In this experiment, you will walk through a retail e-commerce data development and analysis scenario in an OpenLake data lakehouse environment. You will use DataWorks for multi-engine collaborative development, visual workflow orchestration, and data catalog management. You will also practice Python programming and debugging and use a Notebook for AI-powered interactive data exploration and analysis.
Background
Introduction to DataWorks
DataWorks is an intelligent platform for data lakehouse development and governance. It is built on 15 years of Alibaba's big data construction methodology. It is deeply integrated with dozens of Alibaba Cloud big data and AI computing services, such as MaxCompute, E-MapReduce, Hologres, Flink, and PAI. DataWorks provides intelligent extract, transform, and load (ETL) development, data analysis, and proactive data asset governance services for data warehouses, data lakes, and OpenLake data lakehouse architectures. This helps you manage the entire "Data+AI" lifecycle. Since 2009, DataWorks has continuously productized Alibaba's data architecture. It serves various industries, including government, finance, retail, the Internet, automotive, and manufacturing. Tens of thousands of customers use DataWorks to drive digital transformation and create value.
Introduction to DataWorks Copilot
DataWorks Copilot is your intelligent assistant in DataWorks. In DataWorks, you can choose to use the DataWorks default model, Qwen3-235B-A22B, DeepSeek-R2-0528, or the Qwen3-Coder large model to perform Copilot operations. With the deep inference capabilities of DeepSeek-R2, DataWorks Copilot helps you perform complex operations such as SQL code generation, optimization, and testing through natural language interaction. This significantly improves ETL development and data analysis efficiency.
Introduction to DataWorks Notebook
DataWorks Notebook is an intelligent, interactive tool for data development and analysis. It supports SQL or Python analysis across multiple data engines. You can run or debug code instantly and view visualized data results. A DataWorks Notebook can also be orchestrated with other task nodes into a workflow and submitted to the scheduling system for execution. This lets you flexibly implement complex business scenarios.
Usage notes
The DataWorks Copilot public preview is subject to regional and version limitations. For more information, see Usage notes.
To use Python and Notebooks in DataStudio, you must first switch to the personal developer environment.
Limitations
OpenLake only supports Data Lake Formation (DLF) 2.0.
The data catalog only supports Data Lake Formation (DLF) 2.0.
The Qwen3-235B-A22B/DeepSeek-R2 model is available in the following regions: China (Hangzhou), China (Shanghai), China (Beijing), China (Zhangjiakou), China (Shenzhen), and China (Chengdu).
The Qwen3-Coder model is available in China (Hangzhou), China (Shanghai), China (Beijing), China (Zhangjiakou), China (Ulanqab), China (Shenzhen), and China (Chengdu).
Prerequisites
You have prepared an Alibaba Cloud account or a RAM user.
You have created a workspace.
NoteSelect Join the public preview of Data Development (DataStudio) (New).
You have attached a computing resource.
Procedure
Step 1: Manage the data catalog
The data catalog management feature of the data lakehouse lets you manage and create data catalogs for services such as DLF, MaxCompute, and Hologres.
In DataStudio, click the
 icon in the left-side menu to open Data Catalog. In the navigation pane, find the metadata type that you want to manage and click Add Project. The name of this button may vary depending on the metadata type. This topic uses MaxCompute as an example.
icon in the left-side menu to open Data Catalog. In the navigation pane, find the metadata type that you want to manage and click Add Project. The name of this button may vary depending on the metadata type. This topic uses MaxCompute as an example.You can add data sources from your DataWorks workspace. You can also select a MaxCompute project for which you have permissions on the MaxCompute-Project tab.

After you add the project, it appears under the corresponding metadata type. Click the project name to go to the data catalog details page.
On the data catalog details page, select a schema and click any table name to view the table details.
The data catalog lets you create tables visually.
