You can backfill data for a historical or future period to write the data to corresponding time-based partitions. During a data backfill, scheduling parameters in the code are automatically replaced with specific values based on the selected business time. The business code then writes data for the corresponding time to specified partitions. The destination partitions are determined by the logic and content of the task code.
Permission restrictions
You must have operation permissions for all nodes in the data backfill workflow. If you lack permission for any node, the following consequences will occur:
No permission on direct target nodes: If you do not have operation permissions for the root node or any of its descendant nodes, the data backfill cannot be executed.
No permission on intermediate nodes: If a node for which you lack permissions is an intermediate node in the data backfill process, meaning both its upstream and downstream dependencies are within the backfill scope, the system performs a dry-run on that node.
Dry-run description: After the node starts, it does not run the actual computing logic. Instead, it immediately returns a "Succeeded" status to ensure that its descendant nodes can be triggered.
Risk warning: A dry-run on an intermediate node does not produce actual data. This may cause its descendant nodes to produce abnormal output or fail because of a lack of input. Proceed with caution.
Precautions
To ensure the stability and predictability of data backfill operations, carefully read the following execution rules.
I. Instance lifecycle and log retention
Instance cleanup: Data backfill instances cannot be manually deleted. The platform automatically cleans them up approximately 30 days after creation. If a task no longer needs to run, you can freeze its instance to stop its scheduling.
Retention policy: The retention period for instances and logs varies by resource group.
Resource group type
Instance retention policy
Log retention policy
Shared resource group for scheduling
30 days
7 days
Exclusive resource group for scheduling
30 days
30 days
Serverless resource group
30 days
30 days
Large log cleanup: For completed instances, the platform regularly cleans up run logs that exceed 3 MB each day.
II. Instance running rules
Strict day-by-day dependency: Data backfill is performed sequentially based on the data timestamp. Instances for the next day start only after all instances for the previous day have succeeded. If any instance fails, it blocks all tasks for subsequent dates.
Concurrent behavior of hourly and minutely tasks: When you backfill data for all instances on a specific day, the execution method is determined by the task's self-dependency property:
Self-dependency not set: All instances within the day, such as 00:00 and 01:00, are allowed to run in groups, as long as their respective upstream dependencies are met.
Self-dependency set: All instances within the day run in strict sequential execution. For example, the 01:00 instance waits for the 00:00 instance to succeed before it runs.
Conflict with auto triggered instances: To ensure regular scheduling, auto triggered instances have a higher priority than data backfill instances. If both are running at the same time, you must manually stop the data backfill instance.
Blacklisted node handling: If a blacklisted node is an intermediate node in the data backfill workflow, that node also performs a dry-run, which may affect the data output of its descendant nodes.
III. Scheduling resources and priority
Configure resources reasonably: Too many data backfill instances or a high degree of parallelism consumes a large amount of scheduling resources, which may affect the normal operation of auto triggered tasks. You should configure resources as needed.
Priority degradation policy: To protect core business operations, the platform dynamically adjusts task priorities based on the data timestamp of the backfill:
Backfilling data for the previous day (T-1): The task priority remains unchanged and is determined by the priority of the baseline to which the task belongs.
Backfilling historical data (T-2 or earlier): The task priority is automatically degraded according to the following rules:
Original priority 7 or 8 → Degraded to 3
Original priority 5 or 3 → Degraded to 2
Original priority 1 → Remains unchanged
Create a data backfill task
Step 1: Go to the Data Backfill page
Go to the Operation Center page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Operation Center.
In the navigation pane on the left, click .
To backfill data for an auto triggered task, you can also click Backfill Data for the corresponding task on the page.
Step 2: Create a data backfill task
On the Data Backfill page, click Create Data Backfill Task and configure the parameters as needed.
Configure Basic Information.
The platform automatically generates a data backfill name in the default format. You can modify the name as needed.
Select the nodes for which to backfill data.
You can backfill data for tasks that you have permission to operate on using one of the following methods: Manually Select, Select by Link, Select by Workspace, and Specify Task and All Descendent Tasks. Based on a selected task, you can also select other tasks for which to backfill data. The configuration parameters are different for each method.
