In DataWorks, you can create an E-MapReduce (EMR) MapReduce (MR) node to break down large datasets into parallel map tasks, which significantly improves data processing efficiency. This topic provides an example of developing and configuring an EMR MR job that reads a text file from Object Storage Service (OSS) and counts the words in it.
Prerequisites
You have created an Alibaba Cloud EMR cluster and registered it with DataWorks. For more information, see Data Studio: Bind an EMR computing resource.
-
(Optional, for RAM users) The RAM user for task development has been added to the corresponding workspace and granted the Development or Workspace Administrator (this role has extensive permissions, grant with caution) role. For more information about how to add members, see Add members to a workspace.
If you use an Alibaba Cloud account, you can skip this step.
To follow the example in this topic, create a bucket in Object Storage Service (OSS). For more information, see Create buckets.
Limitations
You can run this type of node only on a serverless resource group (recommended) or an exclusive resource group for scheduling.
To manage metadata for a DataLake or custom cluster in DataWorks, you must first configure EMR-HOOK in the cluster. For more information, see Configure Hive EMR-HOOK.
NoteIf EMR-HOOK is not configured in the cluster, DataWorks cannot display real-time metadata, generate audit logs, display data lineage, or perform EMR-related data governance tasks.
Prepare initial data and a JAR package
Prepare the initial data
Create a sample file named input01.txt with the following content.
hadoop emr hadoop dw
hive hadoop
dw emrUpload the initial data file
Log on to the OSS console. In the left-side navigation pane, click Buckets.
Click the name of your target bucket to open the File Management page.
This example uses a bucket named
onaliyun-bucket-2.Click Create Directory to create directories for the initial data and the JAR resource.
Set Directory Name to
emr/datas/wordcount02/inputsto create the directory for the initial data.Set Directory Name to
emr/jarsto create the directory for the JAR resource.
Upload the initial data file to its directory.
Navigate to the
/emr/datas/wordcount02/inputspath and click Upload File.In the Files to Upload area, click Select Files, add the
input01.txtfile to the bucket, and then click Upload File.
Build a MapReduce job and JAR package
Open your IntelliJ IDEA project and add the following dependencies to your pom.xml file.
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.8.5</version> <!--Use version 2.8.5, which is the version used by EMR MR.--> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.8.5</version> </dependency>To read from and write to an OSS file in MapReduce, you must configure the following parameters.
ImportantRisk warning: The AccessKey pair of your Alibaba Cloud account grants full access to all API operations. Exposing your AccessKey ID and AccessKey Secret compromises the security of all resources under your account. We strongly recommend using a RAM user for API calls and daily operations. Do not hardcode your AccessKey ID or AccessKey Secret in your project code or any other publicly accessible location. The following code is for demonstration purposes only. Keep your AccessKey information secure.
conf.set("fs.oss.accessKeyId", "${accessKeyId}"); conf.set("fs.oss.accessKeySecret", "${accessKeySecret}"); conf.set("fs.oss.endpoint","${endpoint}");The following table describes the parameters.
${accessKeyId}: The AccessKey ID of your Alibaba Cloud account.${accessKeySecret}: The AccessKey Secret of your Alibaba Cloud account.${endpoint}: The public endpoint of OSS. The endpoint depends on the region where your EMR cluster resides. The OSS bucket and the cluster must be in the same region. For more information, see Regions and endpoints.
The following Java code is a modified version of the official Hadoop WordCount sample. It includes configurations for the AccessKey ID and AccessKey Secret to grant the job permission to access OSS files.
After you edit the Java code, package it into a JAR file. This example generates a JAR file named
onaliyun_mr_wordcount-1.0-SNAPSHOT.jar.
Procedure
On the configuration tab of the EMR MR node, develop the task as follows:
Develop the EMR MR task
Choose one of the following methods based on your requirements:
Method 1: Upload and reference JAR
You can also upload a resource from your local machine to DataStudio and then reference it in a node. If a resource is too large to upload through the DataWorks console, you can store it in HDFS and reference it in your code.
Create a JAR resource.
For more information, see Manage resources. Store the JAR package from the Prepare initial data and a JAR package step in the
emr/jarsdirectory. Click Click Upload.Configure the Storage Path, Data Sources, and Resource Group parameters.
Click Save.
