This topic describes the syntax of window functions and provides examples on how to use window functions.
Introduction
Aggregate functions calculate the single result for a group of rows, and window functions calculate the result for each row in a group. A window function has three elements: partition, order, and frame. For more information, see Window Function Concepts and Syntax.
function over (
[partition by partition_expression]
[order by order_expression]
[frame]
)Partition: The partition element is defined by the PARTITION BY clause. The PARTITION BY clause separates rows into partitions. If you do not specify the PARTITION BY clause, all rows are treated as a single partition.
Order: The order element is defined by the ORDER BY clause. The ORDER BY clause sorts rows in all partitions.
NoteIf you use the ORDER BY clause to sort rows on fields that have the same value, the order of these rows is non-deterministic. You can include additional fields in the ORDER BY clause to obtain the expected order of these rows. Example:
order by request_time, request_method.Frame: The frame element is defined by the FRAME clause. The FRAME clause specifies a subset of each partition. A frame further refines the rows in each partition. You cannot specify the FRAME clause for ranking functions. Syntax of the FRAME clause:
{ rows | range} { frame_start | frame_between }. Example:range between unbounded preceding and unbounded following. For more information, see Window Function Frame Specification.
Functions
Category | Function | Syntax | Description | Supported in SQL | Supported in SPL |
Aggregate functions | None | You can use all aggregate functions as window functions. For more information about aggregate functions, see Aggregate functions. | √ | × | |
Ranking functions | cume_dist() | Calculates the cumulative distribution of each value in a partition. The result is obtained by using division. The numerator is the number of rows whose field values are smaller than or equal to the field value of the specified row. The specified row is also counted. The denominator is the total number of rows in the partition. The calculation is based on the order of the rows in the partition. The return value is in the range of (0,1]. | √ | × | |
dense_rank() | Calculates the rank of each value of a specified field in a partition. If two values are the same, they are assigned the same rank. The ranks are consecutive. For example, if two values are assigned the same rank of 1, the next rank is 2. | √ | × | ||
ntile(n) | Divides the rows in each partition into the number of groups specified by the N parameter. | √ | × | ||
percent_rank() | Calculates the percentage ranking of each row in a partition. | √ | × | ||
rank() | Calculates the rank of each value of a specified field in a partition. If two values are the same, they are assigned the same rank. The ranks are not consecutive. For example, if two values are assigned the same rank of 1, the next rank is 3. | √ | × | ||
row_number() | Calculates the rank of each value of a specified field in a partition. Each value is assigned a unique rank. The ranks start from 1. For example, if three values are the same, they are assigned the ranks of 1, 2, and 3. | √ | × | ||
Offset functions | first_value(x) | Returns the value of a specified field in the first row of each partition. | √ | × | |
last_value(x) | Returns the value of a specified field in the last row of each partition. | √ | × | ||
lag(x, offset, default_value) | Returns the value of a specified field in the row that is at the specified offset before the current row in a partition. If no row exists at the specified offset before the current row, the value that is specified by default_value is returned. | √ | × | ||
lead(x, offset, default_value) | Returns the value of a specified field in the row that is at the specified offset after the current row in a partition. If no row exists at the specified offset after the current row, the value that is specified by default_value is returned. | √ | × | ||
nth_value(x, offset) | Returns the value of a specified field in the row that is at the specified offset from the beginning of a partition. | √ | × |
Aggregate functions
You can use all aggregate functions as window functions. For more information about aggregate functions, see Aggregate functions. The following example shows how to use the sum function as a window function.
Syntax
sum() over (
[partition by partition_expression]
[order by order_expression]
[frame]
)Parameters
Parameter | Description |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
frame | Specifies a subset of each partition. Example: |
Return value type
The double type.