Manually Select
Select one or more nodes as root nodes, and then select the descendant nodes of the root nodes as the scope for this data backfill. This method is compatible with the original Current Node, Current Node and Descendant Nodes, and Advanced Mode data backfill solutions.
The following table describes the parameters.
Parameter
Description
Task Selection Method
Select Manually Select.
Add Root Tasks
You can search for and add a root task by name or ID. You can also click Batch Add and specify conditions such as resource group, scheduling cycle, and workspace to add multiple root tasks at a time.
NoteYou can only select nodes from workspaces where you are a member.
Selected Root Tasks
The nodes for which to backfill data. The list displays the added root nodes. You can select the descendant nodes for which to backfill data based on the root nodes.
NoteYou can filter descendant nodes based on the level of dependency. The direct descendant nodes of a root node are at the first level by default, and so on.
The maximum number of root nodes for which data can be backfilled at the same time is 500. The maximum total number of nodes (root nodes and their descendant nodes) is 2,000 (3,000 in the China (Beijing) and China (Hangzhou) regions).
Blocklist
If a node does not require data backfill, add it to the blacklist. Nodes in the blacklist will not be included in this data backfill.
NoteYou can only add root tasks to the blacklist. If data backfill is not required for the child tasks of a root task, remove them from the SSelected Root Tasks.
If a blacklisted node is an intermediate node in this data backfill (meaning its upstream and downstream dependencies are within the backfill scope), the node will perform a dry-run to ensure its descendant nodes can run. A dry-run immediately returns a success status without actually running. However, this may cause abnormal data output for the descendant nodes.
Select by link
Select a start node and one or more end nodes. Through automatic analysis, all nodes between the start and end nodes are included in the scope of this data backfill, including the start and end nodes.
The following table describes the parameters.
Parameter
Description
Task Selection Method
Select by Link.
Select Tasks
Search by name or ID to add a start node and one or more end nodes. The platform will analyze the intermediate nodes based on the start and end nodes. An intermediate node is a direct or indirect descendant of the start node and a direct or indirect ancestor of the end node.
Intermediate Tasks
The list of intermediate nodes automatically analyzed by the platform based on the start and end nodes.
NoteThe list displays only 2,000 nodes. Nodes beyond this limit will not be displayed but will be executed normally.
Blocklist
If a node does not require data backfill, add it to the blacklist. Nodes in the blacklist will not be included in this data backfill.
NoteIf a blacklisted node is an intermediate node in this data backfill (meaning its upstream and downstream dependencies are within the backfill scope), the node will perform a dry-run to ensure its descendant nodes can run. A dry-run immediately returns a success status without actually running. However, this may cause abnormal data output for the descendant nodes.
Select by Workspace
Select a node as the root node and determine the scope of this data backfill based on the workspaces where the descendant nodes are located.
NoteThe original plan of backfilling data for massive nodes is compatible with this method.
Configuring a node blacklist is not supported.
The following table describes the parameters.
Parameter
Description
Task Selection Method
Select by Workspace.
Add Root Tasks
Search for and add root nodes by name or ID. The platform will backfill data for nodes in the workspaces where the descendant nodes of the root node are located.
NoteYou can only select nodes from workspaces where you are a member.
Include Root Node
Defines whether this data backfill includes the root node.
Workspaces for Data Backfill
Based on the workspaces where the descendant nodes of the root node are located, select which workspaces' nodes need to have data backfilled.
NoteYou can only select DataWorks workspaces in the current region for data backfill operations.
After selecting a workspace, data is backfilled for all nodes in the workspace by default. You can customize the blacklists and whitelists for data backfill as needed.
Allowlist
Nodes that still require data backfill, in addition to the nodes included in the selected workspaces.
Blocklist
Nodes in the selected workspaces that do not require data backfill.
Specify Task and All Descendant Tasks
After you select a root node, the platform automatically analyzes and includes that node and all its descendant nodes in the scope of this data backfill.
