Function Compute provides two instance usage modes: on-demand mode and provisioned mode. You can configure auto scaling rules based on the limits for the total number of instances and the instance scaling speed. In provisioned mode, you can use scheduled and metric-based scaling to optimize provisioned instance utilization.
Instance scaling limits
Scaling limits for on-demand instances
When processing function invocation requests, Function Compute prioritizes using available instances. If all current instances are at full capacity, Function Compute creates new instances to handle requests. As the number of invocations increases, Function Compute continues to create new instances until there are enough to handle the requests or the configured instance limit is reached. The following limits apply to instance scaling.
Total number of on-demand instances: A single Alibaba Cloud account (main account) is limited to a total of 100 instances per region by default. This total includes both on-demand and provisioned instances. The actual quota is specified in Quota Center.
The scaling speed of running instances is limited by burstable instances and the instance growth rate. For the limits in different regions, see Regional scaling speed limits.
Burstable instances: The number of instances that can be created immediately. The default limit ranges from 100 to 300.
Instance growth rate: The rate at which new instances are added per minute after the burstable instance limit is reached. The default limit ranges from 100 to 300.
When the total number of instances or the instance scaling speed exceeds the limit, Function Compute will return a throttling error (HTTP Status is 429). The following figure shows the throttling behavior of Function Compute in a scenario where the number of invocations rapidly increases.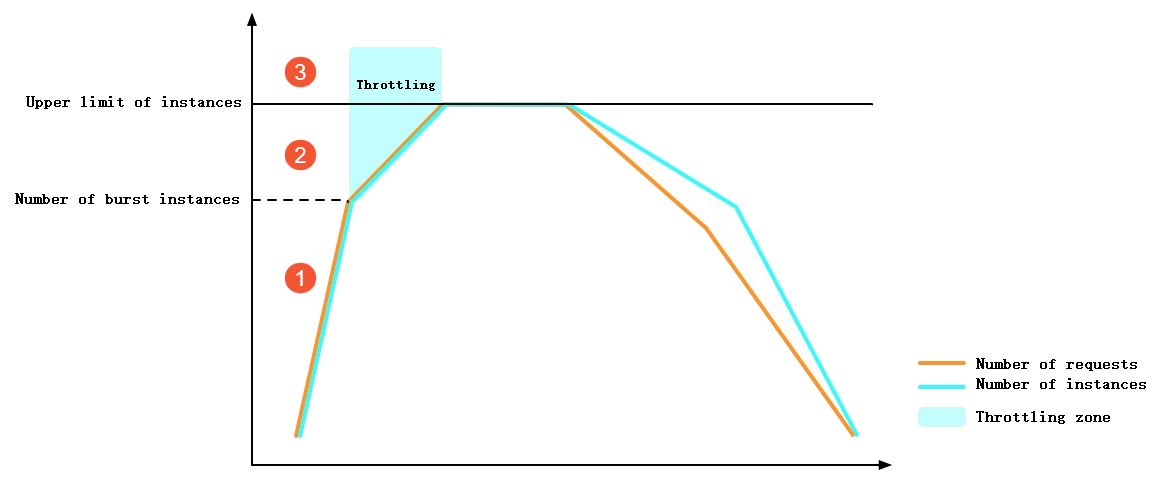
① In the figure: Before the burstable instance limit is reached, Function Compute immediately creates instances. This process involves cold starts but no throttling errors.
② In the figure: After the burstable instance limit is reached, instance growth is constrained by the rate limit, causing some requests to receive throttling errors.
③ In the figure: After the total instance count exceeds the limit, some requests receive throttling errors.
By default, the preceding scaling limits are shared by all functions under an Alibaba Cloud account in the same region. To limit the number of instances for a specific function, you can configure function-level scaling control for on-demand instances. After configuration, if the total number of running instances for this function exceeds the limit, Function Compute returns a throttling error.
Scaling limits for provisioned instances
A large, sudden spike in invocations can cause throttling and request failures when creating many instances. The cold starts of these instances also increase request latency. To avoid these issues, you can use provisioned instances in Function Compute, which prepares function instances in advance. The upper limits on the number and scaling speed of provisioned instances are separate and not affected by the scaling limits mentioned above.
Total number of instances: By default, a single Alibaba Cloud account (main account) is limited to a total of 100 instances per region. This total includes both on-demand and provisioned instances. For the actual limit, refer to Quota Center.
