You can configure and enable Kerberos authentication in a Serverless Spark workspace. After you enable this feature, clients must use Kerberos authentication to submit Spark tasks in the workspace. This improves task execution security.
Prerequisites
You have created a principal, exported a Kerberos keytab file, and uploaded the file to Alibaba Cloud Object Storage Service (OSS).
If you use an EMR on ECS cluster, for more information, see Basic Kerberos usage.
You have created a Serverless Spark workspace. For more information, see Manage workspaces.
Limitations
A workspace can be bound to only one Kerberos cluster.
Kerberos authentication is supported only for Spark batch jobs.
Procedure
Step 1: Prepare the network
Before you configure Kerberos authentication, you must ensure network connectivity between Serverless Spark and your Virtual Private Cloud (VPC). For more information, see Establish network connectivity between EMR Serverless Spark and other VPCs.
When you add a security group rule, you must open the UDP port used by the Kerberos service. This is typically port 88.
Step 2: Configure Kerberos authentication
Go to the Kerberos authentication page.
Log on to the EMR console.
In the navigation pane on the left, choose .
On the Spark page, click the name of the target workspace.
On the EMR Serverless Spark page, click in the navigation pane on the left.
Click Bind Kerberos.
On the Bind Kerberos page, configure the parameters and click OK.
Parameter
Description
Kerberos Name
Enter a custom name.
Network Connection
Select the network connection that you created.
Kerberos krb5.conf
Enter the content of the
krb5.conffile.The
krb5.conffile is typically located in the/etc/krb5.confpath on the server. Obtain the file content based on your environment:If you use the Kerberos service of an EMR DataLake cluster, obtain the content as follows:
Log on to the master node of the EMR cluster. For more information, see Log on to a cluster.
Run the following command to view and manually copy the content of
/etc/krb5.conf.cat /etc/krb5.confCopy the content to the Kerberos krb5.conf field.
For other EMR clusters or self-managed Kerberos services, replace
hostnamein the file with the private IP address of the VPC.
(Optional) Add extra configurations to the
krb5.conffile based on the network protocol type.If you opened UDP port 88 when you configured the network connection in Step 1: Prepare the network, no extra configuration is needed.
If you used the TCP protocol for the network connection in Step 1: Prepare the network, add
udp_preference_limit = 1under[libdefaults].
In the Actions column, click Enable.
In the dialog box that appears, click OK.
Step 3: Submit a Spark batch job
After you enable Kerberos authentication, client authentication is required to submit Spark batch jobs. If you submit a job without the required configuration, the error message spark.kerberos.keytab and spark.kerberos.principal not configured is returned.
Create a Spark batch job. For more information, see PySpark Quick Start.
On the new development tab, add the following configuration and click Run.
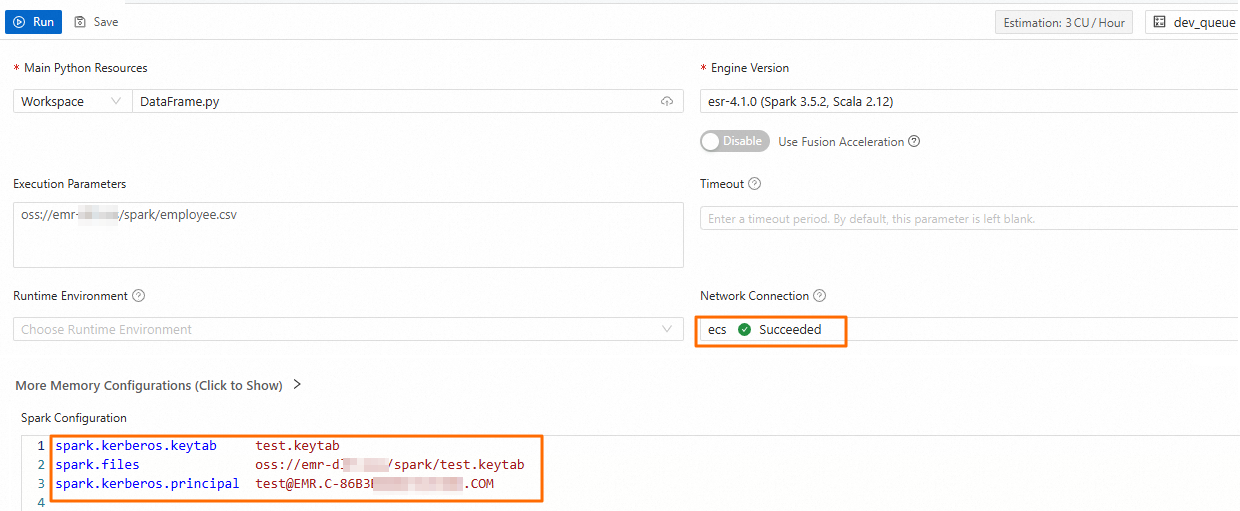
Parameter
Description
Network Connection
Select the name of the network connection that you added in Step 1.
Spark Configuration
Configure the following parameters.
spark.files oss://<bucketname>/path/test.keytab spark.kerberos.keytab test.keytab spark.kerberos.principal <username>@<REALM>The parameters are described as follows:
spark.files: The full path of the keytab file that is uploaded to OSS.spark.kerberos.keytab: The name of the keytab file.spark.kerberos.principal: The name of the principal in the keytab file. This principal is used for identity authentication with the Kerberos service. You can run theklist -kt <keytab_file>command to view the principal name in the target keytab file.
To connect to a Kerberos-enabled Hive Metastore to obtain metadata, add the following information to the Spark Configuration section.
spark.hive.metastore.sasl.enabled true spark.hive.metastore.kerberos.principal hive/<hostname>@<REALM>Set the
spark.hive.metastore.kerberos.principalparameter to the principal from the keytab file that is used by Hive Metastore. To find the path to this keytab file, go to the Configuration page of the Hive service in the EMR on ECS console. On the hive-site.xml tab, find the value of the hive.metastore.kerberos.keytab.file parameter. You can then run theklist -kt <path_to_Hive_Metastore_keytab_file>command to retrieve the principal.The value of the
spark.hive.metastore.kerberos.principalparameter has the following format:The format is typically
hive/<hostname>@<REALM>.<hostname>is the fully qualified domain name of the node where Hive Metastore runs, which you can obtain by running thehostname -fcommand.<REALM>is the realm of the KDC.If the Hive Metastore endpoint uses a hostname, you can simplify the format to
hive/_HOST@<REALM>. When connecting, Spark automatically replaces_HOSTwith the hostname from the Hive Metastore endpoint. This `_HOST` format is required to configure multiple Hive Metastores.
After the job runs, go to the Execution Records section and click Details in the Actions column.
In Job History, you can view relevant logs on the Log Exploration page.

Step 4 (Optional): Connect to a Kerberos-enabled Hive Metastore
If the workspace data catalog needs to connect to a Kerberos-enabled Hive Metastore to obtain metadata, you must specify the keytab file path and the principal name when you add an external Hive Metastore.

Kerberos keytab file: The path to the Kerberos keytab file.
Kerberos principal: The principal name from the keytab file. This principal is used for identity authentication with the Kerberos service. You can run the
klist -kt <keytab_file>command to view the principal name in the specified keytab file.