After you submit a compute engine job, you can view its running status using the Spark UI or the HDFS Shell tool.
Prerequisites
The compute engine service is enabled for the Lindorm instance. For more information, see Enable services.
The IP address of the client is added to the whitelist of the Lindorm instance. For more information, see Configure a whitelist.
View the job running status using the Spark UI
You can view the running status of Spark jobs on the Spark UI.
You can view the running status of a compute engine job on the Spark UI only when the job is in the Running state.
To view completed Spark jobs, enable the History Server.
For more information about the Spark UI, see View job running information.
Log on to the Lindorm console.
On the Instances page, click the ID of the destination instance.
In the navigation pane on the left, choose to view the jobs running on the compute engine.
Click the WebUI Address of the desired compute engine job and log on to the Spark UI with the username and password for LindormTable.
NoteTo obtain the default username and password for LindormTable, go to the Database Connections page, click the Wide Table Engine tab, and copy the default username and password.
In the top menu bar, click Executors to view the running compute engine jobs and all executors.
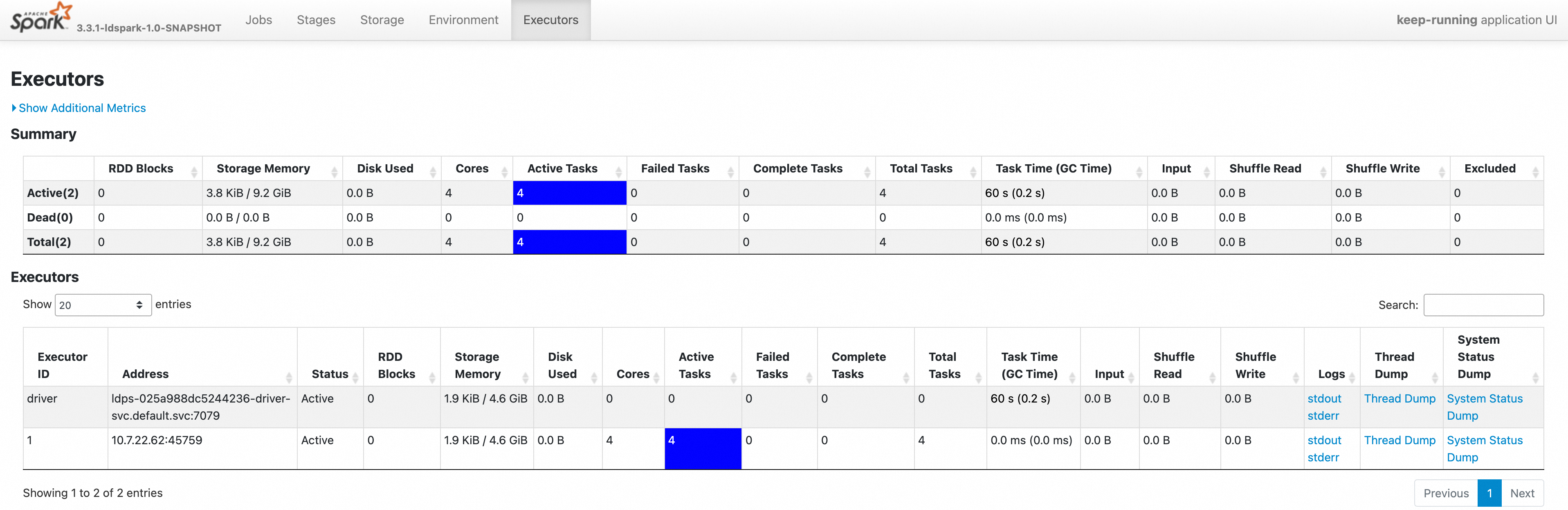
In the Executors list, click stdout or stderr in the Logs column to view the operational logs. Click Thread Dump in the corresponding column to view thread stack information. Click System Status Dump in the corresponding column to view the system status information of the Executor.