Examples
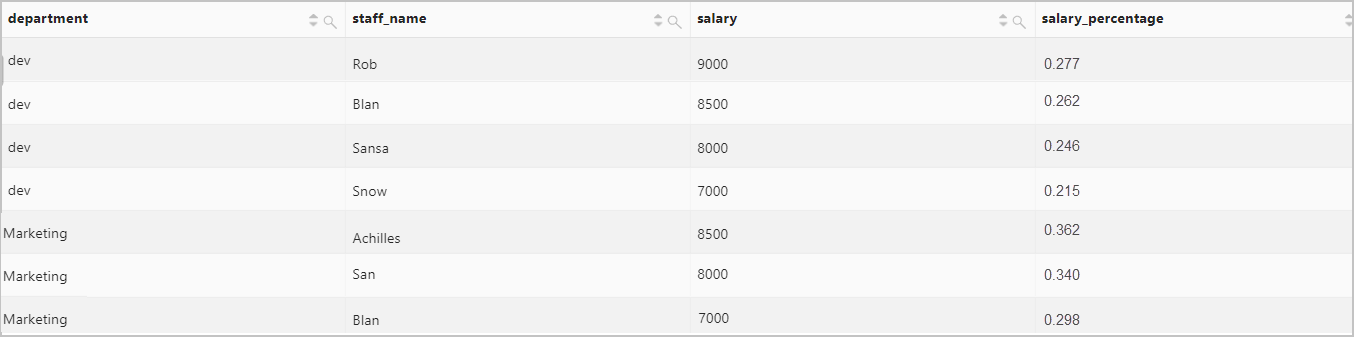
Calculate the percentage of each employee salary in each department.
Query statement
* | SELECT department, staff_name, salary, round ( salary * 1.0 / sum(salary) over(partition by department), 3) AS salary_percentageQuery and analysis results
cume_dist function
The cume_dist function calculates the cumulative distribution of each value in a partition. The result is obtained by using division. The numerator is the number of rows whose field values are smaller than or equal to the field value of the specified row. The specified row is also counted. The denominator is the total number of rows in the partition. The calculation is based on the order of the rows in the partition. The return value is in the range of (0,1].
Syntax
cume_dist() over (
[partition by partition_expression]
[order by order_expression]
)Parameters
Parameter | Description |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
Return value type
The double type.
Examples
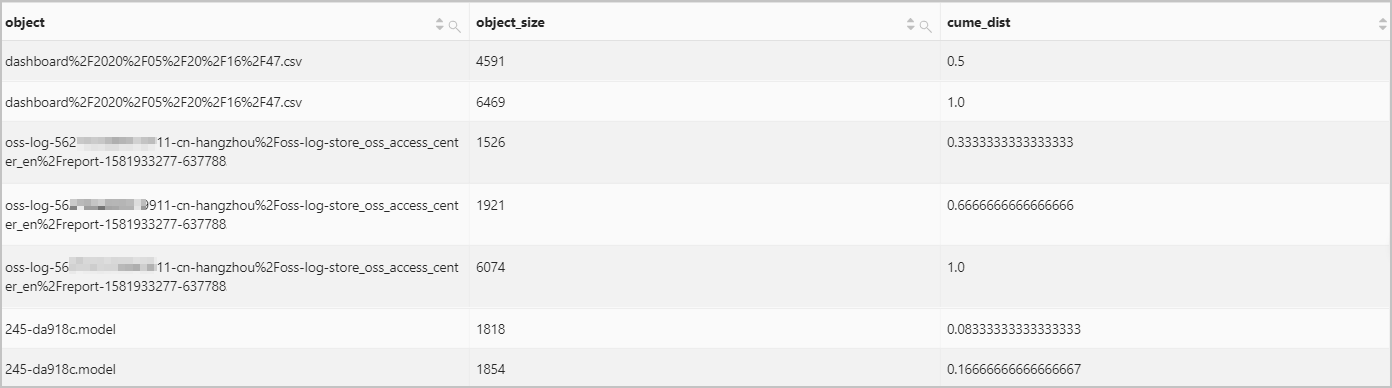
Calculate the cumulative distribution of the size of each object in an OSS bucket named bucket00788.
