Job errors FAQ
Common job runtime errors and solutions in Realtime Compute for Apache Flink.
-
What do I do if data in tasks of a job is not consumed after the job is run?
-
Why is data output suspended on the LocalGroupAggregate operator?
-
What do I do if Kafka partition idleness delays window output?
-
What do I do when the "INFO: org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss" message appears?
-
What do I do if the error message "akka.pattern.AskTimeoutException" appears?
-
What do I do if the error message "Task did not exit gracefully within 180 + seconds." appears?
-
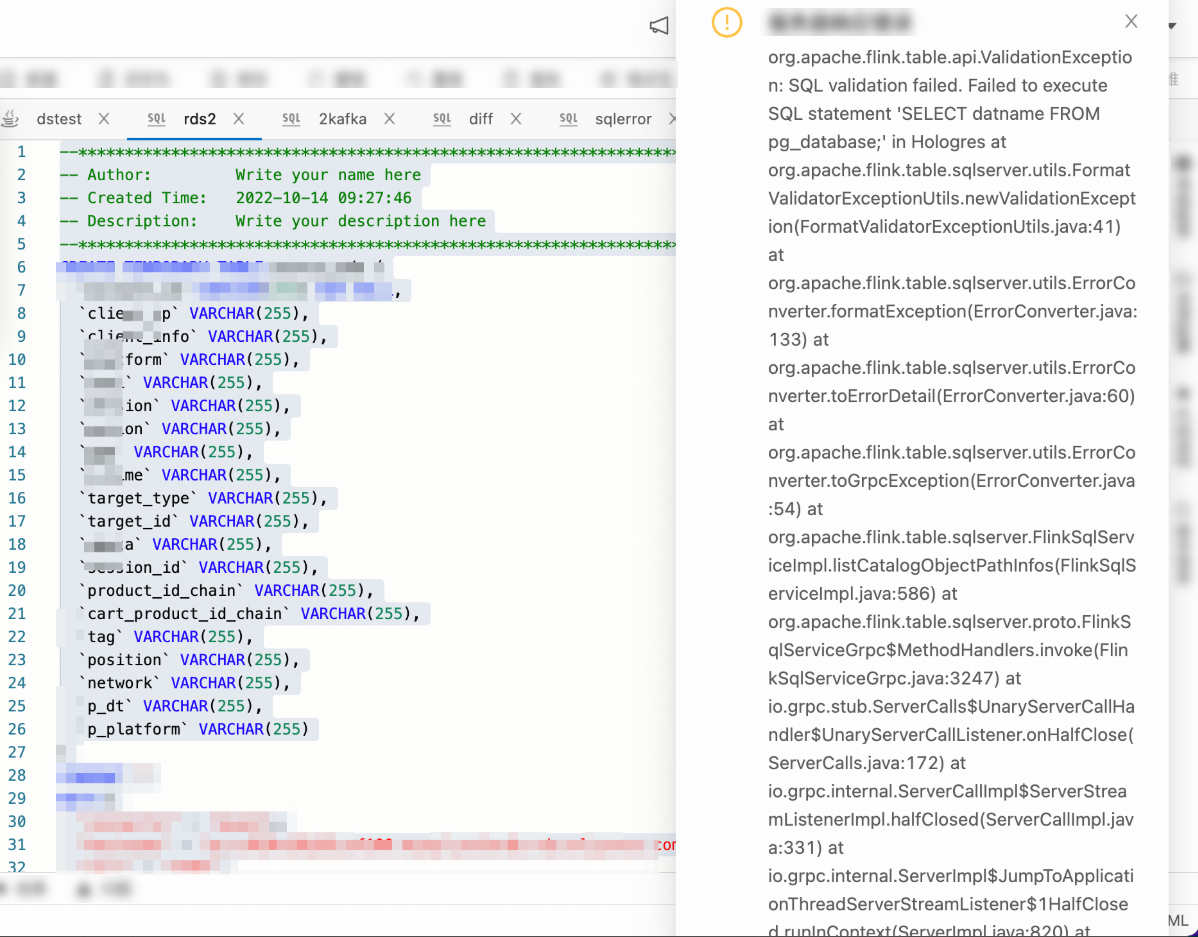
How can I fix the error message "The GRPC call timed out in sqlserver"?
-
What do I do if the error message "Caused by: java.lang.NoSuchMethodError" appears?
What do I do if a job cannot be started?
-
Problem description
When you click Start in the Actions column, the job status changes from STARTING to FAILED.
-
Solutions
-
Check the Events tab: Navigate to the Events tab on the job details page. Locate the failure event that occurred when the job failed to start and review its details to identify the root cause.
