
col_name | Yes | The name of the column whose comment you want to change. The column must exist. |
col_comment | Yes | The new comment. Maximum 1,024 bytes. |
Example:
-- Update the comment of the customer column.
ALTER TABLE sale_detail0113 CHANGE COLUMN customer COMMENT 'customer';Change a column name and comment
Updates both the name and comment of a column in a non-partitioned or partitioned table.
Syntax:
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> <new_col_name> <column_type> COMMENT '<col_comment>';Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table. |
old_col_name | Yes | The current name of the column. The column must exist. |
new_col_name | Yes | The new column name. Must be unique within the table. |
column_type | Yes | The data type of the column. |
col_comment | No | The new comment. Maximum 1,024 bytes. |
Example:
-- Rename the customer column to customer_newname and set its comment.
ALTER TABLE sale_detail CHANGE COLUMN customer customer_newname STRING COMMENT 'customer';Allow NULL values for a column
Changes a non-partition key column to allow NULL values.
This change is irreversible. Once a column allows NULL values, you cannot revert it to disallow NULL values.
Run DESC EXTENDED <table_name> to check the Nullable property before making this change:
Nullable = true: NULL values are allowed.Nullable = false: NULL values are not allowed.
Syntax:
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> NULL;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table. |
old_col_name | Yes | The name of the non-partition key column to modify. The column must exist. |
Example:
-- Create a partitioned table where the id column is NOT NULL.
CREATE TABLE null_test (id INT NOT NULL, name STRING) PARTITIONED BY (ds STRING);
-- Check the current Nullable property.
DESC EXTENDED null_test;
-- Result:
+------------------------------------------------------------------------------------+
| Native Columns: |
+------------------------------------------------------------------------------------+
| Field | Type | Label | ExtendedLabel | Nullable | DefaultValue | Comment |
+------------------------------------------------------------------------------------+
| id | int | | | false | NULL | |
| name | string | | | true | NULL | |
+------------------------------------------------------------------------------------+
| Partition Columns: |
+------------------------------------------------------------------------------------+
| ds | string | |
+------------------------------------------------------------------------------------+
-- Allow the id column to be NULL.
ALTER TABLE null_test CHANGE COLUMN id NULL;
-- Verify the change.
DESC EXTENDED null_test;
-- Result:
+------------------------------------------------------------------------------------+
| Native Columns: |
+------------------------------------------------------------------------------------+
| Field | Type | Label | ExtendedLabel | Nullable | DefaultValue | Comment |
+------------------------------------------------------------------------------------+
| id | int | | | true | NULL | |
| name | string | | | true | NULL | |
+------------------------------------------------------------------------------------+
| Partition Columns: |
+------------------------------------------------------------------------------------+
| ds | string | |
+------------------------------------------------------------------------------------+Add partitions
Adds one or more partitions to a partitioned table.
Limitations:
For multi-level partitioned tables, specify values for all partition key columns.
Partition values can be specified, but not new partition key names.
Syntax:
ALTER TABLE <table_name> ADD [IF NOT EXISTS] PARTITION <pt_spec> [PARTITION <pt_spec> ...];Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the target partitioned table. |
IF NOT EXISTS | No | If omitted, an error is returned when the partition already exists. If specified, the operation succeeds even if the partition exists. |
pt_spec | Yes | The partition specification. Format: (col1=val1, col2=val2, ...). Key names are case-insensitive; values are case-sensitive. |
Examples:
-- Create the sale_detail table used in these examples.
CREATE TABLE IF NOT EXISTS sale_detail(
shop_name STRING,
customer_id STRING,
total_price DOUBLE)
PARTITIONED BY (sale_date STRING, region STRING);
-- Example 1: Add a single partition.
ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date='202512', region='hangzhou');
-- Example 2: Add two partitions in one statement.
ALTER TABLE sale_detail ADD IF NOT EXISTS
PARTITION (sale_date='202512', region='beijing')
PARTITION (sale_date='202512', region='shanghai');
-- Example 3: Specifying only one partition column on a two-column partitioned table returns an error.
ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date='20260111');
-- Error:
-- FAILED: ODPS-0130071:[1,58] Semantic analysis exception - provided partition spec does not match table partition spec
-- Example 4: Add a partition to a Delta table.