Expand the data catalog to the Table level of the specified schema. Click the
 icon on the right to open the Create Table page.
icon on the right to open the Create Table page.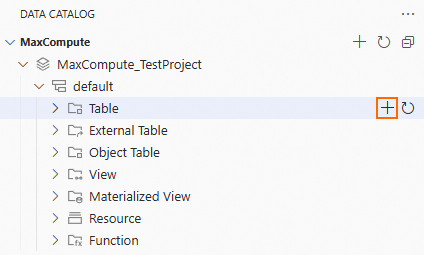
On the Create Table page, you can create a table in the following ways:
In area ①, enter the Table Name and Field Information.
In area ②, you can directly enter the DDL statement to create the table.
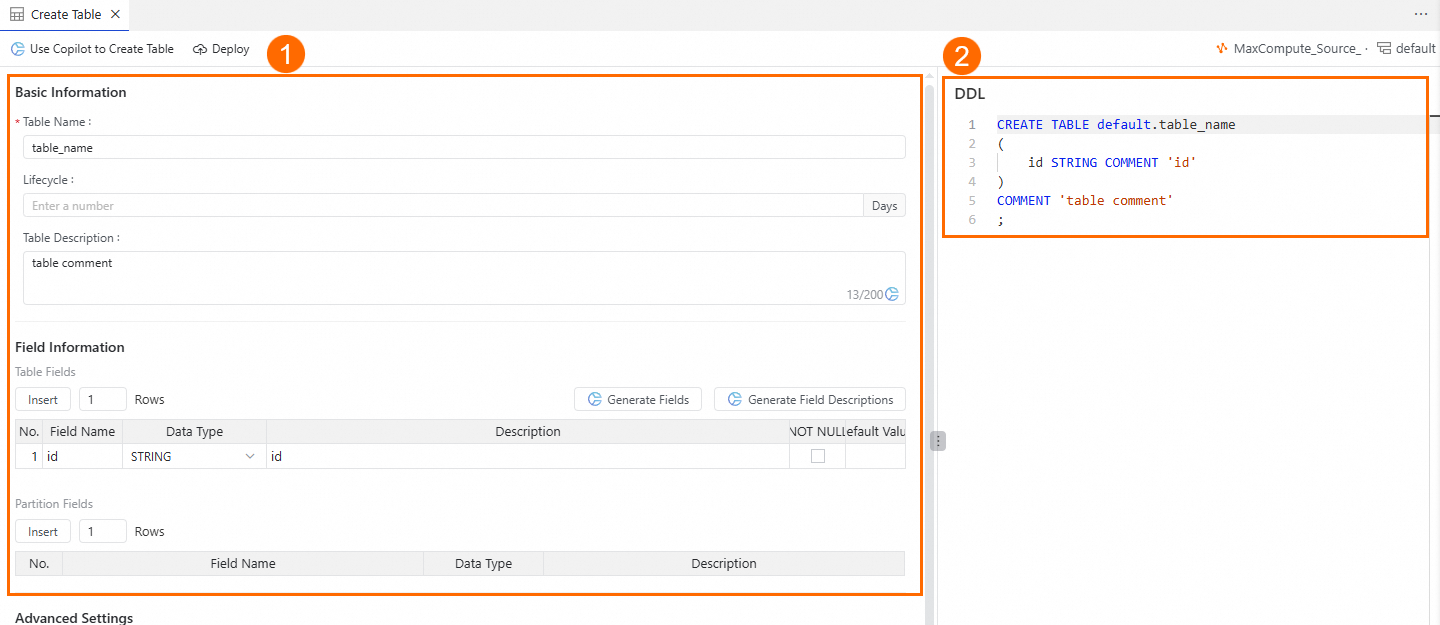
Click the Publish button at the top of the page to create the table.
Step 2: Orchestrate a workflow
A workflow lets you orchestrate various types of data development nodes by dragging and dropping them based on your business logic. You do not need to configure common parameters, such as scheduling time, for each node. This helps you easily manage complex task projects.
