DataWorks has provided solutions for enterprises in various industries to tackle data pain points and mine data values. This topic describes the typical customer cases of DataWorks.
New retail industry: Cloud data mid-end for RT-Mart
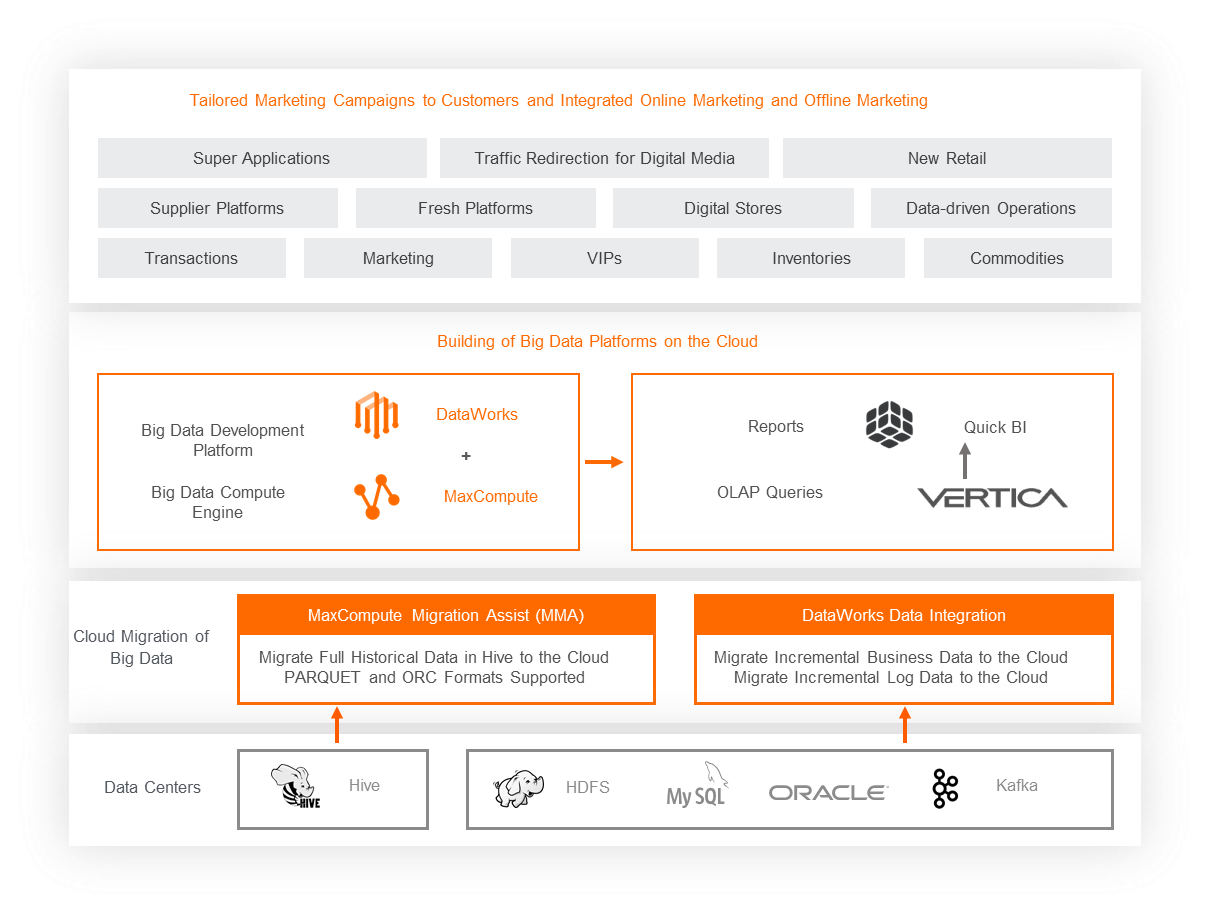
Background
To facilitate the digital transformation and tap into the new retail market, RT-Mart plans to fully migrate its IT system to Alibaba Cloud within two years and no longer uses self-managed data centers. RT-Mart also wants Alibaba Cloud to help build a cloud data mid-end to reduce the total cost of ownership (TCO) and facilitate closed-loop control of data assets based on the cloud ecosystem.
