DataWorks empowers companies across multiple industries to overcome data challenges and unlock the full value of their data. Explore these success stories to see how customers are building innovative solutions with DataWorks.
New retail: Cloud data mid-end for RT-Mart
-
Background
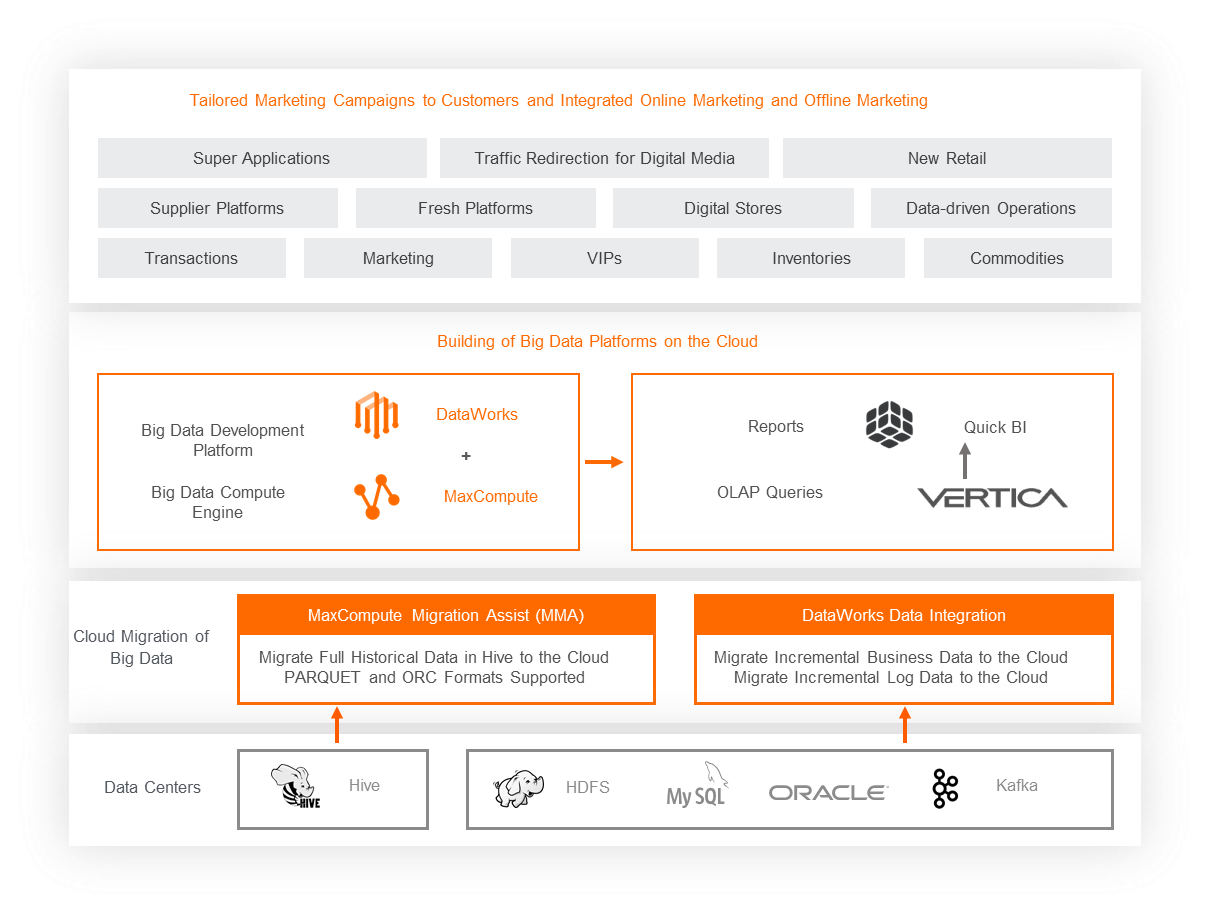
To accelerate its digital transformation and embrace the new retail landscape, RT-Mart planned to migrate its entire IT system to Alibaba Cloud within two years, moving away from self-managed data centers. At the same time, it partnered with Alibaba Cloud to launch a data mid-end project. This initiative aimed to reduce the total cost of ownership (TCO) and use the cloud ecosystem to convert data into business value.
-
The challenge
-
Its existing Hadoop-based system had high maintenance costs and persistent stability issues, severely impacting business operations and analysis.
