This topic describes the factors that affect the speed of data synchronization and how to adjust the parallelism for synchronization tasks to maximize the synchronization speed. This topic also describes bandwidth throttling settings and slow data synchronization scenarios.
Overview
The speed of data synchronization is affected by many factors such as the synchronization task configurations, database performance, and network. For more information, see Factors that affect the speed of data synchronization.
The slow speed of a data synchronization task may occur at different phases of the synchronization process. This topic describes the possible problems in different phases and the solutions to these problems. For more information, see Scenarios and solutions to slow data synchronization.
If the data synchronization performance of a database is limited, faster data synchronization is not necessarily good for the database and may overstress the database and affect the production. Data Integration provides the Bandwidth Throttling parameter, which can be used to control the data synchronization speed. You can configure this parameter based on your business requirements. For more information, see Limit the synchronization speed.
Factors that affect the speed of data synchronization
The speed of data synchronization is affected by many factors such as the source database, destination database, and synchronization task configurations. The factors that you can adjust and optimize are the source database performance, destination database performance, database loads, and network.
The following table describes the factors that affect the speed of data synchronization.
Factor | Description |
Source |
|
Resource group for scheduling used to run a synchronization task | A resource group for scheduling is used to issue a synchronization task to a resource group for Data Integration for running. The usage of the resource group for scheduling affects the overall synchronization efficiency of the synchronization task. |
Configurations of a synchronization task |
|
Destination |
|
Scenarios and solutions to slow data synchronization
For more information about logs of batch synchronization tasks, see Analyze batch synchronization logs.
Scenario | Problem description | Possible cause | Solution |
Wait for scheduling resources |
| A resource group for scheduling is used to issue the synchronization task to a compute engine instance for running. Therefore, if the number of synchronization tasks that are run in parallel on the resource group for scheduling reaches the upper limit, the current task must wait until the synchronization tasks finish running and the resources used by the tasks are released. | On the Intelligent Diagnosis page, you can view the information about the tasks that are using the resources of the resource group while the current task is waiting for resources. Note If you use the shared resource group for scheduling, we recommend that you migrate the task to an exclusive resource group for scheduling or serverless resource groups for running. |
Wait for resources in a resource group for Data Integration | The logs of a synchronization task show that the task is in the WAIT state. | The remaining resources in the resource group for Data Integration that you want to use to run the current synchronization task are insufficient to run the task. For example, a resource group for Data Integration supports a maximum of eight parallel threads. Three synchronization tasks are configured to run on the resource group for Data Integration. Three parallel threads are configured for each of the synchronization tasks. If two of the tasks are run in parallel on the resource group, the resource group for Data Integration can support two more parallel threads. In this case, the remaining task has to wait for resources in the resource group due to insufficient resources, and the logs of the task show that the task is in the WAIT state. | You can use one of the following methods to resolve the issue that other synchronization tasks in the resource group for Data Integration are using a large number of resources: Note
|
Slow data synchronization speed | The logs of a synchronization task show that the task is in the RUN state but the data synchronization speed is 0. If the synchronization task is running but remains in such a state for an extended period of time, we recommend that you click the link to the right of Detail log url to view the execution details of the task. |
