A data quality monitoring node lets you configure monitoring rules to check the quality of tables in a data source — detecting dirty data, validating row counts, checking null values, and more. The node runs as part of your scheduling pipeline and automatically blocks downstream tasks when data quality issues are detected, preventing dirty data from propagating through your Extract, Transform, and Load (ETL) pipeline.
How it works
After a data quality monitoring node runs, it evaluates each configured rule against the monitored table. If a rule check returns an anomaly, the node applies your handling policy: either stop the current node (blocking downstream tasks) or continue while sending an alert.
Limitations
-
Supported data sources: MaxCompute, E-MapReduce, Hologres, CDH Hive, AnalyticDB for PostgreSQL, AnalyticDB for MySQL, and StarRocks
-
One table per node: Each node monitors one table, but you can configure multiple monitoring rules for the node. To monitor multiple tables, create multiple data quality monitoring nodes.
-
Workspace binding: Monitored tables must belong to a data source bound to the same workspace as the node.
-
Partition monitoring: For partitioned tables, specify a partition filter expression. For non-partitioned tables, the entire table is monitored by default.
-
Rules managed in DataStudio only: Rules created in DataStudio can be run, modified, published, and managed only in DataStudio. In the Data Quality module, you can view these rules but cannot trigger scheduled runs or manage them there.
-
Publishing replaces rules: If you modify monitoring rules in a node and republish the node, the original monitoring rules are replaced.
Prerequisites
Before you begin, ensure that you have:
-
A business flow created in Data Development (DataStudio). For more information, see Create a business flow.
-
A data source created and bound to the current workspace, with the target table already created in the data source. For more information, see Data Source Management, Resource Management, and Node development.
-
A Serverless resource group created. Data quality monitoring nodes run only on Serverless resource groups. For more information, see Resource Management.
-
(Optional, for RAM users) The Resource Access Management (RAM) user for task development added to the workspace with the Development or Workspace Manager role. The Workspace Administrator role has extensive permissions and must be granted with caution. For more information, see Add workspace members.
Step 1: Create a data quality monitoring node
-
Log on to the DataWorks console. In the top navigation bar, select the target region. In the left-side navigation pane, choose Data Development and O\&M \> Data Development. Select the target workspace from the drop-down list and click Go to Data Development.
-
In DataStudio, right-click the target business flow and choose Create Node \> Data Quality \> Data Quality Monitoring.
-
In the Create Node dialog box, enter a name and click Confirm.
Step 2: Configure monitoring rules
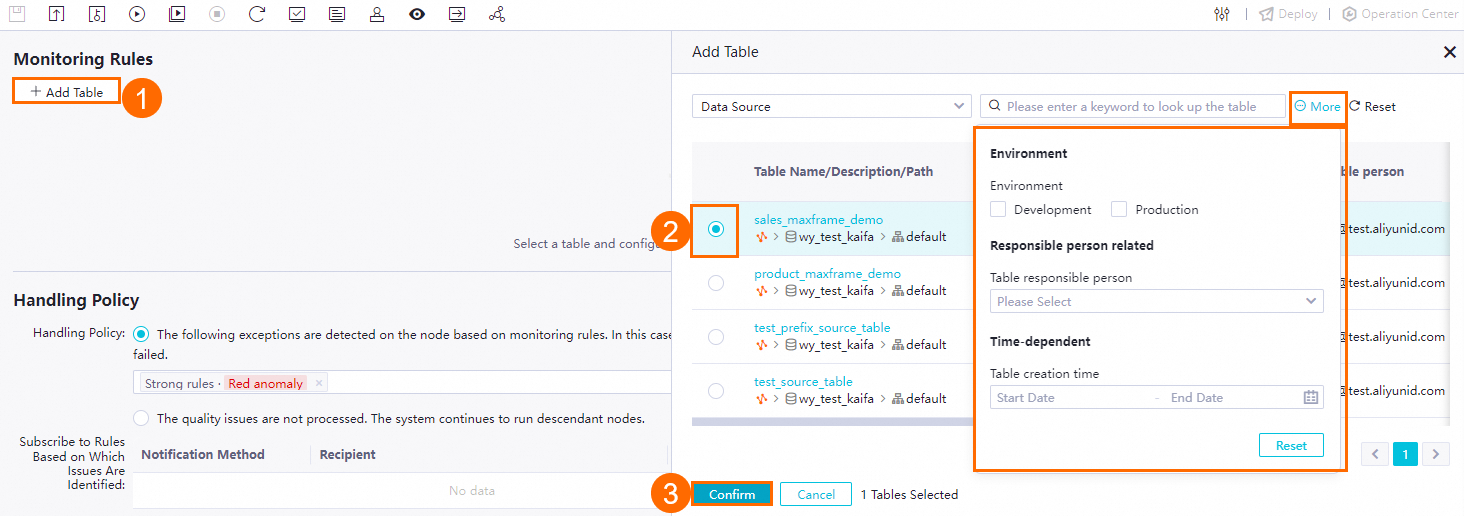
1. Select the table to monitor
Click Add Table. In the Add Table dialog box, search for and select the target table.
