This topic describes how to use MaxCompute nodes in DataWorks to process data in the ods_user_info_d_odps and ods_raw_log_d_odps tables in MaxCompute to obtain user profile data after basic user information and website access logs of users are synchronized to the tables. This topic also describes how to use the DataWorks and MaxCompute product combo to compute and analyze synchronized data to complete simple data processing in data warehousing scenarios.
Prerequisites
The required data is synchronized. For more information, see Synchronize data.
The basic user information stored in the ApsaraDB RDS for MySQL table
ods_user_info_dis synchronized to the MaxCompute tableods_user_info_d_odpsby using Data Integration.The website access logs of users stored in the Object Storage Service (OSS) object
user_log.txtis synchronized to the MaxCompute tableods_raw_log_d_odpsby using Data Integration.
Objective
The objective is to process the ods_user_info_d_odps and ods_raw_log_d_odps tables to obtain a basic user profile table.
Split the log information field in the
ods_raw_log_d_odpstable into multiple fields and generate thedwd_log_info_di_odpsfact table.Join the
dwd_log_info_di_odpsfact table with theods_user_info_d_odpstable based on the uid field to generate thedws_user_info_all_di_odpsaggregate table.Process the
dws_user_info_all_di_odpstable to generate a table named ads_user_info_1d_odps. The dws_user_info_all_di_odps table contains a large number of fields and a large amount of data. In this case,data consumptionmay require a long period of time to complete. Therefore, further data processing is required.
Go to the DataStudio page
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Development.
Step 1: Design a workflow
In the data synchronization phase, the required data is synchronized to MaxCompute tables. The next objective is to further process the data to generate the basic user profile data.
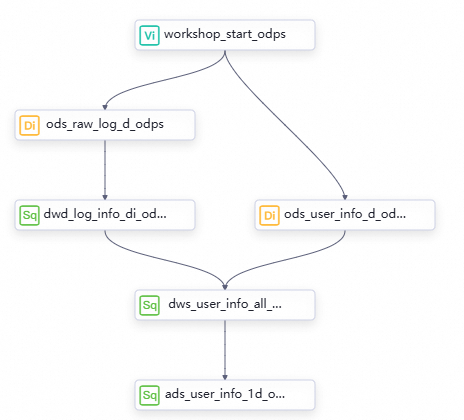
Nodes at different levels and the work logic of the nodes
In the upper part of the workflow canvas, click Create Node to create the nodes described in the following table for data processing.
Node category
Node type
Node name
(Named after the output table)
Code logic
MaxCompute
ODPS SQL
dwd_log_info_di_odpsUse built-in functions and user-defined functions (UDFs) to split data in the
ods_raw_log_d_odpstable and write data to multiple fields in thedwd_log_info_di_odpstable.MaxCompute
ODPS SQL
dws_user_info_all_di_odpsJoin the table that stores the basic user information and the dwd_log_info_di_odps table that stores the preliminarily processed log data to generate an aggregate table.
MaxCompute
ODPS SQL
ads_user_info_1d_odpsFurther process the data to generate a basic user profile.
Directed acyclic graph (DAG) in the workflow
Drag the nodes to the workflow canvas, and configure dependencies between the nodes by drawing lines to design the workflow for data processing.
Step 2: Configure a workflow
Create MaxCompute tables
Create the dwd_log_info_di_odps, dws_user_info_all_di_odps, and ads_user_info_1d_odps tables that are used to store processed data at each layer. In this example, the tables are created in a quick manner. For more information about MaxCompute table-related operations, see Create and manage MaxCompute tables.
Go to the entry point of creating tables.
On the DataStudio page, open the WorkShop workflow that you created in the data synchronization phase. Right-click MaxCompute and select Create Table.
Define the schemas of MaxCompute tables.
In the Create Table dialog box, enter a table name and click Create. For example, you need to create three tables named
dwd_log_info_di_odps,dws_user_info_all_di_odps, andads_user_info_1d_odps. Then, go to the DDL tab and execute a CREATE TABLE statement to create a table. You can view the statements that are used to create the preceding tables in the following content.Commit the tables to the compute engine.
After you define the schemas of the tables, click Commit to Development Environment and Commit to Production Environment in sequence on the configuration tab of each table. In the MaxCompute projects in the development and production environments, the system creates the related physical tables in the MaxCompute projects based on the configurations.
If you commit the tables to the development environment of the workspace, the tables are created in the MaxCompute project in the development environment.
If you commit the tables to the production environment of the workspace, the tables are created in the MaxCompute project in the production environment.
NoteIf you use a workspace in basic mode, you need to commit the tables only to the production environment. For information about workspaces in basic mode and workspaces in standard mode, see Differences between workspaces in basic mode and workspaces in standard mode.
For information about the relationship between DataWorks and MaxCompute and the MaxCompute compute engines in different environments, see Usage notes for development of MaxCompute nodes in DataWorks.