Note If you synchronize data over the Internet, the data synchronization speed cannot be ensured. |
|
The logs of a synchronization task show that the task is in the RUN state but the data synchronization speed is 0. If the synchronization task is running but remains in such a state for an extended period of time, we recommend that you click the link to the right of Detail log url to view the execution details of the task. |
Note If you synchronize data over the Internet, the data synchronization speed cannot be ensured. | ||
The logs of a synchronization task show that the task is in the RUN state but the data synchronization speed is slow. |
Note If you synchronize data over the Internet, the data synchronization speed cannot be ensured. |
|
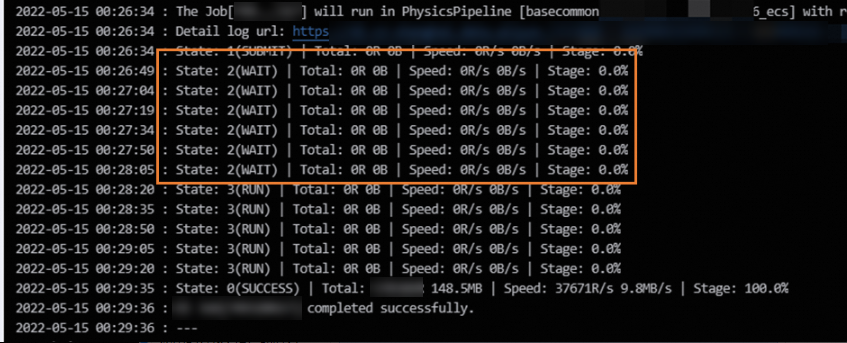

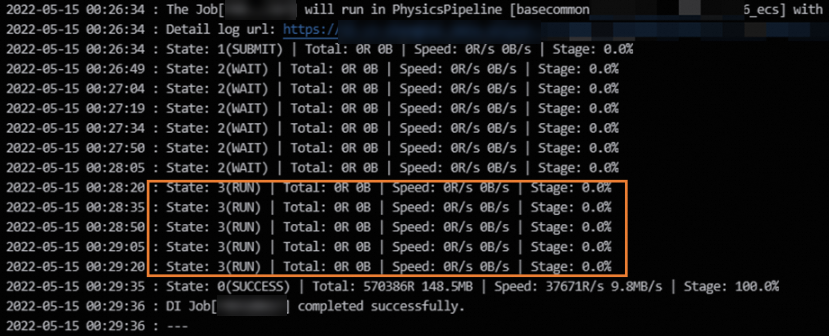 If the value of the
If the value of the 


Limit the synchronization speed
By default, bandwidth throttling is disabled. In a synchronization task, data is synchronized at the maximum transmission rate given the parallelism that is configured for the task. Excessively fast synchronization may overstress the database and thus affect the production. Therefore, Data Integration allows you to limit the synchronization speed and optimize the configuration based on your business requirements. If bandwidth throttling is enabled, we recommend that you limit the maximum transmission rate to 30 MB/s. The following example shows how to configure an upper limit for the synchronization speed in the code editor, in which the transmission rate is 1 MB/s:
"setting": {
"speed": {
"throttle": true // Indicates that bandwidth throttling is enabled.
"mbps": 1, // The synchronization speed.
}
}The valid values of the throttle parameter are true and false.
If you set the throttle parameter to true, bandwidth throttling is enabled. In this case, you must configure the mbps parameter. If you do not configure the mbps parameter, an error is returned when the synchronization task is run or data is synchronized at an abnormal speed.
If you set the throttle parameter to false, bandwidth throttling is disabled, and you do not need to configure the mbps parameter.
The bandwidth value is a Data Integration metric and does not represent the actual elastic network interface (ENI) traffic. In most cases, the ENI traffic is one to two times the channel traffic. The actual ENI traffic varies based on the serialization of the data storage system.
A semi-structured file does not have shard keys. If multiple files exist, you can configure the maximum transmission rate for a task to increase the synchronization speed. However, the maximum transmission rate is limited by the number of files.
For example, the maximum transmission rate for n files can be set to n MB/s.
If you set the maximum transmission rate to (n + 1) MB/s, the files are still synchronized at a speed of n MB/s.
If you set the maximum transmission rate to (n - 1) MB/s, the files are synchronized at a speed of (n - 1) MB/s.
A table in a relational database can be split based on the maximum transmission rate only after you specify the maximum transmission rate and shard key. In most cases, relational databases support only numeric-type shard keys. However, Oracle databases support numeric-type and string-type shard keys.
FAQ
The BatchSize or maxfilesize parameter determines the number of data records to synchronize at a time. We recommend that you specify an appropriate parameter value to reduce the interactions between Data Integration and databases and increase throughput. If you set the BatchSize or maxfilesize parameter to an excessively large value, an out of memory (OOM) error may occur during data synchronization. To resolve the issue, see Offline synchronization FAQ.
Appendix: Check the actual parallelism
On the log details page of a batch synchronization task, find the entry in the JobContainer - Job set Channel-Number to X channels format. In this example, the value of X is 2, which indicates that two parallel threads are used by the batch synchronization task.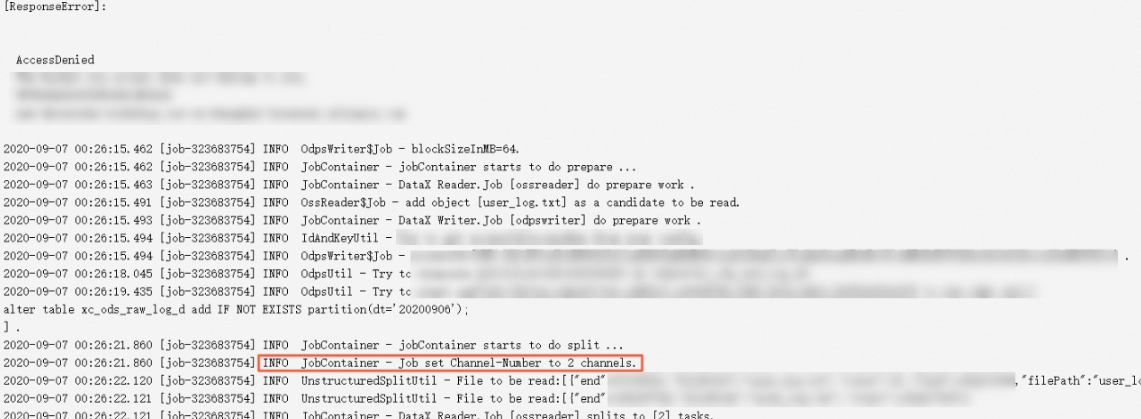
Appendix: Relationship between the parallelism and resource usage
This section describes the relationships between the parallelism and CPU utilization and between the parallelism and memory usage of exclusive resource groups.