-
Due to rapid growth in its online business, the company faced a significant backlog of requests. It needed a comprehensive solution that could flexibly and rapidly scale to support its evolving technical requirements.
-
-
The solution and benefits
Using MaxCompute Migration Assist (MMA), RT-Mart seamlessly migrated over 400 TB of historical data in just 15 days, ensuring high accuracy and a smooth cloud adoption experience. By building on the Apsara big data platform with DataWorks and MaxCompute, the company significantly improved its data development efficiency and established a robust data mid-end.
Fintech: Data lakehouse for an internet finance company
-
Background
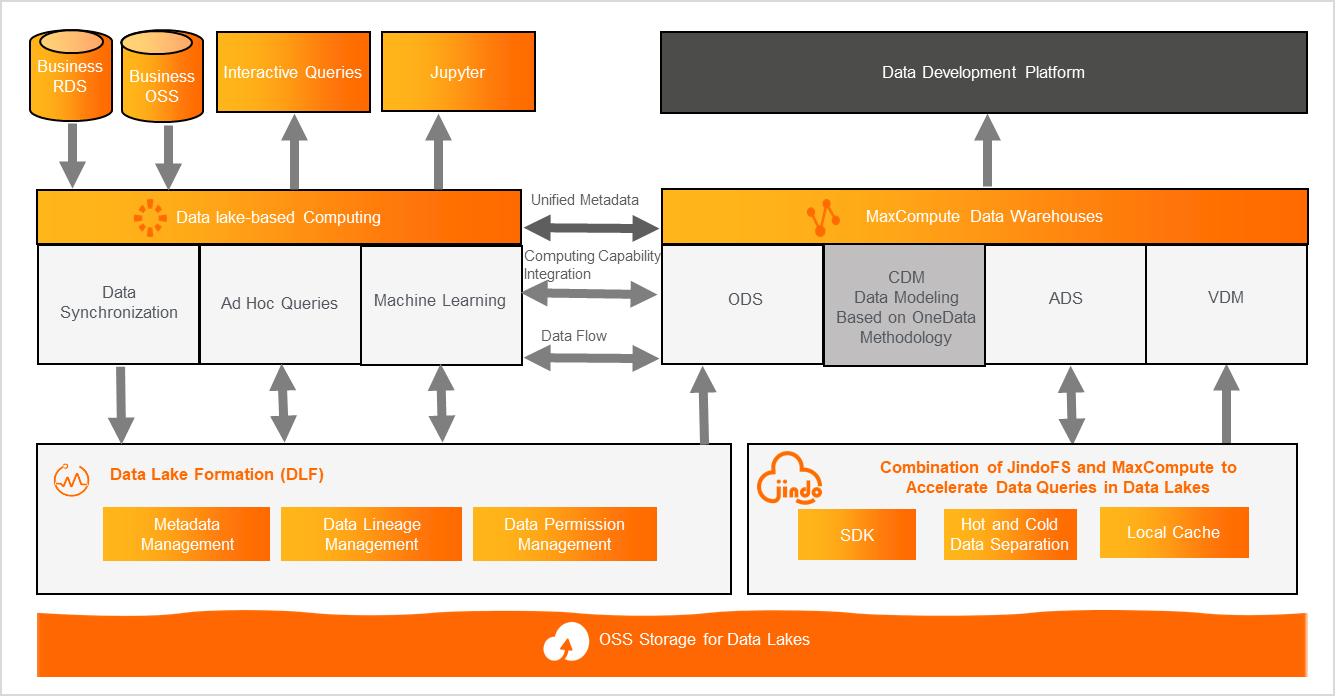
The company's first-generation data lake was built on Hadoop and OSS. However, its data mid-end used MaxCompute as its execution and storage engine. This use of two heterogeneous systems led to redundant storage, inconsistent metadata and permissions, and hindered data and computation sharing between the data lake and the data warehouse.
-
The challenge
As shown in the architecture diagram, MaxCompute and E-MapReduce engines were used for different business scenarios. The company needed to use Alibaba Cloud's Data Lake Formation (DLF) to unify metadata and permission management. They also aimed to implement end-to-end data governance with DataWorks to improve data quality and usability.
-
The solution and benefits
-
The solution centralized metadata from E-MapReduce into DLF and used OSS for unified storage. By building a data lakehouse architecture, it connected the E-MapReduce-based data lake with the MaxCompute-based data warehouse, allowing data and compute resources to move freely between them.
