This topic describes how to configure an auto scaling policy by using LAMMPS to perform high-performance computing.
Background information
You may need to submit jobs at any time, use an Elastic High Performance Computing (E-HPC) cluster to perform large-scale computing for several hours, and then release nodes. In this case, you can configure different scaling policies for different job types. After a scaling policy is configured, the system automatically increases or decreases compute nodes based on the real-time load. This way, you can save resources and costs.
Procedure
Log on to the E-HPC console.
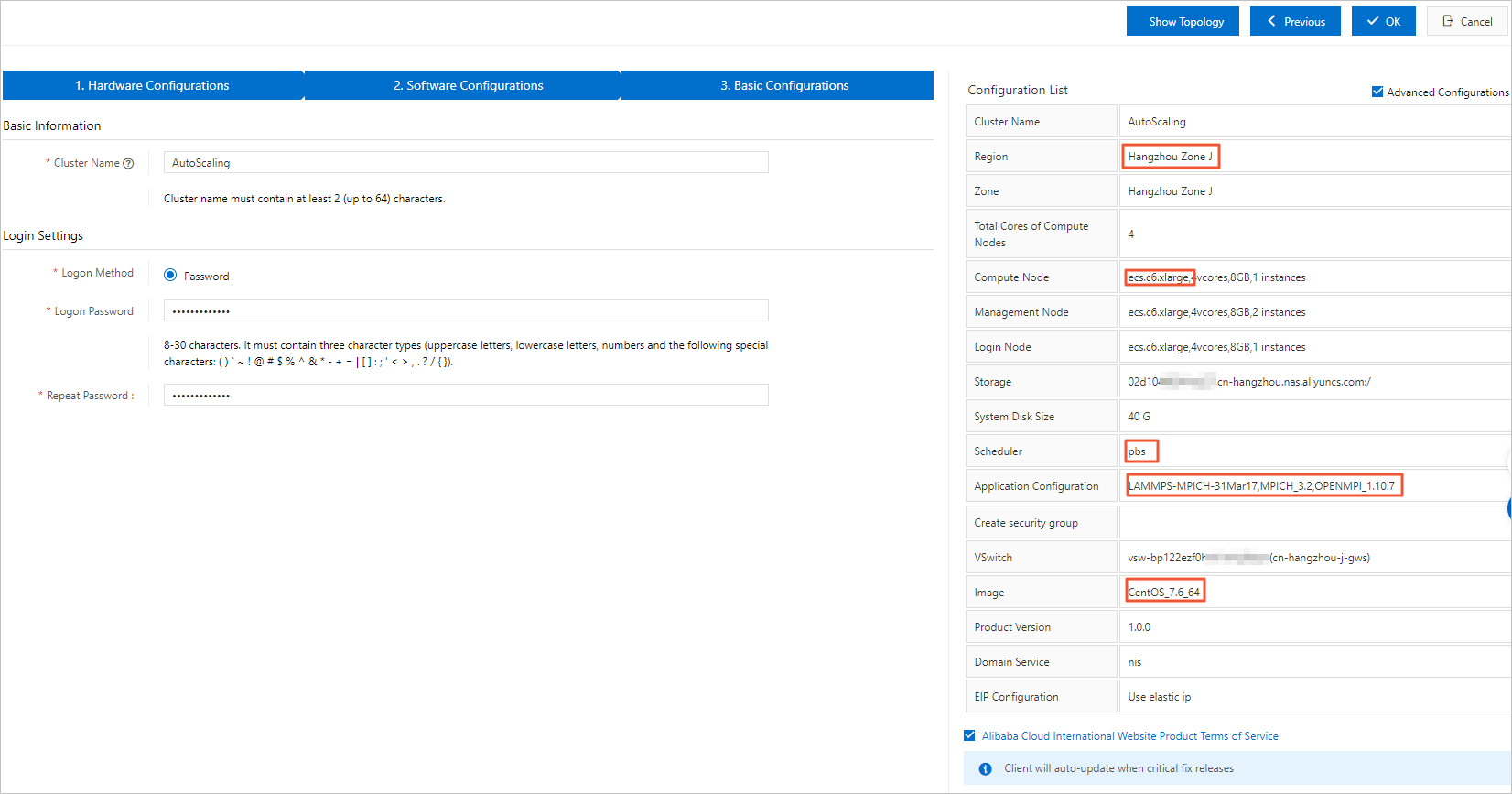
Create a cluster named AutoScaling.