Customer requirements
The original system of RT-Mart was built on the open source Hadoop. The system was unstable and the maintenance costs of software and hardware were high. As a result, the business operations and analytics of RT-Mart were severely affected.
As the online business of RT-Mart surges, piles of requirements remain unsatisfied. RT-Mart wants an overall solution that can flexibly and quickly extend existing technologies to support business growth.
Value embodiment
The solution uses MaxCompute Migration Assist (MMA) to migrate a total of more than 400 TB historical data to the cloud in 15 days with accuracy. This provides RT-Mart with smooth and efficient data migration experience. In addition, the solution uses DataWorks and MaxCompute to help RT-Mart greatly improve the data development efficiency and build a data mid-end for RT-Mart.
New finance industry: Data lakehouse for an Internet financial company
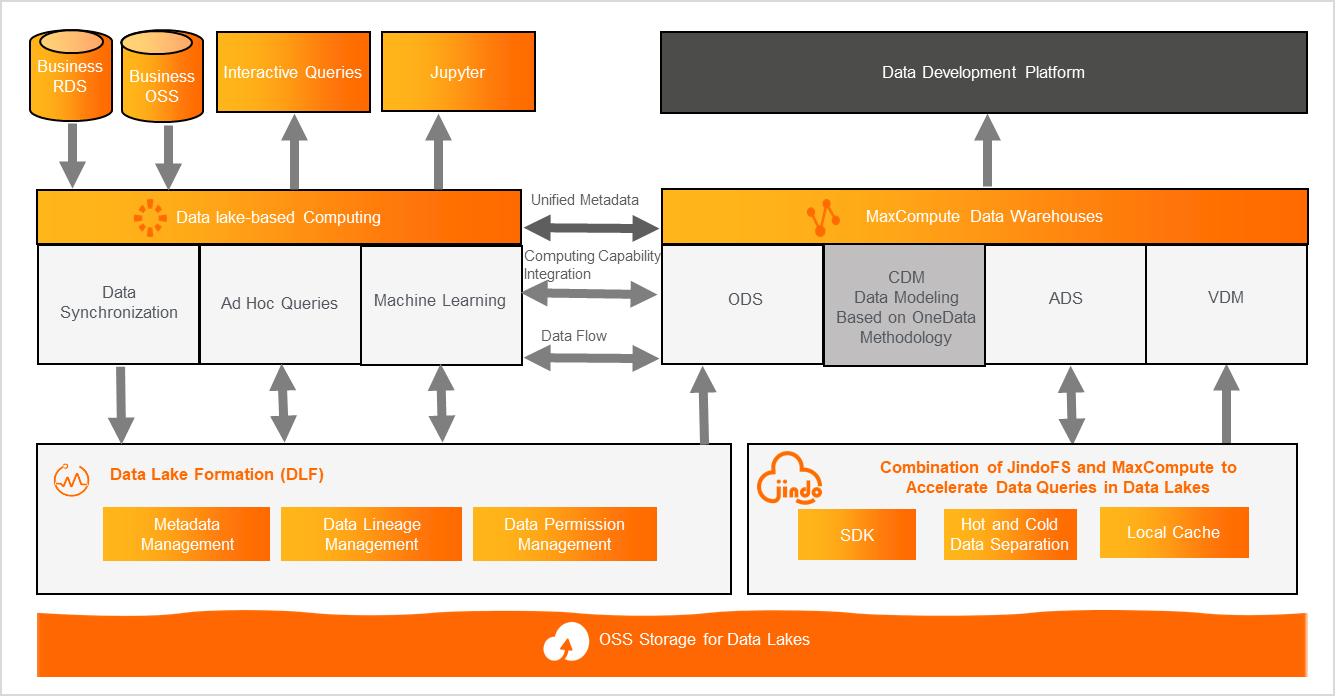
Background
The company builds its primitive data lake based on Hadoop and Object Storage Service (OSS), but uses MaxCompute to run tasks and store data in the data mid-end. The two sets of heterogeneous engines lead to issues such as storage redundancy, metadata and permission inconsistency, and calculation interruption.