-
Review startup logs: Go to the Logs tab and select the Startup Logs sub-tab. Check the logs for specific error messages that explain why the job failed to start.
-
Inspect JobManager/TaskManager logs: If the JobManager appears to start successfully but the job still fails, check the detailed logs for the JobManager and TaskManagers. These can be found on the Job Manager or Running Task Managers sub-tabs within the Logs tab.
-
-
Common errors and solutions
Problem description
Cause
Solution
ERROR:exceeded quota: resourcequotaInsufficient resources in the current Resource Queue.
Increase Resource Queue capacity or reduce job resource requirements.
ERROR:the vswitch ip is not enoughInsufficient IP addresses in the namespace for the required TaskManagers.
Reduce job parallelism, adjust slot configuration, or modify the vSwitch settings.
ERROR: pooler: ***: authentication failedInvalid AccessKey pair or insufficient permissions.
Verify the AccessKey pair is valid and belongs to an account with permissions to execute and manage jobs.
How do I fix the database connection error?
-
Problem description
-
Cause
The registered catalog is invalid or unreachable.
-
Solution
Go to the Catalogs page, delete any grayed-out catalogs, and re-register them.
What do I do if data in tasks of a job is not consumed after the job is run?
-
Check network connectivity
If data is not generated or consumed in upstream and downstream storage, check the Startup Logs tab for error messages. If you see timeout errors, troubleshoot network connectivity between storage systems.
-
Check task execution status
On the Configuration tab, verify whether data is being read from the source and written to the sink to pinpoint where the error occurs.

-
Check operator output
Add a print sink table to each operator to troubleshoot the issue.
What do I do if a job restarts unexpectedly?
To troubleshoot the error, check the Logs tab.
-
View exception information.
On the JM Exceptions sub-tab, review the reported error and identify the root cause.
-
View JobManager and TaskManager logs for the job.

-
View failed TaskManager logs for the job.
Some exceptions may cause TaskManagers to fail, resulting in incomplete logs. View the last invalid TaskManager logs to troubleshoot the issue.

-
View historical job instance logs.
Review historical job instance logs to identify the cause of the failure.

Why is data output suspended on the LocalGroupAggregate operator?
-
Code
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts as PROCTIME(), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a BIGINT, b BIGINT ) WITH ( 'connector'='print' ); CREATE TEMPORARY VIEW window_view AS SELECT window_start, window_end, a, sum(b) as b_sum FROM TABLE(TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '2' SECONDS)) GROUP BY window_start, window_end, a; INSERT INTO sink SELECT count(distinct a), b_sum FROM window_view GROUP BY b_sum; -
Problem description
Data output is suspended on the LocalGroupAggregate operator for an extended period, and the MiniBatchAssigner operator is missing from the job topology.

-
Cause
The job includes both WindowAggregate and GroupAggregate operators. The WindowAggregate operator uses proctime as the time column. Managed memory is used to cache data in miniBatch processing mode if the
table.exec.mini-batch.sizeparameter is not configured or is set to a negative value.The MiniBatchAssigner operator fails to generate and cannot send watermark messages to compute operators to trigger final calculation and data output. Final calculation and data output are triggered only when one of the following conditions is met: managed memory is full, a CHECKPOINT command is received and checkpointing has not been performed, or the job is canceled. For more information, see table.exec.mini-batch.size. If the checkpoint interval is set to an excessively large value, the LocalGroupAggregate operator does not trigger data output for an extended period.
-
Solutions
-
Decrease the checkpoint interval so that the LocalGroupAggregate operator triggers data output before checkpointing. Tuning Checkpointing.
-
Use heap memory to cache data. Output triggers automatically when cached data reaches the
table.exec.mini-batch.sizevalue. Set this parameter to a positive value N. How do I configure custom runtime parameters for a job?
-

What do I do if Kafka partition idleness delays window output?
If the upstream Kafka connector has multiple partitions but only some receive data, idle partitions prevent the watermark from advancing. Windows cannot close promptly, delaying real-time output.
Configure a timeout to mark idle partitions. Idle partitions are excluded from watermark calculations until they receive data again. Configuration.
Add the following configuration to the Other Configuration field in the Parameters section on the Configuration tab. How do I configure custom runtime parameters for a job?
