This topic describes common issues related to offline synchronization.
Document overview
You can search for keywords in this document to find common issues and their solutions.
Network communication issues
Why does the data source connectivity test succeed, but the offline sync task fails to connect to the data source?
Why does an offline sync task sometimes succeed and sometimes fail?
Resource setting issues
An offline sync task fails with the error: [TASK_MAX_SLOT_EXCEED]:Unable to find a gateway that meets resource requirements. 20 slots are requested, but the maximum is 16 slots.
An offline sync task fails with the error: OutOfMemoryError: Java heap space
Task instance conflict
An offline task fails with the error: Duplicate entry 'xxx' for key 'uk_uk_op'
Running timeout
An offline sync task with a MongoDB source fails with the error: MongoDBReader$Task - operation exceeded time limitcom.mongodb.MongoExecutionTimeoutException: operation exceeded time limit.
An offline sync task with a MySQL data source fails with a connection timeout error: Communications link failure
How do I troubleshoot long-running offline sync tasks?
A data sync task slows down because the WHERE clause lacks an index, leading to a full table scan
Switch resource groups
How do I switch the execution resource group for an offline sync task?
Dirty data
How do I troubleshoot and locate dirty data?
How do I view dirty data?
You can go to the log details page and click Detail log url to view the offline sync log and dirty data information.
If the number of dirty data records exceeds the limit during an offline sync task, will the data that has already been synchronized be retained?
How do I handle dirty data errors caused by encoding format settings or garbled text?
Retain source table default values
If a source table has default values, will they be retained in a target table created by Data Integration, along with NOT NULL constraints?
Shard key
Can a composite primary key be used as a shard key when configuring an offline integration task?
Missing data
After data synchronization, the data in the target table is inconsistent with the source table
SSRF attack
SSRF attacks in tasks Task have SSRF attacks: How to resolve?
Date writing
When writing date and time data to a text file, how do I retain milliseconds or specify a custom date and time format?
After you switch the sync task to the code editor, add the following configuration item in the setting section of the task configuration page:
"common": {
"column": {
"dateFormat": "yyyyMMdd",
"datetimeFormatInNanos": "yyyyMMdd HH:mm:ss.SSS"
}
}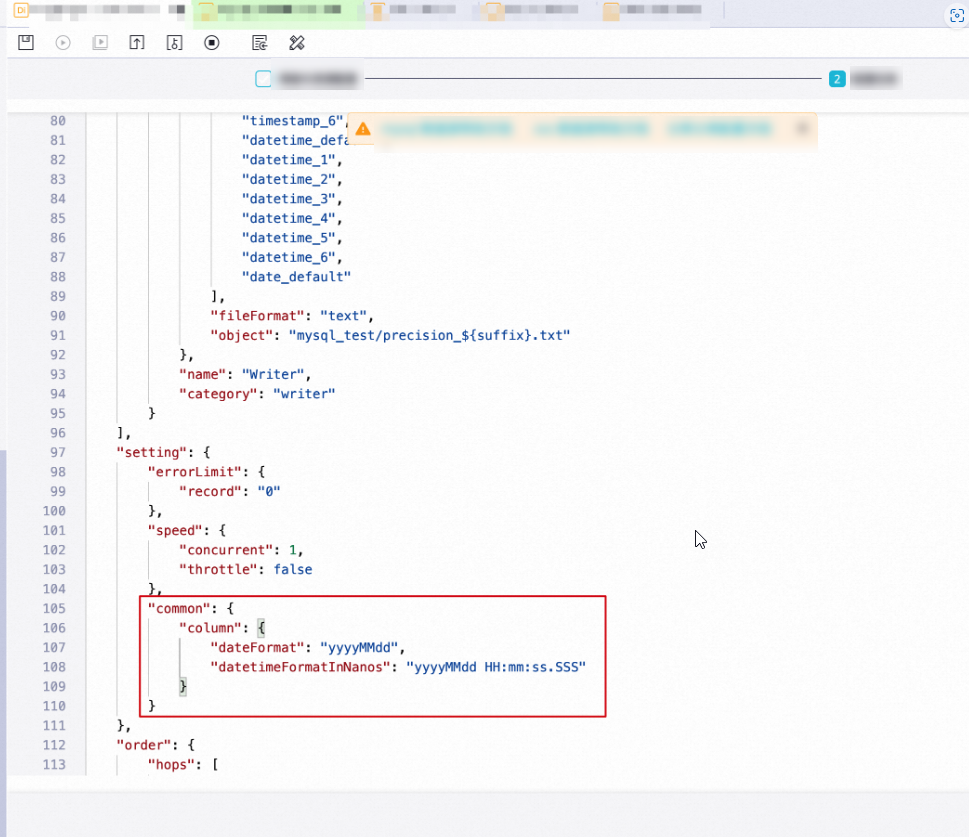
Where:
`dateFormat` specifies the date format to use when a source `DATE` type (without time) is converted to text.
`datetimeFormatInNanos` specifies the date format to use when a source `DATETIME` or `TIMESTAMP` type (with time) is converted to text, with precision up to the millisecond.
MaxCompute
Notes on "Add Row" or "Add Field" for source table fields when reading data from a MaxCompute (ODPS) table
When reading data from a MaxCompute (ODPS) table, how do I synchronize partition fields?
In the field mapping list, under Source table fields, click Add Row or Add Field. Enter the partition column name, such as pt, and configure its mapping to the target table field.

When reading data from a MaxCompute (ODPS) table, how do I synchronize data from multiple partitions?
How do I perform column filtering, reordering, and null padding in MaxCompute?
Handling MaxCompute column configuration errors
Notes on MaxCompute partition configuration
MaxCompute task reruns and failover
An error occurs when reading data from a MaxCompute (ODPS) table: The download session is expired.
An error occurs when writing to MaxCompute (ODPS): Error writing request body to server
MySQL
How do I synchronize sharded MySQL tables into a single MaxCompute table?