2. Set the data range
-
Non-partitioned tables: The entire table is monitored by default. Skip this step.
-
Partitioned tables: Select the partition to monitor. Use scheduling parameters if needed. Click Preview to verify the partition filter expression result.

3. Create or import rules
Configured rules are enabled by default. Create new rules or import existing ones.
Create a rule
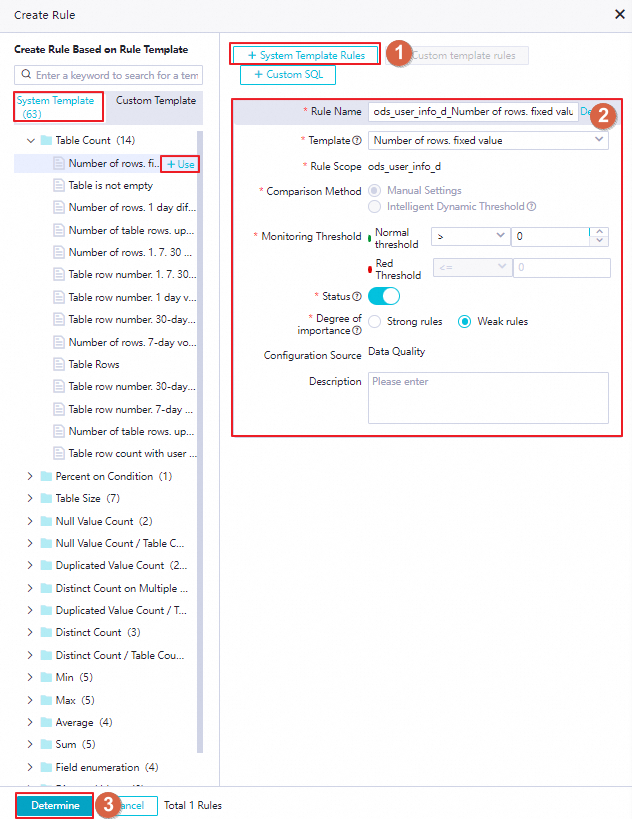
Click Create Rule to create a monitoring rule from a template or a custom SQL statement.
From a system template
The platform provides built-in table-level and field-level rule templates. Select a template to create a rule quickly. You can also find a template in the system template list on the left and click +Use.
From a custom template
Before using this method, go to Data Quality \> Quality Assets \> Rule Template Library to create a custom rule template. Then create a monitoring rule based on that template. For more information, see Create and manage custom rule templates.
You can also find a custom template in the template list on the left and click +Use.

