This guide explains how to create an agent for audio/video calls.
Activate the service
Before you begin, ensure you meet the following requirements:
Real-time Conversational AI is enabled. To enable the feature, go to the buy page.
Step 1: Create a workflow
Go to the Real-time Workflow Template page in the IMS console and click Create Workflow Template.
Select a type of workflow as needed: Audio Call, Avatar Call, Vision Call or Video Call.

Speech-to-Text (STT)
This node converts audio input into text and supports multiple languages.
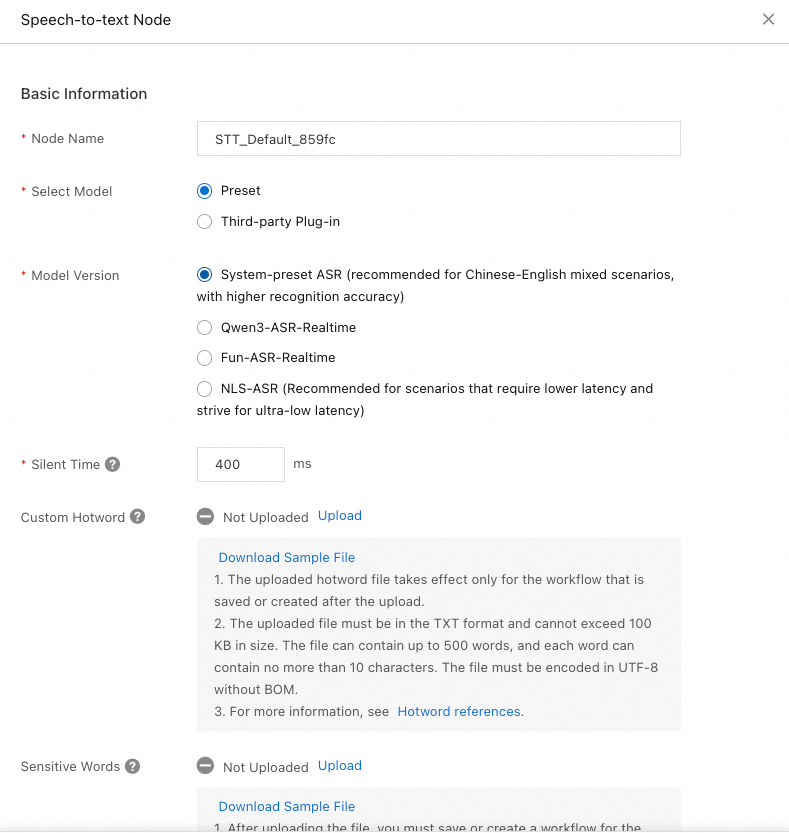
Preset: The system's preset models support selecting a source language, setting the silence duration, and configuring custom hotwords.
Language Model: Select the source language as needed.
Silent Time: The duration the agent waits for a user's voice input before timing out.
Custom Hotword: To improve the recognition accuracy of domain-specific terms, configure hotwords. For more information, see Speech recognition hotwords.
Sensitive Words: If you configure sensitive words, the system automatically masks them in client-side output with asterisks (*). For more information, see Custom sensitive words.
Third-party Plug-in: Currently, only iFLYTEK plug-in is supported. Get the required parameters at iFLYTEK.
Large Language Model (LLM)
The LLM node uses text from the STT node and a large language model to understand and generate natural language.
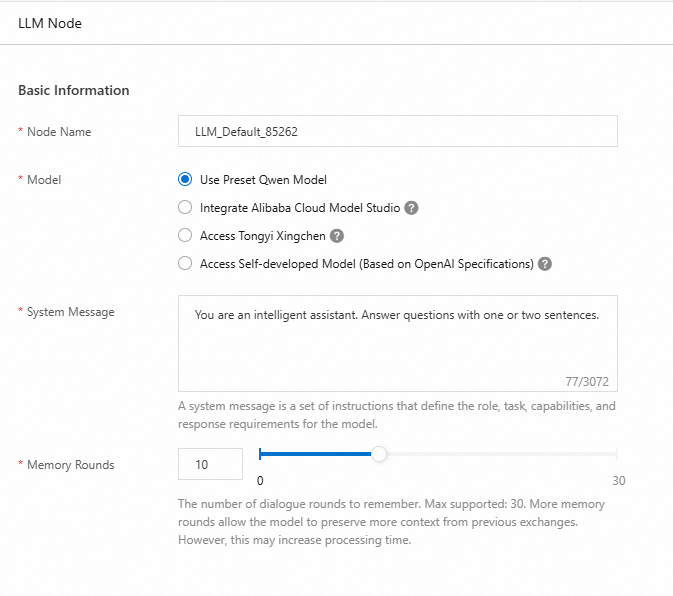
Real-time Conversational AI supports integration with Qwen (system preset), Alibaba Cloud Model Studio, Tongyi Xingchen, and self-developed models (OpenAI-compliant).
Alibaba Cloud Model Studio
Alibaba Cloud Model Studio is a one-stop platform for model development and application building. Select and integrate models and services from Alibaba Cloud Model Studio:
Model: Go to the Models page, select a model, and copy its code as ModelId.