Create the dwd_log_info_di_odps table
Double-click the dwd_log_info_di_odps table. On the table configuration tab that appears, click DDL and enter the following CREATE TABLE statement:
CREATE TABLE IF NOT EXISTS dwd_log_info_di_odps (
ip STRING COMMENT 'The IP address of the client that is used to send the request',
uid STRING COMMENT 'The ID of the user',
time STRING COMMENT 'The time in the format of yyyymmddhh:mi:ss',
status STRING COMMENT 'The status code that is returned by the server',
bytes STRING COMMENT 'The number of bytes that are returned to the client',
region STRING COMMENT 'The region, which is obtained based on the IP address',
method STRING COMMENT 'The type of the HTTP request',
url STRING COMMENT 'url',
protocol STRING COMMENT 'The version number of HTTP',
referer STRING COMMENT 'The source URL',
device STRING COMMENT 'The terminal type',
identity STRING COMMENT 'The access type, which can be crawler, feed, user, or unknown'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;Create the dws_user_info_all_di_odps table
Double-click the dws_user_info_all_di_odps table. On the table configuration tab that appears, click DDL and enter the following CREATE TABLE statement:
CREATE TABLE IF NOT EXISTS dws_user_info_all_di_odps (
uid STRING COMMENT 'The ID of the user',
gender STRING COMMENT 'The gender',
age_range STRING COMMENT 'The age range of the user',
zodiac STRING COMMENT 'The zodiac sign',
region STRING COMMENT 'The region, which is obtained based on the IP address',
device STRING COMMENT 'The terminal type',
identity STRING COMMENT 'The access type, which can be crawler, feed, user, or unknown',
method STRING COMMENT 'The type of the HTTP request',
url STRING COMMENT 'url',
referer STRING COMMENT 'The source URL',
time STRING COMMENT 'The time in the format of yyyymmddhh:mi:ss'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;Create the ads_user_info_1d_odps table
Double-click the ads_user_info_1d_odps table. On the table configuration tab that appears, click DDL and enter the following CREATE TABLE statement:
CREATE TABLE IF NOT EXISTS ads_user_info_1d_odps (
uid STRING COMMENT 'The ID of the user',
region STRING COMMENT 'The region, which is obtained based on the IP address',
device STRING COMMENT 'The terminal type',
pv BIGINT COMMENT 'pv',
gender STRING COMMENT 'The gender',
age_range STRING COMMENT 'The age range of the user',
zodiac STRING COMMENT 'The zodiac sign'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14; Create a function named getregion
You can use methods such as a function to convert the structure of log data for the experiment into data in tables. In this example, the required resources are provided for the function that is used to convert IP addresses into regions. You need to only download the resources to your on-premises machine and upload the resources to your workspace before you register the function in DataWorks.
The IP address resources used by this function are only for the use of this tutorial. If you need to implement the mappings between IP addresses and geographical locations in formal business scenarios, you must seek out professional IP address conversion services from specialized IP address websites.
Upload the resource file ip2region.jar
Download the ip2region.jar file.
NoteThe
ip2region.jarfile is only for the use of this tutorial.On the DataStudio page, open the WorkShop workflow. Right-click MaxCompute and choose .
Click Upload, select the ip2region.jar file that is downloaded to your on-premises machine, and then click Open.
NoteSelect Upload to MaxCompute.
The resource name can be different from the name of the uploaded file.
Click the
 icon in the top toolbar to commit the resource to the MaxCompute project in the development environment.
icon in the top toolbar to commit the resource to the MaxCompute project in the development environment.
Register the function getregion
Go to the function registration page.
On the DataStudio page, open the WorkShop workflow, right-click MaxCompute, and then select Create Function.
Enter a function name.
In the Create Function dialog box, set the Name parameter to
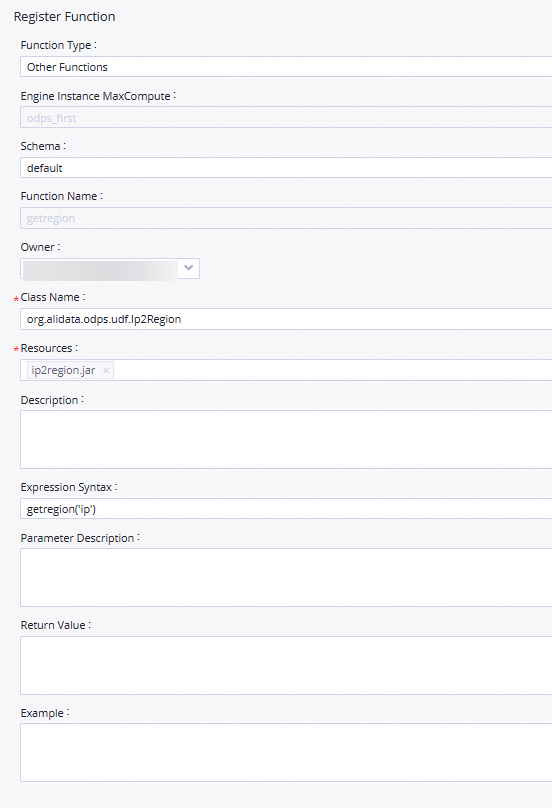
getregionand click Create.In the Register Function section of the configuration tab that appears, configure the parameters that are described in the following table.