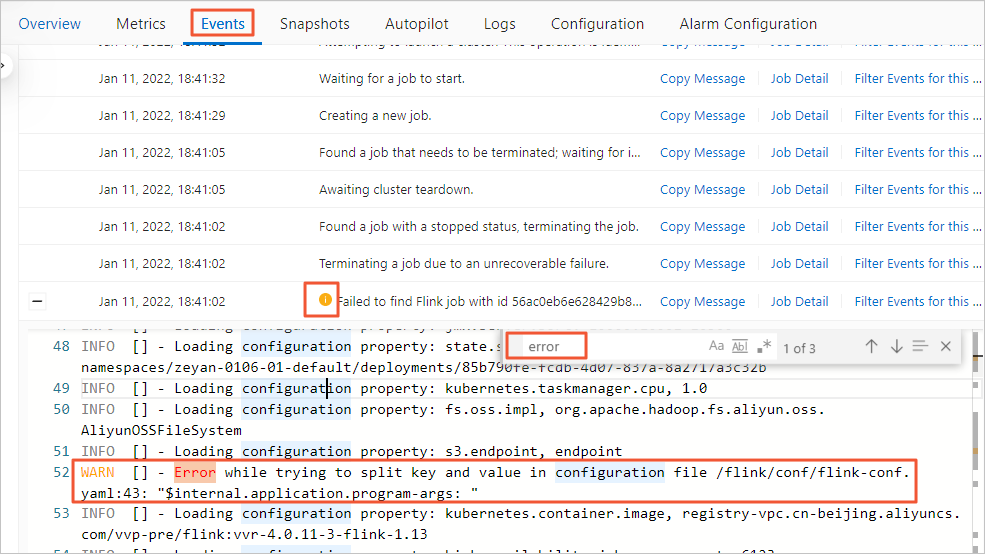
table.exec.source.idle-timeout: 1sHow do I locate the error if the JobManager is not running?
The Flink UI page does not appear because the JobManager is not running. To identify the cause, perform the following steps:
-
In the left navigation menu of the Development Console, choose . On the Deployments page, find the target job deployment and click its name.
-
Click the Events tab.
-
Search for errors using your OS keyboard shortcut:
-
Windows: Ctrl+F
-
macOS: Command+F
-
What do I do when the "INFO: org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss" message appears?
-
Problem description
-
Cause
Data is stored in an OSS bucket. When OSS creates a directory, it checks whether the directory exists. If not, this INFO message is printed. This does not affect your jobs.
-
Solution
Add the following logger configuration to your log template to suppress this message:
<Logger level="ERROR" name="org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss"/>. the log configuration topic.

What do I do if the error message "akka.pattern.AskTimeoutException" appears?
-
Causes
-
Cause 1: Frequent garbage collection (GC). Insufficient JobManager or TaskManager memory causes frequent GC, leading to heartbeat and RPC timeouts between the JobManager and TaskManagers.
-
Cause 2: High volume of RPC requests. Too many RPC requests overwhelm the JobManager, causing an RPC backlog and heartbeat and RPC timeouts.
-
Cause 3: Timeout values are too small. The timeout settings are too low. When Realtime Compute for Apache Flink retries connections to a third-party service, the timeout expires before the failure is reported.
-
-
Solutions
-
Solution 1: Check GC frequency and duration from job memory usage and GC logs. If GC is frequent or long, increase JobManager and TaskManager memory.
-
Solution 2: To handle a high volume of RPC requests, increase the number of CPU cores and the memory size of the JobManager, and set the
akka.ask.timeoutandheartbeat.timeoutparameters to larger values.Important-
Adjust
akka.ask.timeoutandheartbeat.timeoutonly when a large number of RPC requests exist. For jobs with few RPC requests, smaller values typically do not cause this issue. -
Set values based on your business requirements. Excessively large values increase recovery time when a TaskManager unexpectedly exits.
-
-
Solution 3: To handle connection failures of third-party services, increase the following parameters so connection failures are reported promptly:
-
client.timeout: Default value: 60. Recommended value: 600. Unit: seconds. -
akka.ask.timeout: Default value: 10. Recommended value: 600 Unit: seconds. -
client.heartbeat.timeout: Default value: 180000. Recommended value: 600000. Unit: seconds.NoteTo prevent errors, do not include the unit in the value.
-
heartbeat.timeout: Default value: 50000. Recommended value: 600000. Unit: milliseconds.NoteTo prevent errors, do not include the unit in the value.
For example, if the error message
"Caused by: java.sql.SQLTransientConnectionException: connection-pool-xxx.mysql.rds.aliyuncs.com:3306 - Connection is not available, request timed out after 30000ms"appears, the MySQL connection pool is full. In this case, you must increase the value of theconnection.pool.sizeparameter that is described in the WITH parameters of MySQL. Default value: 20.NoteDetermine minimum values from the timeout error message. The value shown in the error indicates the current setting. For example, "60000 ms" in
"pattern.AskTimeoutException: Ask timed out on [Actor[akka://flink/user/rpc/dispatcher_1#1064915964]] after [60000 ms]."is theclient.timeoutvalue. -
-
What do I do if the error message "Task did not exit gracefully within 180 + seconds." appears?