Relationship between the parallelism and CPU utilization
For exclusive resource groups, the ratio of the parallelism to CPU utilization is 1:0.5. For example, if the exclusive resource group that you purchase uses an ECS instance with the specifications of 4 vCPUs and 8 GiB of memory, the parallelism of the exclusive resource group is 8. You can run a maximum of eight batch synchronization tasks with a parallelism of 1 or four batch synchronization tasks with a parallelism of 2 at a time.
If the task that you want to run on the exclusive resource group requires more threads than the threads available in the exclusive resource group, the task needs to wait until the tasks that are using the resources of the resource group finish running and sufficient threads are available for the task.
NoteIf the task that you want to run on the exclusive resource group requires more threads than the maximum number of threads that can be provided by the exclusive resource group, the task enters the state of waiting for resources. For example, if you want to run a task that requires 10 parallel threads on the exclusive resource group that uses an ECS instance with the specifications of 4 vCPUs and 8 GiB of memory, the task will permanently wait for resources. The exclusive resource group allocates resources to tasks based on the sequence in which the tasks are committed. Therefore, DataWorks cannot run tasks that are committed later than this task.
Relationship between the parallelism and memory usage
For exclusive resource groups, the minimum memory size that can be allocated to a synchronization task is calculated by using the following formula: 768 MB + (Parallelism - 1) × 256 MB. The maximum memory size that can be allocated to a synchronization task is 8,029 MB. If you specify a memory size when you configure the synchronization task, the specified memory size overrides the default settings of the exclusive resource group. If you configure the synchronization task in the code editor, you can specify a memory size for the task by configuring the jvmOption parameter in the $.setting.jvmOption path in the JSON configurations.
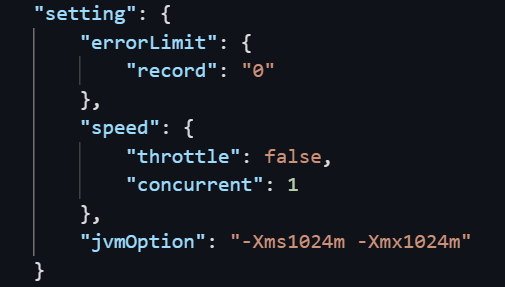
To ensure that all tasks that are running on an exclusive resource group can be run as expected, we recommend that you set the total memory size of the tasks to at least 1 GB less than the total memory size of all ECS instances that are deployed in the exclusive resource group. If this condition is not met, the Linux OOM killer forcefully stops the tasks that are running.
NoteIf you do not configure the required memory size in the code editor, you need to consider only the parallelism limits when you commit synchronization tasks.
Appendix: Synchronization speed
The read and write speeds vary based on data sources. This section describes the average speed for a single thread to read data from or write data to each type of data source.
Average speed for a single thread to write data to each type of data source
Writer
Average write speed for a single thread (KB/s)
AnalyticDB for PostgreSQL
147.8
AnalyticDB for MySQL
181.3
ClickHouse
5259.3
DataHub
45.8
DRDS
93.1
Elasticsearch
74.0
FTP
565.6
GDB
17.1
HBase
2395.0
hbase20xsql
37.8
HDFS
1301.3
Hive
1960.4
HybridDB for MySQL
323.0
HybridDB for PostgreSQL
116.0
Kafka
0.9
LogHub
788.5
MongoDB
51.6
MySQL
54.9
ODPS
660.6
Oracle
66.7
OSS
3718.4
OTS
138.5
PolarDB
45.6
PostgreSQL
168.4
Redis
7846.7
SQLServer
8.3
Stream
116.1
TSDB
2.3
Vertica
272.0
Average speed for a single thread to read data from each type of data source
Reader
Average read speed for a single thread (KB/s)
AnalyticDB for PostgreSQL
220.3
AnalyticDB for MySQL
248.6
DRDS
146.4
Elasticsearch
215.8
FTP
279.4
HBase
1605.6
hbase20xsql
465.3
HDFS
2202.9
Hologres
741.0
HybridDB for MySQL
111.3
HybridDB for PostgreSQL
496.9
Kafka
3117.2
LogHub
1014.1
MongoDB
361.3
MySQL
459.5
ODPS
207.2
Oracle
133.5
OSS
665.3
OTS
229.3
OTSStream
661.7
PolarDB
238.2
PostgreSQL
165.6
RDBMS
845.6
SQLServer
143.7
Stream
85.0
Vertica
454.3