Parameter
Description
Function Type
The type of the function.
MaxCompute Engine Instance
The MaxCompute compute engine. The value of this parameter cannot be changed.
Function Name
The name of the function.
Owner
The owner of the function.
Class Name
Set the parameter to
org.alidata.odps.udf.Ip2Region.Resources
Set the parameter to
ip2region.jar.Description
Set the parameter to Region conversion based on the IP address.
Expression Syntax
Set the parameter to
getregion('ip').Parameter Description
Set the parameter to IP address.
Click the
icon in the top toolbar to commit the function to the compute engine in the development environment.
Configure MaxCompute nodes
In this example, you need to use ODPS SQL nodes to implement data processing logic at each layer. Strong data lineages exist between ODPS SQL nodes at different layers. In the data synchronization phase, the output tables of the synchronization nodes have been manually added to the Output section on the Properties tab for the synchronization nodes. Therefore, the scheduling dependencies of the ODPS SQL nodes used to process data in this example can be automatically configured based on data lineages by using the automatic parsing feature.
Configure the dwd_log_info_di_odps node
On the configuration tab of the workflow, double-click the dwd_log_info_di_odps node. On the configuration tab of the node, enter the SQL code that processes fields in the ods_raw_log_d_odps ancestor table by using the created function and writes the processed data to the dwd_log_info_di_odps table. For more information about how to process data, see Appendix: Data processing example.
Edit node code.
-- Scenario: The following SQL statement uses the getregion function to parse IP addresses in raw log data, use methods such as regular expressions to split the parsed data into analyzable fields, and then write the fields into the dwd_log_info_di_odps table. -- In this example, the getregion function that is used to convert IP addresses into regions is prepared. -- Note: -- 1. Before you can use a function in a DataWorks node, you must upload the resources required for registering the function to DataWorks and then register the function by using the resources in a visualized manner. -- In this example, the resource used to register the getregion function is ip2region.jar. -- 2. You can configure scheduling parameters for nodes in DataWorks to write incremental data to the related partition in the desired table every day in the scheduling scenario. -- In actual development scenarios, you can define variables in the code of a node in the ${Variable name} format and assign scheduling parameters to the variables on the Properties tab of the configuration tab of the node. This way, the values of scheduling parameters can be dynamically replaced in the node code based on the configurations of the scheduling parameters. INSERT OVERWRITE TABLE dwd_log_info_di_odps PARTITION (dt='${bizdate}') SELECT ip , uid , time , status , bytes , getregion(ip) AS region -- Obtain the region based on the IP address by using the UDF. , regexp_substr(request, '(^[^ ]+ )') AS method -- Use the regular expression to extract three fields from the request. , regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url , regexp_substr(request, '([^ ]+$)') AS protocol , regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer -- Use the regular expression to clarify the referrer to obtain a more accurate URL. , CASE WHEN TOLOWER(agent) RLIKE 'android' THEN 'android' -- Obtain the terminal information and access type based on the agent parameter. WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone' WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad' WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device , CASE WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN TOLOWER(agent) RLIKE 'feed' OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed' WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^[Mozilla|Opera]' AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM ( SELECT SPLIT(col, '##@@')[0] AS ip , SPLIT(col, '##@@')[1] AS uid , SPLIT(col, '##@@')[2] AS time , SPLIT(col, '##@@')[3] AS request , SPLIT(col, '##@@')[4] AS status , SPLIT(col, '##@@')[5] AS bytes , SPLIT(col, '##@@')[6] AS referer , SPLIT(col, '##@@')[7] AS agent FROM ods_raw_log_d_odps WHERE dt ='${bizdate}' ) a;Configure scheduling properties.
On the configuration tab of the node, click Properties in the right-side navigation pane. On the Properties tab, configure the scheduling properties and basic information for the node. For more information, see Scheduling properties of a node. The following table describes the parameters.
Section
Description
Illustration
Scheduling Parameter
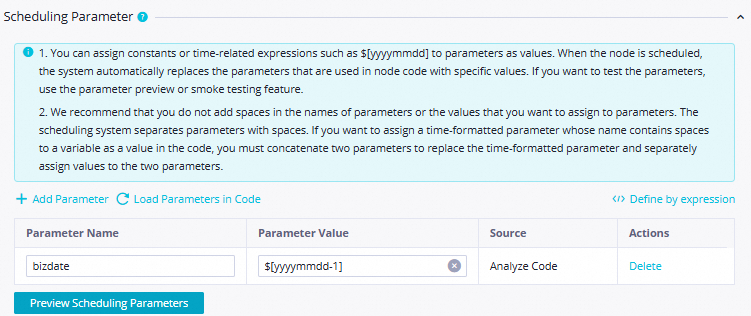
Configure the following parameters in the Scheduling Parameter section:
Parameter Name: Set the value to
bizdate.Parameter Value: Set the value to
$[yyyymmdd-1].