CREATE TABLE delta_table_test (
pk BIGINT NOT NULL PRIMARY KEY,
val BIGINT NOT NULL)
PARTITIONED BY (dd STRING, hh STRING)
TBLPROPERTIES ("transactional"="true");
ALTER TABLE delta_table_test ADD PARTITION (dd='01', hh='01');
-- Example 5: Change the properties of a Delta table after adding a partition.
-- Update the bucket count (partitioned tables only).
ALTER TABLE delta_table_test SET tblproperties("write.bucket.num"="64");
-- Update the Time Travel retain property.
ALTER TABLE delta_table_test SET tblproperties("acid.data.retain.hours"="60");Update the LastModifiedTime of a partition
The touch operation sets LastModifiedTime for a partition to the current time, which triggers lifecycle recalculation.
Limitation: For multi-level partitioned tables, specify all partition key values.
Syntax:
ALTER TABLE <table_name> touch PARTITION (<pt_spec>);Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the target partitioned table. |
pt_spec | Yes | The target partition. Format: (col1=val1, col2=val2, ...). |
Example:
-- Update the LastModifiedTime for a specific partition.
ALTER TABLE sale_detail touch PARTITION (sale_date='202512', region='shanghai');Rename a partition
Changes the value of a partition key (not the key name).
Limitations:
Only partition values can be changed, not key names.
For multi-level partitioned tables, specify values for all partition key columns.
Syntax:
ALTER TABLE <table_name> PARTITION (<pt_spec>) rename TO PARTITION (<new_pt_spec>);Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table. |
pt_spec | Yes | The source partition. Format: (col1=val1, col2=val2, ...). |
new_pt_spec | Yes | The target partition. Format: (col1=new_val1, col2=new_val2, ...). |
Example:
-- Rename a partition by changing its values.
ALTER TABLE sale_detail
PARTITION (sale_date='201312', region='hangzhou')
rename TO PARTITION (sale_date='201310', region='beijing');Merge partitions
Merges multiple source partitions into a single target partition. Source partitions are deleted and their data is moved to the target partition.
Limitations:
Not supported for external tables.
Clustered tables lose their clustering property after merging.
Maximum 4,000 partitions per merge operation.
Syntax:
ALTER TABLE <table_name> MERGE [IF EXISTS] PARTITION (<predicate>) [, PARTITION (<predicate>) ...]
overwrite PARTITION (<fullpartitionSpec>) [purge];Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the target partitioned table. |
IF EXISTS | No | If omitted, an error is returned when a specified partition does not exist. If specified, missing partitions are skipped without error. Note Concurrent modifications (INSERT, RENAME, DROP) during the merge cause errors regardless of this flag. |
predicate | Yes | The condition for selecting partitions to merge. |
fullpartitionSpec | Yes | The target partition into which data is merged. |
purge | No | If specified, the session directory is cleared immediately. Otherwise, logs are retained for the default retention period (usually 3 days). For details, see Purge. |
Examples:
-- Example 1: Merge all partitions matching a predicate into a target partition.
-- Before merge:
SHOW PARTITIONS sale_detail;
-- Result:
-- sale_date=202512/region=beijing
-- sale_date=202512/region=shanghai
-- sale_date=202602/region=beijing
-- Merge all partitions where sale_date='202512' into the target partition.
ALTER TABLE sale_detail MERGE PARTITION (sale_date='202512')
overwrite PARTITION (sale_date='202601', region='hangzhou');
-- After merge:
SHOW PARTITIONS sale_detail;
-- Result:
-- sale_date=202601/region=hangzhou
-- sale_date=202602/region=beijing
-- Example 2: Merge specific named partitions into a target partition, then clear the session directory.
ALTER TABLE sale_detail MERGE IF EXISTS
PARTITION (sale_date='202601', region='hangzhou'),
PARTITION (sale_date='202602', region='beijing')
overwrite PARTITION (sale_date='202603', region='shanghai') purge;
-- After merge:
SHOW PARTITIONS sale_detail;
-- Result:
-- sale_date=202603/region=shanghaiDrop partitions
Drops one or more partitions from a table. Dropping a partition permanently deletes its data and frees storage space.
Use the lifecycle feature to automatically reclaim old partitions instead of dropping them manually.
Limitations:
Each
PARTITIONclause in a filter condition can reference only one partition key column.Any function used in a filter expression must be a built-in scalar function.
