If you orchestrate data pipelines with Apache Airflow and want to trigger Spark jobs on EMR Serverless Spark automatically, this guide covers two methods: the open-source LivyOperator (via a Livy gateway) and the EMR-native EmrServerlessSparkStartJobRunOperator (via the airflow-alibaba-provider plugin).
Choose a method
| Method | When to use |
|---|---|
| Method 1: LivyOperator | Submit jobs using the standard Apache Airflow Livy provider. Works with any Airflow setup. |
| Method 2: EmrServerlessSparkStartJobRunOperator | Submit jobs using the EMR-native operator, which integrates directly with the Directed Acyclic Graph (DAG) mechanism. Recommended for new projects built entirely on EMR Serverless Spark. |
Prerequisites
Before you begin, ensure that you have:
-
Airflow installed and running. See Installation of Airflow.
-
An EMR Serverless Spark workspace created. See Create a workspace.
Usage notes
You cannot call the EmrServerlessSparkStartJobRunOperator operation to query job logs. If you want to view job logs, you must go to the EMR Serverless Spark page and find the job run whose logs you want to view by job run ID. Then, you can check and analyze the job logs on the Logs Exploration tab of the job details page or on the Spark Jobs page in the Spark UI.
Method 1: Use LivyOperator
Apache Livy provides a REST API that abstracts Spark cluster communication. For information about the Livy API, see REST API. The LivyOperator in Apache Airflow uses this API to submit jobs to EMR Serverless Spark through a Livy gateway.
Step 1: Create a Livy gateway and token
Create a Livy gateway:
-
Log on to the EMR console.
-
In the left-side navigation pane, choose EMR Serverless > Spark.
-
Click the name of the target workspace.
-
In the left-side navigation pane, click Operation Center > Gateway.
-
Click the Livy Gateway tab.
-
Click Create Livy Gateway.
-
Enter a Name (for example,
Livy-gateway) and click Create. For other parameters, see Manage gateways. -
On the Livy Gateway page, find the gateway you created and click Start in the Actions column.
Create a token:
-
On the Gateway page, find
Livy-gatewayand click Tokens in the Actions column. -
Click Create Token.
-
In the Create Token dialog box, enter a Name (for example,
Livy-token) and click OK. -
Copy the token immediately.
The token is only visible once. After you leave the page, you cannot retrieve it. If the token is lost or expires, reset it or create a new one.
Step 2: Configure Airflow
-
Install the Apache Livy provider:
pip install apache-airflow-providers-apache-livy -
Add a connection to Airflow. Use either the UI or the CLI. UI: Find the default connection named
livy_defaultand edit it, or create a new connection. See Creating a connection with the UI. Set the following fields: CLI: Run the following command. Replace thehostvalue with your gateway endpoint andx-acs-spark-livy-tokenwith the token you copied.Field Value Host The endpoint of the Livy gateway Schema httpsExtra {"x-acs-spark-livy-token": "<your-token>"}airflow connections add 'livy_default' \ --conn-json '{ "conn_type": "livy", "host": "pre-emr-spark-livy-gateway-cn-hangzhou.data.aliyun.com/api/v1/workspace/w-xxxxxxx/livycompute/lc-xxxxxxx", "schema": "https", "extra": { "x-acs-spark-livy-token": "6ac**********kfu" } }'See Creating a connection with the CLI for more options.
Step 3: Define a DAG and submit a job
The following example uses LivyOperator to run a SparkPi job from a JAR stored in Object Storage Service (OSS).
from datetime import timedelta, datetime
from airflow import DAG
from airflow.providers.apache.livy.operators.livy import LivyOperator
default_args = {
'owner': 'aliyun',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
# Initialize the DAG
livy_operator_sparkpi_dag = DAG(
dag_id="livy_operator_sparkpi_dag",
default_args=default_args,
schedule_interval=None, # Trigger manually
start_date=datetime(2024, 5, 20),
tags=['example', 'spark', 'livy'],
catchup=False
)
# Define the Livy task
livy_sparkpi_submit_task = LivyOperator(
file="oss://<YourBucket>/jars/spark-examples_2.12-3.3.1.jar", # Replace with your OSS path
class_name="org.apache.spark.examples.SparkPi",
args=['1000'],
driver_memory="1g",
driver_cores=1,
executor_memory="1g",
executor_cores=2,
num_executors=1,
name="LivyOperator SparkPi",
task_id="livy_sparkpi_submit_task",
dag=livy_operator_sparkpi_dag,
)
livy_sparkpi_submit_taskReplace the file value with the OSS path of your JAR. For instructions on uploading files to OSS, see Simple upload.