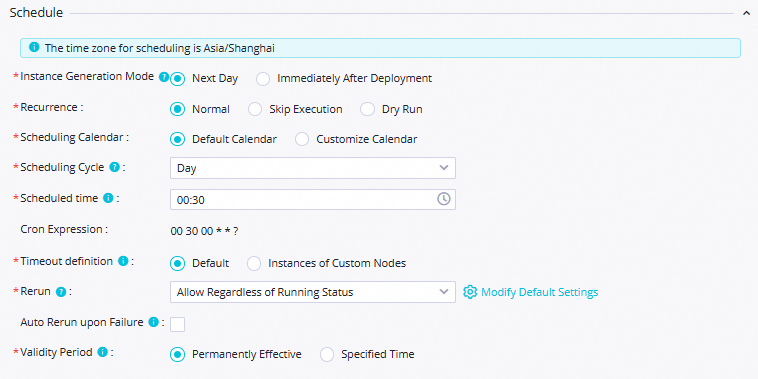
Schedule
Scheduling Cycle: Set the value to
Day.Scheduled time: Set the value to
00:30.Rerun: Set the value to Allow Regardless of Running Status.
Use the default values for other parameters.
NoteThe time when the current node is scheduled to run every day is determined by the scheduling time of the zero load node workshop_start of the workflow. The current node is scheduled to run after 00:30 every day.
Resource Group
Select the serverless resource group that you purchased in the environment preparation phase.

Dependencies
Set Automatic Parsing From Code Before Node Committing to Yes to allow the system to configure the
ods_raw_log_d_odpsnode that generates theods_raw_log_d_odpstable as the ancestor node of thedwd_log_info_di_odpsnode. Thedwd_log_info_di_odpstable is used as the output of the dwd_log_info_di_odps node. This way, the dwd_log_info_di_odps node can be automatically configured as an ancestor node of other nodes when these nodes query the table data generated by the dwd_log_info_di_odps node. Note
NoteDetermine the ancestor nodes of the current node: Click Parse Input and Output from Code, the table name in the code is parsed to the output node named in the format of
MaxCompute project name in the production environment.Table name. The output node name is used as the name of the output of an ancestor node.Determine the output of the current node: Click Parse Input and Output from Code, the table name in the code is parsed to the output node named in the format of
MaxCompute project name in the production environment.Table name, which is output to the downstream node.In this example, other required configuration items can be configured based on your business requirements. After the configuration is complete, click the
 icon in the top toolbar on the configuration tab of the node to save the node configurations.
icon in the top toolbar on the configuration tab of the node to save the node configurations.
Configure the dws_user_info_all_di_odps node
On the configuration tab of the workflow, double-click the dws_user_info_all_di_odps node. On the configuration tab of the node, enter the SQL code that merges the dwd_log_info_di_odps and ods_user_info_d_odps ancestor tables and writes the merged data to the dws_user_info_all_di_odps table.
Edit node code.
-- Scenario: Aggregate the processed log data in the dwd_log_info_di_odps table and the basic user information in the ods_user_info_d_odps table and write the aggregated data to the dws_user_info_all_di_odps table. -- Note: You can configure scheduling parameters for nodes in DataWorks to write incremental data to the related partition in the desired table every day in the scheduling scenario. -- In actual development scenarios, you can define variables in the code of a node in the format of ${Variable name} and assign scheduling parameters to the variables on the Properties tab of the configuration tab of the node. This way, the values of scheduling parameters can be dynamically replaced in the node code based on the configurations of the scheduling parameters. INSERT OVERWRITE TABLE dws_user_info_all_di_odps PARTITION (dt='${bizdate}') SELECT COALESCE(a.uid, b.uid) AS uid , b.gender , b.age_range , b.zodiac , a.region , a.device , a.identity , a.method , a.url , a.referer , a.time FROM ( SELECT * FROM dwd_log_info_di_odps WHERE dt = '${bizdate}' ) a LEFT OUTER JOIN ( SELECT * FROM ods_user_info_d_odps WHERE dt = '${bizdate}' ) b ON a.uid = b.uid;Configure scheduling properties.
On the configuration tab of the node, click Properties in the right-side navigation pane. On the Properties tab, configure the scheduling properties and basic information for the node. For more information, see Scheduling properties of a node. The following table describes the parameters.
Section
Description
Illustration
Scheduling Parameter
Configure the following parameters in the Scheduling Parameter section:
Parameter Name: Set the value to
bizdate.Parameter Value: Set the value to
$[yyyymmdd-1].