Customer requirements
The company wants to use MaxCompute and E-MapReduce (EMR) engines to adapt to the needs of different business scenarios, use Alibaba Cloud Data Lake Formation (DLF) to centrally manage metadata and user permissions, and use DataWorks to govern data from end to end so as to improve data quality and enhance data application.
Value embodiment
The solution integrates the metadata of the EMR engine into DLF, uses OSS at the underlying layer for unified data storage, and builds a data lakehouse that connects the EMR-based data lake to the MaxCompute-based data warehouse. This way, data can freely flow and calculations can be performed without interruptions between the data lake and the data warehouse.
The solution stores the data of the data lake and data warehouse at different layers. Specifically, the solution stores the intermediate tables that the data mid-end uses to perform dimensional modeling on the data in the data lake in MaxCompute, and stores the data used by EMR and other engines at the application data service (ADS) layer.
New energy industry: DataWorks-based data governance from end to end for an energy company
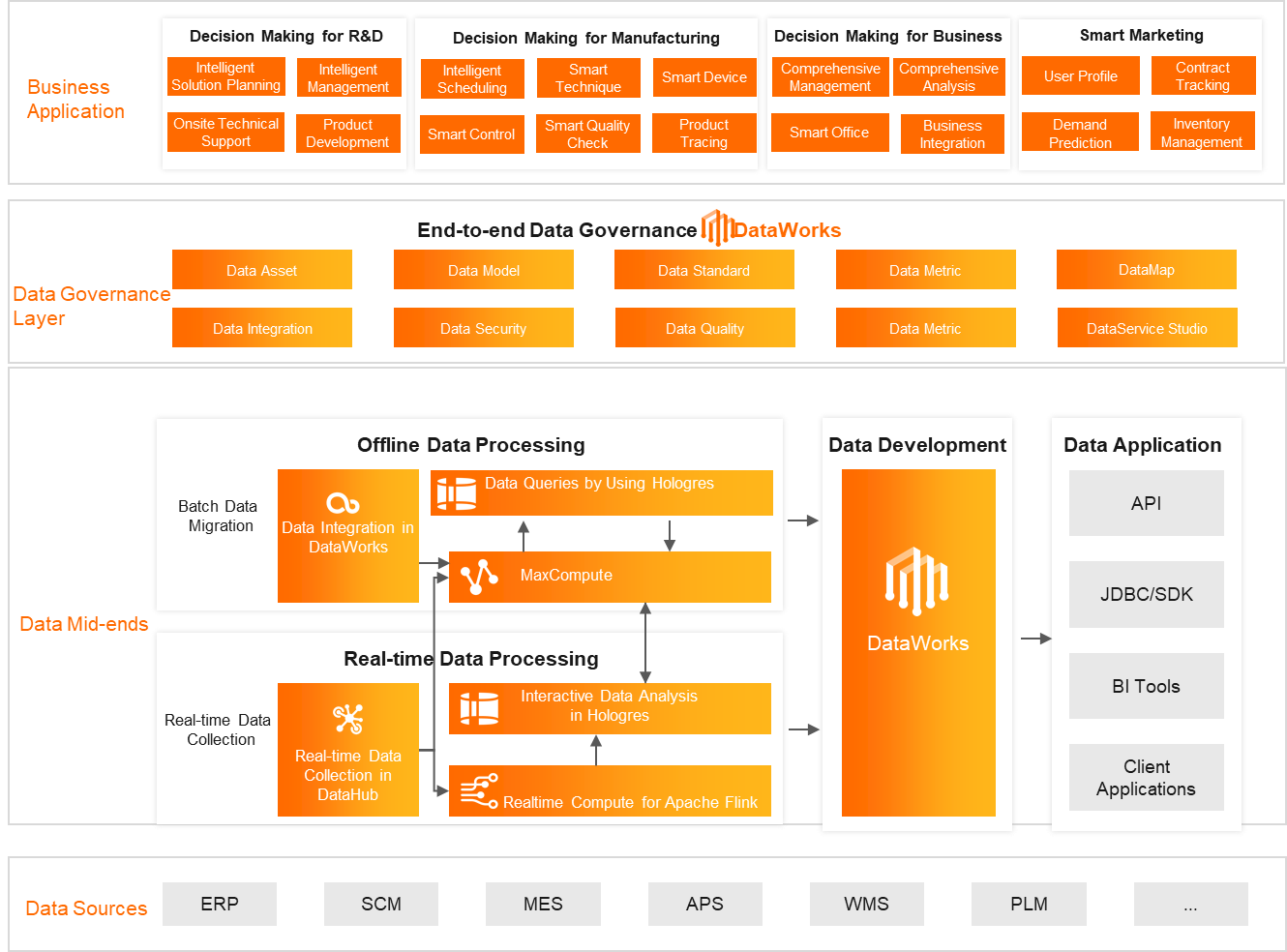
Background
The company has multiple subsidiaries and a large number of systems. The technical routes are complex and diversified.
The data is scattered and is defined based on various standards. This causes data gaps and increases data analysis difficulties.