When the destination MySQL table's character set is utf8mb4, how do I handle garbled Chinese characters after synchronization?
An error occurs when writing to or reading from MySQL: Application was streaming results when the connection failed. Consider raising value of 'net_write_timeout/net_read_timeout' on the server.
Cause:
`net_read_timeout`: DataX splits the data from RDS for MySQL into several equal data retrieval SQL statements (`SELECT` statements) based on `SplitPk`. When the execution time of an SQL statement exceeds the maximum allowed running time on the RDS side, this error occurs.
`net_write_timeout`: The timeout period for waiting to send a block to the client is too short.
Solution:
Add the `net_write_timeout` or `net_read_timeout` parameter to the data source URL connection and set a larger value, or adjust this parameter in the RDS console.
Suggestion:
If the task can be rerun, set the task to automatically rerun on error.
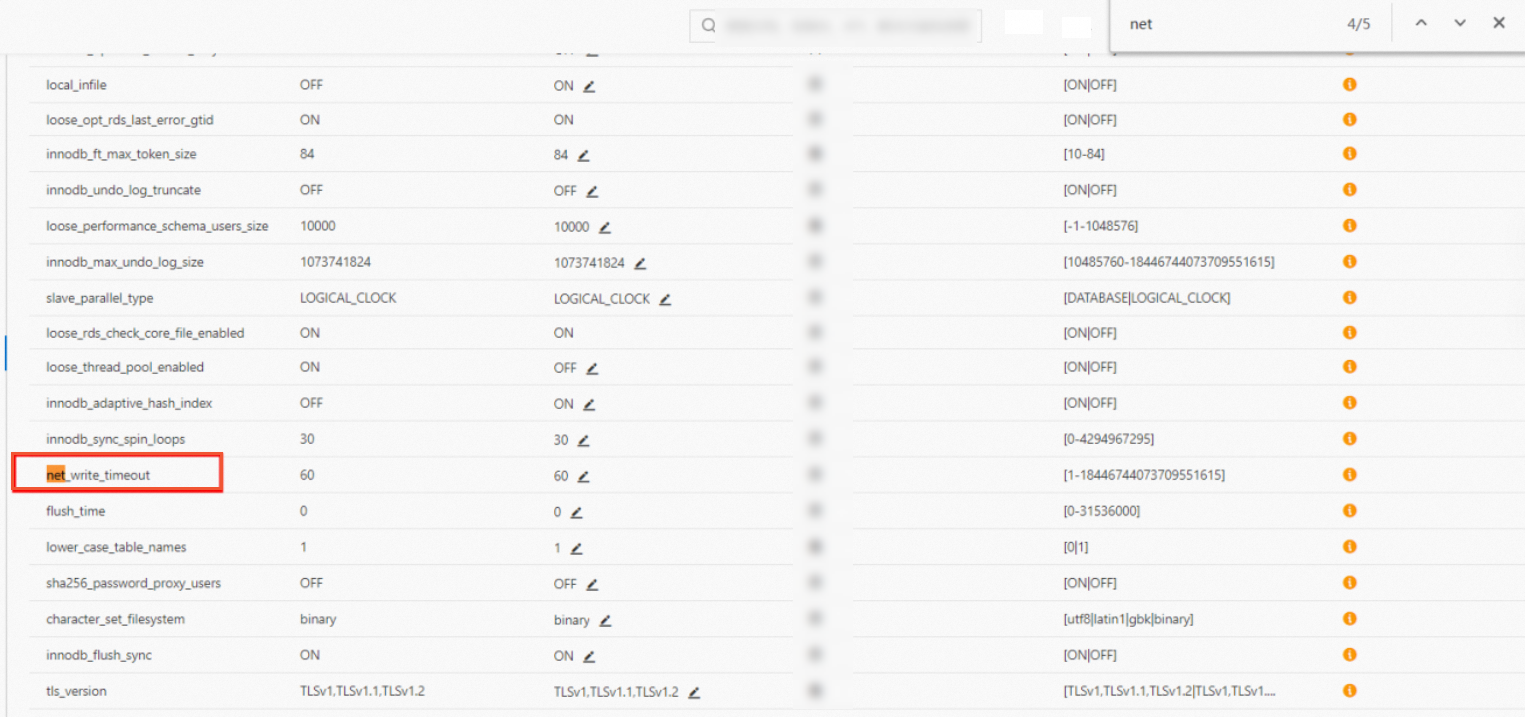
For example: jdbc:mysql://192.168.1.1:3306/lizi?useUnicode=true&characterEncoding=UTF8&net_write_timeout=72000
An offline sync task to MySQL fails with an error: [DBUtilErrorCode-05]ErrorMessage: Code:[DBUtilErrorCode-05]Description:[Failed to write data to the configured destination table.]. - com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: No operations allowed after connection closed
An error occurs when reading from a MySQL database: The last packet successfully received from the server was 902,138 milliseconds ago
PostgreSQL
An error occurs when reading data from PostgreSQL: org.postgresql.util.PSQLException: FATAL: terminating connection due to conflict with recovery
RDS
An offline sync task with an Amazon RDS source fails with the error: Host is blocked
MongoDB
Why do I get an error when adding a MongoDB data source with the root user?
When reading from MongoDB, how do I use a timestamp in the query parameter to perform incremental synchronization?
After synchronizing data from MongoDB to a destination data source, the time zone is shifted by +8 hours. How do I fix this?
During data reading from MongoDB, records are updated in the source but not synchronized to the destination. How do I handle this?
Is MongoDB Reader case-sensitive?
How do I configure the timeout duration for MongoDB Reader?