ImportantYou can see the triggered nodes only when the data backfill task is running. Use this with caution.
The following table describes the parameters.
Parameter
Description
Task Selection Method
Specify Task and All Descendent Tasks.
Add Root Tasks
Search for and add root nodes by name or ID. The platform will backfill data for the root node and all its descendant nodes.
NoteYou can only select nodes from workspaces where you are a member.
If the selected root node has no descendant nodes, only the data for the current root node will be backfilled after the data backfill task is submitted.
Blocklist
If a node does not require data backfill, add it to the blacklist. Nodes in the blacklist will not be included in this data backfill.
NoteIf a blacklisted node is an intermediate node in this data backfill (meaning its upstream and downstream dependencies are within the backfill scope), the node will perform a dry-run to ensure its descendant nodes can run. A dry-run immediately returns a success status without actually running. However, this may cause abnormal data output for the descendant nodes.
Configure data backfill execution policies.
Configure information such as the running time, whether to execute in groups, whether to trigger alerts, and the resource group to be used for the data backfill task, as needed.
The following table describes the parameters.
Parameter
Description
Data Timestamp
You can specify the business dates for the data backfill task. Supported methods include manual entry, AI generation, and batch entry.
The system will apply different execution strategies based on the dates and options you select:Scenario 1: Backfill historical data (Data timestamp < Current date)
This is the most common data backfill scenario. When the selected data timestamp is earlier than today, the system immediately creates and runs the task instance for that historical date to backtrack and recalculate past data.
Use case: Fix historical data errors, backfill missing data.
Execution method: Execute immediately.
Scenario 2: Schedule a future task (Data timestamp > Current date)
If you select a future data timestamp and do not select any special options, this creates a future one-time scheduled task.
Use case: Pre-schedule a one-time task run for a known future date.
Execution method: Execute at the scheduled time. The instance is created and enters a waiting state. It will run automatically according to the task's own scheduling configuration when its corresponding data timestamp arrives.
Scenario 3: Run a future task in advance (Data timestamp > Current date, with Run immediately selected)
Run Retroactive Instances Scheduled to Run after the Current Time is an advanced option that lets you immediately start an instance that is scheduled to run in the future. The task's execution time is now, but the business logic and data partition it processes are for a future date.
Use case: Validate task logic for a future date in advance, or prepare data in specific partitions for data migration or testing.
Execution method: Execute immediately after selection.
Example: The current date is
2024-03-12. You choose to backfill data for2024-03-17and select the Run Retroactive Instances Scheduled to Run after the Current Time option. Then, the task instance will start immediately on2024-03-12, but the data timestamp parameter that it uses at runtime (for example, to determine the data partition) is2024-03-17.
NoteConcept of data timestamp: In offline computing, tasks typically process yesterday's (T-1) data today (T). The data backfill feature lets you precisely control which day's data a task processes by generating an instance for a specific "data timestamp".
Multiple time ranges: To backfill data for multiple non-consecutive dates, click [Add] to configure multiple time ranges.
Resource planning: A single data backfill should not span a long period. Many data backfill instances will consume scheduling resources and may affect the operation of regular auto triggered tasks.
Time Range
Specifies the time period during which the selected tasks need to be run. Instances whose scheduling time is within the time period can be generated and run. You can configure this parameter to allow tasks that are scheduled by hour or minute to backfill only data in the specified time period. Default value:
00:00 to 23:59.NoteInstances whose scheduling time is not within the time period are not generated. If tasks with longer cycles depend on tasks with shorter cycles (for example, daily tasks depending on hourly tasks), isolated instances may be generated and block task execution.
Modify this parameter only when hourly or minutely scheduled tasks need to backfill data for a specific period.
Run by Group
If you backfill data for multiple data timestamps, you can specify several groups to run the data backfill task concurrently. The values are:
Yes: The platform will generate multiple data backfill batches based on the specified number of groups and run the batches concurrently in groups.
No: Data backfill instances are run sequentially in the order of their data timestamps, where a new instance starts only after the previous one is complete.