NoteClick stdout to view the standard output logs.
Click stderr to view the standard error output logs.
View job operational logs using the HDFS Shell tool
The operational logs of compute engine jobs are synchronized and stored in the underlying file engine. If a compute engine job is interrupted, you can enable the Lindorm file engine and use the Hadoop Distributed File System (HDFS) Shell tool to view the job's operational logs.
When you submit a JAR job, initialize the SparkSession object at the beginning of the Main function. This prevents abnormal operational logs from failing to sync to the file engine.
If the compute engine service of a Lindorm instance is large, the operational logs of compute engine jobs may put significant pressure on the Distributed File System (DFS). In the startup parameters of the compute engine job, you can configure the spark.dfsLog.executor.enabled=false parameter. This prevents executor logs from being saved to the DFS. The collection of the driver's operational logs for the compute engine job is not affected.
Log on to the Lindorm console.
On the Instances page, click the ID of the destination instance.
In the navigation pane on the left, choose . On the Jobs page, find the JobId, such as
562f7c98-2a66-****, as shown in the following figure.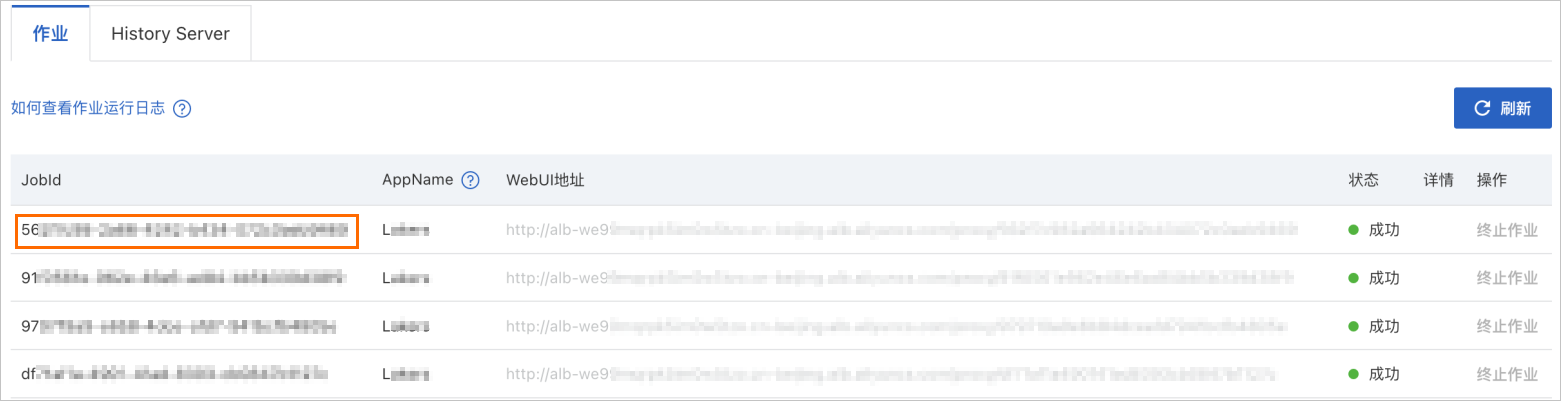
Use the HDFS Shell tool to view the logs. For more information about how to configure the HDFS Shell tool, see Connection guide.
The log folder for compute engine jobs is
/ldspark/ldspark-logs/${JobId}. The log folder for the driver is__driver_logs__. The log folder for the executor is__executor_logs__/${EXECUTOR_ID}. To view the driver's stderr operational log, run the following statement:$HADOOP_HOME/bin/hadoop fs -cat /ldspark/ldspark-logs/${JobId}/__driver_logs__/stderr | lessNoteYou can also use a Filesystem in Userspace (FUSE) client to mount the file engine folder to an ECS instance for access. For more information, see Connect to and use LindormDFS using HDFS FUSE.