Syntax:
-- Drop one or more specific partitions.
ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <pt_spec>;
ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <pt_spec>, PARTITION <pt_spec> [, ...];
-- Drop partitions using a filter condition.
ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <partition_filtercondition>;Filter condition format:
partition_filtercondition
: PARTITION (<partition_col> <relational_operator> <partition_col_value>)
| PARTITION (scalar(<partition_col>) <relational_operator> <partition_col_value>)
| PARTITION (<partition_filtercondition1> AND|OR <partition_filtercondition2>)
| PARTITION (NOT <partition_filtercondition>)
| PARTITION (<partition_filtercondition1>)[, PARTITION (<partition_filtercondition2>), ...]partition_col: The partition key column name.relational_operator: A relational operator. For details, see Operators.partition_col_value: A comparison value or regular expression matching the partition key column's data type.scalar(): A scalar function that processes the partition column value before comparison.Supported logical operators:
NOT,AND,OR.Multiple
PARTITIONclauses separated by commas have an OR relationship.Filter conditions are case-insensitive.
Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the target partitioned table. |
IF EXISTS | No | If omitted, an error is returned when the partition does not exist. |
pt_spec | Yes (for exact drop) | The partition to drop. Format: (col1=val1, col2=val2, ...). Key names are case-insensitive; values are case-sensitive. |
partition_filtercondition | Yes (for filter drop) | The filter condition for batch-dropping partitions. |
Examples:
-- Drop a specific partition.
ALTER TABLE sale_detail DROP IF EXISTS PARTITION (sale_date='202603', region='shanghai');
-- Drop two partitions in one statement.
ALTER TABLE sale_detail DROP IF EXISTS
PARTITION (sale_date='202412', region='hangzhou'),
PARTITION (sale_date='202412', region='shanghai');Batch-drop examples using filter conditions on a single-level partitioned table:
-- Create a single-level partitioned table and add partitions for testing.
CREATE TABLE IF NOT EXISTS sale_detail_del(
shop_name STRING,
customer_id STRING,
total_price DOUBLE)
PARTITIONED BY (sale_date STRING);
ALTER TABLE sale_detail_del ADD IF NOT EXISTS
PARTITION (sale_date='201910') PARTITION (sale_date='201911') PARTITION (sale_date='201912')
PARTITION (sale_date='202001') PARTITION (sale_date='202002') PARTITION (sale_date='202003')
PARTITION (sale_date='202004') PARTITION (sale_date='202005') PARTITION (sale_date='202006')
PARTITION (sale_date='202007');
-- Drop partitions using comparison operators.
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (sale_date < '201911');
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (sale_date >= '202007');
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (sale_date BETWEEN '202001' AND '202007');
-- Drop using LIKE and RLIKE (regular expression).
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (sale_date LIKE '20191%');
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (sale_date RLIKE '2019-\\d+-\\d+');
-- Drop using IN.
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (sale_date IN ('202002', '202004', '202006'));
-- Drop using scalar functions.
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (substr(sale_date, 1, 4) = '2020');
-- Drop using logical operators.
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (sale_date < '201912' OR sale_date >= '202006');
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (sale_date > '201912' AND sale_date <= '202004');
ALTER TABLE sale_detail_del DROP IF EXISTS PARTITION (NOT sale_date > '202004');
-- Multiple PARTITION clauses (OR relationship).
ALTER TABLE sale_detail_del DROP IF EXISTS
PARTITION (sale_date < '201911'),
PARTITION (sale_date >= '202007');Batch-drop examples for multi-level partitioned tables:
-- Create a multi-level partitioned table and add partitions for testing.
CREATE TABLE IF NOT EXISTS region_sale_detail(
shop_name STRING,
customer_id STRING,
total_price DOUBLE)
PARTITIONED BY (sale_date STRING, region STRING);
ALTER TABLE region_sale_detail ADD IF NOT EXISTS
PARTITION (sale_date='201910', region='shanghai') PARTITION (sale_date='201911', region='shanghai')
PARTITION (sale_date='201912', region='shanghai') PARTITION (sale_date='202001', region='shanghai')
PARTITION (sale_date='202002', region='shanghai') PARTITION (sale_date='201910', region='beijing')
PARTITION (sale_date='201911', region='beijing') PARTITION (sale_date='201912', region='beijing')
PARTITION (sale_date='202001', region='beijing') PARTITION (sale_date='202002', region='beijing');
-- Drop all partitions where sale_date < '201911' OR region = 'beijing'.
