Alibaba Cloud Knative can integrate with the Horizontal Pod Autoscaler (HPA) to enable auto scaling based on resource load. Although Knative natively supports auto scaling based on the number of requests, integrating with HPA allows for fine-grained scaling using additional metrics such as CPU and memory utilization.
Prerequisites
Before you begin, ensure that you have:
-
Knative deployed in your ACS cluster. See Deploy Knative
-
kubectl connected to the cluster. See Obtain the kubeconfig file of a cluster and use kubectl to connect to the cluster
-
(Optional) Knative integrated with Managed Service for Prometheus, if you want to view monitoring data in the Knative dashboard. See View the Knative monitoring dashboard
Step 1: Deploy a Knative service with HPA
-
Log on to the ACS console. In the left-side navigation pane, click Clusters.
-
On the Clusters page, click the ID of the cluster you want to manage. In the left-side navigation pane of the cluster details page, choose Applications > Knative.
-
On the Services tab, select default from the Namespace drop-down list, click Create from Template, paste the following YAML into the editor, and click Create.
HPA annotation reference:
Annotation Possible values Default autoscaling.knative.dev/class"hpa.autoscaling.knative.dev","kpa.autoscaling.knative.dev""kpa.autoscaling.knative.dev"autoscaling.knative.dev/metric"cpu","memory""concurrency"autoscaling.knative.dev/targetInteger. Specifies the threshold of the selected metric. HPA automatically scales pods when the threshold is exceeded. — autoscaling.knative.dev/minScaleInteger. Specify the minimum number of pods that must be guaranteed. — autoscaling.knative.dev/maxScaleInteger. Specify the maximum number of pods that are allowed. — apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go-hpa spec: template: metadata: labels: app: helloworld-go-hpa annotations: autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev" # Use HPA instead of the default KPA autoscaling.knative.dev/metric: "cpu" # Scale on CPU utilization; also supports "memory" autoscaling.knative.dev/target: "30" # Specify the threshold of CPU utilization. HPA automatically scales pods when the threshold is exceeded. autoscaling.knative.dev/minScale: "1" # Minimum pod count (HPA does not support scale to zero) autoscaling.knative.dev/maxScale: "4" # Maximum pod count spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:v1024 resources: requests: cpu: '200m' -
Verify the Knative service is ready:
kubectl get ksvcExpected output:
NAME URL LATESTCREATED LATESTREADY READY REASON helloworld-go-hpa http://helloworld-go-hpa.default.example.com helloworld-go-hpa-00001 helloworld-go-hpa-00001 TrueTruein theREADYcolumn confirms the Knative service is running.
Step 2: Test auto scaling with a CPU load
-
Install hey, an HTTP load testing tool.
-
Run a 60-second load test at 100 QPS (queries per second):
hey -z 60s -q 100 \ -host "helloworld-go-hpa.default.example.com" \ "http://<gateway-ip>?prime=40000000"Replace
<gateway-ip>with the IP address or domain name of your gateway. -
While the test runs, watch pod scaling in real time:
kubectl get pods --watchExpected output:
NAME READY STATUS RESTARTS AGE helloworld-go-hpa-00001-deployment-67cc8f979b-fxfl5 2/2 Running 0 101m helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 0/2 Pending 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 0/2 Pending 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 0/2 Pending 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 0/2 Pending 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 0/2 ContainerCreating 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 0/2 ContainerCreating 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 0/2 ContainerCreating 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 0/2 ContainerCreating 0 0s helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 1/2 Running 0 1s helloworld-go-hpa-00001-deployment-67cc8f979b-kv6rj 2/2 Running 0 1s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 1/2 Running 0 1s helloworld-go-hpa-00001-deployment-67cc8f979b-fxq85 2/2 Running 0 1sHPA scales the pod count from 1 to 4 in response to the increased load.
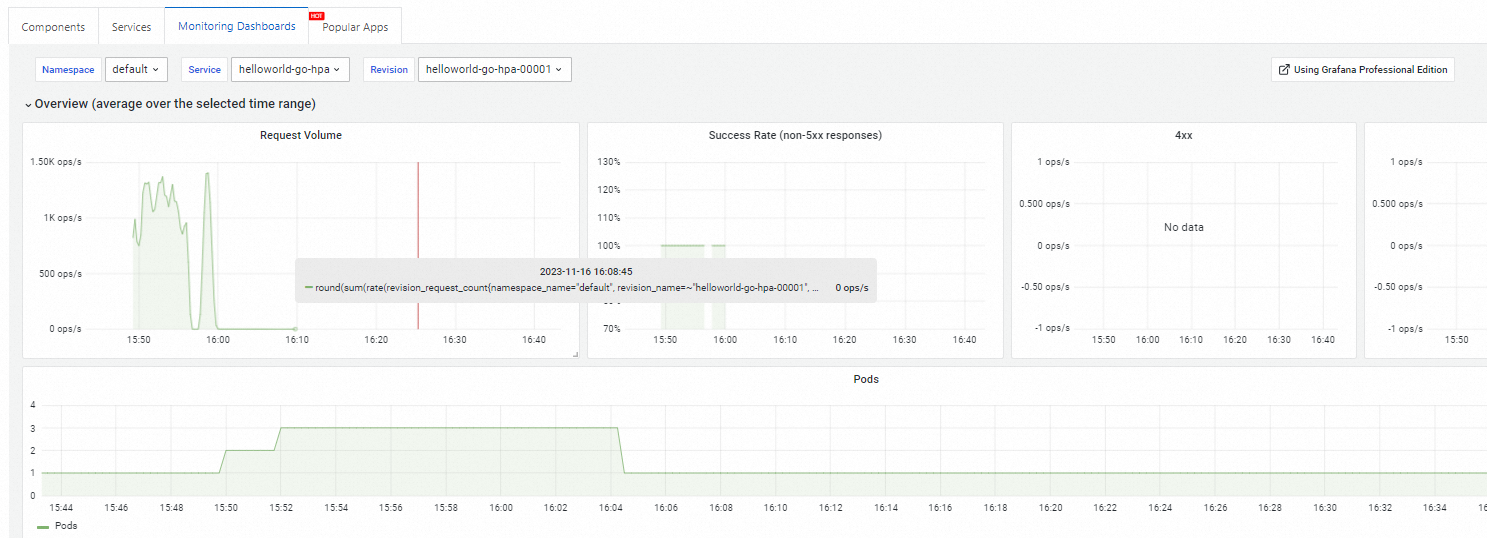
(Optional) Step 3: View the Knative monitoring dashboard
On the Knative page, click the Monitoring Dashboards tab to view the monitoring data of your Knative service.
This requires Knative to be integrated with Managed Service for Prometheus. See View the Knative monitoring dashboard.
What's next
-
Knative overview — Learn how Alibaba Cloud Knative integrates containers, workload management, and event models into a Kubernetes-based serverless framework.
-
Comparison between Alibaba Cloud Knative and open source Knative — See what features Alibaba Cloud Knative adds on top of open source Knative.