Schedule
Scheduling Cycle: Set the value to
Day.Scheduled time: Set the value to
00:30.Rerun: Set the value to Allow Regardless of Running Status.
Use the default values for other parameters.
NoteThe time when the current node is scheduled to run every day is determined by the scheduling time of the zero load node workshop_start of the workflow. The current node is scheduled to run after 00:30 every day.
Resource Group
Select the serverless resource group that you purchased in the environment preparation phase.
Dependencies
Set Automatic Parsing From Code Before Node Committing to Yes to allow the system to configure the
dwd_log_info_di_odpsandods_user_info_d_odpsnodes that generate thedwd_log_info_di_odpsandods_user_info_d_odpstables as the ancestor node of thedws_user_info_all_di_odpsnode. Thedws_user_info_all_di_odpstable is used as the output of the dws_user_info_all_di_odps node. This way, the dws_user_info_all_di_odps node can be automatically configured as an ancestor node of other nodes when these nodes query the table data generated by the dws_user_info_all_di_odps node.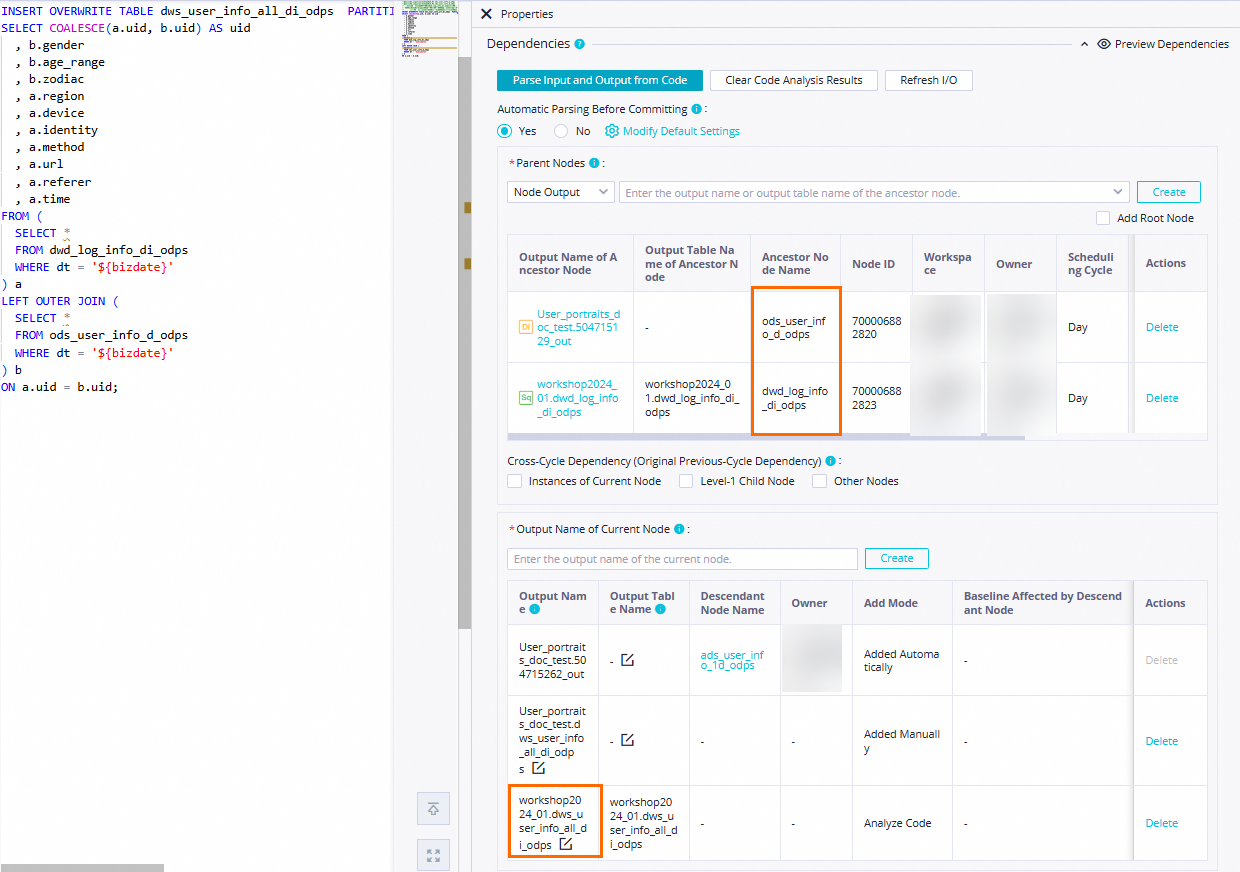 Note
NoteDetermine the ancestor nodes of the current node: Click Parse Input and Output from Code, the table name in the code is parsed to the output node named in the format of
MaxCompute project name in the production environment.Table name. The output node name is used as the name of the output of an ancestor node.Determine the output of the current node: Click Parse Input and Output from Code, the table name in the code is parsed to the output node named in the format of
MaxCompute project name in the production environment.Table name, which is output to the downstream node.In this example, other required configuration items can be configured based on your business requirements. After the configuration is complete, click the
icon in the top toolbar on the configuration tab of the node to save the node configurations.