-
Problem description
Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852861506+08:00 stdout F org.apache.flink.util.FlinkRuntimeException: Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852865065+08:00 stdout F at org.apache.flink.runtime.taskmanager.Task$TaskCancelerWatchDog.run(Task.java:1709) [flink-dist_2.11-1.12-vvr-3.0.4-SNAPSHOT.jar:1.12-vvr-3.0.4-SNAPSHOT] 2022-04-22T17:32:25.852867996+08:00 stdout F at java.lang.Thread.run(Thread.java:834) [?:1.8.0_102] log_level:ERROR -
Cause
This error does not indicate the root cause. It means task exit was stuck during failover or cancellation for longer than the default
task.cancellation.timeoutof 180 seconds. Realtime Compute for Apache Flink treats the task as unrecoverable, stops the affected TaskManager, and allows failover or cancellation to continue.This is often caused by user-defined functions (UDFs). For example, if the close method in a UDF blocks or does not return, the task cannot exit.
-
Solution
For debugging, set
task.cancellation.timeoutto 0. How do I configure custom runtime parameters for a job? When set to 0, a blocked task waits indefinitely to exit without triggering a timeout. If failover triggers again or a task remains stuck after restart, locate the task in the CANCELLING state, inspect its stack trace, and fix the root cause.ImportantThe
task.cancellation.timeoutparameter is for debugging only. Do not set it to 0 in production. Use an appropriate timeout and fix the underlying UDF or business logic issue.
What do I do when the error message "Can not retract a non-existent record. This should never happen." appears?
-
Problem description
java.lang.RuntimeException: Can not retract a non-existent record. This should never happen. at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:196) at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:55) at org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:135) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:106) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:424) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:685) at org.apache.flink.streaming.runtime.tasks.StreamTask.executeInvoke(StreamTask.java:640) at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:651) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:624) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:799) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:586) at java.lang.Thread.run(Thread.java:877) -
Causes and solutions
Scenario
Cause
Solution
Scenario 1
The issue is caused by the
now()function in the code.The TopN algorithm does not allow a non-deterministic field to be used in the ORDER BY or PARTITION BY clause. If a non-deterministic field is used, the values returned by the
now()function are different for each record, and the previous value cannot be found in the state.Use a deterministic field in the ORDER BY or PARTITION BY clause.
Scenario 2
The
table.exec.state.ttlparameter is set to an excessively small value. As a result, state entries expire and are deleted, and the required key state cannot be found in the state.Increase the
table.exec.state.ttlvalue. How do I configure custom runtime parameters for a job?
How can I fix the error message "The GRPC call timed out in sqlserver"?
-
Problem description
org.apache.flink.table.sqlserver.utils.ExecutionTimeoutException: The GRPC call timed out in sqlserver, please check the thread stacktrace for root cause: Thread name: sqlserver-operation-pool-thread-4, thread state: TIMED_WAITING, thread stacktrace: at java.lang.Thread.sleep0(Native Method) at java.lang.Thread.sleep(Thread.java:360) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.processWaitTimeAndRetryInfo(RetryInvocationHandler.java:130) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:107) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy195.getFileInfo(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1661) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1577) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1574) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1589) at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1683) at org.apache.flink.connectors.hive.HiveSourceFileEnumerator.getNumFiles(HiveSourceFileEnumerator.java:118) at org.apache.flink.connectors.hive.HiveTableSource.lambda$getDataStream$0(HiveTableSource.java:209) at org.apache.flink.connectors.hive.HiveTableSource$$Lambda$972/1139330351.get(Unknown Source) at org.apache.flink.connectors.hive.HiveParallelismInference.logRunningTime(HiveParallelismInference.java:118) at org.apache.flink.connectors.hive.HiveParallelismInference.infer(HiveParallelismInference.java:100) at org.apache.flink.connectors.hive.HiveTableSource.getDataStream(HiveTableSource.java:207) at org.apache.flink.connectors.hive.HiveTableSource$1.produceDataStream(HiveTableSource.java:123) at org.apache.flink.table.planner.plan.nodes.exec.common.CommonExecTableSourceScan.translateToPlanInternal(CommonExecTableSourceScan.java:127) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecExchange.translateToPlanInternal(StreamExecExchange.java:87) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecGroupAggregate.translateToPlanInternal(StreamExecGroupAggregate.java:148) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.java:108) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:74) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:73) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at org.apache.flink.table.planner.delegation.StreamPlanner.translateToPlan(StreamPlanner.scala:73) at org.apache.flink.table.planner.delegation.StreamExecutor.createStreamGraph(StreamExecutor.java:52) at org.apache.flink.table.planner.delegation.PlannerBase.createStreamGraph(PlannerBase.scala:610) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraphInternal(StreamPlanner.scala:166) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraph(StreamPlanner.scala:159) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:304) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:288) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$validate$22(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$394/1626790418.run(Unknown Source) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapClassLoader(DelegateOperationExecutor.java:250) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$wrapExecutor$26(DelegateOperationExecutor.java:275) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$395/1157752141.run(Unknown Source) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:281) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:786) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522) at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172) at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331) at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820) at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37) at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) Caused by: java.util.concurrent.TimeoutException at java.util.concurrent.FutureTask.get(FutureTask.java:205) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:277) ... 11 more -
Cause
Complex SQL in the draft causes RPC execution timeout.