An error occurs when reading from MongoDB: no master
An error occurs when reading from MongoDB: MongoExecutionTimeoutException: operation exceeded time limit
An offline sync task reading from MongoDB fails with the error: DataXException: operation exceeded time limit
A MongoDB sync task fails with the error: no such cmd splitVector
Possible cause:
When a sync task runs, it uses the
splitVectorcommand for task sharding by default. Some MongoDB versions do not support thesplitVectorcommand, which leads to theno such cmd splitVectorerror.Solution:
Go to the sync task configuration page and click the Convert to script
 button. Change the task to the code editor.
button. Change the task to the code editor.In the MongoDB parameter configuration, add the parameter
"useSplitVector" : falseto avoid using
splitVector.
A MongoDB offline sync task fails with the error: After applying the update, the (immutable) field '_id' was found to have been altered to _id: "2"
Symptom:
This issue may occur in a sync task, such as in the codeless UI, if Write Mode (Overwrite) is set to Yes and a field other than
_idis configured as the Business Primary Key.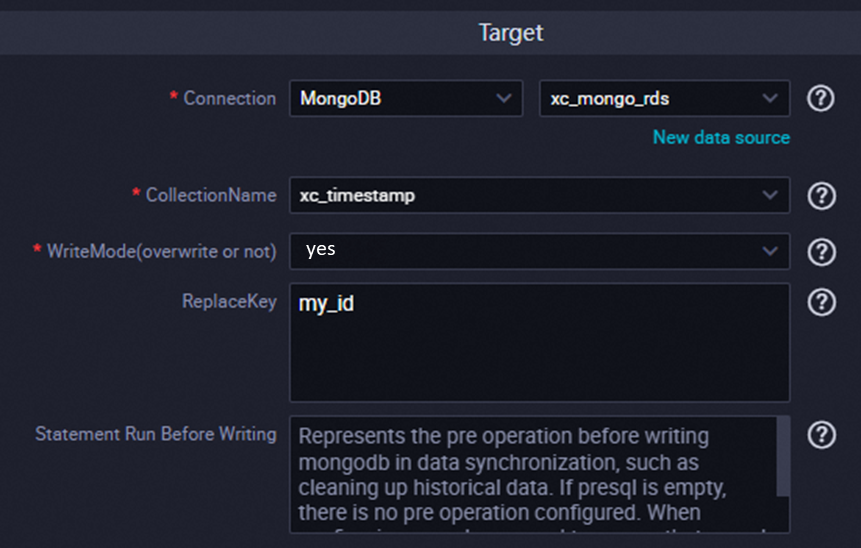
Possible cause:
The data contains records whose _id does not match the configured Business Primary Key (such as
my_idin the example configuration above).Solution:
Solution 1: Modify the offline sync task to ensure that the configured Business Primary Key is consistent with the _id.
Solution 2: Use _id as the business primary key for data synchronization.
Redis
When writing to Redis in hash mode, an error occurs: Code:[RedisWriter-04], Description:[Dirty data]. - source column number is in valid!
OSS
When reading a CSV file with multiple delimiters, how do I handle dirty data?
Is there a limit on the number of files that can be read from OSS?
When writing to OSS, how do I remove the random string that appears in the filename?
An error occurs when reading data from OSS: AccessDenied The bucket you access does not belong to you.
Hive
An offline sync task to a local Hive instance fails with the error: Could not get block locations.
DataHub
When writing to DataHub, how do I handle a write failure caused by exceeding the single-write data limit?
LogHub
When reading from LogHub, a field with data is synchronized as empty
Data is missing when reading from LogHub
When reading from LogHub, the mapped fields are not as expected
Lindorm