Configure the ads_user_info_1d_odps node
On the configuration tab of the workflow, double-click the ads_user_info_1d_odps node. On the configuration tab of the node, enter the SQL code that processes the dws_user_info_all_di_odps ancestor table and writes the processed data to the ads_user_info_1d_odps table.
Edit node code.
-- Scenario: The following SQL statement is used to further process the dws_user_info_all_di_odps wide table that is used to store user access information into the ads_user_info_1d_odps table that is used to store basic user profile data. -- Note: You can configure scheduling parameters for nodes in DataWorks to write incremental data to the related partition in the desired table every day in the scheduling scenario. -- In actual development scenarios, you can define variables in the code of a node in the format of ${Variable name} and assign scheduling parameters to the variables on the Properties tab of the configuration tab of the node. This way, the values of scheduling parameters can be dynamically replaced in the node code based on the configurations of the scheduling parameters. INSERT OVERWRITE TABLE ads_user_info_1d_odps PARTITION (dt='${bizdate}') SELECT uid , MAX(region) , MAX(device) , COUNT(0) AS pv , MAX(gender) , MAX(age_range) , MAX(zodiac) FROM dws_user_info_all_di_odps WHERE dt = '${bizdate}' GROUP BY uid;Configure scheduling properties.
On the configuration tab of the node, click Properties in the right-side navigation pane. On the Properties tab, configure the scheduling properties and basic information for the node. For more information, see Scheduling properties of a node. The following table describes the parameters.
Section
Description
Illustration
Scheduling Parameter
Configure the following parameters in the Scheduling Parameter section:
Parameter Name: Set the value to
bizdate.Parameter Value: Set the value to
$[yyyymmdd-1].
Schedule
Scheduling Cycle: Set the value to
Day.Scheduled time: Set the value to
00:30.Rerun: Set the value to Allow Regardless of Running Status.
Use the default values for other parameters.
NoteThe time when the current node is scheduled to run every day is determined by the scheduling time of the zero load node workshop_start of the workflow. The current node is scheduled to run after 00:30 every day.
Resource Group
Select the serverless resource group that you purchased in the environment preparation phase.
Dependencies
Set Automatic Parsing From Code Before Node Committing to Yes to allow the system to configure the
dws_user_info_all_1d_odpsnode that generates thedws_user_info_all_1d_odpstable as the ancestor node of theads_user_info_1d_odpsnode. The ads_user_info_1d table is used as the output of the ads_user_info_1d node. This way, the ads_user_info_1d node can be automatically configured as an ancestor node of other nodes when these nodes query the table data generated by the ads_user_info_1d node.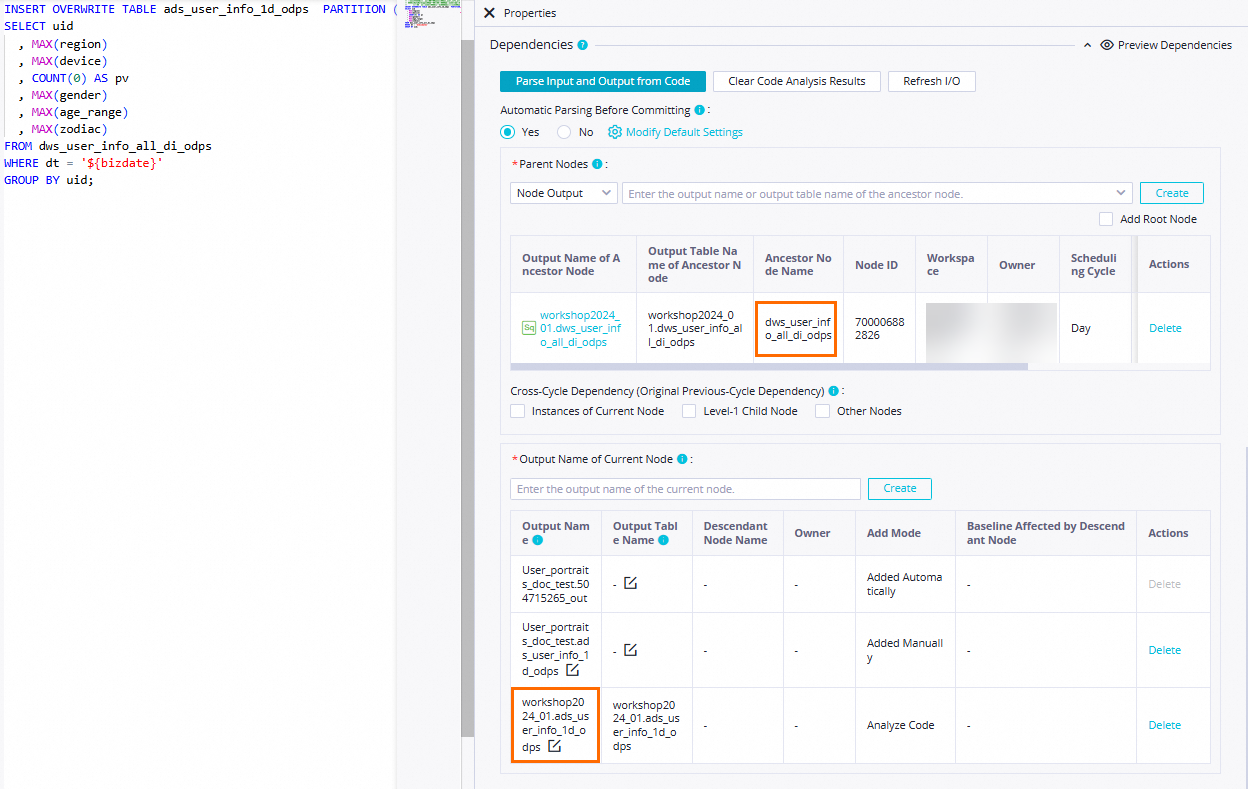 Note
