DataStudio is the DataWorks module for developing and scheduling periodic tasks. It integrates with Operation Center and provides a visual development interface for compute engines such as MaxCompute, Hologres, and E-MapReduce, with intelligent code development, multi-engine hybrid workflows, and standardized task publishing. DataStudio helps you build offline data warehouses, real-time data warehouses, and ad hoc query systems.
Go to DataStudio
Log on to the DataWorks console. In the target region, click in the left-side navigation pane. Select a workspace from the drop-down list and click Go to Data Development.
DataStudio is supported only on Google Chrome 69 or later on a PC.
Overview
Features
The following table describes the main DataStudio features. Key terms are defined in Appendix: Concepts.

|
Type |
Description |
|
Object organization and management |
DataStudio organizes and manages objects in the following ways:
Create a workflow. Management modes. Note
In DataStudio, the following limits apply to the number of workflows and objects that you can create in a workspace:
If the number of workflows or objects in the current workspace reaches the upper limit, you cannot create new ones. |
|
Task development |
All available node types are listed in Supported node types. |
|
Task scheduling |
Configure time properties. Guide for configuring scheduling dependencies. |
|
Task debugging |
DataStudio supports debugging individual tasks and entire workflows. Task debugging process. |
|
Process control |
Provides standardized task publishing and process control:
|
|
Other features |
|
UI overview
Follow the DataStudio feature guide to learn about the data development interface and how to use the features of each module.
Development process
DataStudio supports real-time sync tasks, offline scheduled tasks (including sync and processing), and manually triggered tasks for various compute engines. For data synchronization capabilities, see Data Integration. Before you begin, understand the development requirements for each compute engine and choose the appropriate task type.
-
Compute engine development guides: DataWorks supports various data sources and compute engines. Configuration requirements vary by engine. Major compute engine guides:
-
General development process: DataWorks workspaces run in standard mode and basic mode. The development process differs slightly between modes.
Development process in a workspace in standard mode.

Development process in a workspace in basic mode.
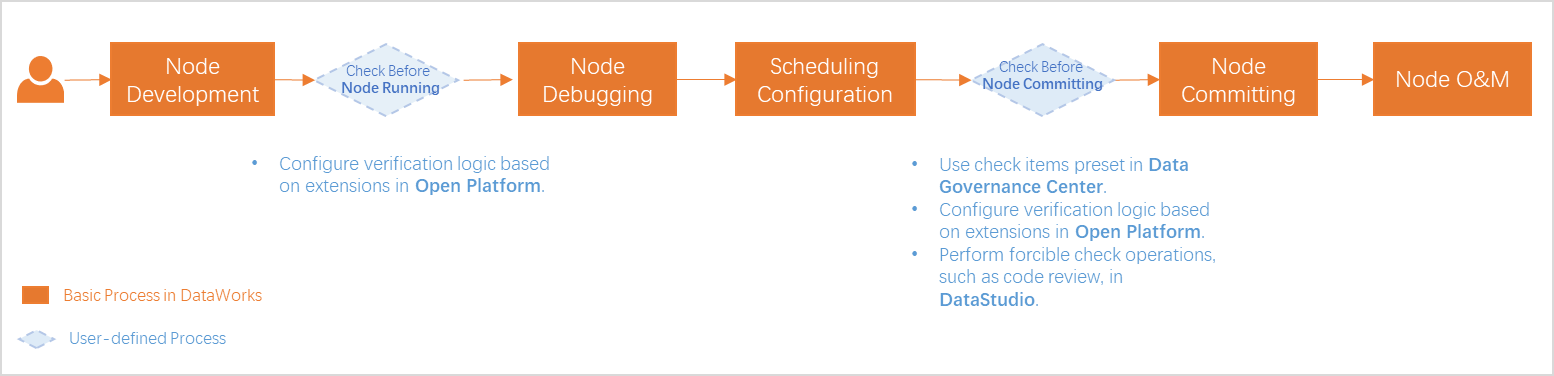
-
Basic process: In standard mode, the scheduled task lifecycle includes development, debugging, scheduling configuration, committing, publishing, and O&M. Guide to the data development process.