-
The solution implemented tiered storage across the lakehouse. The data mid-end stored dimensional modeling intermediate tables for data lake data in MaxCompute, while E-MapReduce or other engines consumed the ADS layer.
-
New energy: End-to-end data governance for an energy company using DataWorks
-
Background
-
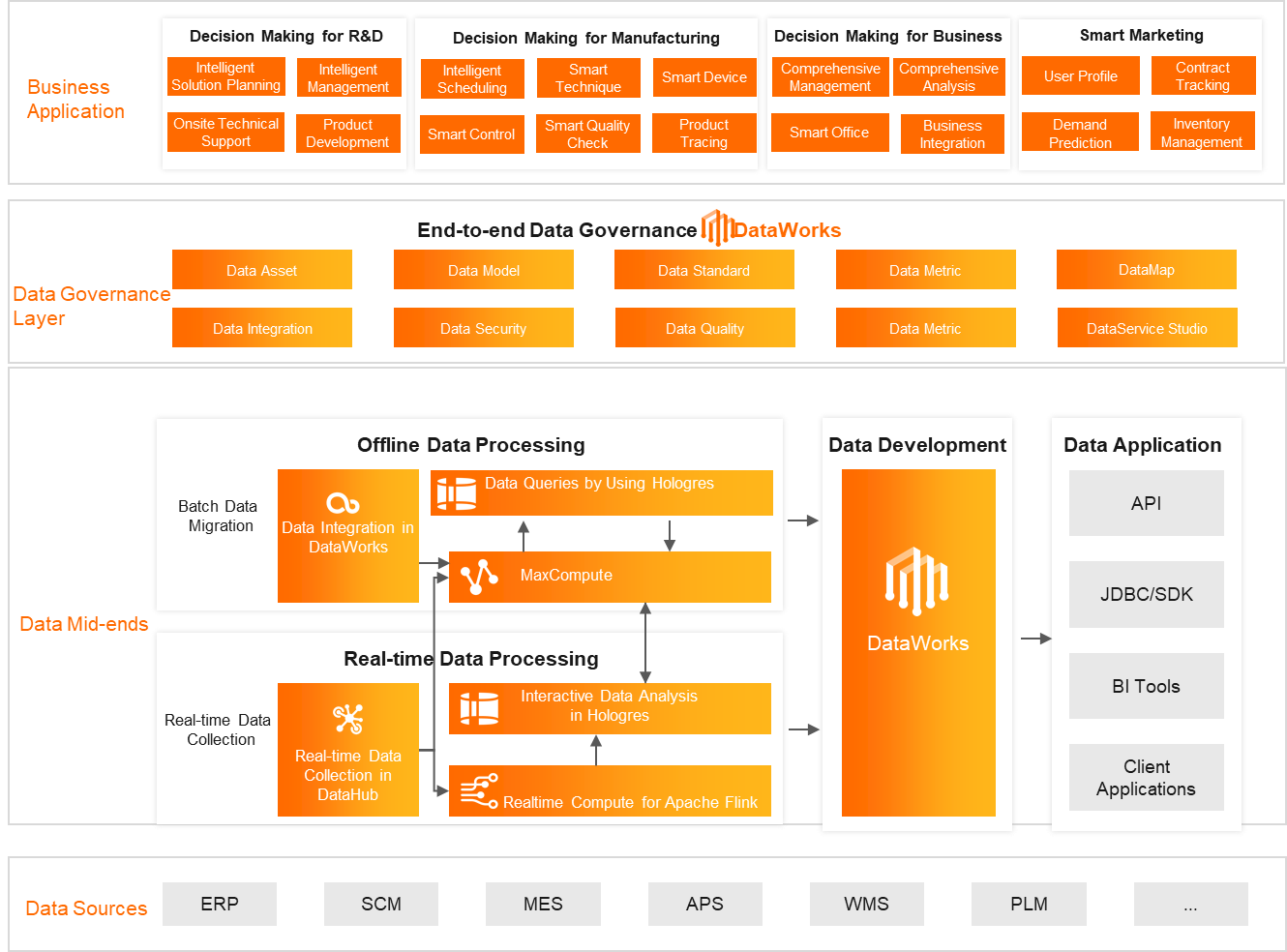
Multiple subsidiaries had accumulated a large number of systems over the years, resulting in complex and diverse technology stacks.
-
Data was scattered across systems with inconsistent data standards, causing gaps between datasets and making effective analysis impossible.
-
Data management responsibilities were unclear, data governance was lacking, and no effective data sharing mechanism was in place.