DAG parameters:
| Parameter | Description |
|---|---|
dag_id |
Unique identifier of the DAG. |
schedule_interval |
Schedule for the DAG. None means manual trigger only. |
start_date |
Date from which the DAG is eligible to run. |
tags |
Labels for categorizing and searching DAGs in the UI. |
catchup |
Whether to run skipped historical runs. False skips them even if start_date is in the past. |
LivyOperator parameters:
| Parameter | Description |
|---|---|
file |
Path to the Spark job file. Supports OSS JAR paths. |
class_name |
Main class in the JAR package. |
args |
Command-line arguments passed to the Spark job. |
driver_memory, driver_cores |
Memory and CPU cores for the driver. |
executor_memory, executor_cores |
Memory and CPU cores per executor. |
num_executors |
Number of executors. |
name |
Display name of the Spark job. |
task_id |
Unique identifier of the Airflow task within the DAG. |
dag |
Associates the task with its parent DAG. |
Method 2: Use EmrServerlessSparkStartJobRunOperator
EmrServerlessSparkStartJobRunOperator is an EMR Serverless Spark-native operator provided through the airflow-alibaba-provider plugin. It integrates directly with Airflow's DAG mechanism and supports JAR, SQL, and Python job types.
EmrServerlessSparkStartJobRunOperator does not support querying job logs. To view logs, go to the EMR Serverless Spark console, find the job run by its job run ID, then check the Logs Exploration tab on the job details page or the Spark Jobs page in the Spark UI.Step 1: Configure Airflow
-
Install the plugin on each Airflow node:
pip install airflow_alibaba_provider-0.0.3-py3-none-any.whl -
Add a connection to Airflow. Use either the CLI or the UI. CLI:
Field Value Connection Id emr-serverless-spark-idConnection Type Generic(orEmailif Generic is unavailable)Extra {"auth_type": "AK", "access_key_id": "<yourAccesskeyId>", "access_key_secret": "<yourAccesskeyKey>", "region": "<yourRegion>"}airflow connections add 'emr-serverless-spark-id' \ --conn-json '{ "conn_type": "emr_serverless_spark", "extra": { "auth_type": "AK", "access_key_id": "<yourAccesskeyId>", "access_key_secret": "<yourAccesskeyKey>", "region": "<yourRegion>" } }'See Creating a connection with the CLI for more options. UI: Go to Admin > Connections > Add Connection and fill in the following fields. See Creating a connection with the UI.
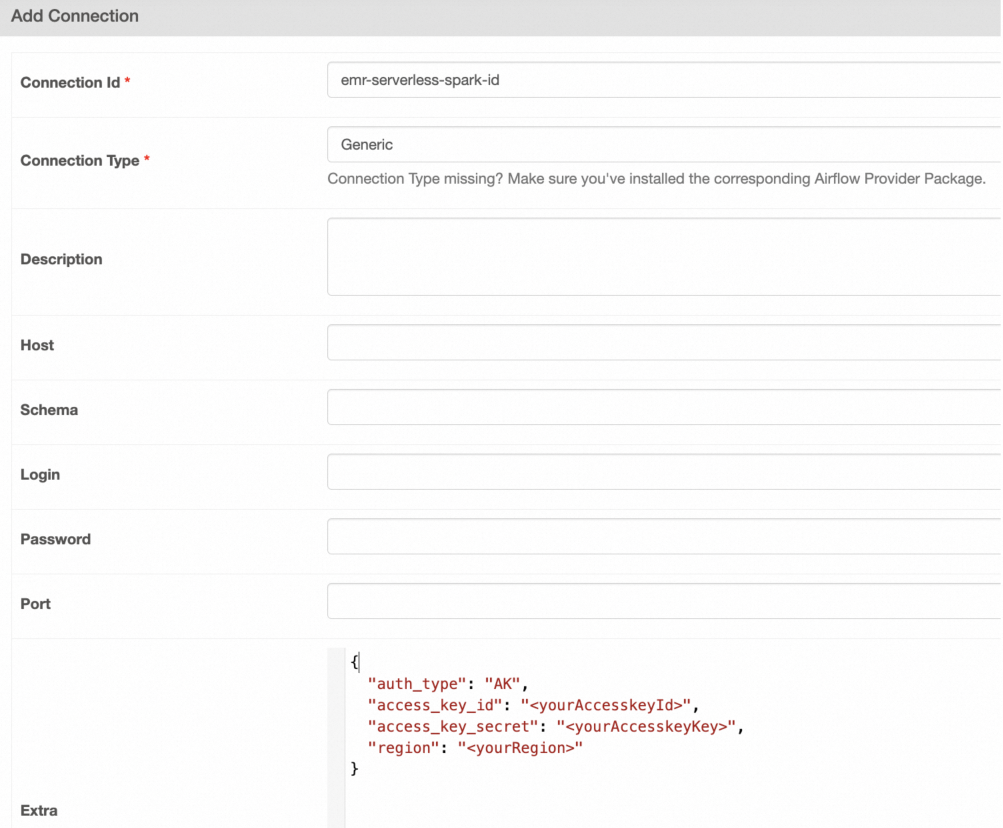
Step 2: Define DAGs and submit jobs
All examples use EmrServerlessSparkStartJobRunOperator to submit jobs to EMR Serverless Spark. Replace workspace_id, region, and entry point values with your own.