When using the Lindorm bulk method to write data, is historical data replaced every time?
Elasticsearch
How do I query all fields under an ES index?
When synchronizing data offline from ES to other data sources, the index name changes daily. How do I configure this?
You can add date scheduling variables to the index configuration. This allows the index string to be calculated based on different dates, which enables automatic changes to the Elasticsearch Reader's index name. The configuration process includes three steps: defining date variables, configuring the index variable, and publishing and executing the task.
Define date variables: In the sync task's scheduling configuration, select Add Parameter to define date variables. In the example below, `var1` is configured to represent the task execution time (current day), and `var2` represents the task's data timestamp (previous day).
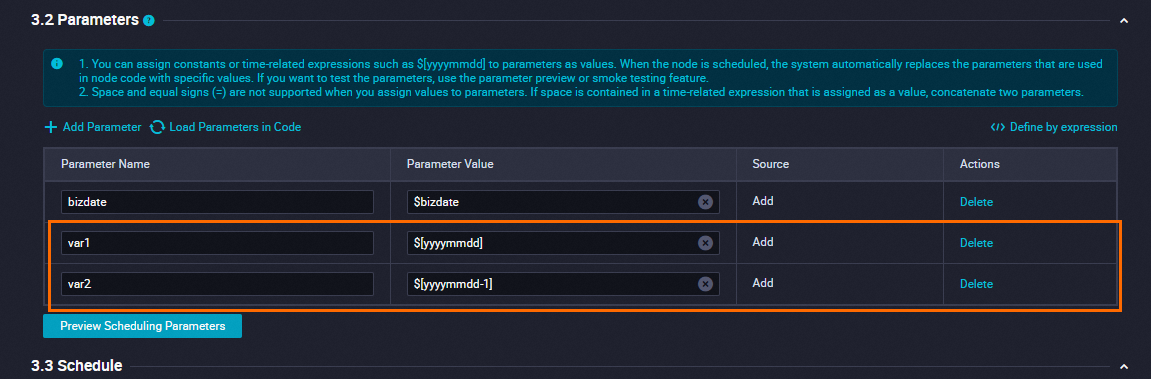
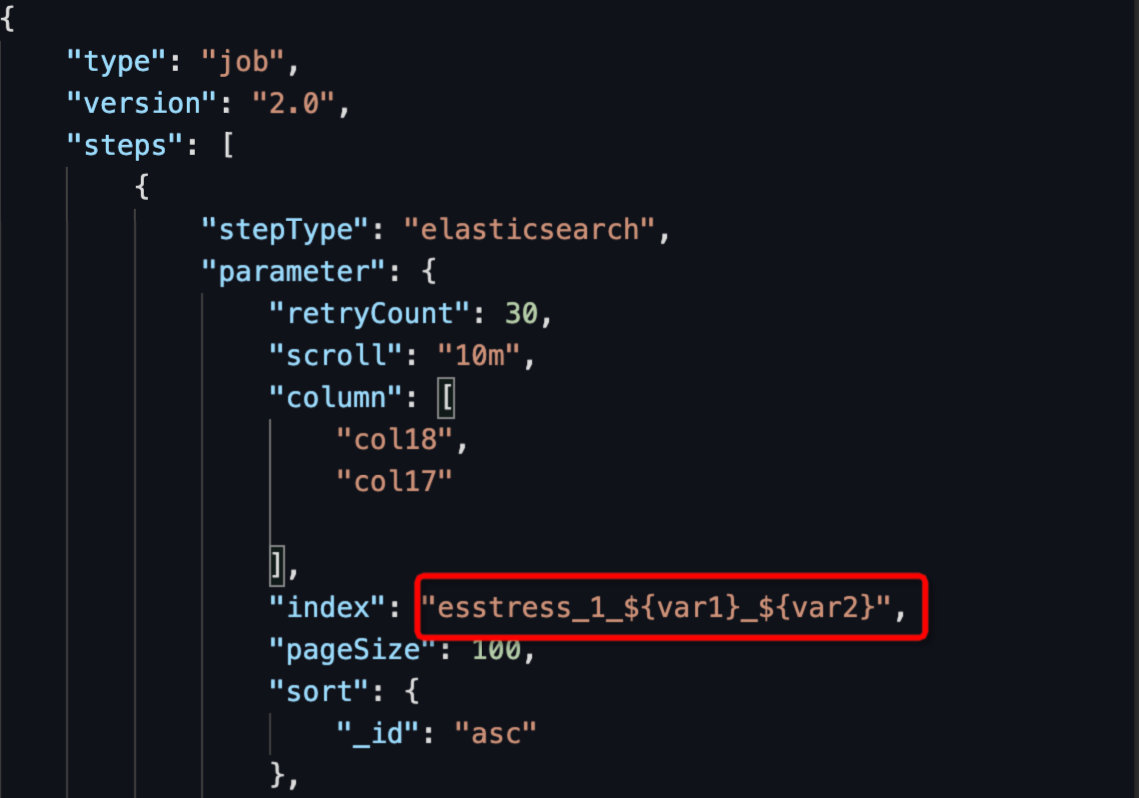
Configure the index variable: Switch the task to the code editor and configure the Elasticsearch Reader's index. The configuration format is: `${variable_name}`, as shown in the figure below.
Publish and execute the task: After validation, submit and publish the task to the Operation Center, and run it using a recurring schedule or data backfill.
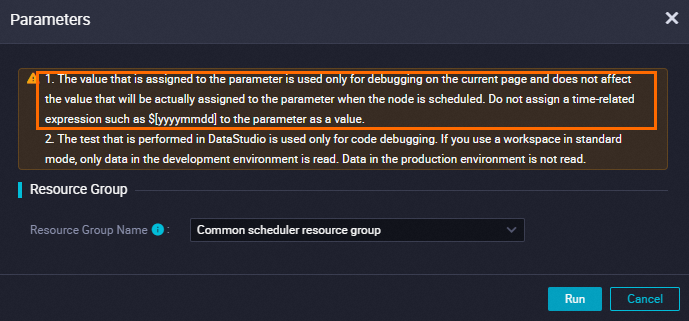
Click the Run With Parameters button to run the task for validation. This action replaces the scheduling system parameters in the task configuration. After the task is complete, check the logs to verify that the synchronized index is as expected.
NoteWhen you run with parameters, directly enter the parameter values for testing.
If the validation is successful, you can click Save and Submit to add the sync task to the production environment.

For a standard project, click the Publish button to open the publishing center and publish the sync task to the production environment.

Result: The following figure shows the configuration and the actual index result from the run.
Script index configuration:
"index": "esstress_1_${var1}_${var2}".Running index replaced as:
esstress_1_20230106_20230105.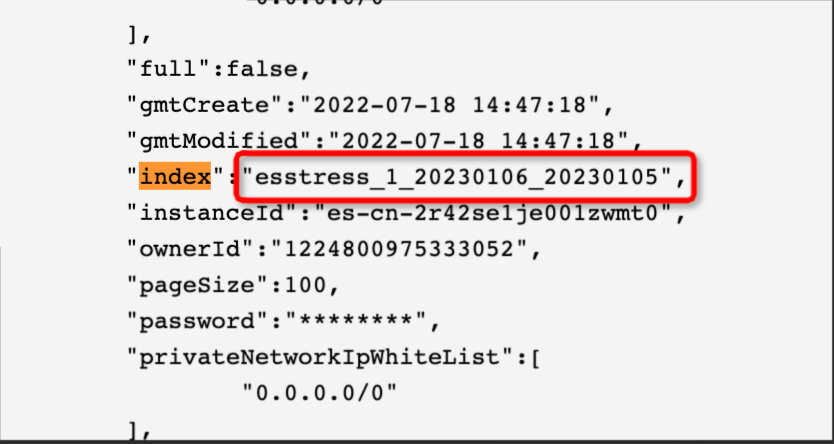
How does Elasticsearch Reader synchronize properties of Object or Nested fields? (e.g., synchronizing object.field1)
After synchronizing a string type from ODPS to ES, the surrounding quotes are missing. How do I fix this? Can a JSON-type string from the source be synchronized as a NESTED object in ES?