Query statement
bucket=bucket00788 | select object, object_size, cume_dist() over ( partition by object order by object_size ) as cume_dist from oss-log-storeQuery and analysis results
dense_rank function
The dense_rank function calculates the rank of each value of a specified field in a partition. If two values are the same, they are assigned the same rank. The ranks are consecutive. For example, if two values are assigned the same rank of 1, the next rank is 2.
Syntax
dense_rank() over (
[partition by partition_expression]
[order by order_expression]
)Parameters
Parameter | Description |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
Return value type
The bigint type.
Examples
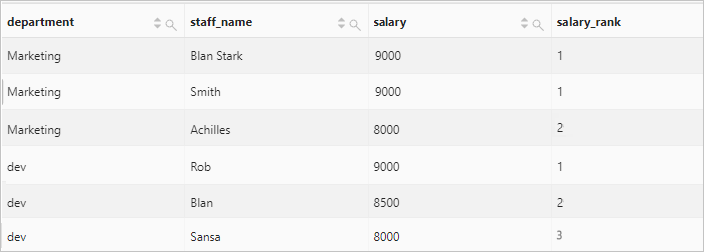
Calculate the rank of each employee salary in each department.
Query statement
* | select department, staff_name, salary, dense_rank() over( partition by department order by salary desc ) as salary_rank order by department, salary_rankQuery and analysis results
ntile function
The ntile function divides the rows in each partition into the number of groups specified by the N parameter.
Syntax
ntile(n) over (
[partition by partition_expression]
[order by order_expression]
)Parameters
Parameter | Description |
n | Specifies the number of groups. |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
Return value type
The bigint type.
Examples
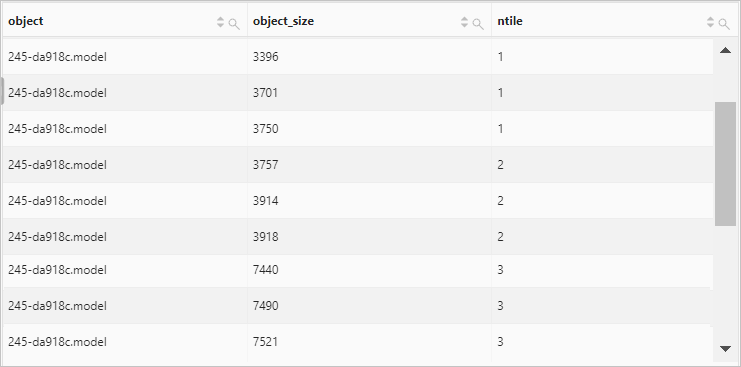
Divide the rows in each partition into three groups.
Query statement
object=245-da918c.model | select object, object_size, ntile(3) over ( partition by object order by object_size ) as ntile from oss-log-storeQuery and analysis results
percent_rank function
The percent_rank function calculates the percentage ranking of each row in a partition. The calculation formula is (rank - 1) / (total_rows - 1). In the formula, rank represents the rank of the current row, and total_rows represents the total number of rows in a partition.
Syntax
percent_rank() over (
[partition by partition_expression]
[order by order_expression]
)Parameters
Parameter | Description |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
Return value type
The double type.
Examples
Calculate the percentage ranking of the size of each OSS object.
Query statement
object=245-da918c3e2dd9dc9cb4d9283b%2F555e2441b6a4c7f094099a6dba8e7a5f.model| select object, object_size, percent_rank() over ( partition by object order by object_size ) as ntile FROM oss-log-storeQuery and analysis results

rank function
The rank function calculates the rank of each value of a specified field in a partition. If two values are the same, they are assigned the same rank. The ranks are not consecutive. For example, if two values are assigned the same rank of 1, the next rank is 3.
Syntax
rank() over (
[partition by partition_expression]
[order by order_expression]
)Parameters
Parameter | Description |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
Return value type
The bigint type.