Application: Go to the My Applications page, create an application, and copy its Application ID.

Go to the Key Management page, create and copy the API key.

Tongyi Xingchen
Tongyi Xingchen enables you to create highly personalized agents, each with a unique persona and style. Combined with real-time voice interaction capabilities, these agents can deliver rich, interactive experiences in various scenarios.
ModelId: Tongyi Xingchen offers the following five models:
xingchen-lite,xingchen-base,xingchen-plus,xingchen-plus-v2, andxingchen-max.API-KEY: Visit the Tongyi Xingchen console to create and obtain an API Key.
Self-developed model (OpenAI-compliant)
Real-time Conversational AI supports self-developed LLMs that comply with the OpenAI specification.
OpenAI specification: To connect a model using the OpenAI specification, provide the following parameters:
Name
Description
Example
ModelId
The model name. This parameter corresponds to the model field in the OpenAI specification.
abc
API-KEY
The authentication information. This parameter corresponds to the api_key field in the OpenAPI specification.
AUJH-pfnTNMPBm6iWXcJAcWsrscb5KYaLitQhHBLKrI
Model URL (HTTPS)
The service request URL. This parameter corresponds to the base_url field in the OpenAPI specification.
http://www.abc.com
For more details on integrating custom LLMs, see LLM standard interface.
Text-to-Speech (TTS)
This node converts text to spoken audio, letting users hear the system's response.
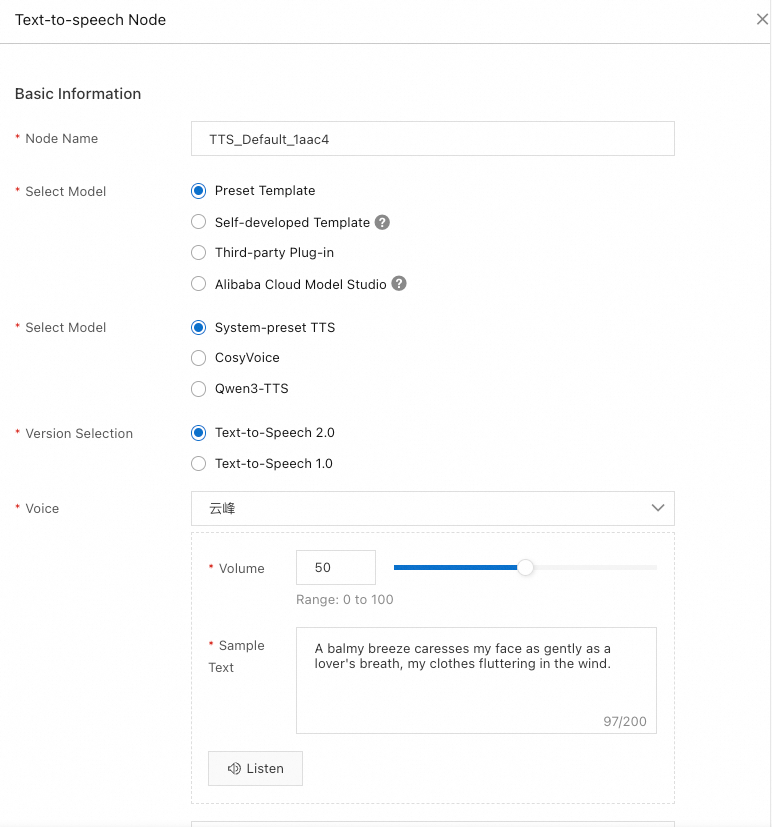
You can select a TTS model that suits your application:
Preset Template: For a preset template, you need to configure the voice. For examples of different voice effects, see Intelligent voice samples.
Self-developed Template: Integrate your own model into the workflow by following a standardized protocol. For more information, see Access TTS models.
Third-party Plug-in: Currently, only the MiniMax Speech Model is supported. Multiple versions are available, and we recommend using the latest one. For more information, see MiniMax Speech Model.
Filter: Filter the specific symbols from the LLM output before it is converted to speech.

