The Microsoft SQL Server output component writes data to a Microsoft SQL Server data source. After you configure the source data source, configure the Microsoft SQL Server output component as the target data source to complete the synchronization pipeline.
Prerequisites
A Microsoft SQL Server data source is created. For more information, see Create a Microsoft SQL Server data source.
The account used to configure the Microsoft SQL Server output component properties must have write-through permission for the data source. If you do not have the permission, you need to request the data source permission. For more information, see Apply for, Renew, and Return Data Source Permissions.
Procedure
In the top navigation bar of the Dataphin homepage, choose Develop > Data Integration.
In the top navigation bar of the integration page, select Project (In Dev-Prod mode, you need to select an environment).
In the navigation pane on the left, click Batch Pipeline, and then click the offline pipeline that you want to develop in the Batch Pipeline list to open the configuration page of the offline pipeline.
Click Component Library in the upper-right corner of the page to open the Component Library panel.
In the navigation pane on the left of the Component Library panel, select Outputs, find the Microsoft SQL Server component in the output component list on the right, and drag the component to the canvas.
Click and drag the
 icon of the target input component to connect it to the current Microsoft SQL Server output component.
icon of the target input component to connect it to the current Microsoft SQL Server output component.On the Microsoft SQL Server output component, click the
 icon to open the Microsoft SQL Server Output Configuration dialog box.
icon to open the Microsoft SQL Server Output Configuration dialog box.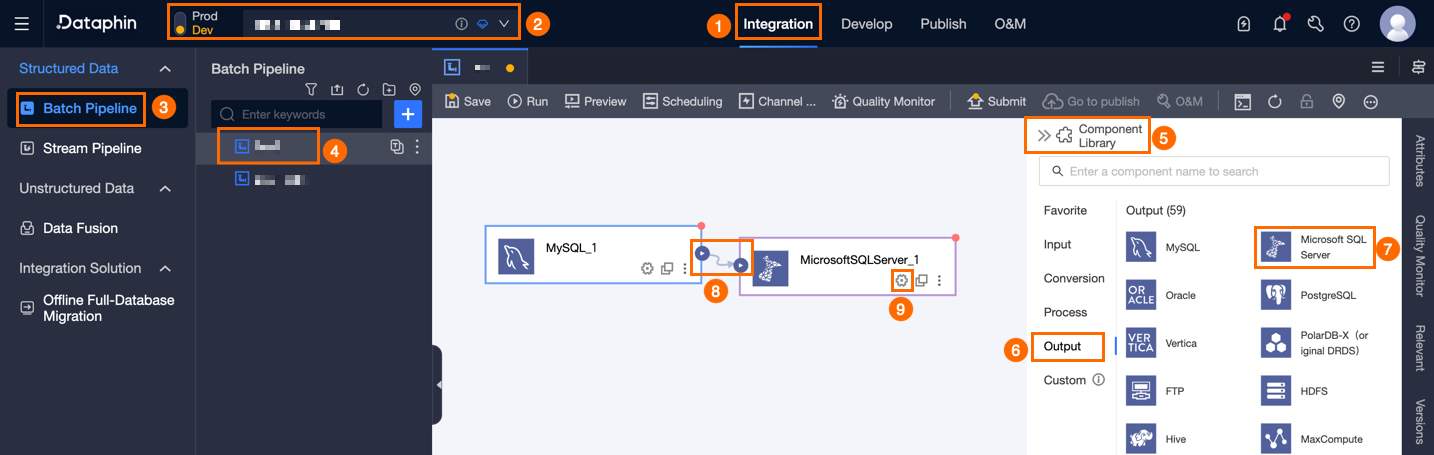
In the Microsoft SQL Server Output Configuration dialog box, configure the parameters.
Parameter
Description
Basic Settings
Step Name
The name of the output component. Dataphin generates a default name that you can change. The name must meet the following requirements:
It can contain only Chinese characters, letters, underscores (_), and digits.
It can be up to 64 characters in length.
Datasource
Lists all Microsoft SQL Server data sources, regardless of whether you have write-through permission. Click the
 icon to copy the data source name.
icon to copy the data source name.For data sources without write-through permission, click Request next to the data source to request permission. For more information, see Apply for, Renew, and Return Data Source Permissions.