NoteDetermine the ancestor nodes of the current node: Click Parse Input and Output from Code, the table name in the code is parsed to the output node named in the format of
MaxCompute project name in the production environment.Table name. The output node name is used as the name of the output of an ancestor node.Determine the output of the current node: Click Parse Input and Output from Code, the table name in the code is parsed to the output node named in the format of
MaxCompute project name in the production environment.Table name, which is output to the downstream node.In this example, other required configuration items can be configured based on your business requirements. After the configuration is complete, click the
icon in the top toolbar on the configuration tab of the node to save the node configurations.
Step 3: Run a workflow
Run the workflow
On the DataStudio page, double-click the
User profile analysis_MaxComputeworkflow under Business Flow. On the configuration tab of the workflow, click the icon in the top toolbar to run the nodes in the workflow based on the scheduling dependencies between the nodes.
icon in the top toolbar to run the nodes in the workflow based on the scheduling dependencies between the nodes. 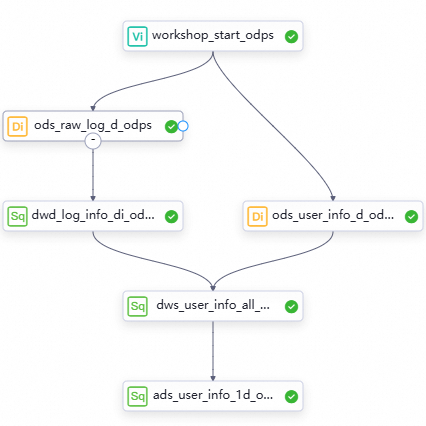
Confirm the status.
View the node status: If a node is in the
 state, the synchronization process is normal.
state, the synchronization process is normal. View the node running logs: Right-click the node and select View Logs to view the logs of each node in the entire user profile analysis process in the development environment.
View the synchronization result
After all nodes in the workflow enter the ![]() state, you can query the finally processed result table.
state, you can query the finally processed result table.
In the left-side navigation pane of the DataStudio page, click
 .
. In the Ad Hoc Query pane, right-click Ad Hoc Query and choose Create Node > ODPS SQL.
Execute the following SQL statement in the ODPS SQL node to confirm the final result table in this example.
// You must specify the data timestamp of the data on which you perform read and write operations as the filter condition for partitions. For example, if a node is scheduled to run on February 22, 2023, the data timestamp of the node is 20230221, which is one day earlier than the scheduling time of the node. select count(*) from ads_user_info_1d_odps where dt='Data timestamp';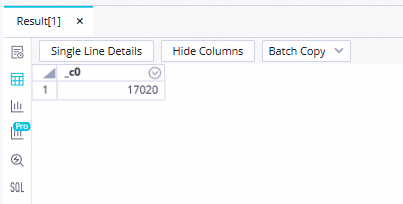 Note
NoteIn this example, nodes are run in DataStudio, which is the development environment. Therefore, data is written to the specified tables in the MaxCompute project workshop2024_01_dev that is associated with the workspace in the development environment by default.
Step 4: Deploy the workflow
The nodes can be automatically scheduled and run only after the nodes are deployed to the production environment. For more information, see the following content.