Examples
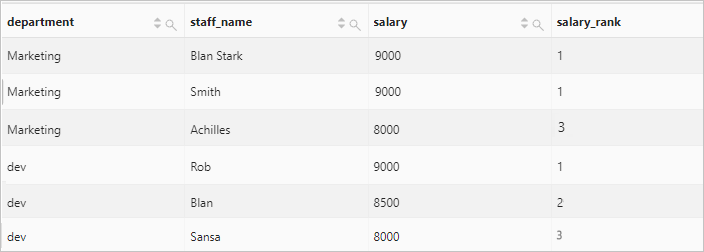
Calculate the rank of each employee salary in each department.
Query statement
* | select department, staff_name, salary, rank() over( partition by department order by salary desc ) as salary_rank order by department, salary_rankQuery and analysis results
row_number function
The row_number function calculates the rank of each value of a specified field in a partition. Each value is assigned a unique rank. The ranks start from 1.
Syntax
row_number() over (
[partition by partition_expression]
[order by order_expression]
)Parameters
Parameter | Description |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
Return value type
The bigint type.
Examples
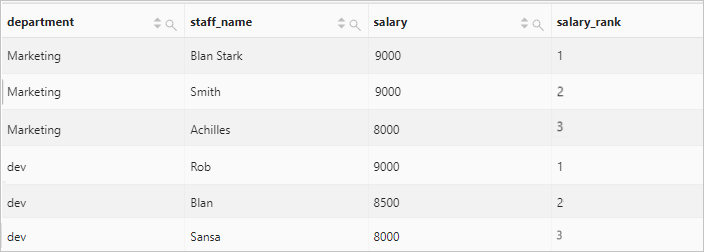
Calculate the rank of each employee salary in each department.
Query statement
* | select department, staff_name, salary, row_number() over( partition by department order by salary desc ) as salary_rank order by department, salary_rankQuery and analysis results
first_value function
The first_value function returns the value of a specified field in the first row of each partition.
Syntax
first_value(x) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)Parameters
Parameter | Description |
x | The field name. The value of this parameter can be of an arbitrary data type. |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
frame | Specifies a subset of each partition. Example: |
Return value type
The data type is the same as the data type of the x parameter.
Examples
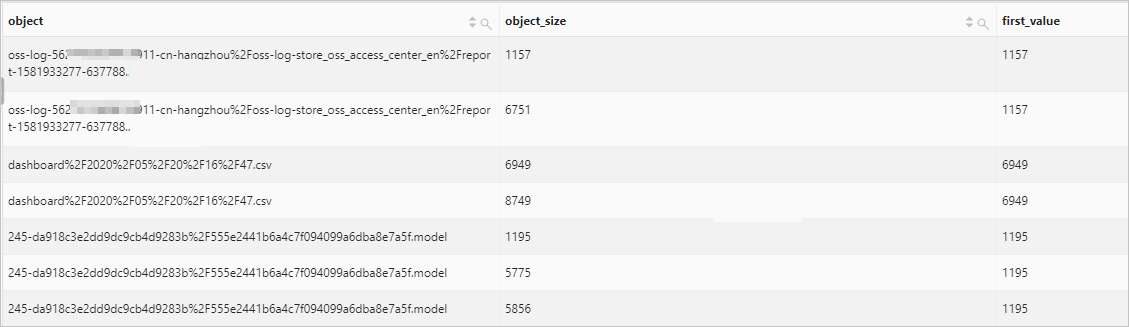
Return the minimum size of each object in the specified OSS bucket.
Query statement
bucket :bucket90 | select object, object_size, first_value(object_size) over ( partition by object order by object_size range between unbounded preceding and unbounded following ) as first_value from oss-log-storeQuery and analysis results
last_value function
The last_value function returns the value of a specified field in the last row of each partition.
Syntax
last_value(x) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)Parameters
Parameter | Description |
x | The field name. The value of this parameter can be of an arbitrary data type. |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
frame | Specifies a subset of each partition. Example: |
Return value type
The data type is the same as the data type of the x parameter.
