This topic describes how to create an E-MapReduce (EMR) cluster that contains the Kafka service and use Kafka topics and the Kafka Connect service. This helps you get started with an EMR Kafka cluster.
Precautions
When you create an EMR Kafka cluster, you must select an Elastic Compute Service (ECS) instance type and determine the number of brokers based on the evaluated load of your business. No general cluster plan can be provided due to the variety of business scenarios. You must create a cluster based on your actual environment. In most cases, we recommend that you consider the following items when you select an instance type:
Deploy Kafka brokers on ECS instances whose CPU-to-memory ratio is 1:4.
Use cloud disks to store data.
Consider the relationship between the I/O throughput of cloud disks and the network interface card (NIC) bandwidth.
Consider the following factors when you configure the deployment parameters:
The Kafka versions used in EMR depend on the ZooKeeper service. The availability of ZooKeeper determines whether the Kafka service is highly available. We recommend that you turn on High Service Availability when you create a cluster. If you turn on High Service Availability when you create the cluster, three nodes are deployed for the ZooKeeper service.
If the master node group is only used to deploy ZooKeeper, you must configure only one data disk for the master node group.
For more information about evaluation-based suggestions, see Suggestions for evaluating cluster resources.
Create an EMR Kafka cluster
This section describes how to create a Kafka cluster. For more information, see Create a cluster.
Go to the cluster creation page.
Log on to the EMR console. In the left-side navigation pane, click EMR on ECS.
On the EMR on ECS page, click Create Cluster.
In the Software Configuration step, select an EMR version based on the required Kafka version.
Turn on High Service Availability to allow three nodes to be deployed for the ZooKeeper service.
 Important
ImportantIf you turn on High Service Availability when you create the cluster, three nodes are deployed in the master node group for the ZooKeeper service. The Kafka versions used in EMR depend on the ZooKeeper service. When you create a cluster, we recommend that you turn on High Service Availability.
In the Hardware Configuration step, select the appropriate specifications for Elastic Compute Service (ECS) instances and the number of nodes.
Specifications: Select an instance type with a CPU-to-memory ratio of 1:4 for the core node group.
Number of nodes: Set the number of nodes in the core node group to the number of Kafka partition replicas plus one. This ensures sufficient redundancy of resources. For example, if the planned number of replicas is three, set the number of nodes to four.

In the Basic Configuration step, configure the parameters based on your business requirements.
Use Kafka topics
This section describes how to use Kafka topics to produce and consume data. In actual business scenarios, you can also use software such as Kafka Manager or Cruise Control to manage clusters.
Log on to the master node of the Kafka cluster in SSH mode. For more information, see Log on to a cluster.
Run the following commands to create a Kafka topic:
sudo su - kafka kafka-topics.sh --partitions 10 --replication-factor 2 --bootstrap-server core-1-1:9092 --topic test --createRun the following command to view the details of the Kafka topic:
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test --describeRun the following command to produce data:
kafka-console-producer.sh --broker-list core-1-1:9092 --topic testAfter the data is produced, you can enter required information and press the Enter key to send the data to the topic.
Open a new terminal window and run the following command to consume data:
kafka-console-consumer.sh --bootstrap-server core-1-1:9092 --topic test --from-beginning --group test-consumer-group
Use the Kafka Connect service
You can deploy the KafkaConnect component only in a minor version later than EMR V3.41.0 or EMR V5.7.0. This section describes how to use the Kafka Connect service.
Go to the Nodes tab.
Log on to the EMR console. In the left-side navigation pane, click EMR on ECS.
In the top navigation bar, select the region in which your cluster resides and select a resource group based on your business requirements.
On the EMR on ECS page, find the cluster that you want to scale out and click Nodes in the Actions column.
Create a node group to deploy the KafkaConnect component.
The KafkaConnect component is deployed in an EMR task node group. After you create a task node group in an EMR Kafka cluster, EMR automatically creates a Kafka Connect cluster in the node group.
Create an EMR task node group.
On the Nodes tab of the cluster details page, click Add Node Group to create a task node group. For more information, see the Create a node group section of the "Manage node groups" topic.
Scale out the task node group.
You can increase the number of ECS instances in the task node group based on your business requirements. For more information, see Scale out an EMR cluster.
Check the status of the KafkaConnect component. Make sure that the Kafka Connect cluster is started.
Go to the Status tab of the Kafka service page. In the Components section, view the status of the Kafka Connect component. Make sure that the component is running.
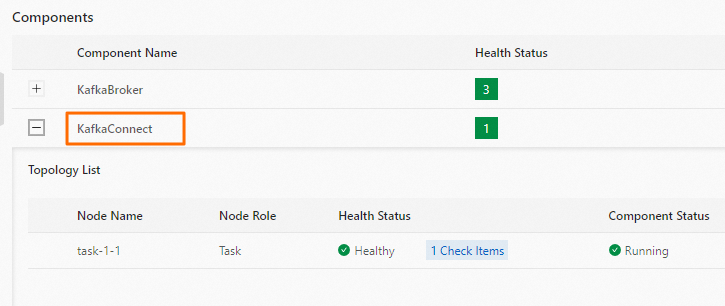
Check the status of the Kafka Connect Rest service.
Log on to the master node of the Kafka cluster in SSH mode. For more information, see Log on to a cluster.
Run the following command to check the status of the Kafka Connect Rest service:
curl -X GET http://task-1-1:8083| jq .The information similar to the following output is returned:
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 91 100 91 0 0 13407 0 --:--:-- --:--:-- --:--:-- 15166 { "version": "2.4.1", "commit": "42ce056344c5625a", "kafka_cluster_id": "6Z7IdHW4SVO1Pbql4c****" }
Use the Kafka Connect service to migrate data.
You can start a MirrorMaker 2.0 (MM2) task in the Kafka cluster to replicate and migrate data. For more information, see Use Kafka MM2 to synchronize data across clusters.
References
For information about how to enable Secure Sockets Layer (SSL) and use SSL to connect to Kafka, see Use SSL to encrypt Kafka data.
For information about how to configure Simple Authentication and Security Layer (SASL) and use SASL to connect to Kafka, see Log on to a Kafka cluster by using SASL.