Provisioned instance scaling speed: The default is 100 to 300 instances per minute, and the limits vary by region. For more information, see Scaling speed limits in each region. The figure below shows the throttling behavior of Function Compute with provisioned instances under the same load scenario as above.
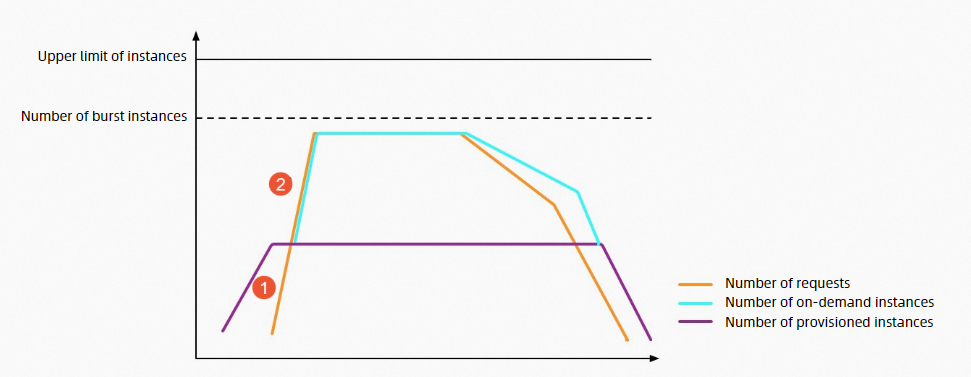
① In the figure: Before the provisioned instances are fully utilized, requests are executed immediately. This process has no cold starts or throttling errors.
In part ② of the figure: After provisioned instances are fully utilized and before on-demand instances reach the burstable instance limit, Function Compute immediately creates instances. This process involves cold starts, but no throttling errors.
Regional scaling speed limits
Region | Burstable instances | Instance growth rate |
China (Hangzhou), China (Shanghai), China (Beijing), China (Zhangjiakou), China (Shenzhen) | 300 | 300/minute |
Other regions | 100 | 100/minute |
In the same region, the scaling speed limits are the same for both provisioned mode and on-demand mode.
By default, a single Alibaba Cloud account (main account) is limited to a total of 100 instances per region. The actual quota is specified in Quota Center. If you need to increase this quota, submit a request in Quota Center.
The scaling speed of GPU instances is slower than that of CPU instances. We recommend using GPU instances with provisioned mode.
Auto scaling rules
Create an auto scaling rule
Log on to the Function Compute console. In the left-side navigation pane, click Services & Functions.
In the top navigation bar, select a region. On the Services page, click the desired service.
- On the Functions page, click the function that you want to modify.
On the Function Details page, click the Auto Scaling tab and then click Create Rule.
On the Create Auto Scaling Rule page, configure the relevant parameters and click Create.
Configure scaling for on-demand instances
Set Minimum Number of Instances to 0 and Maximum Number of Instances to the maximum number of on-demand instances. If you do not configure Maximum Number of Instances, the limit defaults to the maximum instance limit for your account in the current region.
NoteIdle Mode, Scheduled Setting Modification, and Metric-based Setting Modification take effect only in provisioned mode.
Configure scaling for provisioned instances
Parameter
Description
Basic Settings
Version or Alias
Select the version or alias for which you want to create provisioned instances.
NoteProvisioned instances can be created only for the LATEST version.
Minimum Number of Instances
Enter the number of provisioned instances. Minimum Number of Instances = Number of provisioned instances.
NoteBy limiting the minimum number of function-level instances, you can ensure quick responses to invocations, reduce cold starts, and better serve latency-sensitive online businesses.
Idle mode
Select whether to enable or disable idle mode. It is disabled by default. The following describes the options:
If you enable this feature, vCPUs are allocated to provisioned instances only while they are processing requests. At other times, the instance's CPU is frozen.
When idle mode is enabled, Function Compute prioritizes routing requests to the same instance based on the function's instance concurrency until that instance is at full capacity. For example, assume a function has an instance concurrency of 50 and you have 10 idle provisioned instances. If Function Compute receives 40 requests simultaneously, all 40 requests are routed to a single instance, which then transitions from idle to active.
If you disable this feature, provisioned instances are allocated vCPUs regardless of whether they are processing requests.
Maximum Number of Instances
Enter the maximum number of instances. Maximum Number of Instances = Number of provisioned instances + Maximum number of on-demand instances.
NoteBy limiting the maximum number of function-level instances, you can prevent a single function from occupying too many instances due to excessive invocations. This protects backend resources and avoids unexpected costs.