Examples
Return the maximum size of each object in the specified OSS bucket.
Query statement
bucket :bucket90 | select object, object_size, last_value(object_size) over ( partition by object order by object_size range between unbounded preceding and unbounded following ) as last_value from oss-log-storeQuery and analysis results
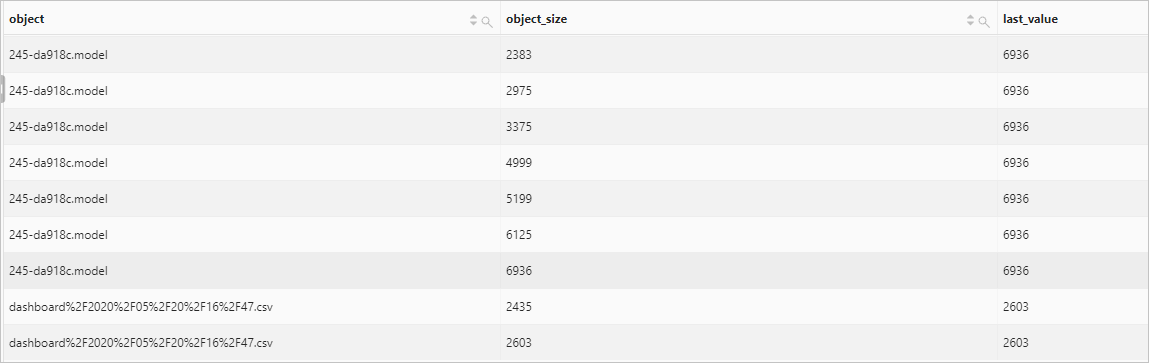
lag function
The lag function returns the value of a specified field in the row that is at the specified offset before the current row in a partition.
Syntax
lag(x, offset, default_value) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)Parameters
Parameter | Description |
x | The field name. The value of this parameter can be of an arbitrary data type. |
offset | The offset before the current row in a partition. If the value of the offset parameter is 0, the value of the specified field in the current row is returned. |
default_value | If no row exists at the specified offset before the current row, the value of the defaut_value parameter is returned. |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
frame | Specifies a subset of each partition. Example: |
Return value type
The data type is the same as the data type of the x parameter.
Examples
Count the daily unique visitors (UVs) to your website and calculates the percentage of the increase in UVs over the previous day.
Query statement
* | select day, UV, UV * 1.0 /(lag(UV, 1, 0) over()) as diff_percentage from ( select approx_distinct(client_ip) as UV, date_trunc('day', __time__) as day from log group by day order by day asc )Query and analysis results
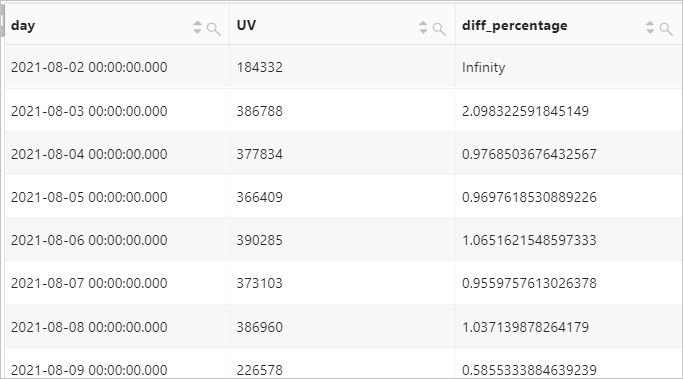
lead function
The lead function returns the value of a specified field in the row that is at the specified offset after the current row in a partition.
Syntax
lead(x, offset, default_value) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)Parameters
Parameter | Description |
x | The field name. The value of this parameter can be of an arbitrary data type. |
offset | The offset after the current row in a partition. If the value of the offset parameter is 0, the value of the specified field in the current row is returned. |
default_value | If no row exists at the specified offset after the current row, the value of the defaut_value parameter is returned. |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
frame | Specifies a subset of each partition. Example: |
Return value type
The data type is the same as the data type of the x parameter.