-
Process control: Use built-in code review and smoke testing, preset checks in Data Governance Center, and custom validation through Open Platform extensions to ensure standards compliance.
NoteProcess control options vary by workspace mode. The features available in the console are definitive.
-
Organization
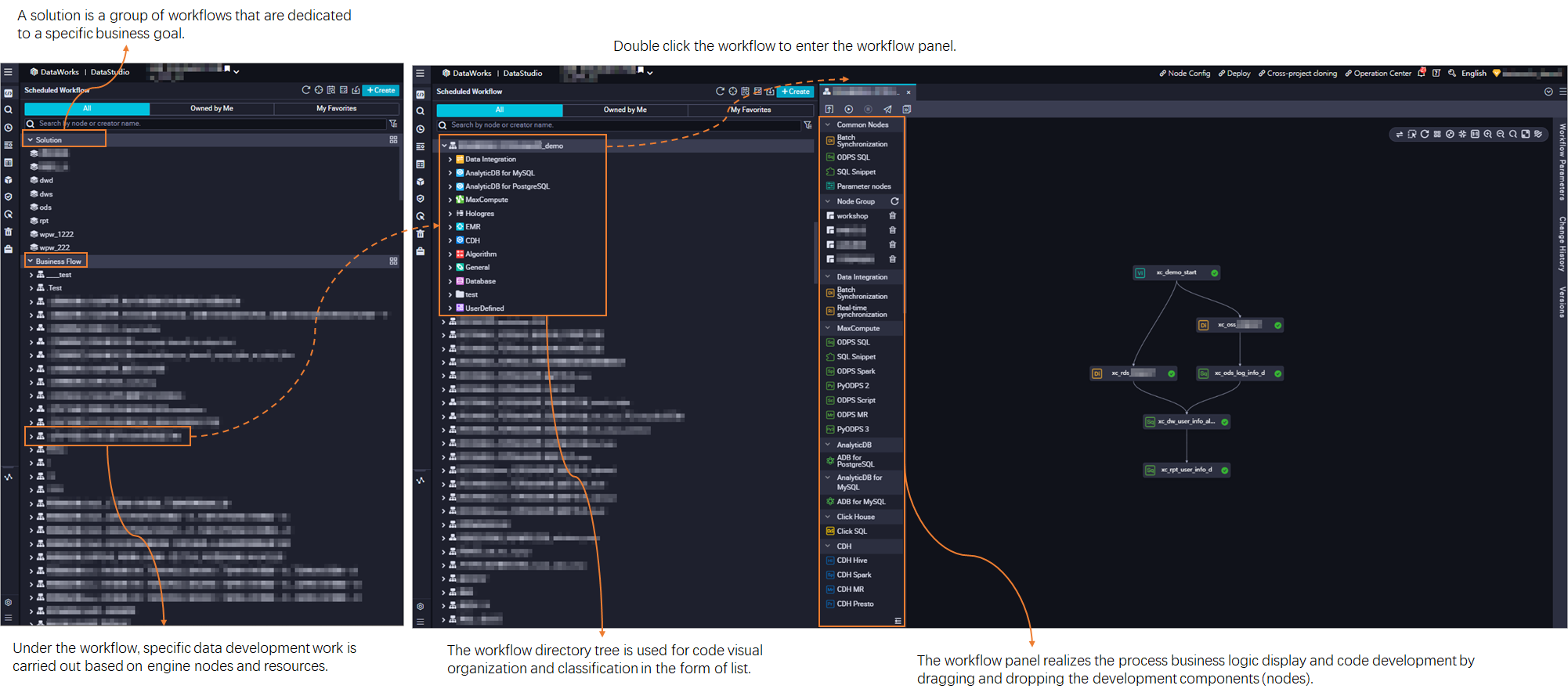
In DataStudio, a workflow is the basic unit for code development and resource organization. Workflows and task nodes are developed independently in each workspace and do not affect each other. Create a workflow.