If you do not have a Microsoft SQL Server data source, click Create Data Source to create a data source. For more information, see Create a Microsoft SQL Server data source.
Time Zone
Time-format data is processed according to the specified time zone. Defaults to the time zone configured in the selected data source and cannot be modified.
NoteFor tasks created before V5.1.2, you can select Data Source Default Configuration or Channel Configuration Time Zone. The default selection is Channel Configuration Time Zone.
Data Source Default Configuration: The default time zone of the selected data source.
Channel Configuration Time Zone: The time zone configured in Properties > Channel Configuration for the current integration task.
Schema (Optional)
Allows cross-schema table selection. Select the schema where the table is located. If not specified, the schema configured in the data source is used.
Table
Select the target table for output data. You can search by keyword or enter the exact table name and click Exact Match. After you select a table, the system automatically checks the table status. Click the
 icon to copy the selected table name.
icon to copy the selected table name.Loading Policy
The policy for writing data to the target table. Options:
Append Data (insert Into): When there is a primary key/constraint conflict, a dirty data error will be displayed.
Update On Primary Key Conflict (merge Into): When there is a primary key/constraint conflict, the data of the mapped fields will be updated on the existing record.
Synchronous Write
The primary key update syntax is not atomic. If the data contains duplicate primary keys, enable synchronous write. Otherwise, parallel write is used. Synchronous write performance is lower than parallel write.
NoteThis option is only available when the loading policy is set to Update on Primary Key Conflict.
Batch Write Data Size
The maximum data size per batch write. You can also set Batch Write Records. The system writes data when either limit is reached first. Default: 32M.
Batch Write Records
The maximum number of records per batch write. Default: 2048 records. The batch write strategy uses both Batch Write Records and Batch Write Data Size.
When the accumulated data reaches either limit (batch write data size or record count), the system considers the batch full and writes it to the target.
We recommend setting the batch write data size to 32 MB. Adjust the record count based on your actual record size to maximize batch write efficiency. For example, if each record is about 1 KB, set the batch data size to 16 MB and set the record count above 16 MB / 1 KB = 16,384, such as 20,000 records. With this configuration, the system triggers a batch write whenever accumulated data reaches 16 MB.