Submit a JAR job
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# mypy: disable-error-code="call-arg"
with DAG(
dag_id="emr_spark_jar",
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_jar = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_jar",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-7e2f1750c6b3****",
resource_queue_id="root_queue",
code_type="JAR",
name="airflow-emr-spark-jar",
entry_point="oss://<YourBucket>/spark-resource/examples/jars/spark-examples_2.12-3.3.1.jar",
entry_point_args=["1"],
spark_submit_parameters="--class org.apache.spark.examples.SparkPi --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_jarSubmit an inline SQL job
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# mypy: disable-error-code="call-arg"
with DAG(
dag_id="emr_spark_sql",
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_sql = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_sql",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-7e2f1750c6b3****",
resource_queue_id="root_queue",
code_type="SQL",
name="airflow-emr-spark-sql",
entry_point=None,
entry_point_args=["-e", "show tables;show tables;"],
spark_submit_parameters="--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None,
)
emr_spark_sqlSubmit an SQL file from OSS
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# mypy: disable-error-code="call-arg"
with DAG(
dag_id="emr_spark_sql_2",
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_sql_2 = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_sql_2",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-ae42e9c92927****",
resource_queue_id="root_queue",
code_type="SQL",
name="airflow-emr-spark-sql-2",
entry_point="",
entry_point_args=["-f", "oss://<YourBucket>/spark-resource/examples/sql/show_db.sql"],
spark_submit_parameters="--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_sql_2Submit a Python script from OSS
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# mypy: disable-error-code="call-arg"
with DAG(
dag_id="emr_spark_python",
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_python = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_python",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-ae42e9c92927****",
resource_queue_id="root_queue",
code_type="PYTHON",
name="airflow-emr-spark-python",
entry_point="oss://<YourBucket>/spark-resource/examples/src/main/python/pi.py",
entry_point_args=["1"],
spark_submit_parameters="--conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_pythonEmrServerlessSparkStartJobRunOperator parameters:
| Parameter | Type | Description |
|---|---|---|
task_id |
str | Unique identifier of the Airflow task within the DAG. |
emr_serverless_spark_conn_id |
str | ID of the Airflow connection to EMR Serverless Spark. |
region |
str | Region where the EMR Serverless Spark workspace is located. |
polling_interval |
int | Interval in seconds at which Airflow polls for job status. |
workspace_id |
str | ID of the EMR Serverless Spark workspace. |
resource_queue_id |
str | ID of the resource queue for the job. |
code_type |
str | Job type: JAR, SQL, or PYTHON. Determines how entry_point is interpreted. |
name |
str | Display name of the Spark job. |
entry_point |
str | Location of the file used to start the job. JAR, SQL, and Python files are supported. The meaning of this parameter varies based on code_type. |
entry_point_args |
List | Arguments passed to the Spark application. |
spark_submit_parameters |
str | Additional spark-submit parameters, such as class name and resource configuration. |
is_prod |
bool | True runs the job in the production environment. The resource_queue_id must match the production resource queue (for example, root_queue). |
engine_release_version |
str | EMR Spark engine version. Default is esr-2.1-native (Spark 3.3.1, Scala 2.12, native runtime). |