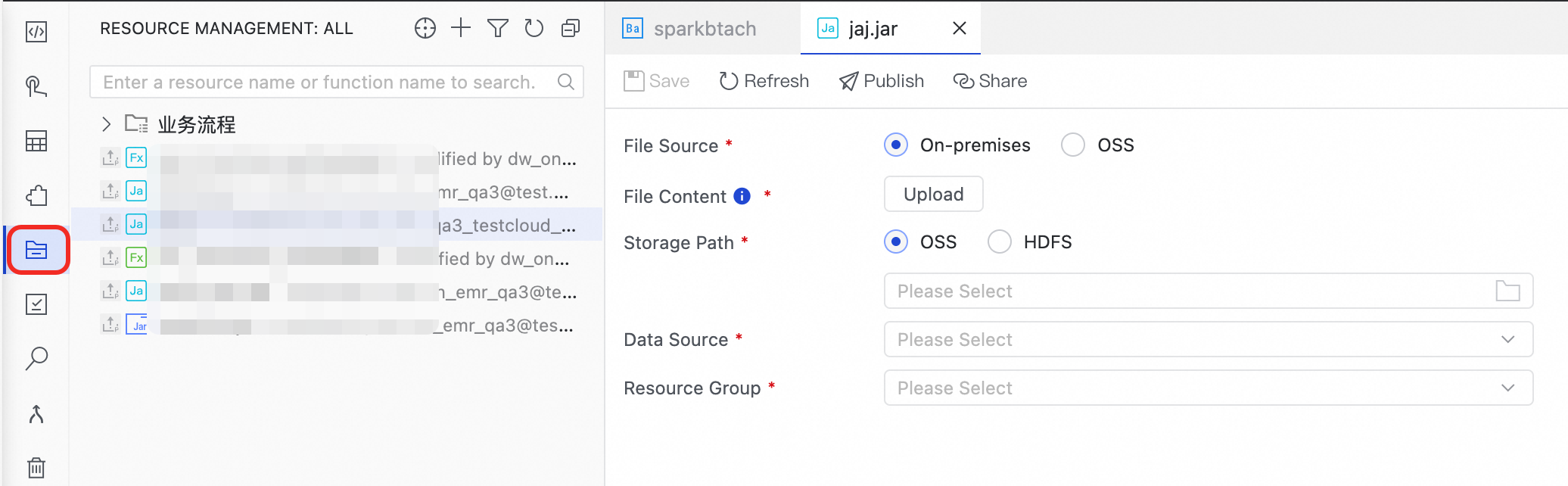
Reference the JAR resource.
Open the EMR MR node to go to its configuration tab.
In the Resource Management pane on the left, find the resource that you want to reference. In this example, the resource is
onaliyun_mr_wordcount-1.0-SNAPSHOT.jar. Right-click the resource and select Insert Resource Path.After you reference the resource, a reference statement appears on the configuration tab of the EMR MR node, indicating that the resource was referenced successfully. Run the following command. Replace the resource package, bucket name, and path with your actual information.
##@resource_reference{"onaliyun_mr_wordcount-1.0-SNAPSHOT.jar"} onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputsNoteComments are not supported in the code editor for EMR MR nodes.
Method 2: Reference OSS resource
You can use the OSS REF method to directly reference a resource from OSS. When the node runs, DataWorks automatically downloads the referenced OSS resource to the local environment. This method is often used in scenarios where an EMR task depends on a JAR file or a script.
Upload the JAR resource.
After you develop the code, log on to the OSS console. In the left-side navigation pane, click Buckets.
Click the name of your target bucket to open the File Management page.
This example uses a bucket named
onaliyun-bucket-2.Upload the JAR resource to its directory.
Navigate to the
emr/jarsdirectory. Click Upload File. In the Files to Upload area, click Select Files, add theonaliyun_mr_wordcount-1.0-SNAPSHOT.jarfile, and then click Upload File.
Reference the JAR resource.
On the configuration tab of the EMR MR node, write the code to reference the JAR resource.
hadoop jar ossref://onaliyun-bucket-2/emr/jars/onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputsNoteThe command is in the following format:
hadoop jar <Path of the JAR to run> <Full name of the main class> <Input file directory> <Output directory>.The following table describes the parameters for the JAR path.
Parameter
Description
Path of the JAR to run
The format is
ossref://{endpoint}/{bucket}/{object}Endpoint: The public endpoint of OSS. If this parameter is left empty, you can only reference resources from a bucket in the same region as the EMR cluster.
Bucket: A container that OSS uses to store objects. Each Bucket has a unique name. You can log on to the OSS console to view all Buckets under your account.
object: A specific object, which can be a file or a path, stored in a bucket.
(Optional) Configure advanced parameters
In the right-side pane, click the Scheduling Settings tab. You can configure the following parameters in the section.
