Data Integration allows you to specify a filter condition for a batch synchronization node to enable the node to synchronize only incremental data. If you specify a filter condition when you configure a batch synchronization node, only the data that meets the filter condition can be synchronized. You can use a filter condition together with scheduling parameters. This way, the filter condition can dynamically change with the settings of the scheduling parameters, and incremental data can be synchronized. This topic describes how to configure a batch synchronization node to synchronize only incremental data.
Usage notes
- Incremental synchronization is not supported for some types of data sources, such as HBase and OTSStream data sources. You can refer to the topics that introduce the Reader plug-ins of the related data sources to check whether incremental synchronization is supported.
- The parameters that you must configure vary based on the Reader plug-ins that you
use to synchronize incremental data. For more information, see Supported data source types, readers, and writers. The following table provides examples.
Reader plug-in Parameter required for incremental synchronization Supported syntax MySQL Reader where Note If you use the codeless UI to configure a batch synchronization node that uses MySQL Reader, you must configure the Filter parameter.Use the syntax of the related database. Note You can use the filter condition together with scheduling parameters to read the data that is generated during a specified period of time every day.MongoDB Reader query Note If you use the codeless UI to configure a batch synchronization node that uses MongoDB Reader, you must configure the Search Condition parameter.Use the syntax of the related database. Note You can use the filter condition together with scheduling parameters to read the data that is generated during a specified period of time every day.OSS Reader Object Specify the object path. Note You can use the filter condition together with scheduling parameters to read data from specified objects every day.... ... ...
Configure a batch synchronization node to synchronize only incremental data
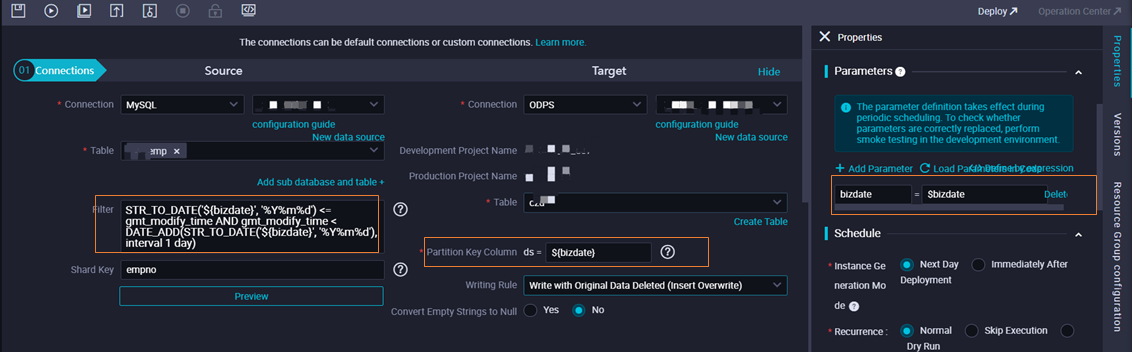
If you use a batch synchronization node to synchronize data, you can configure scheduling parameters for the node to specify the path and scope of the data that you want to synchronize and the location to which you want to write the data. The method used to configure scheduling parameters for a batch synchronization node is the same as the method used to configure scheduling parameters for other types of nodes.
When a batch synchronization node is run, the scheduling parameters configured for the node are replaced with the actual values based on the value formats of the scheduling parameters. Then, the batch synchronization node synchronizes data based on the values.
- If you do not specify a filter condition when you configure the node, the node automatically synchronizes all data from the source to the destination.
- If you specify a filter condition when you configure the node, the node synchronizes only the data that meets the filter condition to the destination.
 Before you configure a batch synchronization node to synchronize only incremental
data, take note of the following items:
Before you configure a batch synchronization node to synchronize only incremental
data, take note of the following items:
- If you want to synchronize incremental data of a time data type, you can use scheduling parameters when you specify a filter condition for the node. This way, when the node is scheduled, the scheduling parameters are replaced with the actual values based on the data timestamp of the node. For more information about scheduling parameters, see Overview of scheduling parameters.
- If you want to synchronize incremental data of a data type other than time, you can use an assignment node to convert the data type of the source fields to the data type supported by the destination and then transmit the processed data to Data Integration for data synchronization. For more information about how to use an assignment node, see Configure an assignment node.
Sample scenarios
- Synchronize historical incremental data: If you want to synchronize historical incremental data from a source table to the related time partition in a destination table, you can use the data backfill feature provided in Operation Center. For more information about the data backfill feature, see Backfill data for an auto triggered node and view data backfill instances generated for the node.
- Synchronize incremental data from ApsaraDB RDS to MaxCompute