No effective mechanism is provided for data permission management, data governance, and data sharing.
Customer requirements
Use DataWorks and MaxCompute to build a data mid-end to prevent data silos.
Use Realtime Compute for Apache Flink and Hologres to improve the real-time performance of the data mid-end.
Use DataWorks to govern data from end to end to improve data quality and enhance data application.
Value embodiment
The solution helps build an intelligent business-to-business (B2B) marketing system that integrates intelligent manufacturing with Internet marketing.
The solution creates a data mid-end that integrates offline and real-time data processing, and provides a unified and complete big data application chain to serve the core business systems of the company.
The end-to-end data governance improves data availability and allows data to freely flow in the data mid-end. This ensures data accuracy, real-time performance, and data consistency, and helps the company reduce the costs for about CNY 100 million.
The solution improves business iteration efficiency, and allows data to be updated every 10 minutes and new services to be released within one day. The original system of the company requires one day to update data and one week to release a new service.
Internet industry: Cloud big data warehouse for GOGOX
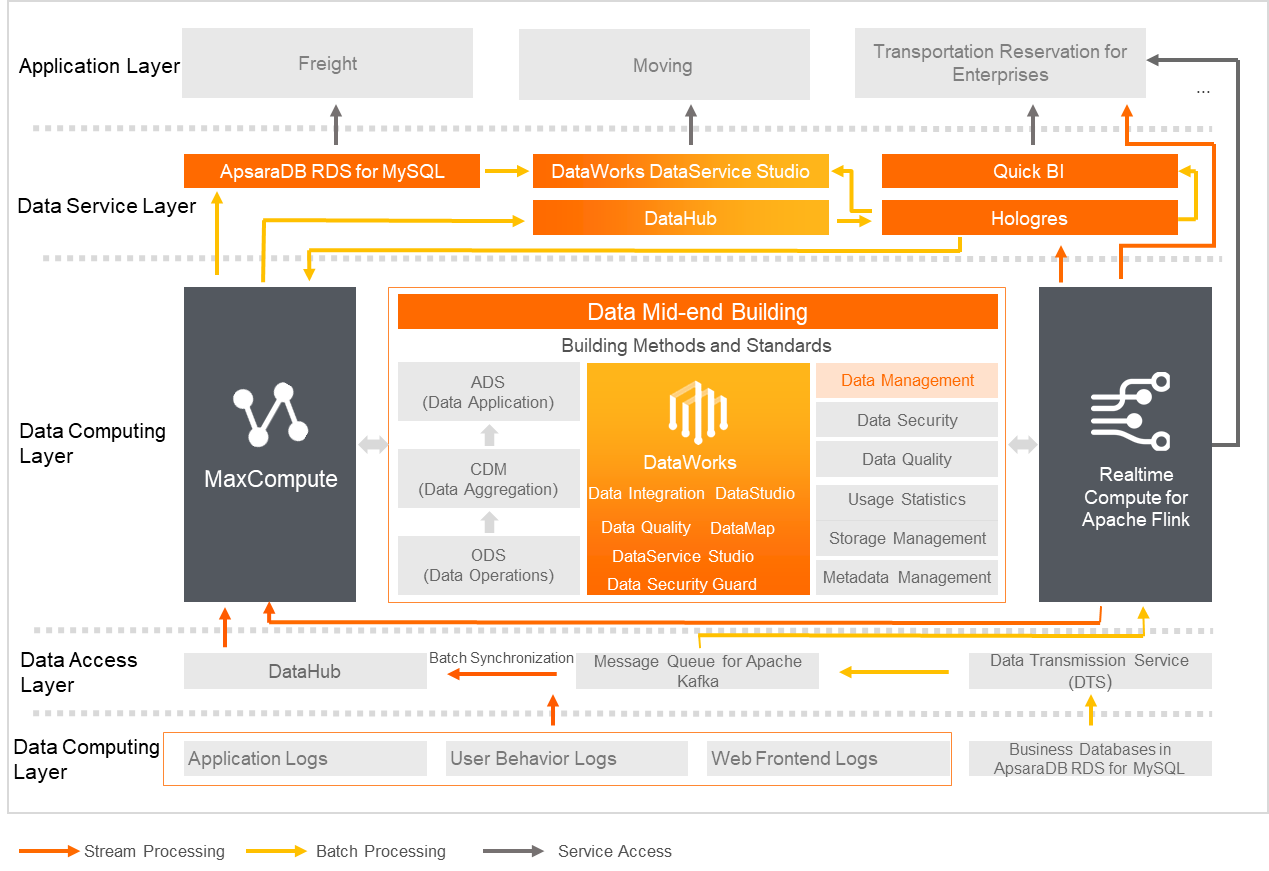
Background
GOGOX is a logistics platform that keeps integrating idle transport resources by using digital information methods, such as network connection, transport resource sharing, process digitalization, and intelligent matching. Then, the platform makes analysis based on the big data to precisely distribute the transport resources to the required markets. This saves energy, reduces emissions, and lowers the empty load rate. In addition, this improves the operating efficiency and facilitates the development of green logistics.
Customer requirements
The efficiency of massive data processing is low, and the duration for offline data calculation is variable.
Realtime Compute for Apache Flink requires a large amount of development and maintenance costs. The company needs a solution for comprehensive data warehouse governance.
Value embodiment
The Apsara big data platform of Alibaba Cloud helps GOGOX reduce the server costs by more than 30% and increase the data development efficiency by 100%. Compared with the original Java-based Apache Storm, Flink SQL has greatly reduced the development cycle of real-time computing and is easier to maintain. In addition, Flink SQL can better ensure data consistency and improve the accuracy and real-time performance of service monitoring. This allows users to focus more on business, and expedites the real-time transformation of business. In addition, the 24-hour O&M service of Alibaba Cloud ensures cluster stability and zero failure.