NoteThe available advanced parameters vary by EMR cluster type, as shown in the following tables.
Configure additional open-source Spark properties on the Scheduling Settings tab in the section.
DataLake and custom cluster: EMR on ECS
Parameter
Description
queue
The queue where jobs are submitted. The default value is default. For more information about EMR YARN, see Basic queue configurations.
priority
The priority of the job. The default value is 1.
FLOW_SKIP_SQL_ANALYZE
The execution mode for SQL statements. Valid values:
true: Executes multiple SQL statements at a time.false(Default): Executes one SQL statement at a time.
NoteThis parameter is supported only for test runs in the data development environment.
Others
You can also add custom MR job parameters in the advanced configuration section. When you commit the code, DataWorks automatically adds the new parameters to the command using the
-D key=valuestatement.Hadoop cluster: EMR on ECS
Parameter
Description
queue
The queue where jobs are submitted. The default value is default. For more information about EMR YARN, see Basic queue configurations.
priority
The priority of the job. The default value is 1.
USE_GATEWAY
Specifies whether to submit jobs from this node through a gateway cluster. Valid values:
true: Submits jobs through a gateway cluster.false(Default): Does not submit jobs through a gateway cluster. Jobs are submitted to the master node by default.
NoteIf you set this parameter to
truebut the node's cluster is not associated with a gateway cluster, the EMR job submission fails.Run the task
In Run Configuration, under Compute Resource, configure Compute Resource and Resource Group.
NoteYou can also specify the CUs for Scheduling based on your task requirements. The default value is
0.25.To access a data source over the public internet or in a Virtual Private Cloud (VPC), you must use a resource group for scheduling that can connect to the data source. For more information, see Network connectivity solutions.
In the parameter dialog box in the toolbar, select the data source that you created and click Run.
If you need to run the node task periodically, configure its scheduling properties. For more information, see Configure scheduling properties for a node.
After you configure the node, you must deploy it. For more information, see Deploy nodes.
After the task is deployed, you can view its status in Operation Center. For more information, see Introduction to Operation Center.
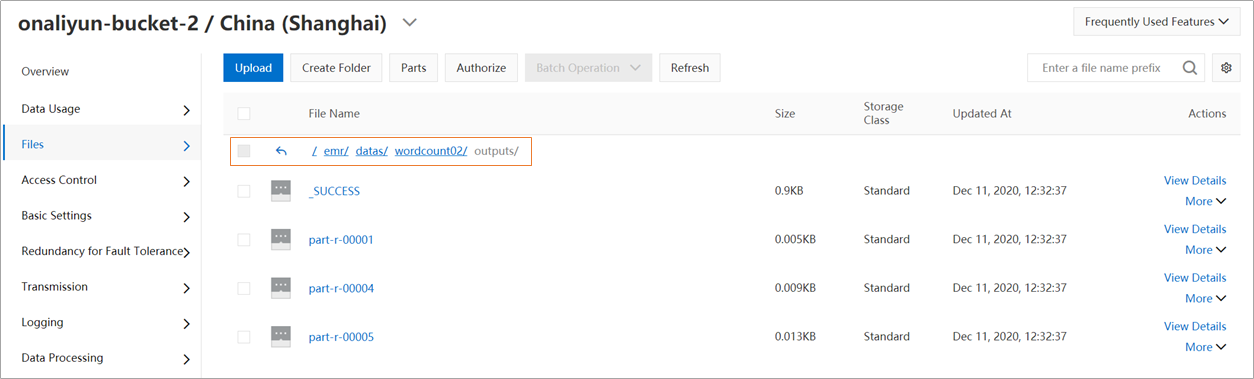
View the results
Log on to the OSS console. You can view the output file in the destination directory within your bucket. In this example, the path is emr/datas/wordcount02/outputs.
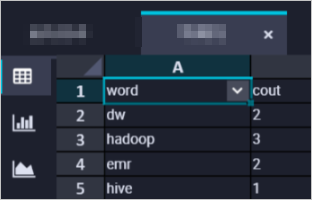
Read the statistical results in DataWorks.
Create an EMR Hive node. For more information, see Create a node for a scheduled workflow.
In the EMR Hive node, create a Hive external table mapped to the data in OSS, and then query the table data. The following is sample code:
CREATE EXTERNAL TABLE IF NOT EXISTS wordcount02_result_tb ( `word` STRING COMMENT 'Word', `count` STRING COMMENT 'Count' ) ROW FORMAT delimited fields terminated by '\t' location 'oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs/'; SELECT * FROM wordcount02_result_tb;The following figure shows the result.