NoteWhen you backfill data for a specific day for a task scheduled by hour or minute, whether instances for the task run concurrently in groups depends on whether self-dependency is set for the task.
You can specify a number of groups in the range of
2~10. The following describes how multiple instances run concurrently in groups:If the time span of the data timestamps is less than the number of groups, the tasks run concurrently in groups.
For example, if the data timestamps are from
January 11 to January 13and the number of groups is 4, only three data backfill instances are generated, one for each data timestamp. The three instances run concurrently in groups.If the number of data timestamps is greater than the number of groups, the platform runs a combination of serial and parallel tasks based on the data timestamp order.
For example, if the data timestamps are from
January 11 to January 13and you set the number of groups to 2, two data backfill instances are generated and run in parallel. One of these instances contains two data timestamps, and the tasks corresponding to these timestamps are run sequentially.
Alert for Data Backfill
Set whether this data backfill operation will trigger an alert.
Yes: An alert is generated for data backfill if the trigger condition is met.
No: This data backfill will not trigger alerts.
Trigger Condition
Only when Alert for Data Backfill is set to Yes can you specify the alert trigger condition:
Alert on Failure or Success: An alert is generated regardless of whether the data backfill is successful or fails.
Alert on Success: An alert is generated if data backfill is successful.
Alert on Failure: An alert is generated if data backfill fails.
Alert Notification Method
You can select to receive alerts by Text Message and Email, Text Message, or Email only if Alert for Data Backfill is set to Yes. The alert recipient is the initiator of the data backfill.
NoteYou can click Check Contact Information to verify whether the mobile phone number or email address of the alert contact is registered. If it is not registered, you can refer to View and set alert contacts to configure the information.
Order
Select Ascending by Business Date or Descending by Business Date as the order for the data backfill.
Resource Group for Scheduling
Specify the resource group used to run the data backfill instances.
Follow Task Configuration: Uses the resource group configured for the auto triggered task to execute the data backfill instance.
Specify Resource Group for Scheduling: Use a specified resource group to execute the data backfill instance. This prevents the data backfill instance from competing for resources with recurring instances.
NoteEnsure the resource group has network connectivity, otherwise the task may fail. If the specified resource group is not attached to the relevant workspace, the original resource group of the auto triggered task will be used.
We recommend that you use Serverless Resource Groups or Exclusive Resource Groups for Scheduling, which provide dedicated compute resource groups to ensure fast and stable data transmission when tasks run with high concurrency and cannot be staggered.
Execution Period
Specify when the data backfill tasks generated this time will be executed.
Follow Task Configuration: The data backfill instance runs at its scheduled time.
Specify Time Period: Data backfill tasks are triggered to run only within the specified time period. Set an appropriate running time period based on the number of tasks that require data backfilling.
NoteTasks that are in a non-running state beyond this time period will not be executed. Tasks that are in a running state beyond this time period will continue to execute.
Computing Resource
Currently, only EMR and Serverless Spark compute resources can be set as compute resources for data backfill.
Ensure that the mapped compute resource exists and is active, otherwise task scheduling may be affected.
Configure data backfill task validation policies.
This is used to configure whether to stop task execution if the data backfill validation fails. The platform checks the basic information and potential risks of this data backfill task, as follows:
Basic information: The number of nodes involved in this data backfill, the number of instances generated, and whether there are situations such as node loops, isolated nodes, or instances without permissions.
Risk detection: Checks for task dependency loops and isolated nodes. Either of these can cause the task to run abnormally. You can set an option to terminate the data backfill task if the check fails.
Click Submit. A data backfill task is created.
Step 3: Run the data backfill task
When the configured running time for the data backfill task is reached and no abnormalities are found, the data backfill task automatically triggers and runs.
The data backfill task does not run if the following conditions are met:
The verification feature is enabled for the data backfill task and the verification fails. For more information, see Step 2: Create a data backfill task.
If extension checks are enabled for the data backfill operation, a failed check blocks the task from running. For more information, see Extension Program Overview.