Internet industry: Cloud big data warehouse for Babytree
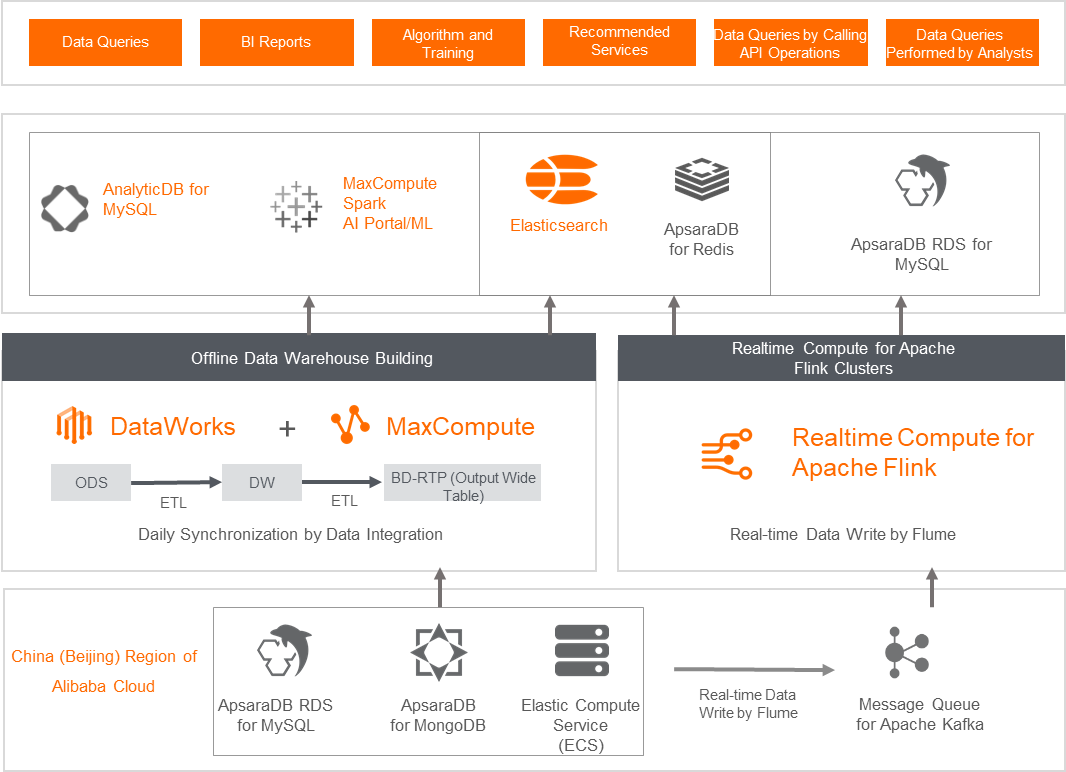
Background
Babytree, founded in 2007, is the largest and most active community platform for maternity and infant care in China. As one of the first customer-oriented community platforms over the Internet, Babytree has its own data centers from the early start, and the scale of these data centers rapidly grow.
Customer requirements
These data centers provide poor performance and are difficult to manage. The company urgently needs a solution that supports comprehensive big data governance.
The annual costs of these data centers are high. The company wants a solution that can reduce costs and improve efficiency.
Value embodiment
The solution provided by Alibaba Cloud is developed based on the overall principle of cost reduction and efficiency improvement. After data is migrated to MaxCompute, Realtime Compute for Apache Flink, and DataWorks, the performance of specific tasks can be improved by more than 10 times and the data storage is reduced from 3 PB in a self-managed Hadoop system to 900 TB in the cloud. In addition, with the real-time data processing capabilities of Realtime Compute for Apache Flink, the solution can perform real-time processing on the existing scenarios of Babytree and make real-time recommendations to increase the behavior conversion rate. For example, the solution can take real-time actions based on user IDs and content types, obtain real-time group chat IDs of users, and obtain real-time information about article publishing. The solution helps the company reduce the overall costs by more than 30%.