In DataStudio, click the
 icon in the primary menu on the left to open Data Development. In the navigation pane on the left, find Project Folder, click the
icon in the primary menu on the left to open Data Development. In the navigation pane on the left, find Project Folder, click the  icon next to it, and select New Workflow.
icon next to it, and select New Workflow.Enter a Name for the workflow and click OK to open the workflow editor.
In the workflow editor, click Drag Or Click To Add A Node on the canvas. In the Add Node dialog box, set Node Type to Zero Load Node, enter a custom Node Name, and then click Confirm.
From the list of node types on the left, find the required node type and drag it onto the canvas. In the Add Node dialog box, enter a Node Name and click Confirm.
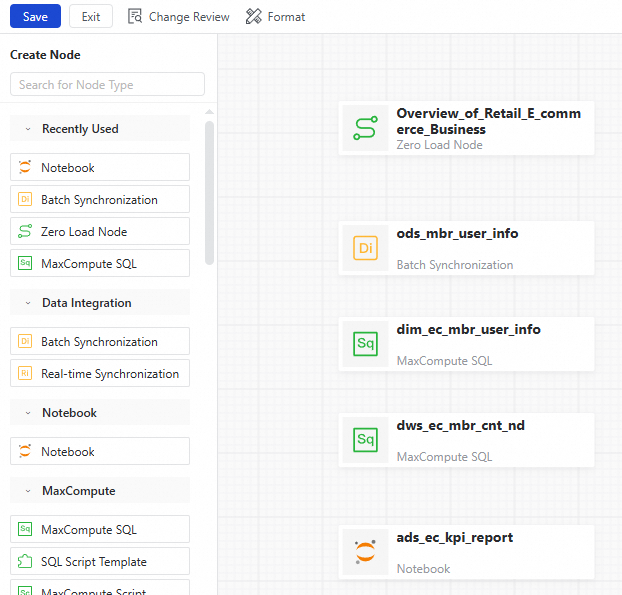
On the canvas, find the two nodes for which you want to create a dependency. Hover your mouse over the middle of the bottom edge of one node. When the pointer changes to a +, drag the arrow to the other node and release the mouse. After you set the dependency as shown in the figure, click Save on the top toolbar.
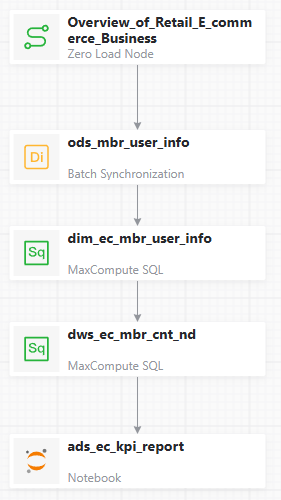
After clicking Save, you can adjust the canvas layout as needed.
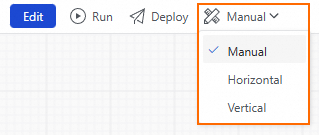
On the right side of the workflow canvas, click Scheduling Configuration. Use the Scheduling Configuration panel to configure the scheduling parameters and node dependencies for the workflow. In the Scheduling Parameters section, click Add Parameter. In the parameter name field, enter bizdate. From the parameter value drop-down list, select $[yyyymmdd-1].