Prepare Statement
Optional. SQL statements to execute on the database before data import.
For example, to ensure continuous service availability, the component first creates a target table Target_A, writes data to Target_A, then renames the active table Service_B to Temp_C, renames Target_A to Service_B, and finally drops Temp_C.
End Statement
Optional. SQL statements to execute on the database after data import.
Field Mapping
Input Fields
Lists the input fields from the upstream component output.
Output Fields
Lists the output fields. You can perform the following operations:
Field Management: Click Field Management to select output fields.
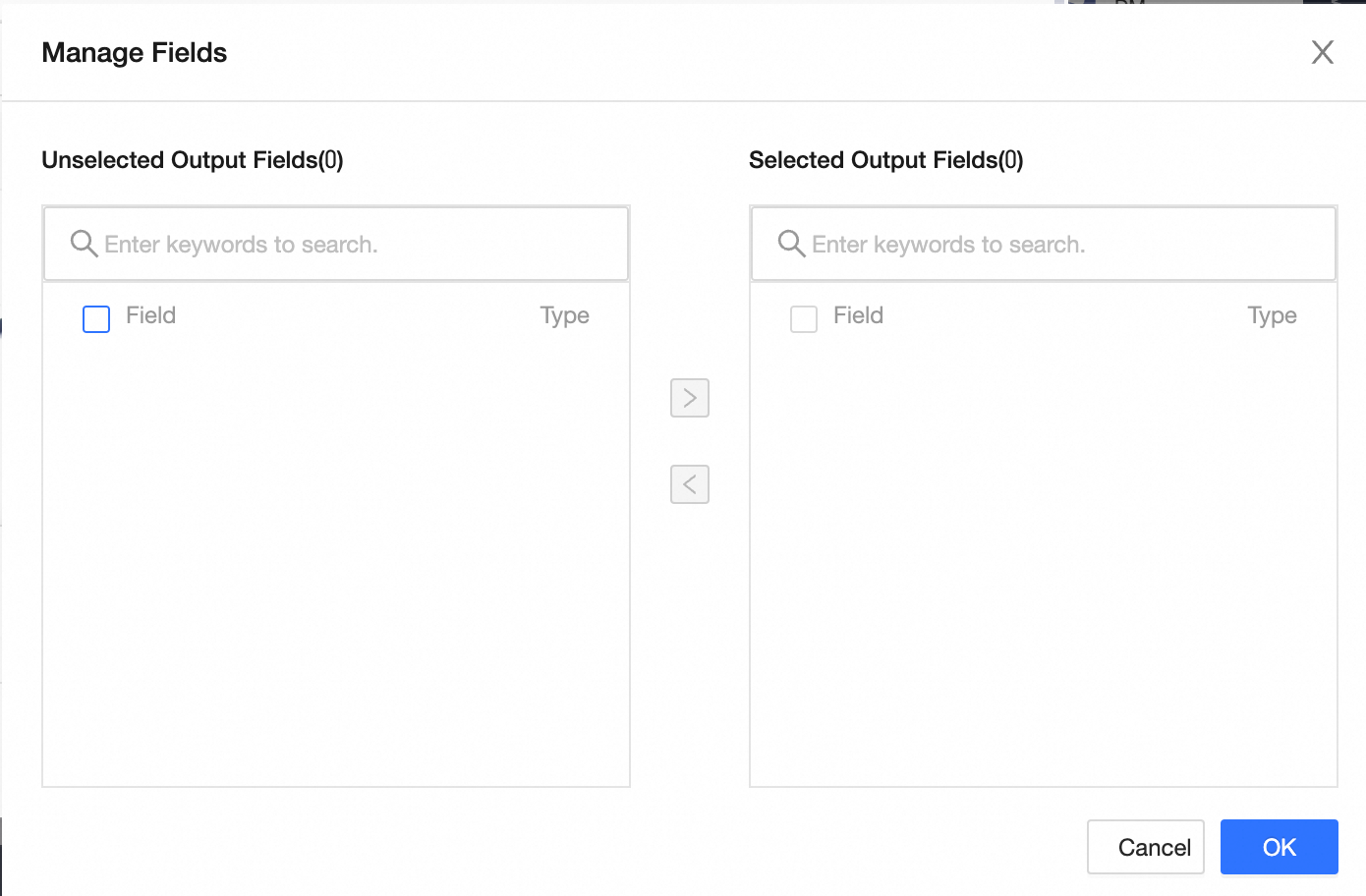
Click the
 icon to move Selected Input Fields to Unselected Input Fields.
icon to move Selected Input Fields to Unselected Input Fields.Click the
 icon to move Unselected Input Fields to Selected Input Fields.
icon to move Unselected Input Fields to Selected Input Fields.
Batch Add: Click Batch Add to support batch configuration in JSON, TEXT, and DDL formats.
Batch configuration in JSON format, for example:
// Example: [{"name":"id","type":"String"}, {"name":"aaasa","type":"String"}, {"name":"creator","type":"String"}, {"name":"modifier","type":"String"}, {"name":"creator_nickname","type":"String"}, {"name":"modifier_nickname","type":"String"}, {"name":"create_time","type":"Date"}, {"name":"modify_time","type":"Date"}, {"name":"qbi_system_upload_id","type":"Long"}]Notenameis the field name andtypeis the field type after import. For example,"name":"user_id","type":"String"imports a field named user_id with the type String.Batch configuration in TEXT format, for example:
// Example: id,String aaasa,String creator,String modifier,String creator_nickname,String modifier_nickname,String create_time,Date modify_time,Date qbi_system_upload_id,LongThe row delimiter separates field entries. Default: line feed (\n). Supported: line feed (\n), semicolon (;), and period (.).
The column delimiter separates the field name from the field type. Default: comma (,).
Batch configuration in DDL format, for example:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
Create New Output Field: Click +Create New Output Field, fill in Column and select Type as prompted. After completing the configuration for the current row, click the
 icon to save.
icon to save.
Quick Mapping
Maps upstream input fields to target table fields. Quick Mapping supports Same Row Mapping and Same Name Mapping.
Same Name Mapping: Maps fields with the same name.
Same Row Mapping: Maps fields by their row position, even if the source and target field names differ.
Click OK to complete the property configuration of the Microsoft SQL Server output component.