Examples
Count the hourly unique visitors (UVs) to your website on 2021-08-26 and calculates the difference in percentage between UVs of two consecutive hours.
Query statement
* | select time, UV, UV * 1.0 /(lead(UV, 1, 0) over()) as diff_percentage from ( select approx_distinct(client_ip) as uv, date_trunc('hour', __time__) as time from log group by time order by time asc )Query and analysis results
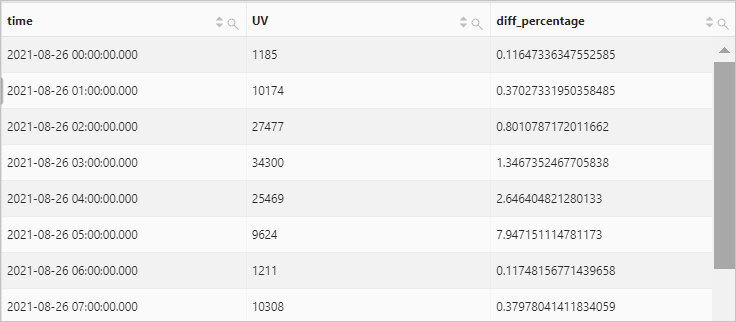
nth_value function
The nth_value function returns the value of a specified field in the row that is at the specified offset from the beginning of a partition.
Syntax
nth_value(x, offset) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)Parameters
Parameter | Description |
x | The field name. The value of this parameter can be of an arbitrary data type. |
offset | The offset from the beginning of a partition. |
partition by partition_expression | Specifies how the rows are partitioned based on the value of the partition_expression parameter. |
order by order_expression | Specifies how the rows in each partition are ordered based on the value of the order_expression parameter. |
frame | Specifies a subset of each partition. Example: |
Return value type
The data type is the same as the data type of the x parameter.
Examples
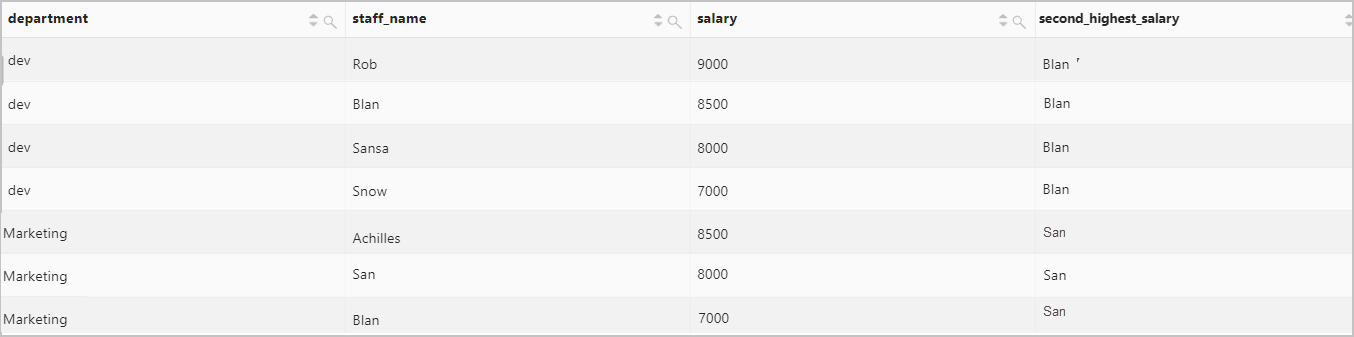
Return the employees whose salary is the second highest in each department.
Query statement
* | select department, staff_name, salary, nth_value(staff_name, 2) over( partition by department order by salary desc range between unbounded preceding and unbounded following ) as second_highest_salary from logQuery and analysis results