LindormTable uses a Log-Structured Merge-Tree (LSM-Tree) storage structure. Getting an exact row count requires a full table scan — the larger the table, the longer the operation takes. Avoid running COUNT operations frequently.
The following methods are available:
| Method | Count type | Speed | Best for |
|---|---|---|---|
| HBase Shell COUNT | Exact | Under 100,000 rows/sec | Small tables, quick checks |
| HBase RowCounter | Exact | Similar to HBase Shell (multithreaded option available) | Data integrity validation after migration |
Lindorm SQL SELECT COUNT(*) | Exact | Hundreds of thousands of rows/sec/server (distributed) | Large tables requiring faster exact counts |
Lindorm SQL SHOW ESTIMATED ROWS | Estimated | Instant | Quick capacity estimates |
| Cluster management system | Estimated | Instant | Data integrity check after migration |
Prerequisites
Before you begin, ensure that you have:
Access to LindormTable
An ECS client in the same VPC as your Lindorm cluster (required for HBase Shell and RowCounter operations)
Count the number of rows using HBase Shell
Connect to LindormTable using HBase Shell. For more information, see Access LindormTable using Lindorm Shell.
The count command scans all table data in batches to compile row statistics. Run it on an ECS client in the same VPC (virtual private cloud) — running it over the Internet causes high network usage and significantly slows the operation. Scan speed is under 100,000 rows per second and varies based on table schema.
Run the following command to count all rows in a table:
count 'table'The following result is returned:

Count the number of rows using HBase RowCounter
Connect to LindormTable using HBase Shell. For more information, see Access LindormTable using Lindorm Shell.
RowCounter runs a local, pseudo-distributed MapReduce job to count rows.
By default, RowCounter is single-threaded, with counting speed similar to the HBase Shell count command.
Examples:
Count all rows in a table:
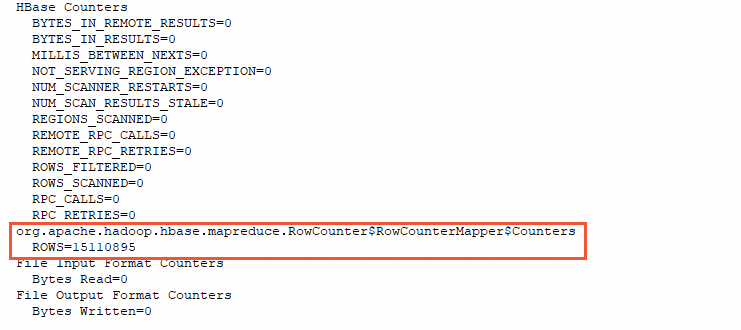
./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter "table"Count all rows using 16 concurrent threads:
./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter -Dmapreduce.local.map.tasks.maximum=16 "table"Count all rows in a table in the
nsnamespace:./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter "ns:table"
When using multiple threads, note that:
The thread count must be less than or equal to the number of regions in the table.
A higher thread count increases cluster load and may affect online services.
The result is saved in the hbase.log file in the Log directory.
Count the number of rows using Lindorm SQL
Count the exact number of rows
Connect to LindormTable using Lindorm-cli. For more information, see Connect to LindormTable using Lindorm-cli.
Lindorm SQL distributes the COUNT logic across all Lindorm processes in parallel, making it significantly faster than HBase Shell. Speed reaches hundreds of thousands of rows per second per server and scales with the number of servers in your cluster. The operation still requires a full table scan and has a default timeout of 120 seconds — if the count does not complete within that limit, the statement returns an error.
SELECT COUNT(*) FROM table;The following result is returned:
+--------+
| EXPR$0 |
+--------+
| 16000 |
+--------+For tables with more than one million rows, use a search index to accelerate the query. For more information, see Query data in a wide table using a search index.
Count the estimated number of rows
This feature requires LindormTable version 2.8.2.6 or later and Lindorm SQL version 2.8.2.6 or later.
Run the following statement to get an estimated row count without a full table scan:
SHOW ESTIMATED ROWS FROM table;The following result is returned:
+---------------------+
| ESTIMATED_ROW_COUNT |
+---------------------+
| 15000 |
+---------------------+View the estimated number of rows using the cluster management system
Log on to the cluster management system. For more information, see Log on to the cluster management system.
In the Lindorm cluster management system, click Overview
The estimated row count is calculated by adding the row count metadata from each data file, collected when the files were created. This value may be inaccurate if the table has updates, deletions, or TTL (time-to-live) expired data — in those cases, the same row may exist in multiple files with different states. If the table has no updates, deletions, or TTL expiry, the displayed count is completely accurate. This makes it useful for verifying data integrity after a data migration.
If the estimated row count shows 0 but the table contains data, the minor version of LindormTable may be outdated. Upgrade the minor version to resolve this. For more information, see Upgrade the minor version.