If you leave this parameter empty, the limit defaults to the maximum instance limit for your account in the current region.
(Optional) Scheduled Setting Modification: You can create scheduled scaling rules to configure provisioned instances more flexibly. It sets the number of provisioned instances to a specified value at a designated time to better align with your business's concurrency demands. For more information about how it works and for configuration examples, see Scheduled scaling.
Policy Name
Enter a custom policy name.
Minimum Number of Instances
Set the number of provisioned instances as needed.
Schedule expression (UTC)
The schedule information. Example: cron(0 0 20 * * *). For more information, see Parameter description.
Effective time (UTC)
The period during which the scheduled auto scaling rule is active.
(Optional) Metric-based Setting Modification: Scales provisioned resources once per minute based on the utilization of various instance metrics or the provisioned instance concurrency utilization. For more information about how it works and for configuration examples, see Metric-based scaling.
Policy Name
Enter a custom policy name.
Minimum range of instances
Set the allowable range (minimum and maximum) for the number of provisioned instances adjusted by this policy.
Utilization type
This parameter is valid only when the function's instance type is a GPU instance. Select the metric type for the utilization-based auto scaling policy. For more information about auto scaling policies for GPU instances, see Auto scaling policies for provisioned GPU mode.
Concurrency Usage Threshold
Set the target utilization threshold. When utilization falls below this threshold, a scale-in occurs. When utilization exceeds this threshold, a scale-out occurs.
Effective time (UTC)
The period during which the metric-based auto scaling rule is active.
After creation, you can view the provisioned mode instance configuration for the target function in the rules list.
Modify or delete an auto scaling rule
On the Auto Scaling page, you can view the list of created rules. You can find the target rule in the list and click Modify or Delete in the Actions column.
To delete provisioned instances, set Minimum Number of Instances to 0.
Auto scaling methods for provisioned mode
To avoid the low utilization that can result from a fixed number of provisioned instances, you can use scheduled and metric-based scaling.
Scheduled scaling
Definition: Scheduled scaling sets the number of provisioned instances to a specific value at a scheduled time, which helps align capacity with predictable concurrency demands.
Use cases: This method is suitable for functions with obvious cyclical patterns or predictable traffic peaks. When the function invocation concurrency is greater than the scheduled provisioned value, the excess load is handled by on-demand mode instances.
Configuration example: The following figure shows a configuration with two scheduled actions. Before the function invocation traffic arrives, the first scheduled configuration scales out the provisioned instances to a larger value. After the traffic decreases, the second scheduled configuration scales in the provisioned instances to a smaller value.
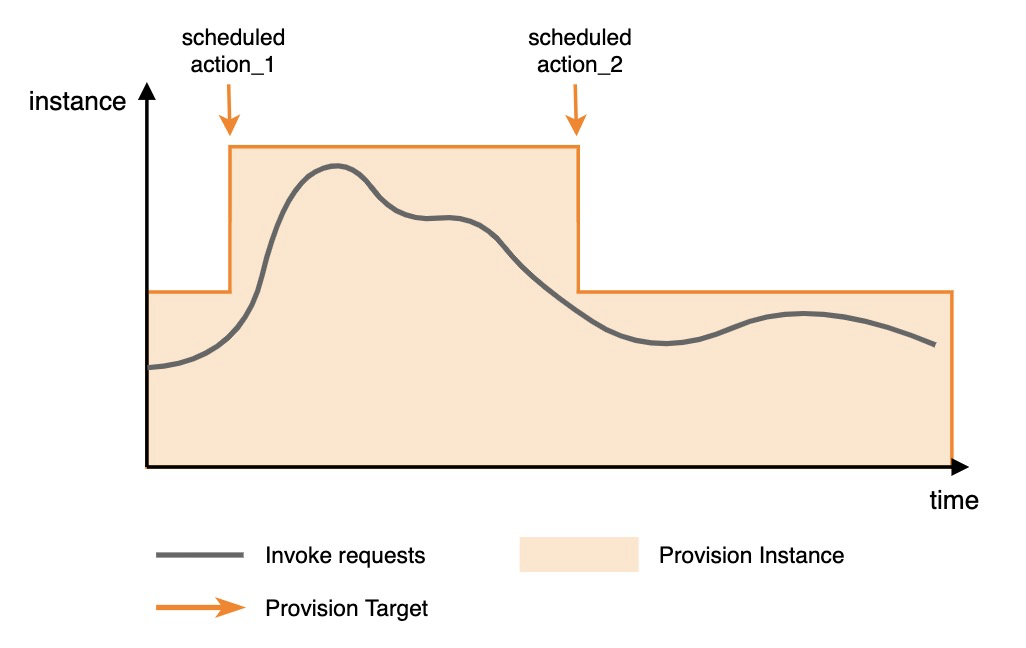
The following is a parameter example. Scheduled scaling is configured for function_1 of service_1. The configuration is effective from 2022-11-01 10:00:00 to 2022-11-30 10:00:00. At 20:00 every day, the number of provisioned instances is scaled out to 50, and at 22:00, it is scaled in to 10. The following information can be used as a reference for the request parameters when configuring scheduled scaling by using the PutProvisionConfig API.