Game industry: Full-link game operation for DeNA China
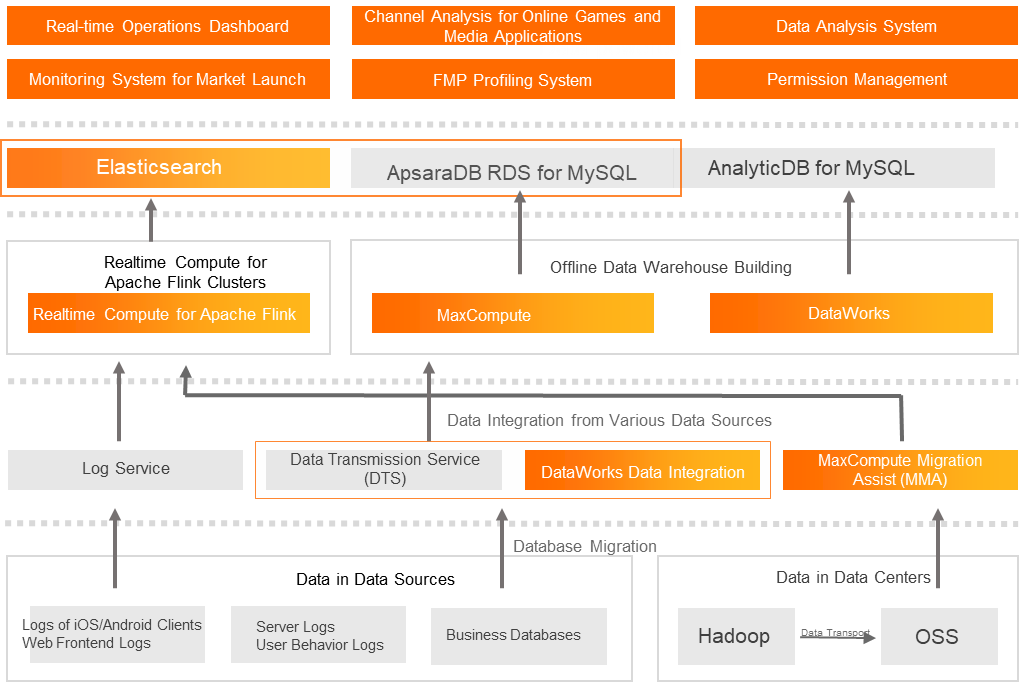
Background
DeNA is an excellent game service provider. As the lifecycle of game projects get shorter, a cost-effective, efficient, and refined data operation system is required to manage each project stage in real time with precision.
Customer requirements
The company has two clusters that separately run on Hadoop 1.0 and 2.0. This makes the technical architecture complex and reduces the stability, security, and scaling performance of the platform.
The company has diversified log sources and high demands for real-time performance. As the log volume increases, the performance and stability of the Fluentd-based log collection service are greatly affected.
The data development is based on manual coding. The business efficiency is low and the Hive-based computing performance cannot meet the requirements.
Value embodiment
DeNA China is the first company that uses Lightning Cube together with MMA in the game industry. About 300-TB incremental data and 50-TB historical data accumulated in the RDS databases of the company over the past 10 years are successfully migrated to the cloud within only over a month, even without the use of leased lines. The process is technically complex. Compared with the original task management system that uses the open source Python-based Airflow, DataWorks provides the following benefits:
The task management is clearly presented. If a task error occurs, the system can locate and fix the error at the earliest opportunity.
The game business has hundreds of data sources. These data sources can be managed at one time without the need of redundant efforts and can be used in various data services.
DataWorks provides various features for users to schedule resources based on the GUI without manual efforts or extra coding. This allows users to focus more on the management and development.
After data is migrated to the cloud, the Apsara big data platform of Alibaba Cloud helps the company manage data operations throughout the entire link from data collection, storage, and computing, to real-time or offline analysis.