The extra double quotes around the characters are a display issue in the Kibana tool. The actual data does not have these surrounding double quotes. You can use a curl command or Postman to view the actual data. The curl command to obtain the data is as follows:
//es7 curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/_mapping' //es6 curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/typename/_mapping'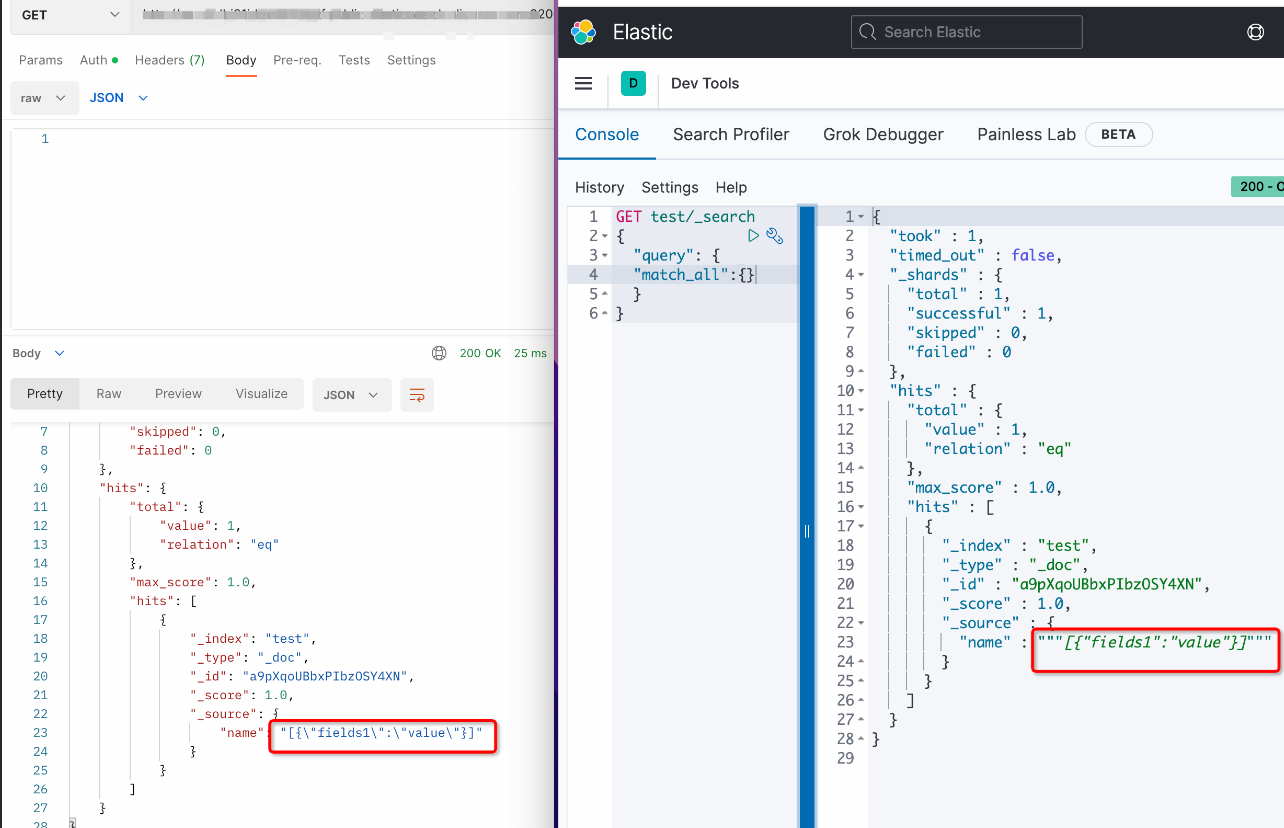
You can configure the ES write field type as `nested` to synchronize JSON-type string data from ODPS to ES and store it in nested format. The following example synchronizes the `name` field to ES in nested format.
Sync configuration: Configure the type of `name` as nested.
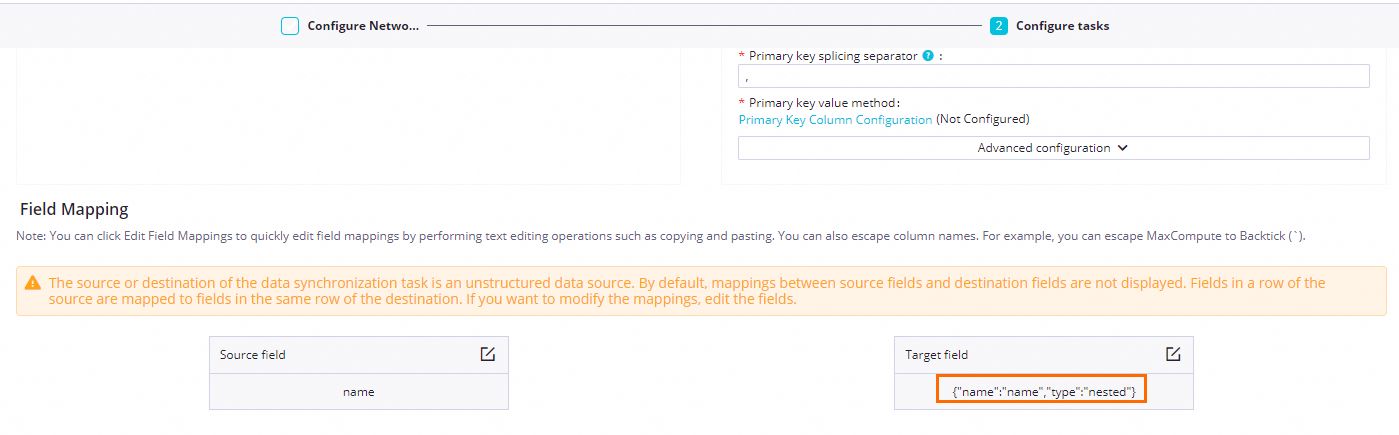
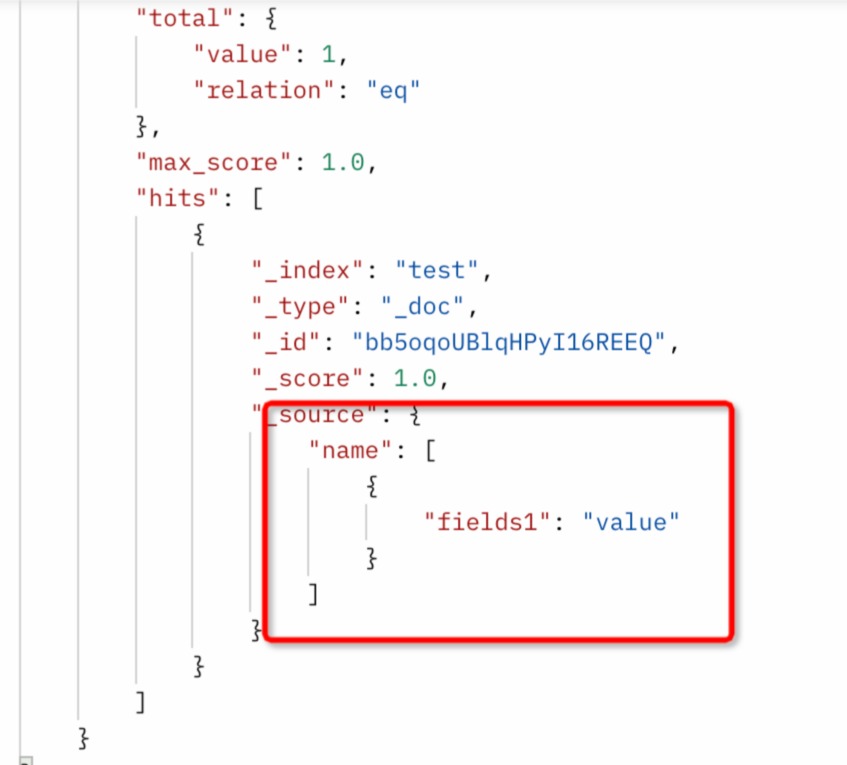
Sync result: `name` is a nested object type.
If the source data is the string "[1,2,3,4,5]", how can I synchronize it to ES as an array?
There are two ways to configure writing to ES as an array type. You can choose the appropriate synchronization method based on the source data format.
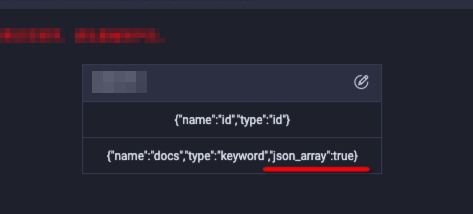
Write to ES as an array type by parsing the source data in JSON format. For example, if the source data is `"[1,2,3,4,5]"`, configure
json_array=trueto parse the source data and write it to the ES field as an array. Set ColumnList tojson_array=true.Codeless UI configuration:
Code editor configuration:
"column":[ { "name":"docs", "type":"keyword", "json_array":true } ]
Write to ES as an array type by parsing the source data with a delimiter. For example, if the source data is `"1,2,3,4,5"`, configure the delimiter `splitter=","` to parse and write it to the ES field as an array.
Limitations:
Only one type of delimiter is supported per task. The splitter is globally unique. You cannot configure different delimiters for multiple Array fields. For example, if the source columns are
col1="1,2,3,4,5" , col2="6-7-8-9-10", you cannot configure a separate splitter for each column.The splitter can be a regular expression. For example, if the source column value is `"6-,-7-,-8+,*9-,-10"`, you can configure `splitter:".,."`. This is supported in the codeless UI.
Codeless UI configuration:
 splitter: Defaults to "-,-"
splitter: Defaults to "-,-"Code editor configuration:
"parameter" : { "column": [ { "name": "col1", "array": true, "type": "long" } ], "splitter":"," }
When writing data to ES, a submission is made without a username, but username validation is still required, causing the submission to fail and all requested data to be logged. This generates many audit logs daily. How do I handle this?
How do I synchronize data to ES as a Date type?
Elasticsearch Writer fails to write data due to a specified external version. How do I handle this?
An offline sync task reading from Elasticsearch fails with the error: ERROR ESReaderUtil - ES_MISSING_DATE_FORMAT, Unknown date value. please add "dataFormat". sample value:
An offline sync task reading from Elasticsearch fails with the error: com.alibaba.datax.common.exception.DataXException: Code:[Common-00].
An offline sync task writing to Elasticsearch fails with the error: version_conflict_engine_exception.
An offline sync task writing to Elasticsearch fails with the error: illegal_argument_exception.
Cause analysis:
When you configure advanced properties such as `similarity` or `properties` for a Column field, `other_params` is required for the plugin to recognize them.