-
Solution
Add the following code to the Other Configuration field in the Parameters section of the Configuration tab to increase the RPC timeout. The default is 120 seconds. For more information, see Configure custom running parameters
flink.sqlserver.rpc.execution.timeout: 600s
How can I resolve the error message "RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051"?
-
Problem description
Caused by: io.grpc.StatusRuntimeException: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051 at io.grpc.stub.ClientCalls.toStatusRuntimeException(ClientCalls.java:244) at io.grpc.stub.ClientCalls.getUnchecked(ClientCalls.java:225) at io.grpc.stub.ClientCalls.blockingUnaryCall(ClientCalls.java:142) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$FlinkSqlServiceBlockingStub.generateJobGraph(FlinkSqlServiceGrpc.java:2478) at org.apache.flink.table.sqlserver.api.client.FlinkSqlServerProtoClientImpl.generateJobGraph(FlinkSqlServerProtoClientImpl.java:456) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.lambda$generateJobGraph$25(ErrorHandlingProtoClient.java:251) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.invokeRequest(ErrorHandlingProtoClient.java:335) ... 6 more Cause: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051) -
Cause
The JobGraph is too large due to complex draft logic. This causes verification errors or prevents the draft job from starting or being canceled.
-
Solution
Add the following code to the Other Configuration field in the Parameters section of the Configuration tab. How do I configure custom runtime parameters for a job?
table.exec.operator-name.max-length: 1000
What do I do if the error message "Caused by: java.lang.NoSuchMethodError" appears?
-
Problem description
Error message: Caused by: java.lang.NoSuchMethodError: org.apache.flink.table.planner.plan.metadata.FlinkRelMetadataQuery.getUpsertKeysInKeyGroupRange(Lorg/apache/calcite/rel/RelNode;[I)Ljava/util/Set; -
Cause
If you call an Apache Flink API and Realtime Compute for Apache Flink provides an optimized version, an exception such as a package conflict may occur.
-
Solution
Restrict your method calls to those explicitly marked with @Public or @PublicEvolving in the source code of Apache Flink. Realtime Compute for Apache Flink ensures compatibility with those methods.
What do I do if the error message "java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory" appears?
-
Problem description
Causedby:java.lang.ClassCastException:org.codehaus.janino.CompilerFactorycannotbecasttoorg.codehaus.commons.compiler.ICompilerFactory atorg.codehaus.commons.compiler.CompilerFactoryFactory.getCompilerFactory(CompilerFactoryFactory.java:129) atorg.codehaus.commons.compiler.CompilerFactoryFactory.getDefaultCompilerFactory(CompilerFactoryFactory.java:79) atorg.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:426) ...66more -
Cause
-
The JAR package contains a Janino dependency that causes a conflict.
-
Specific JAR packages that start with
Flink-such asflink-table-plannerandflink-table-runtimeare added to the JAR package of the UDF or connector.
-
-
Solutions
-
Check whether the JAR package contains
org.codehaus.janino.CompilerFactory. Class conflicts may occur because the class loading sequence on different machines is different. To resolve this issue, perform the following steps:-
In the left navigation menu of the Development Console, choose . On the Deployments page, find the target job and click its name.
-
On the Configuration tab of the job details page, click Edit in the upper-right corner of the Parameters section.
-
Add the following code to the Other Configuration field and click Save.
classloader.parent-first-patterns.additional: org.codehaus.janinoReplace the value of the
classloader.parent-first-patterns.additionalparameter with the conflict class.
-
-
Specify
<scope>provided</scope>for Apache Flink dependencies, such as non-connector dependencies whose names start withflink-in theorg.apache.flinkgroup.
-