Text Normalization: Convert numbers, symbols, and other non-standard words into a uniform, spoken format to make text-to-speech sound more natural. For example, it turns "$100" into "one hundred dollars."
Avatar
This node generates the video stream of the avatar which moves and speaks according to the processed text and audio, with rich facial expressions.

Choose one of the following options in the node:
Avatar Plug-in:
Faceunity: Contact FaceUnity customer support to activate the 3D avatar service. You must get AppId, AppKey, and AvatarId.
Lingjing Digital Avatar Platform: Submit a ticket to activate the service.
Video Frame Extraction
This node extracts single or multiple frames from a video.

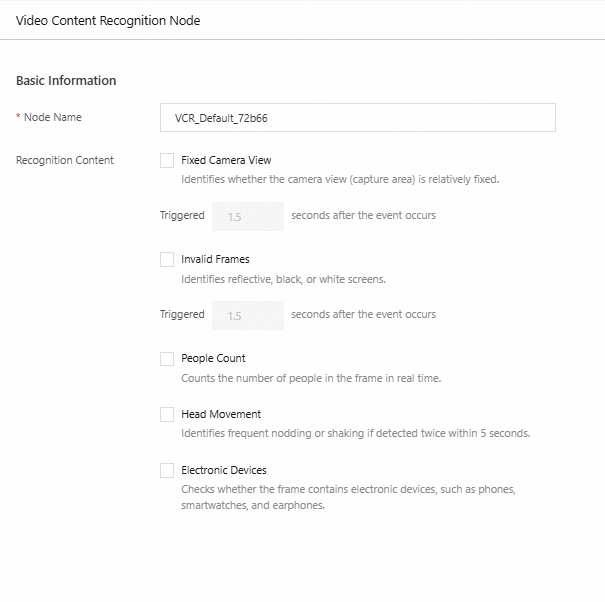
Video Content Recognition
This node identifies specific actions in the video.
Multimodal Large Language Model (MLLM)
The MLLM uses data from previous nodes to understand input images and text, then generates a natural language response. You can control the model's input by selecting different model types.

Real-time Conversational AI supports integration with Qwen (system preset), Alibaba Cloud Model Studio, Tongyi Xingchen, and self-developed models (OpenAI-compliant).
Alibaba Cloud Model Studio Alibaba Cloud Model Studio is a one-stop platform for model development and application building. Select and integrate models and services from Alibaba Cloud Model Studio:
Model: Go to the Models page, select a model, and copy its code as ModelId.
Application: Go to the My Applications page, create an application, and copy its Application ID.
Go to the Key Management page, create and copy the API key.
Tongyi Xingchen
Tongyi Xingchen enables you to create highly personalized agents, each with a unique persona and style. Combined with real-time voice interaction capabilities, these agents can deliver rich, interactive experiences in various scenarios.
ModelId: Tongyi Xingchen offers the following five models:
xingchen-lite,xingchen-base,xingchen-plus,xingchen-plus-v2, andxingchen-max.API-KEY: Visit the Tongyi Xingchen console to create and obtain an API Key.
Self-developed model (OpenAI-compliant)
Real-time Conversational AI also supports self-developed LLMs that comply with the OpenAI specification.
OpenAI specification: To connect a model using the OpenAI specification, provide the following parameters:
Parameter
Type
Required
Description
Example
ModelId
String
Yes
The model name. This parameter corresponds to the model field in the OpenAI specification.
abc
API-KEY
String
Yes
The authentication information. This parameter corresponds to the api_key field in the OpenAPI specification.
AUJH-pfnTNMPBm6iWXcJAcWsrscb5KYaLitQhHBLKrI
Model URL (HTTPS)
String
Yes
The service request URL. This parameter corresponds to the base_url field in the OpenAPI specification.
http://www.abc.com
Maximum Number of Images per Call
Integer
Yes
Some multi-modal large models limit the number of image frames that can be received in a single request. You can set this parameter to adapt to different models. During a request, video frames are automatically sampled according to this value.
15
For more details on integrating custom LLMs, see LLM standard interface.
Click Save to create the workflow.
Step 2: Create an AI agent
Go to the AI Agents page in the IMS console and click Create AI Agent.
Configure the basic information and bind an audio/video call workflow.
Bind a workflow. The AI agent runs according to the workflow.