Commit the workflow to the development environment
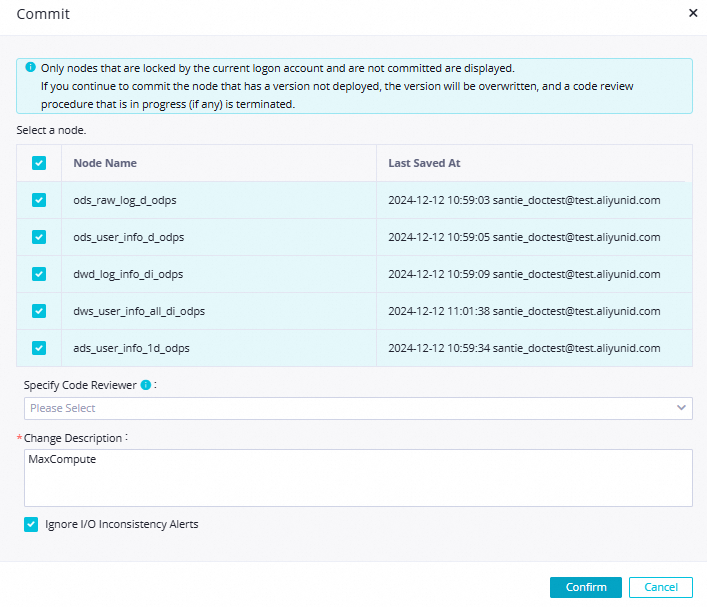
In the top toolbar of the configuration tab of the workflow, click the  icon to commit all nodes in the workflow. In the Commit dialog box, configure the parameters as shown in the following figure, and click Confirm.
icon to commit all nodes in the workflow. In the Commit dialog box, configure the parameters as shown in the following figure, and click Confirm.
Commit the workflow to the production environment
After you commit the workflow, the nodes in the workflow enter the development environment. You must deploy the configured nodes to the production environment because nodes in the development environment cannot be automatically scheduled.
In the top toolbar of the configuration tab of the workflow, click the
 icon. Alternatively, go to the configuration tab of one of the nodes in DataStudio and click the Deploy icon in the upper-right corner to go to the Create Deploy Task page.
icon. Alternatively, go to the configuration tab of one of the nodes in DataStudio and click the Deploy icon in the upper-right corner to go to the Create Deploy Task page. Deploy the desired nodes at the same time. The deployed content includes the resources and functions that are involved in the workflow.
Step 5: Perform O&M and scheduling operations on the workflow
In actual development scenarios, you can use the data backfill feature in the production environment to backfill data of a historical period of time or a period of time in the future. This topic describes how to perform O&M and scheduling operations on the data backfill instances. For more information about capabilities in Operation Center, see Operation Center.
Go to the Operation Center page.
After the nodes are deployed, click Operation Center in the upper-right corner of the configuration tab of the node.
You can also click Operation Center in the upper part of the DataStudio page to go to the Operation Center page.
Backfill data for auto triggered tasks.
In the left-side navigation pane, choose . On the page that appears, click the root node of the
workshop_start_odpsworkflow.Right-click the
workshop_start_odpsnode and choose .Select all descendant nodes of the
workshop_start_odpsnode, enter data timestamps, and then click OK. The Patch Data page appears.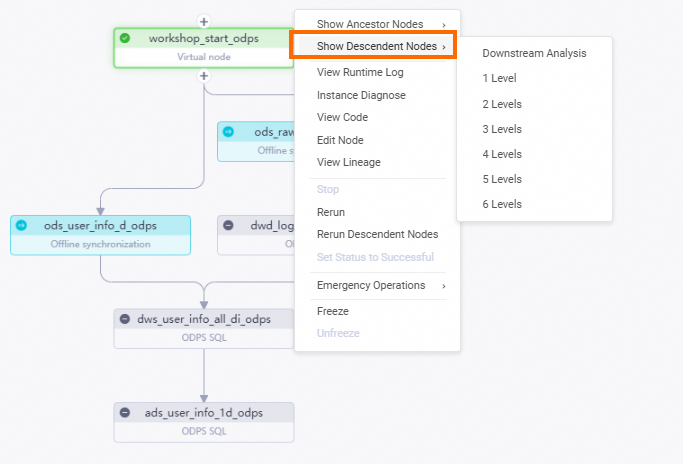
Click Refresh until all SQL nodes are successfully run.
After the test is complete, you can configure the Validity Period parameter for the nodes or freeze the root node of the workflow to which the nodes belong to prevent the fees of long-term node scheduling. The root node is the zero load node named workshop_start_odps.
What to do next
After you deploy the nodes, the entire workflow is complete. You can view the details of the created tables, consume data in the related table, and configure data quality monitoring. For more information, see Manage data, Use an API to provide data services, Visualize data on a dashboard, and Monitor data quality.
Appendix: Data processing example
Before data processing
58.246.10.82##@@2d24d94f14784##@@2014-02-12 13:12:25##@@GET /wp-content/themes/inove/img/feeds.gif HTTP/1.1##@@200##@@2572##@@http://coolshell.cn/articles/10975.html##@@Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36After data processing