Workflows are presented as a directory tree and an operation panel, helping you organize code from a business perspective.
-
Directory tree structure: Provides a way to organize code based on task types.
-
Workflow panel: Provides a process-oriented display of business logic.
Get started
Prerequisites
To develop tasks, model data, or schedule periodic tasks in DataWorks, you must associate your data sources or clusters as computing resources in DataStudio. Without this association, you cannot create data development nodes.
-
Create the data sources or clusters required for your planned task types.
Data source or cluster
Description
DataWorks auto-associates the first MaxCompute data source. Manually associate subsequent ones.
Manually associate these data sources after creation.
DataWorks auto-associates registered clusters. No manual association needed.
Log on to the DataWorks console. In the target region, click in the left-side navigation pane. Select a workspace from the drop-down list and click Go to Data Development.
-
In the left-side navigation pane, click Computing Resources.
If the Computing Resource module is not in the left-side navigation pane, add it from Personal Settings. Module Management.
-
Associate a computing resource.
On the Computing Resource page, search for the target data source or cluster by Computing Resource Name or Computing Resource Type and click Associate. After association, you can use the data source for development.
NoteIf data source information changes, refresh the page to view the updates.

-
In some cases, a data source or cluster may fail to be associated with DataStudio:
-
Association depends on configuration. For example, data sources using an AccessKey pair cannot be associated. Check the association page for limitations.
-
The data source is missing a development or production environment.
-
A MaxCompute computing resource cannot be associated with multiple DataWorks workspaces at the same time.
NoteThe platform displays the reason for any association failure.
-
-
Only MaxCompute, E-MapReduce, Hologres, AnalyticDB for MySQL, ClickHouse, CDH/CDP, and AnalyticDB for PostgreSQL can be associated with DataStudio.
-
Associable data source types and limits vary by DataWorks edition. Features of different editions of DataWorks.
-
Tutorial
Get started with data development covers basic operations and the development process.
Supported node types
DataStudio provides various node types, many supporting periodic scheduling. Select nodes based on your business needs. Supported node types.
Appendix: Concepts
-
Task development
Term
Description
Solution
A collection of workflows managed collectively. Workflows can be reused across multiple Solutions for collaboration.
Workflow
A collection of tasks, tables, resources, and functions for a business requirement. Tasks run on a schedule.
Manually triggered workflow
A collection of tasks, tables, resources, and functions for a specific business requirement.
Unlike regular workflows, tasks in a manually triggered workflow must be triggered manually rather than running on a schedule.
DAG
An abbreviation for
directed acyclic graph. Displays nodes and their dependencies. In DataStudio, all tasks within a workflow share one DAG.Task
The basic execution unit in DataWorks. Tasks run sequentially based on dependencies.
Node
Represents a task in a DAG. Nodes run sequentially based on dependencies.
-
Task scheduling
Term
Description
Dependency
Defines execution order between tasks. If task B runs only after task A completes, A is an upstream dependency of B. Shown as arrows in a DAG.
Output name
A globally unique identifier for a node. A node can have multiple output names. DataWorks uses output names to define scheduling dependencies.
Output table name
The name of the task's output table, helping downstream tasks confirm the correct data source. Do not modify auto-generated output table names. This identifier does not affect the actual table name, which is determined by SQL logic.
NoteA node's Output Name must be globally unique, whereas an Output Table Name does not have this restriction.
Scheduling resource group
The resource group used for task scheduling. Overview of DataWorks resource groups.
Scheduling parameter
Variables in code that dynamically retrieve runtime values such as date and time. Define scheduling parameters in DataWorks to assign values to code variables at execution.
Business date
The date a business transaction occurred. In offline computing, this is typically the day before the task runs. By default, DataWorks sets this to the day before the task runs, accurate to the day. For example, when generating statistics for yesterday's sales, yesterday is the business date.
Scheduling time
The expected time a task is scheduled to run, accurate to the second. The actual start time may differ due to various factors.