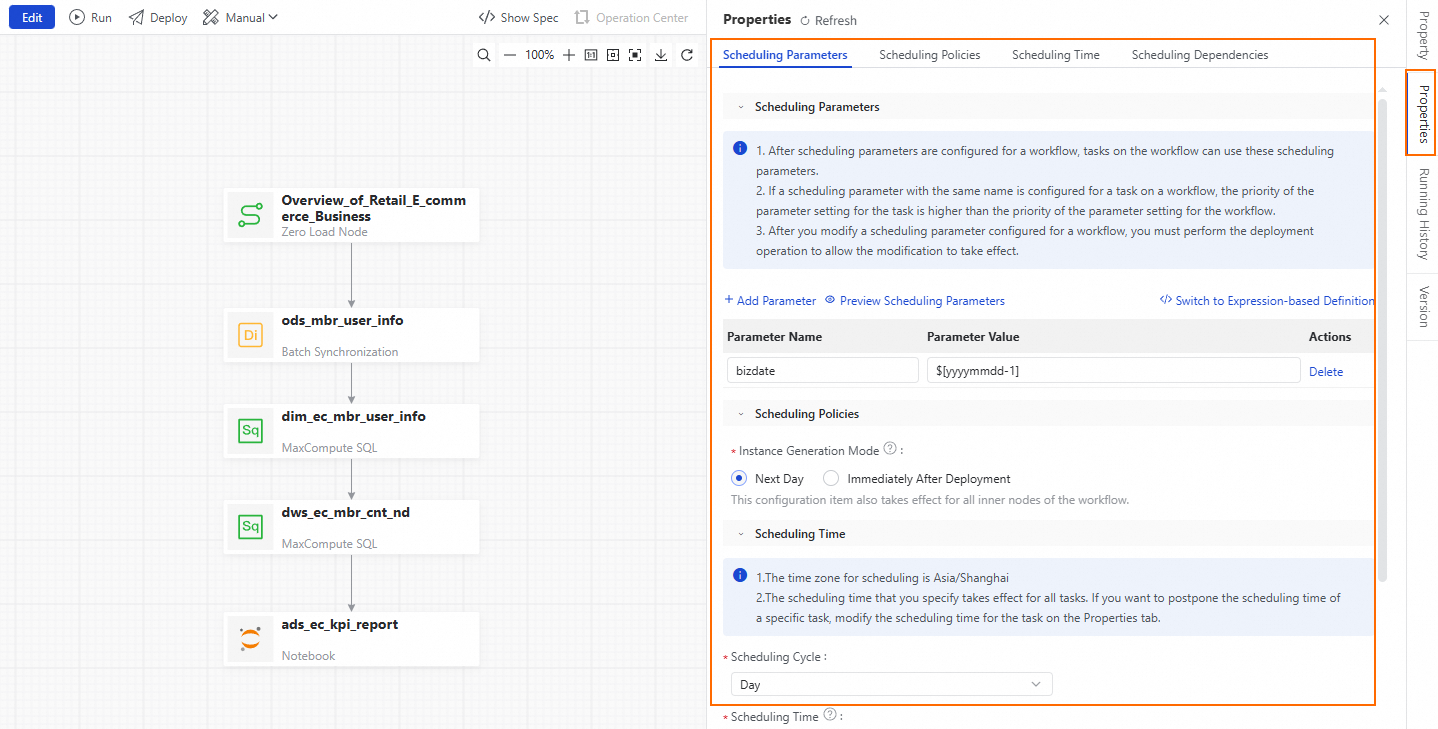
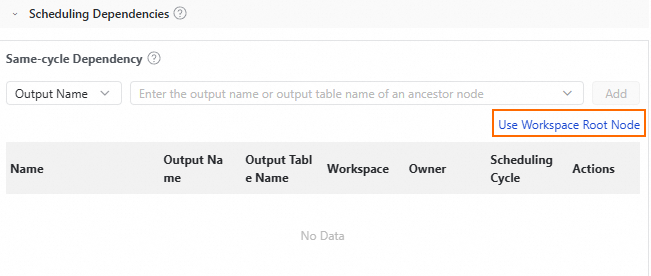
Click Use Workspace Root Node to set this node as the upstream dependency for the workflow.
Click Publish above the workflow canvas. The Publish Content panel appears in the lower-right corner. In the panel, click Start Publishing To Production and follow the prompts to confirm.

Step 3: Use multi-engine collaborative development
DataStudio supports data warehouse development for dozens of node types across different engines, such as Data Integration, MaxCompute, Hologres, EMR, Flink, Python, Notebook, and ADB. It supports complex scheduling dependencies and provides a development model that isolates the development environment from the production environment. This experiment uses the creation of a Flink SQL Streaming node as an example.