{
"ServiceName": "service_1",
"FunctionName": "function_1",
"Qualifier": "alias_1",
"ScheduledActions": [
{
"Name": "action_1",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"TargetValue": 50,
"ScheduleExpression": "cron(0 0 20 * * *)"
},
{
"Name": "action_2",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"TargetValue": 10,
"ScheduleExpression": "cron(0 0 22 * * *)"
}
]
}The parameters are described as follows.
Parameter | Description |
Name | The name of the scheduled task. |
StartTime | The time when the configuration takes effect, in UTC format. |
EndTime | The time when the configuration expires, in UTC format. |
TargetValue | The target number of provisioned instances. |
ScheduleExpression | The schedule information. Two formats are supported:
|
The fields of a cron expression are Seconds, Minutes, Hours, Day-of-month, Month, and Day-of-week. They are described as follows.
Table 1. Field description
Field | Allowed values | Allowed special characters |
Seconds | 0-59 | None |
Minutes | 0-59 | , - * / |
Hours | 0-23 | , - * / |
Day-of-month | 1-31 | , - * ? / |
Month | 1-12 or JAN-DEC | , - * / |
Day-of-week | 1-7 or MON-SUN | , - * ? |
Table 2. Special character description
Character | Definition | Example |
* | Indicates any or every. | In the |
, | Indicates a list of values. | In the |
- | Indicates a range. | In the |
? | Indicates an uncertain value. | Used with other specified values. For example, if you specify a specific date but do not care which day of the week it is, you can use ? in the |
/ | Indicates an increment for a value. n/m indicates an increment of m starting from n. | In the |
Metric-based scaling
Definition: Dynamically scales function instances in provisioned mode by tracking monitoring metrics.
Use case: The Function Compute system periodically collects metrics on the concurrency or resource utilization of provisioned instances. The system uses these metrics, along with your configured scale-out and scale-in trigger values, to control the scaling of function instances in provisioned mode. This process ensures that the number of provisioned instances closely aligns with your actual resource usage.
How it works: Metric-based tracking auto scaling adjusts provisioned resources once per minute based on metric conditions.
When the metric exceeds the scale-out threshold, an aggressive policy begins to scale out the number of provisioned instances, quickly expanding to the target value.
When the metric falls below the scale-in threshold, a conservative policy begins to scale in the number of provisioned instances, gradually approaching the scale-in target.
If you have set maximum and minimum scaling values in the system, the number of provisioned function instances will scale between these values. Scaling out stops when the maximum value is reached, and scaling in stops when the minimum value is reached.
Configuration example: The following figure shows an example of scaling based on the provisioned instance utilization metric.
As traffic increases, the scale-out threshold is triggered, and the provisioned function instances begin to scale out. When the configured maximum value is reached, scaling out stops, and any excess requests are allocated to on-demand function instances.
As traffic decreases, the scale-in threshold is triggered, and the provisioned function instances begin to scale in.