-
-
The challenge
-
Build a data mid-end with DataWorks and MaxCompute to break down data silos.
-
Improve the real-time capabilities of the data mid-end with Realtime Compute and MaxCompute interactive analytics (Hologres).
-
Implement end-to-end data governance with DataWorks to improve data quality and usability.
-
-
The solution and benefits
-
Built a B2B smart marketing system to enable the implementation of an intelligent manufacturing plus internet model.
-
Built a unified batch-and-real-time data mid-end with a complete big data application pipeline to serve multiple core business units.
-
End-to-end data governance improved data usability, enabling data to flow freely within the mid-end while ensuring accuracy, timeliness, and consistency, resulting in cost savings of CNY 100 million.
-
Improved business iteration efficiency by reducing the data refresh interval from one day to 10 minutes and the time to launch new requirements from one week to one day.
-
Internet: Cloud data warehouse for GoGoX 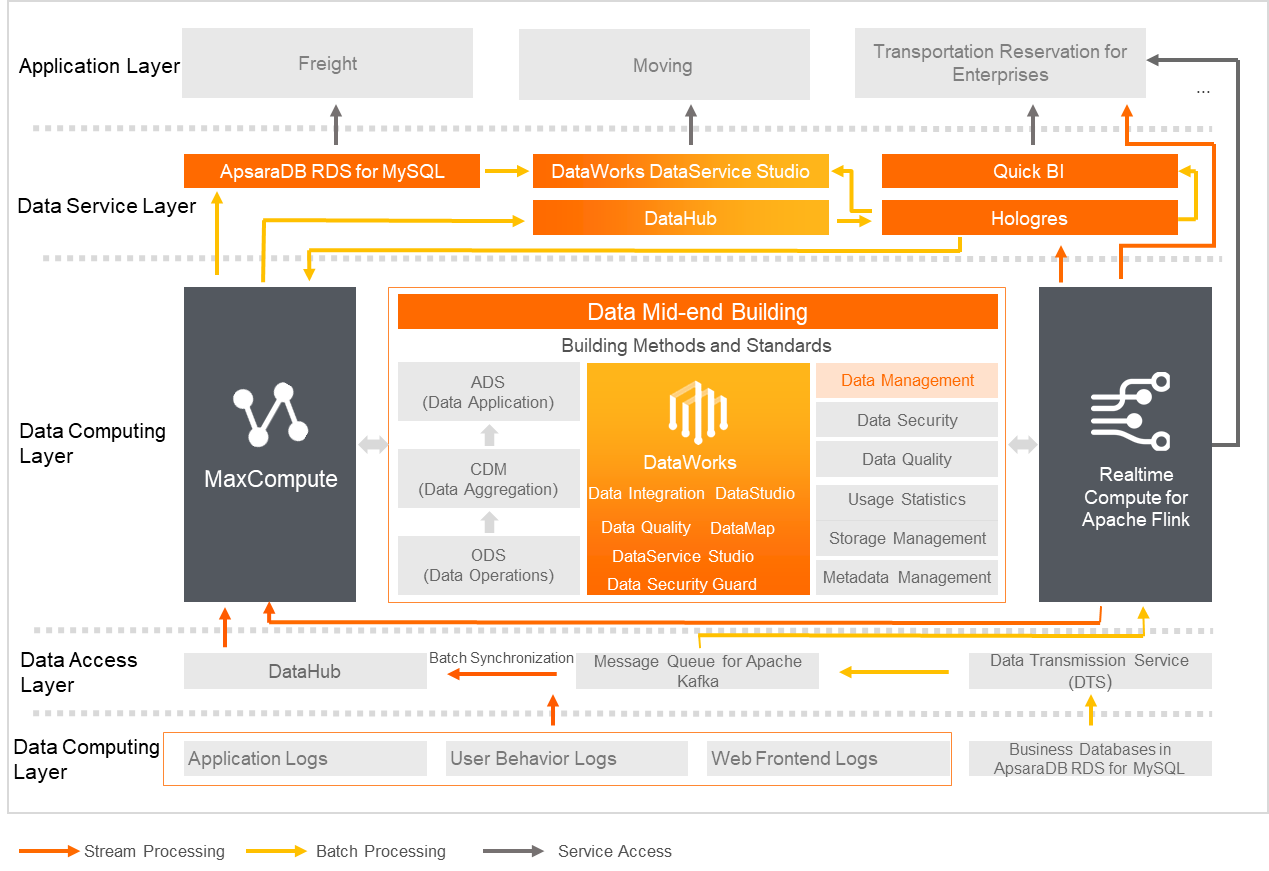
-
Background
GoGoX has been committed to digital solutions such as network connectivity, shared transport capacity, data-driven processes, and intelligent matching. The company consolidates fragmented transport capacity onto its platform and uses big data to precisely match capacity with market demand, achieving energy savings, reducing empty-run rates, effectively improving industry efficiency, and actively promoting green logistics.