In DataStudio, click the
 icon in the navigation pane on the left to open the Data Development page. In the navigation pane, find Project Folder and click the
icon in the navigation pane on the left to open the Data Development page. In the navigation pane, find Project Folder and click the  icon next to it. In the cascading menu, click Flink SQL Streaming to open the node editor. Before the editor opens, enter a Node Name and press Enter.
icon next to it. In the cascading menu, click Flink SQL Streaming to open the node editor. Before the editor opens, enter a Node Name and press Enter.Preset node name:
ads_ec_page_visit_log.
In the node editor, paste the preset Flink SQL Stream code into the code editor.

In the node editor, click Real-time Configuration on the right side of the code editor to configure the Flink Resource Information, Script Parameters, and Flink Runtime Parameters.

After you configure the real-time settings, click Save above the code editor. Then click Publish. In the Publish Content panel that appears in the lower-right corner, click Start Publishing To Production and follow the prompts to confirm.

Step 4: Enter the personal development environment
The personal development environment supports custom container images, connecting to user NAS and Git, and programming in Python using Notebooks.
In DataStudio, click the ![]() icon at the top of the page. In the drop-down menu, select the personal development environment that you want to enter and wait for the page to load.
icon at the top of the page. In the drop-down menu, select the personal development environment that you want to enter and wait for the page to load.

Step 5: Program and debug in Python
DataWorks is deeply integrated with DSW. After you enter the personal development environment, DataStudio supports writing, debugging, running, and scheduling Python code.
You must complete Step 4: Enter the personal development environment before you start this step.
On the DataStudio page, in your personal developer environment, click the
workspacefolder. Click the icon to the right of Personal Folder. An untitled file appears in the list on the left. Name the file, press Enter, and wait for it to be generated.
icon to the right of Personal Folder. An untitled file appears in the list on the left. Name the file, press Enter, and wait for it to be generated.Preset file name:
ec_item_rec.py.
In the code editor on the Python file page, enter the preset Python code. Then, click Run Python File above the code editor and check the results in the Terminal at the bottom of the page.


To debug the code, click Debug Python File above the code editor or click the
 icon in the panel to the left of the code editor. You can set breakpoints by clicking to the left of the line numbers.
icon in the panel to the left of the code editor. You can set breakpoints by clicking to the left of the line numbers.
Step 6: Explore data with a Notebook
Notebook data exploration operations are performed in the personal development environment. You must complete Step 4: Enter the personal development environment before you begin.
Create a Notebook
Go to DataStudio > Data Development.
In the Personal Folder, right-click the target folder and select New Notebook.
Enter a name for the Notebook and press Enter or click a blank area on the page to apply the name.
In the personal folder, click the Notebook name to open it in the editor.
Use a Notebook
The following steps are independent and can be performed in any order.
Notebook multi-engine development
EMR Spark SQL
In the DataWorks Notebook, click the
 button to create a new SQL Cell.
button to create a new SQL Cell.In the SQL Cell, enter the following statement to query the dim_ec_mbr_user_info table.
In the lower-right corner of the SQL Cell, set the SQL Cell type to EMR Spark SQL and the computing resource to
openlake_serverless_spark.
Click the Run button, wait for the execution to complete, and view the data results.
StarRocks SQL
In the DataWorks Notebook, click the
 button to create a new SQL Cell.
button to create a new SQL Cell.In the SQL Cell, enter the following statement to query the dws_ec_trd_cate_commodity_gmv_kpi_fy table.
In the lower-right corner of the SQL Cell, set the SQL Cell type to StarRocks SQL and the computing resource to
openlake_starrocks.
Click the Run button, wait for the execution to complete, and view the data results.
Hologres SQL
In the DataWorks Notebook, click the
button to create a new SQL Cell.In the SQL Cell, enter the following statement to query the dws_ec_mbr_cnt_std table.
In the lower-right corner of the SQL Cell, set the SQL Cell type to Hologres SQL and the computing resource to
openlake_hologres.
Click the Run button, wait for the execution to complete, and view the data results.