ALTER TABLE region_sale_detail DROP IF EXISTS
PARTITION (sale_date < '201911'),
PARTITION (region = 'beijing');
-- Drop partitions where sale_date < '201911' AND region = 'beijing'.
-- Use a single PARTITION clause with a comma-separated multi-column condition.
ALTER TABLE region_sale_detail DROP IF EXISTS PARTITION (sale_date < '201911', region = 'beijing');EachPARTITIONfilter clause can reference only one partition key column. The following statement returns an error because it combines two partition key columns in a singlePARTITIONclause:
-- This returns an error:
-- FAILED: ODPS-0130071:[1,82] Semantic analysis exception - invalid column reference region,
-- partition expression must have one and only one column reference
ALTER TABLE region_sale_detail DROP IF EXISTS PARTITION (sale_date < '201911' AND region = 'beijing');Compact files of a transactional table
A transactional table stores data in Base files and Delta files. Each UPDATE or DELETE operation appends new Delta files without modifying the Base files. Over time, many Delta files accumulate, increasing storage use and degrading read performance because the system must load all Delta files to reconstruct the current data state.
Compaction merges Base and Delta files to reduce storage and improve read efficiency.
Syntax:
ALTER TABLE <table_name> [PARTITION (<partition_key>='<partition_value>' [, ...])] compact {minor|major};Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the transactional table to compact. |
partition_key | No | The partition key column name. Required only for partitioned transactional tables. |
partition_value | No | The partition key value. Required only for partitioned transactional tables. |
minor | major | Yes | The compaction type. |
Compaction types:
| Type | Behavior |
|---|---|
minor | Merges Delta files into their corresponding Base file, eliminating the Delta files. |
major | Merges Delta files into the Base file (same as minor), then merges small files within the Base file. If the Base file is smaller than 32 MB or Delta files exist, this is equivalent to running INSERT OVERWRITE. If the Base file is 32 MB or larger and no Delta files exist, the Base file is not rewritten. |
Examples:
-- Example 1: Run minor compaction on the acid_delete table.
ALTER TABLE acid_delete compact minor;
-- Sample output:
-- Summary:
-- Nothing found to merge, set odps.merge.cross.paths=true IF cross path merge is permitted.
-- OK
-- Example 2: Run major compaction on a specific partition of the acid_update_pt table.
ALTER TABLE acid_update_pt PARTITION (ds='2019') compact major;
-- Sample output:
-- Summary:
-- table name: acid_update_pt /ds=2019 instance count: 2 run time: 6
-- before merge, file count: 8 file size: 2613 file physical size: 7839
-- after merge, file count: 2 file size: 679 file physical size: 2037
-- OKMerge small files
A distributed file system stores data in fixed-size blocks. Files smaller than the block size (64 MB) are called small files. Small files are produced by SQL queries, distributed engines, and Tunnel data ingestion. Merging small files reduces the number of files the system must open during queries, improving compute performance.
Syntax:
ALTER TABLE <table_name> [PARTITION (<partition_key>=<partition_value>)] MERGE SMALLFILES;Parameters:
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table whose small files you want to merge. |
partition_key | No | The partition key column name. Required only for partitioned tables. |
partition_value | No | The partition key value. Required only for partitioned tables. |
Example:
SET odps.merge.cross.paths=true;
SET odps.merge.smallfile.filesize.threshold=128;
SET odps.merge.max.filenumber.per.instance=2000;
ALTER TABLE tbcdm.dwd_tb_log_pv_di PARTITION (ds='20151116') MERGE SMALLFILES;If you use a pay-as-you-go instance, the small file merge feature is billed at the same rate as pay-as-you-go SQL jobs. For details, see Compute costs (pay-as-you-go).
For more information, see Merge small files.
What's next
CREATE TABLE: Create non-partitioned, partitioned, foreign, or clustered tables.
TRUNCATE: Delete all data from a table.
DROP TABLE: Delete a partitioned or non-partitioned table.
DESC TABLE/VIEW: View table schema and properties.
SHOW: List tables, views, or partitions in a project.