-
The challenge
-
Processing efficiency for massive data volumes was declining, and offline data computation durations were unstable.
-
Real-time computing had high development and maintenance costs, and comprehensive data warehouse governance was needed.
-
-
The solution and benefits
By leveraging the Apsara big data platform, GoGoX reduced infrastructure costs by over 30% and doubled data development efficiency. Migrating from Java Storm to Flink SQL significantly shortened real-time computing development cycles, simplified maintenance, and improved data consistency, enhancing the accuracy and timeliness of business monitoring dashboards. Users can focus more on business logic, accelerating real-time business transformation. Additionally, Alibaba Cloud's 24/7 operations support ensured cluster stability with zero downtime.
Internet: Cloud data warehouse for Babytree 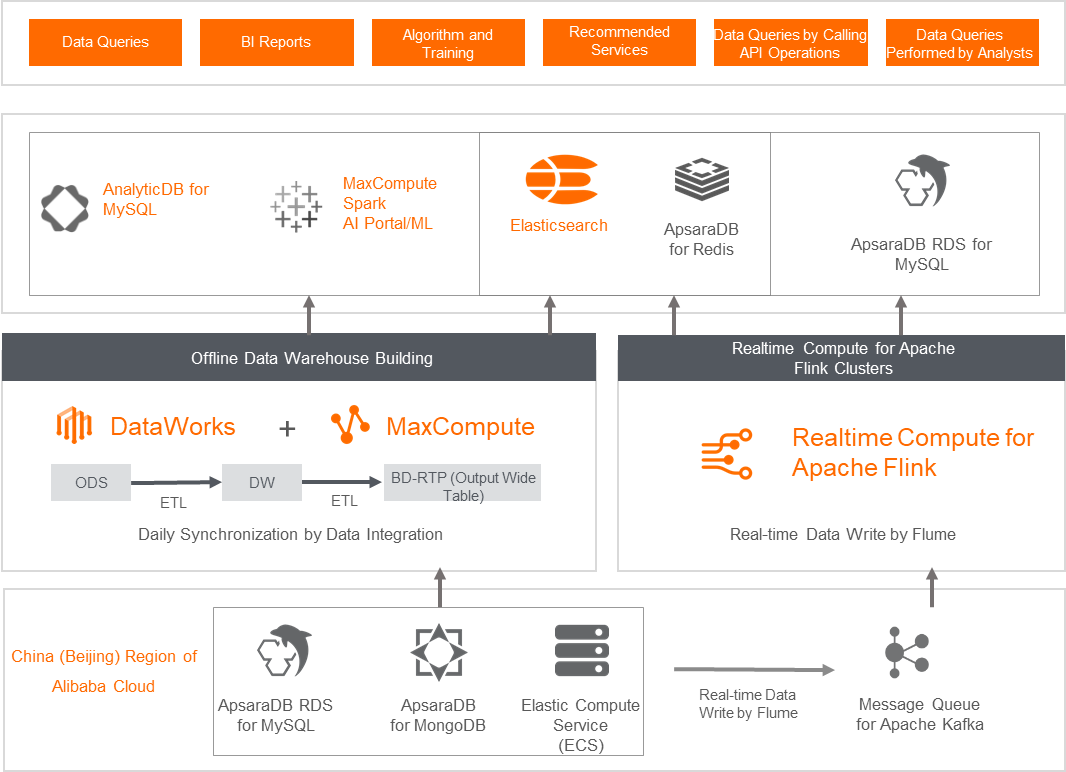
-
Background
Founded in 2007, Babytree is China's largest and most active parenting community platform. As one of the earliest internet B2C community platforms, Babytree built its own IDC clusters early on, and the scale continued to grow.
-
The challenge
-
Cluster utilization was high, performance was poor, and comprehensive big data governance was urgently needed.
-
Annual investment in IDC-based big data infrastructure was high, and the company wanted to reduce costs and improve efficiency.