MaxCompute SQL
In the DataWorks Notebook, click the
button to create a new SQL Cell.In the SQL Cell, enter the following statement to query the dws_ec_mbr_cnt_std table.
In the lower-right corner of the SQL Cell, set the SQL Cell type to MaxCompute SQL and the computing resource to
openlake_maxcompute.
Click the Run button, wait for the execution to complete, and view the data results.
Notebook interactive data
In the DataWorks Notebook, click the
 button to create a new Python Cell.
button to create a new Python Cell.In the upper-right corner of the Python Cell, click the
 button to open the DataWorks Copilot intelligent programming assistant.
button to open the DataWorks Copilot intelligent programming assistant.In the DataWorks Copilot input box, enter the following requirement to generate an ipywidgets interactive component for querying member age.
NoteDescription: Use Python to generate a slider widget for member age. The value range is from 1 to 100, with a default value of 20. Monitor changes to the widget's value in real time and save the value to a global variable named query_age.
Review the Python code generated by DataWorks Copilot and click the Accept button.

Click the run button for the Python Cell, wait for the execution to complete, and view the generated interactive component. You can run the code generated by Copilot or the preset code. You can also slide the interactive component to select the target age.

In the DataWorks Notebook, click the
 button to create a new SQL Cell.
button to create a new SQL Cell.In the SQL Cell, enter the following query statement, which includes the member age variable
${query_age}defined in Python.SELECT * FROM openlake_win.default.dim_ec_mbr_user_info WHERE CAST(id_age AS INT) >= ${query_age};In the lower-right corner of the SQL Cell, set the SQL Cell type to Hologres SQL and the computing resource to
openlake_hologres.
Click the Run button, wait for the execution to complete, and view the data results.
In the results, click the
 button to generate a chart.
button to generate a chart.
Notebook model development and training
In the DataWorks Notebook, click the
button to create a new SQL Cell.In the SQL Cell, enter the following statement to query the ods_trade_order table.
SELECT * FROM openlake_win.default.ods_trade_order;Write the SQL query result to a DataFrame variable. Click the df location and enter a custom DataFrame variable name, such as
df_ml.
Click the Run button for the SQL Cell, wait for the execution to complete, and view the data results.
In the DataWorks Notebook, click the
 button to create a new Python Cell.
button to create a new Python Cell.In the Python Cell, enter the following statement to clean and process the data using Pandas and store it in a new DataFrame variable named
df_ml_clean.import pandas as pd def clean_data(df_ml): # Generate a new column: estimated order total = item price * quantity df_ml['predict_total_fee'] = df_ml['item_price'].astype(float).values * df_ml['buy_amount'].astype(float).values # Rename the 'total_fee' column to 'actual_total_fee' df_ml = df_ml.rename(columns={'total_fee': 'actual_total_fee'}) return df_ml df_ml_clean = clean_data(df_ml.copy()) df_ml_clean.head()Click the Run button for the Python Cell, wait for the execution to complete, and view the data cleaning results.
In the DataWorks Notebook, click the
button to create a new Python Cell.In the Python Cell, enter the following statement to build, train, and test a linear regression machine learning model.
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # Get item price and total fee X = df_ml_clean[['predict_total_fee']].values y = df_ml_clean['actual_total_fee'].astype(float).values # Prepare the data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05, random_state=42) # Create and train the model model = LinearRegression() model.fit(X_train, y_train) # Predict and evaluate y_pred = model.predict(X_test) for index, (x_t, y_pre, y_t) in enumerate(zip(X_test, y_pred, y_test)): print("[{:>2}] input: {:<10} prediction:{:<10} gt: {:<10}".format(str(index+1), f"{x_t[0]:.3f}", f"{y_pre:.3f}", f"{y_t:.3f}")) # Calculate the mean squared error (MSE) mse = mean_squared_error(y_test, y_pred) print("Mean Squared Error (MSE):", mse)Click the Run button, wait for the execution to complete, and view the model training test results.