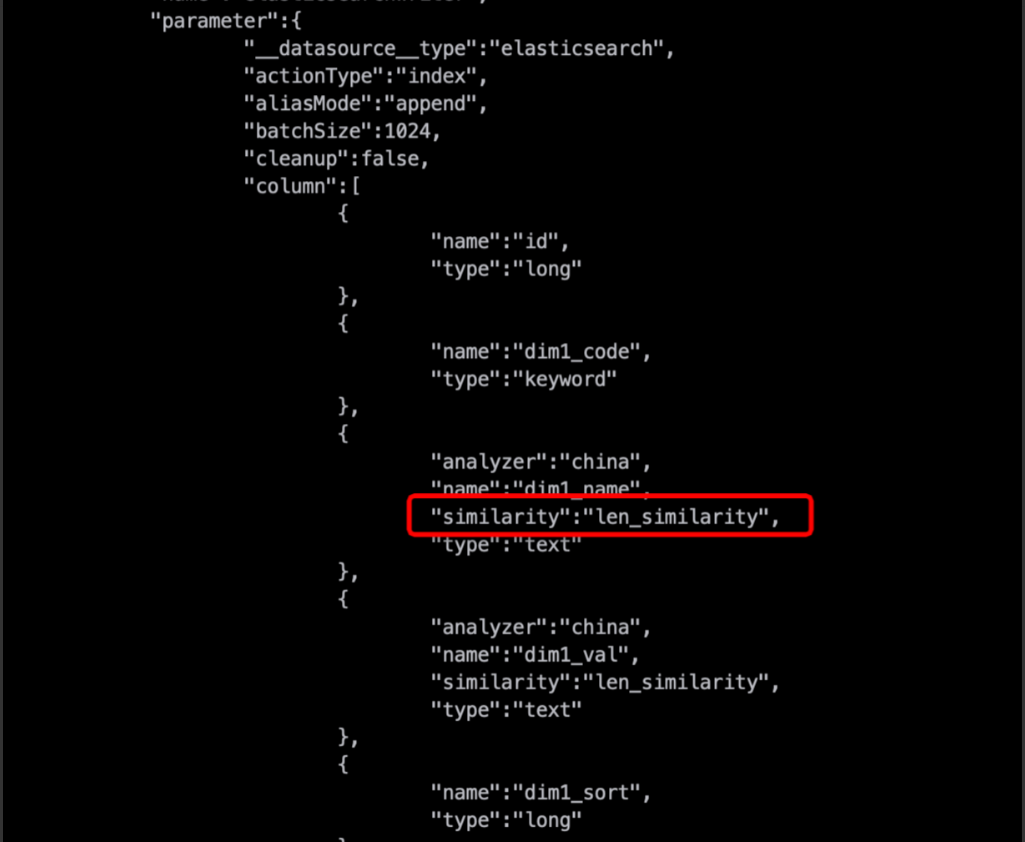
Solution:
Configure
other_paramsin the Column, and add `similarity` withinother_params, as shown below:{"name":"dim2_name",...,"other_params":{"similarity":"len_similarity"}}
An offline sync task from an ODPS Array field to Elasticsearch fails with the error: dense_vector
Why don't the settings configured in Elasticsearch Writer take effect when creating an index?
Why does a property of the nested type in my self-built index change to the keyword type after automatic generation? (Automatic generation refers to executing a sync task with cleanup=true configured.)
Kafka
When reading from Kafka, endDateTime is configured to specify the data range, but data beyond this time is found in the destination
Why does a task with a small amount of data in Kafka keep running for a long time without reading data or finishing?
RestAPI
RestAPI Writer reports an error: The JSON string found through path:[] is not an array type
RestAPI Writer provides two write modes. When you synchronize multiple data records, you need to configure `dataMode` as `multiData`. For more information, see RestAPI Writer. You also need to add the parameter `dataPath:"data.list"` in the RestAPI Writer script.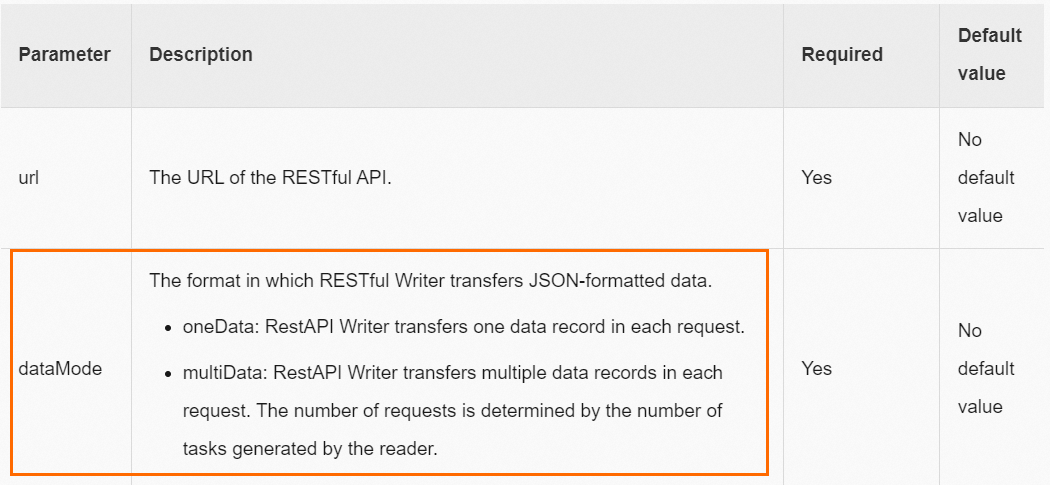
You do not need to add the "data.list" prefix when you configure Column.
OTS Writer configuration
How do I configure OTS Writer to write data to a target table that contains an auto-increment primary key column?
Time series model configuration
In a time series model configuration, what do the _tag and is_timeseries_tag fields mean?
Example: A data record has three tags: `[phone=Xiaomi, memory=8G, camera=Leica]`.
Data exporting example (OTS Reader)
If you want to merge the above tags into a single column for export, configure as follows:
"column": [ { "name": "_tags", } ],DataWorks exports the tags as a single column of data, in the following format:
["phone=xiaomi","camera=LEICA","RAM=8G"]If you want to export the
phoneandcameratags so that each tag is in a separate column, use the following configuration:"column": [ { "name": "phone", "is_timeseries_tag":"true", }, { "name": "camera", "is_timeseries_tag":"true", } ],The following two columns of data are obtained:
xiaomi, LEICA
Data import example (OTS Writer)
Suppose the upstream data source (Reader) has two columns of data:
One column of data is:
["phone=xiaomi","camera=LEICA","RAM=8G"].The other column of data is: 6499.
If you want to add both of these columns to the tags, with the expected tag field format after writing as shown below:
 Then configure as follows:
Then configure as follows:"column": [ { "name": "_tags", }, { "name": "price", "is_timeseries_tag":"true", }, ],The first column configuration imports
["phone=xiaomi","camera=LEICA","RAM=8G"]as a whole into the tag field.The second column configuration imports
price=6499separately into the tag field.
Custom table names
How do I customize table names for offline sync tasks?