-
-
The solution and benefits
Starting with an overall cloud migration strategy focused on cost reduction and efficiency improvement, the migration to MaxCompute, Realtime Compute, and DataWorks delivered over 10x performance improvements for certain tasks. Storage was reduced from 3 PB on self-managed Hadoop to 900 TB. By leveraging Flink's real-time data processing capabilities, Babytree enabled real-time scenarios such as real-time user behavior tracking by user ID and content type, real-time group chat ID retrieval, and real-time article publishing information retrieval. Flink-based real-time recommendations also increased conversion rates. Overall big data platform costs were reduced by over 30%.
Gaming: Full-pipeline operations for DeNA China 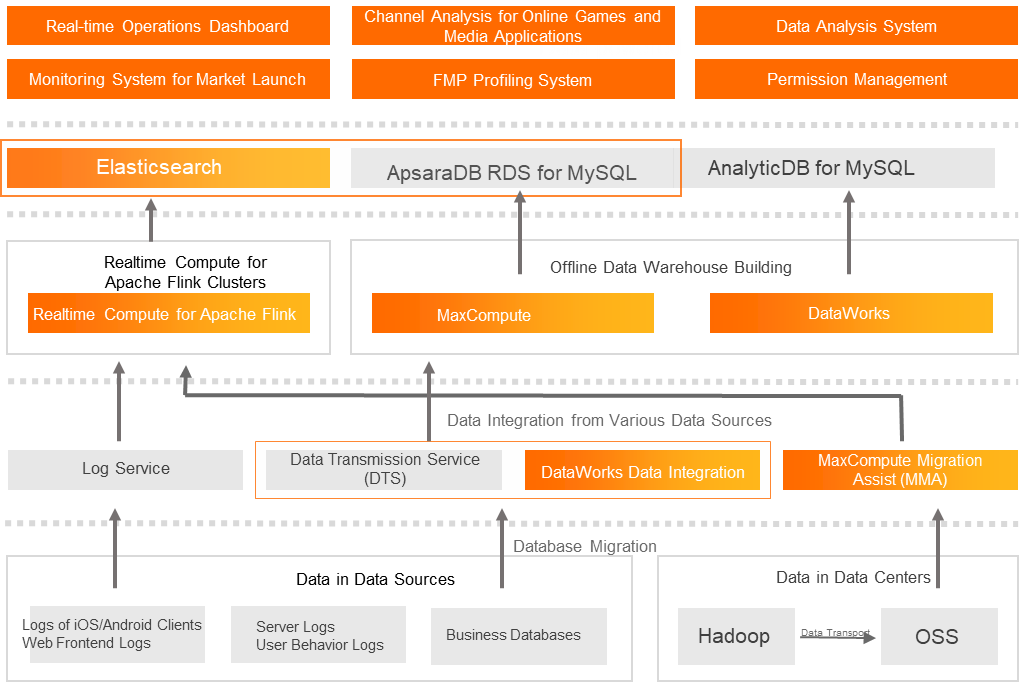
-
Background
DeNA is a leading internet services company. As game project lifecycles become shorter, every phase requires real-time and precise control, creating the need for a cost-effective and efficient data operations system.
-
The challenge
-
The company operated two Hadoop clusters (1.0 and 2.0) with a complex architecture, and was hitting bottlenecks in platform stability, security, and elastic scalability.
-
Log sources were diverse and required high real-time capability. The fluentd-based file collection service faced significant performance and stability bottlenecks as log volumes grew.
-
Manual script-based data development led to low business support efficiency, and Hive's computing performance could not meet requirements.
-
-
The solution and benefits
DeNA China was the first gaming company to use Lightning Cube and MMA tools. Without a dedicated network connection, the company completed the migration of 300 TB+ of incremental RDS data accumulated over 10 years and 50 TB of historical data in just over one month, a project of considerable technical complexity. Compared to the previous Python-based open-source Airflow task management system, DataWorks offers the following advantages:
-
Task management is clear at a glance, with quick error identification and instant navigation to the relevant task code for fixes.
-
With hundreds of data sources for gaming operations, a one-time setup allows reuse across multiple data service requirements, eliminating redundant work.
-
Overall technology abstraction means that resource scheduling and other infrastructure tasks require no extra effort or additional coding, allowing the team to focus on development and management.
After migration, the Apsara big data platform covered the full gaming data operations pipeline from data collection > storage & computing > real-time/batch analysis.
-