Manage data backfill instances
Query data backfill instances
In the navigation pane on the left, click .

On the right side of the Data Backfill page, click Show Search Options and specify filter conditions, such as Retroactive Instance Name, Status, and Node Type, to search for instances. You can also terminate multiple running data backfill tasks at once.
View data backfill instance status

In this area, you can view information about the data backfill instance, including the following:
Node Name: The name of the data backfill instance. Click the
 icon next to the instance name to view its run date, run status, and the included nodes and their run details.
icon next to the instance name to view its run date, run status, and the included nodes and their run details.Check Status: The check status of the current data backfill instance.
Running Status: The status of the data backfill instance. Valid values are Succeeded, Run failed, Waiting for resources, and Pending. You can troubleshoot issues based on an abnormal status.
Nodes: The number of nodes in the data backfill instance.
Data Timestamp: The date on which the data backfill instance is run.
View Task Analysis Results: You can view the estimated number of generated instances, the run date, and the risk check results to promptly handle blocked tasks.
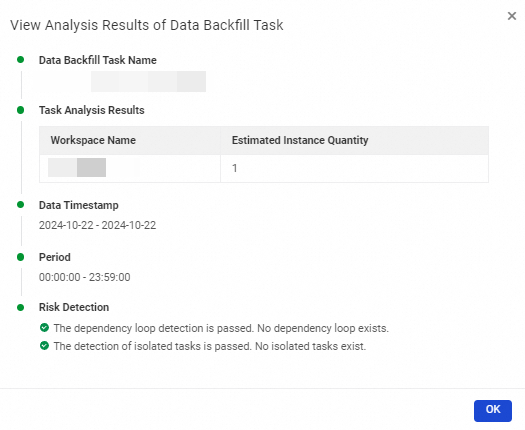
Actions: You can perform operations such as Stop, Batch Rerun, and Reuse on data backfill instances.
Operation Name
Description
Stop
You can batch stop data backfill instances that are in the Running state. After you perform this operation, the corresponding instances are set to the Failed state.
NoteYou cannot stop instances with the Not Running, Succeeded, or Failed status.
Batch Rerun
Rerun the data backfill instances in a batch.
NoteOnly instances in the Succeeded or Failed state can be rerun.
If you perform this operation, selected data backfill instances are immediately rerun at the same time. The scheduling dependencies between the instances are not considered. If you want to rerun data backfill instances in sequence, you can select Rerun Descendant Nodes or perform the Data Backfill operation again.
Reuse
You can choose to reuse the node set from a previous data backfill operation, making it easy to quickly select the nodes for which to backfill data.
Manage data backfill tasks