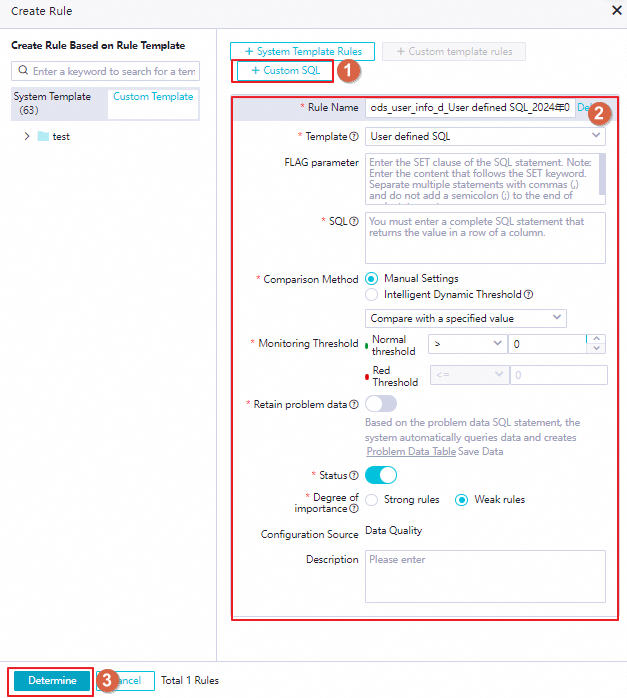
From a custom SQL statement
This method lets you define custom check logic directly without a template.
Import existing rules
If monitoring rules for the target table already exist in the Data Quality module, import them to quickly clone those rules. If no rules exist, you must first create them in the Data Quality module. For more information, see Configure rules for a single table. This supports batch import of both table-level and field-level rules.
Click Import Rule. Search for and select rules to import by rule ID or name, rule template, or associated scope.

After you publish a data quality monitoring node, rule details are visible in the Data Quality module, but management operations such as modifying or deleting rules are not available there.
4. Configure compute resources
Step 3: Configure a handling policy
In the Handling policy section of the node configuration page, configure how the node responds to check anomalies and how notifications are delivered.
Exception categories and handling policy
Notification settings
Step 4: Configure scheduling
To run the node periodically, click Properties in the right-side pane and configure the scheduling properties. For more information, see Configure scheduling properties for a node.
Set the Rerun and Parent nodes properties before submitting the node.
Step 5: Debug the task
-
(Optional) Select a resource group and assign values to scheduling parameters. Click the
 icon in the toolbar. In the Parameters dialog box, select the scheduling resource group and assign values to any scheduling parameters used by the task. For more information, see Task debugging process.
icon in the toolbar. In the Parameters dialog box, select the scheduling resource group and assign values to any scheduling parameters used by the task. For more information, see Task debugging process.
-
Save and run the task. Click the
 icon to save the task, then click the
icon to save the task, then click the  icon to run it. After the run completes, view the results at the bottom of the node configuration page. If the run fails, check the error message to troubleshoot.
icon to run it. After the run completes, view the results at the bottom of the node configuration page. If the run fails, check the error message to troubleshoot. -
(Optional) Perform smoke testing. To verify that the scheduling node task runs as expected in the development environment, perform smoke testing when you submit the node or after submission. For more information, see Perform smoke testing.
Step 6: Submit and publish the task
When you submit and publish the node, the configured quality rules are also submitted and published. After publishing, the node runs periodically according to its scheduling configuration.
-
Click the
 icon to save the node.
icon to save the node. -
Click the
 icon to submit the node. In the Submit dialog box, enter a Change description. If needed, select whether to perform a code review after submission.
icon to submit the node. In the Submit dialog box, enter a Change description. If needed, select whether to perform a code review after submission.Set the Rerun and Parent nodes properties before submitting. Code review helps ensure configuration quality — a submitted node can be published only after a reviewer approves it. For more information, see Code review.
-
If using a workspace in standard mode, click Deploy in the upper-right corner of the node configuration page to publish the task to the production environment. For more information, see Publish tasks.
What's next
-
Task O\&M: After the task is published, it runs periodically. Click Operation Center in the upper-right corner of the node configuration page to view the scheduling and running status of the auto triggered task, including node status and triggered rule details. For more information, see Manage auto triggered tasks.
-
Data Quality: After quality rules are published, go to the Data Quality module to view rule details. Management operations such as modifying or deleting rules are not available there. For more information, see Data Quality.