This topic answers frequently asked questions (FAQs) about EMR Serverless Spark.
Frequently asked questions about EMR Serverless Spark are organized below by compatibility area.
Questions
DLF compatibility
What do I do if a java.net.UnknownHostException error occurs when reading DLF data?
This error occurs in Development when you run an SQL query to read data from a Data Lake Formation (DLF) 1.0 data table, and EMR Serverless Spark cannot resolve the host in the table's location path. The fix depends on whether the Hadoop Distributed File System (HDFS) cluster uses high availability (HA).
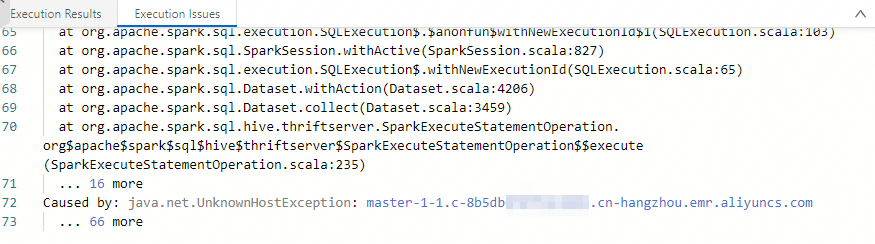
HDFS without HA
Make sure the domain name in the table's location is accessible. By default, master-1-1.<cluster-id>.<region>.emr.aliyuncs.com is directly accessible. For other domain names, add the required mappings. See Manage Domain Names.
HDFS with HA
Configure the domain name mappings. See Manage Domain Names.
Create a file named
hdfs-site.xmlat/etc/spark/conf. Base the content on thehdfs-site.xmlfrom your EMR on ECS cluster. See Manage custom configurations for how to upload the file. The following is a samplehdfs-site.xml. Replace the NameNode addresses and port numbers with values from your cluster.<?xml version="1.0"?> <configuration> <property> <name>dfs.nameservices</name> <value>hdfs-cluster</value> </property> <property> <name>dfs.ha.namenodes.hdfs-cluster</name> <value>nn1,nn2,nn3</value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn1</name> <value>master-1-1.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn2</name> <value>master-1-2.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn3</name> <value>master-1-3.<cluster-id>.<region-id>.emr.aliyuncs.com:<port></value> </property> <property> <name>dfs.client.failover.proxy.provider.hdfs-cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> </configuration>After the file is in place, the Java Runtime or Fusion Runtime can resolve the HA cluster and access the data.
OSS compatibility
How do I access OSS resources across accounts?
Two methods are available. Choose based on how broadly you need to share access:
| Method | Scope | When to use |
|---|---|---|
| Workspace level | All jobs in the workspace | The workspace runs many jobs that need access to the same bucket, and you want a single, persistent configuration. |
| Task and session level | A specific task or session | Access is temporary or task-specific, or you don't have permission to modify the workspace configuration. |
Workspace level
Configure the bucket policy of the target Object Storage Service (OSS) bucket to grant the workspace execution role read and write access.
Log on to the OSS console. In the left-side navigation pane, click Buckets, then click the target bucket.
In the navigation pane on the left, choose Permission Control > Bucket Policy.
On the Bucket Policy page, click the Add in GUI tab, then click Authorize.
In the Authorize panel, set the following parameters and click OK. For all other parameters, see Configure a bucket policy using the GUI.
Parameter Value Applied To Whole Bucket Authorized User Other Accounts. Set Principal to arn:sts::<uid>:assumed-role/<role-name>/*. Replace<uid>with the Alibaba Cloud account ID and<role-name>with the execution role name (case-sensitive). The default role is AliyunEMRSparkJobRunDefaultRole. To find the execution role, go to the workspace list page and click Details in the Actions column.
Task and session level
When you create a task or session, add the following properties in the Spark Configurations section. Replace the placeholders with your bucket details.
spark.hadoop.fs.oss.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.oss.bucket.<bucketName>.credentials.provider com.aliyun.jindodata.oss.auth.SimpleCredentialsProvider
spark.hadoop.fs.oss.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.oss.bucket.<bucketName>.accessKeySecret <accessKey>| Placeholder | Description |
|---|---|
<bucketName> | Name of the OSS bucket |
<endpoint> | OSS endpoint |
<accessID> | AccessKey ID of the Alibaba Cloud account used to access the OSS data |
<accessKey> | AccessKey secret of the Alibaba Cloud account used to access the OSS data |
S3 compatibility
How do I access S3?
When you create a task or session, add the following properties in the Spark Configurations section. Replace the placeholders with your bucket details.
spark.hadoop.fs.s3.impl com.aliyun.jindodata.s3.JindoS3FileSystem
spark.hadoop.fs.AbstractFileSystem.s3.impl com.aliyun.jindodata.s3.S3
spark.hadoop.fs.s3.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.s3.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.s3.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.s3.credentials.provider com.aliyun.jindodata.s3.auth.SimpleCredentialsProvider| Placeholder | Description |
|---|---|
<bucketName> | Name of the S3 bucket |
<endpoint> | S3 endpoint |
<accessID> | AccessKey ID of the account used to access S3 |
<accessKey> | AccessKey secret of the account used to access S3 |
OBS compatibility
How do I access OBS?
When you create a task or session, add the following properties in the Spark Configurations section. Replace the placeholders with your bucket details.
spark.hadoop.fs.obs.impl com.aliyun.jindodata.obs.JindoObsFileSystem
spark.hadoop.fs.AbstractFileSystem.obs.impl com.aliyun.jindodata.obs.OBS
spark.hadoop.fs.obs.bucket.<bucketName>.accessKeyId <accessID>
spark.hadoop.fs.obs.bucket.<bucketName>.accessKeySecret <accessKey>
spark.hadoop.fs.obs.bucket.<bucketName>.endpoint <endpoint>
spark.hadoop.fs.obs.credentials.provider com.aliyun.jindodata.obs.auth.SimpleCredentialsProvider| Placeholder | Description |
|---|---|
<bucketName> | Name of the OBS bucket |
<endpoint> | OBS endpoint |
<accessID> | AccessKey ID of the account used to access OBS |
<accessKey> | AccessKey secret of the account used to access OBS |