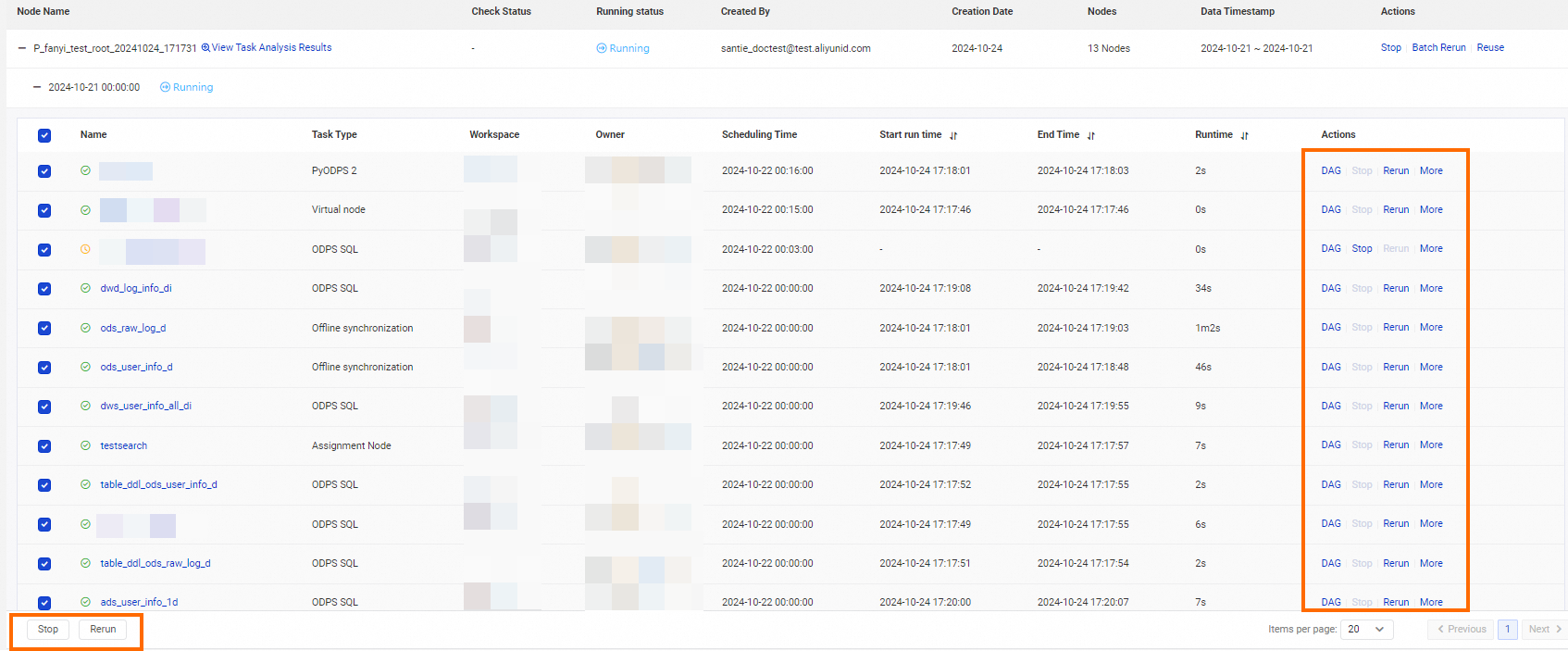
In this area, you can view information about the nodes included in the data backfill instance, including the following:
Name: Click the node name to open the node details page and view more node information.
Scheduling Time: The scheduled run time for the node task.
Start Run Time: The time when the node task starts to run.
End Time: The time when the node task finishes running.
Runtime: The length of time that the node task runs.
Actions: You can view the DAG, or Stop or Rerun the data backfill node task.
Operation Name
Description
DAG
View the DAG of the task to identify ancestor and descendant tasks of the task. For more information, see Appendix: DAG graph features.
Stop
You can stop a node that is in the Running state. After you perform this operation, the status of the node is set to Failed.
NoteYou cannot stop a node in the Not Running, Succeeded, or Failed state.
This operation will cause the instance to fail and block the execution of its descendant nodes. Be aware of the risks and proceed with caution.
Rerun
Rerun the target node task.
NoteYou can only rerun nodes whose status is Succeeded or Failed.
More
Rerun Descendant Nodes
Rerun the descendant nodes of the target node task.
Set Status to Successful
Set the status of this node task to Succeeded.
Freeze
Set the current node to a paused (frozen) state and stop its scheduling.
NoteYou cannot freeze a task that is in the Waiting for Resources, Waiting for Scheduling Time, or Running state. The Running state includes cases where the node code is running or a data quality check is in progress.
Unfreeze
Resume scheduling for a paused (frozen) node.
View Lineage
View the node's data lineage graph.
You can select one or more task nodes and click Stop or Rerun to stop or rerun them in a batch.
Instance status description
Status Type | Status Icon |
Succeeded status |
|
Not Run status |
|
Failed status |
|
Running status |
|
Waiting status |
|
Frozen status |
|






FAQ
Why doesn't group execution for data backfill work for hourly and minute-level tasks?
Why are multiple data backfill instances generated when I backfill data from 00:00 to 01:00?
Data backfill is enabled for a node, but no data backfill instances are generated. Why?
How do I backfill data for tasks that are scheduled to run by week or month?