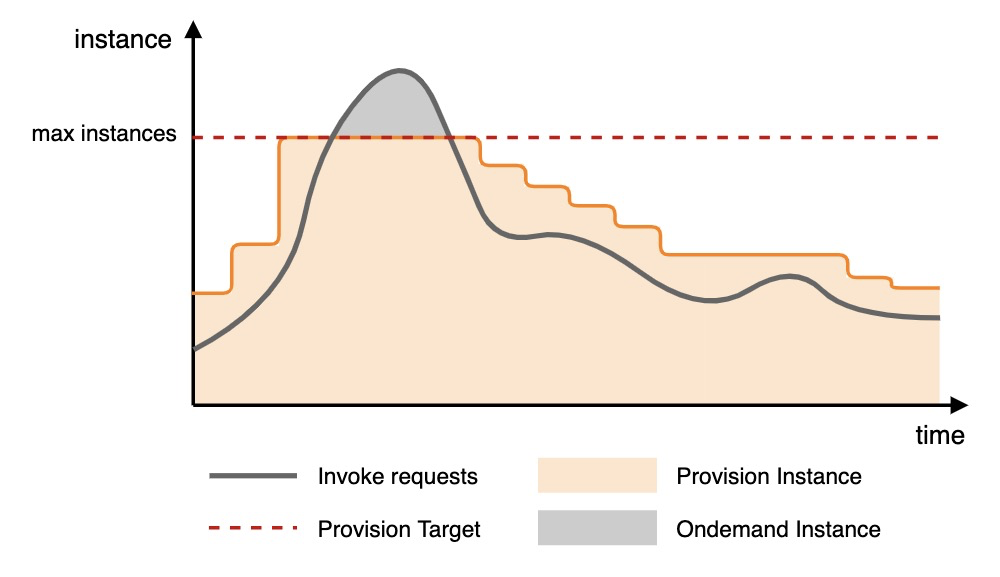
The concurrency utilization of provisioned function instances is based only on the concurrency of provisioned instances and does not include data from on-demand mode.
Metric calculation: The ratio of the number of concurrent requests being handled by provisioned function instances to the maximum number of concurrent requests that all provisioned function instances can handle. The value ranges from 0 to 1.
For different instance concurrency settings, the calculation logic for the maximum concurrent request capacity of provisioned instances is as follows. For more information about instance concurrency, see Configure instance concurrency.
Single request per instance: Maximum concurrent requests = Number of provisioned instances
Multiple requests per instance: Maximum concurrent requests = Number of provisioned instances × instance concurrency
Scale-out and scale-in target values
The target values are determined by the current metric value, the metric tracking value, the current number of provisioned function instances, and the scale-in coefficient.
Scaling calculation principle: During a scale-in, a scale-in coefficient is used to achieve a relatively conservative scale-in process. The scale-in coefficient ranges from 0 (exclusive) to 1 (inclusive). The scale-in coefficient is a system parameter used to slow down the scale-in speed and prevent it from being too fast; you do not need to set it. The final scaling target value is obtained by rounding up the calculation result. The calculation logic is as follows.
Scale-out target = Current number of provisioned function instances × (Current metric value / Metric tracking value)
Number of instances to remove = Current number of provisioned function instances × Scale-in coefficient × (1 - Current metric value / Metric tracking value)
Scale-out target calculation example: If the current metric value is 80%, the metric target value is 40%, and the current number of provisioned function instances is 100, the calculation is 100 × (80% / 40%) = 200. The number of provisioned function instances will be scaled out to 200 to ensure the metric target value remains around 40% after scaling.
The following is a parameter example. Metric-based tracking auto scaling is configured for function_1 of service_1. The configuration is effective from 2022-11-01 10:00:00 to 2022-11-30 10:00:00. It tracks the ProvisionedConcurrencyUtilization metric of provisioned function instances. The concurrency utilization tracking value is 60%. When the utilization exceeds 60%, a scale-out event occurs, with a maximum capacity of 100. When the utilization falls below 60%, a scale-in event occurs, with a minimum capacity of 10. The following information can be used as a reference for the request parameters when configuring metric-based scaling by using the PutProvisionConfig API.
{
"ServiceName": "service_1",
"FunctionName": "function_1",
"Qualifier": "alias_1",
"TargetTrackingPolicies": [
{
"Name": "action_1",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"MetricType": "ProvisionedConcurrencyUtilization",
"MetricTarget": 0.6,
"MinCapacity": 10,
"MaxCapacity": 100,
}
]
}The parameters are described as follows.
Parameter | Description |
Name | The name of the metric-based task. |
StartTime | The time when the configuration takes effect, in UTC format. |
EndTime | The time when the configuration expires, in UTC format. |
MetricType | The metric to track. Valid value: ProvisionedConcurrencyUtilization. |
MetricTarget | The target value for the metric. |
MinCapacity | The minimum number of instances for scaling. |
MaxCapacity | The maximum number of instances for scaling. |
Related documents
For basic concepts and billing methods of on-demand and provisioned modes: Instance types and usage modes.
To view the number of provisioned instances in use after you configure auto scaling, check the FunctionProvisionedCurrentInstance metric: Function-level metrics.