Select an ApsaraVideo Real-time Communication (ARTC) application under your account. If you do not have an ARTC application, the system automatically creates one. For more information about ARTC, see ARTC overview.
 Note
NoteThe ARTC application handles the real-time communication required for the conversation.
When you bind an audio call workflow, you can upload a custom profile image in the Advanced Feature section. The system will display the image during voice calls.

Click Submit to create the agent.
Step 3: Test the agent
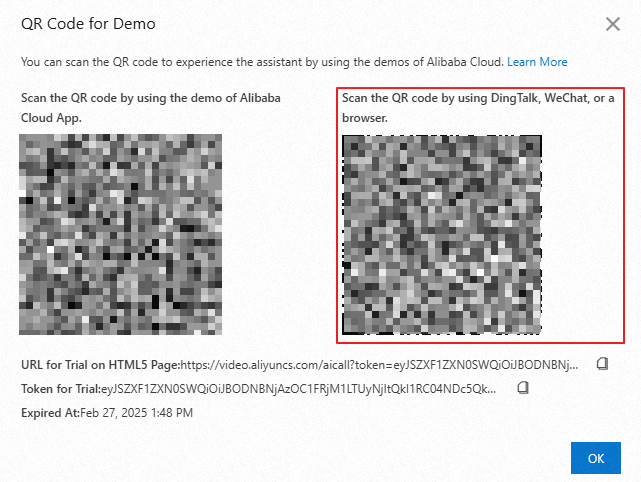
After you create the agent, you can test it by scanning a QR code for demo.
On the AI Agents page, generate a QR code for the demo.

Scan the QR code with DingTalk, WeChat, or a browser, or copy the demo URL into your browser.
Step 4: Integrate the agent
The following parameters are required for integration. To learn how to integrate an agent into your project to implement audio/video calls, see Integrate an audio/video call agent.
Region ID: The region where your workflow and agent are located as shown in the IMS console.

Region Name
Region ID
China (Hangzhou)
cn-hangzhou
China (Shanghai)
cn-shanghai
China (Beijing)
cn-beijing
China (Shenzhen)
cn-shenzhen
Singapore
ap-southeast-1
AppID and AppKey of the ARTC application

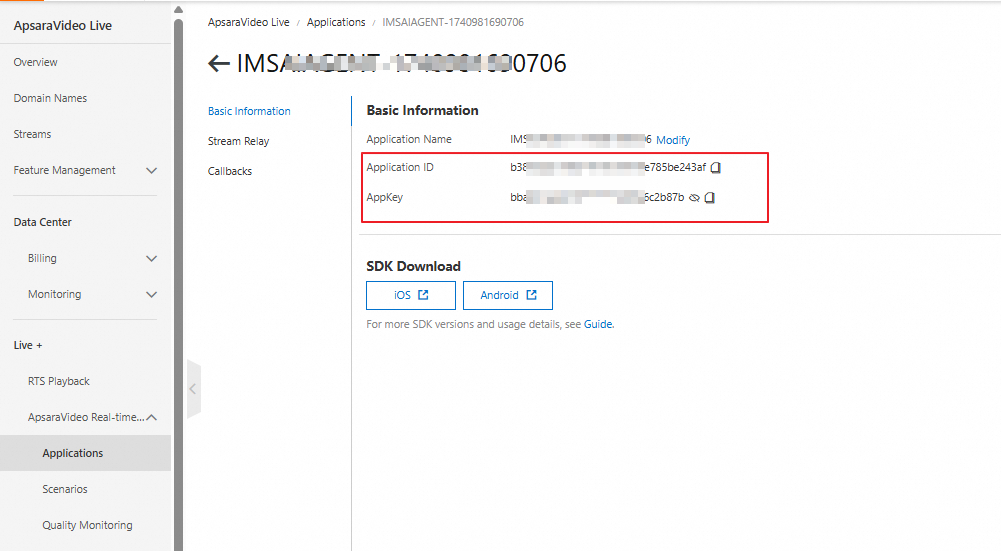
AccessKey pair: To get the AccessKey ID and AccessKey secret, see Create an AccessKey pair.