For more information, see Create a cluster. Set the following parameters:
Availability Zone: Select Hangzhou Zone I.
Compute node: Select ecs.c6.large.
vSwitch: Select vsw-bp122ezf0hvk1xnhj****.
Scheduler: Select pbs.
Other Software: Install lammps-mpich 31Mar17, mpich 3.2, and openmpi 1.10.7.
Create New Queue: Create a queue named low.
Create an ordinary user named AutoScaling. For more information, see Create a user.
Configure an auto scaling policy
In the left-side navigation pane, choose Elasticity > Auto Scale.
In the Queue Configuration section, select low, and click Edit.
Click Add next to Configuration List. Set the following parameters, and then click OK.
Zone: Select Hangzhou Zone I.
VSwitch ID: Select vsw-bp122ezf0hvk1xnhj****.
Instance Type: Select ecs.c6.large.
Bid Strategy: Select Not Preemptible Instance.
In the Queue Configuration panel, set the following parameters, and click OK.
Auto Grow: Turn on the Auto Grow switch.
Auto Shrink: Turn on the Auto Shrink switch.
Queue Compute Nodes: Set a value between 2 and 10.
Prefix of Hostnames: Enter computelow.
Image Type: Select Public Image.
Image ID: Select CentOS_7.6_64.
On the Auto Scale page, click OK in the upper-right corner.
After you configure auto scaling for the cluster, two compute nodes are kept if no job runs on the cluster. One compute node needs to be added to the low queue because a compute node already exists in the queue.
Create a job script and submit the job.
In the left-side navigation pane, choose Job and Performance Management > Job.
Select AutoScaling from the Cluster drop-down list. Click Create Job.
On the Create Job page, choose Edit Job File > Create File > Template > pbs demo.
On the Edit Job File page, configure the lj.in and AutoScaling.pbs files. Click OK.
For information about the parameters and parameter descriptions of the lj.in example, see Use LAMMPS to perform high-performance computing. The following sample script shows how to configure AutoScaling.pbs:
#!/bin/sh # PBS -l select=3:ncpus=1:mpiprocs=1 # The script runs on three compute nodes. Each node uses one vCPU and one Message Passing Interface (MPI) process. #PBS -j oe export MODULEPATH=/opt/ehpcmodulefiles/ module load lammps-openmpi/31Mar17 module load openmpi/1.10.7 echo "run at the beginning" mpirun lmp -in ./lj.in
View the result of auto scaling.
In the left-side navigation pane, choose Resource Management > Nodes.
Select AutoScaling from the Cluster drop-down list. Select Compute Node from the Node Type drop-down list.
In the Node List section, select the low queue from the Queue drop-down list.
The number of nodes in the queue varies with the following job statuses:
If a job runs on the cluster, a compute node is automatically added to the node list. After a few minutes, the compute node enters the Running state. In this case, the job starts running on the three nodes in the low queue.
If no job runs on the cluster, the idle compute nodes in the low queue are released after six minutes and the two compute nodes in the queue are kept for basic needs.
View the running details of the job.
In the left-side navigation pane, choose Job and Performance Management > Job.
Select AutoScaling from the Cluster drop-down list. Set Job Status to Finished.
Find the job and click Details.
View the logs of scale-out and scale-in operations.
In the left-side navigation pane, choose Maintenance & Monitoring > Operation Log.
Select AutoScaling from the Cluster drop-down list. You can view the operation logs of scale-out and scale-in operations.