If your table names follow a regular pattern, such as orders_20170310, orders_20170311, and orders_20170312, are distinguished by day, and have consistent table structures, you can combine scheduling parameters with code editor configuration to customize table names. This lets you automatically read the previous day's table data from the source database every morning.
For example, if today is March 15, 2017, the task automatically reads data from the orders_20170314 table and imports it.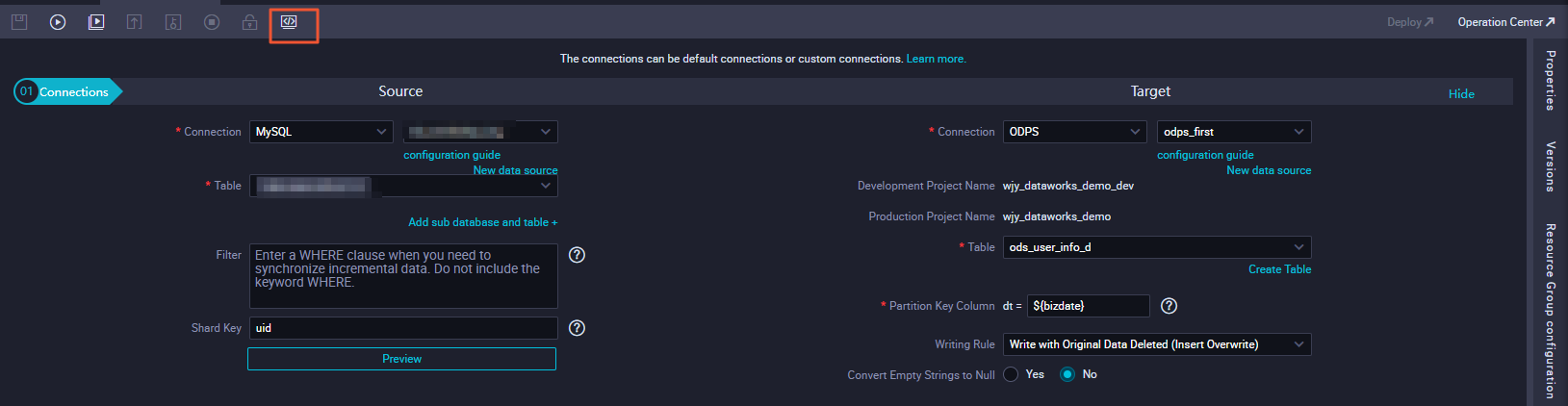
In the code editor, change the source table name to a variable, for example, orders_${tablename}. Because the table names are distinguished by day and you need to read the previous day's data each day, in the task's parameter configuration, assign the variable as tablename=${yyyymmdd}.
For more information about how to use scheduling parameters, see Supported formats of scheduling parameters.
Table modification and column addition
How do I handle adding or modifying columns in the source table of an offline sync task?
Task configuration issues
When configuring an offline sync node, I cannot view all tables. How do I handle this?
Table/column name keywords
How do I handle sync task failures caused by keywords in table or column names?
Cause: The column contains a reserved word, or the column configuration contains a field that starts with a number.
Solution: Switch the Data Integration sync task to the code editor and escape the special fields in the column configuration. For more information about how to configure a task in the code editor, see Configure a sync node in the code editor.
The escape character for MySQL is
`keyword`.The escape character for Oracle and PostgreSQL is
"keyword".The escape character for SQL Server is
[keyword].
MySQL example:
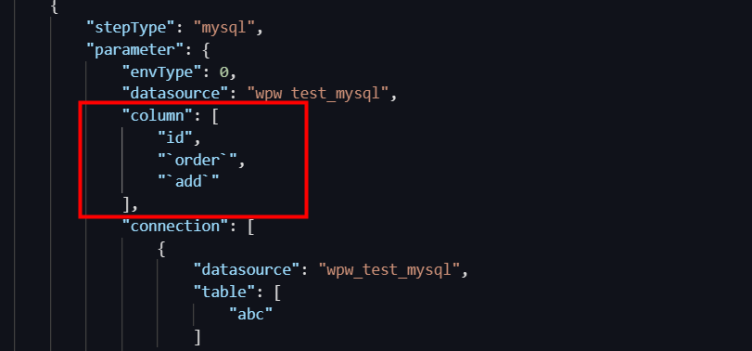
Take a MySQL data source as an example:
Run the following statement to create a new table named `aliyun`.
create table aliyun (`table` int ,msg varchar(10));Run the following statement to create a view and give an alias to the `table` column.
create view v_aliyun as select `table` as col1,msg as col2 from aliyun;Note`table` is a MySQL keyword. The code generated during data synchronization causes an error. Therefore, you need to create a view to give an alias to the `table` column.
Do not use keywords as table column names.
By running the above statement, you can assign an alias to the column that has a keyword. When you configure the sync task, select the `v_aliyun` view instead of the `aliyun` table.
Field mapping
An offline task fails with the error: plugin xx does not specify column
For an unstructured data source, fields cannot be mapped when I click Data Preview. How do I handle this?
Symptom:
When you click Data Preview, the following message is displayed, indicating that a field exceeds the maximum byte size.
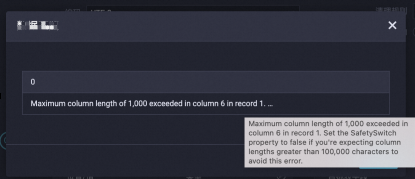
Cause: To avoid an out-of-memory (OOM) error, the data source service checks the length of fields when it processes a data preview request. If a single column exceeds 1,000 bytes, the above message appears. This message does not affect the normal operation of the task. You can ignore this error and run the offline sync task directly.
NoteIf the file exists and connectivity is normal, other reasons for data preview failure include the following:
The byte size of a single row in the file exceeds the limit of 10 MB. In this case, no data is displayed, similar to the message above.
The number of columns in a single row of the file exceeds the limit of 1,000. In this case, only the first 1,000 columns are displayed, and a message is shown at the 1001st column.