When multiple GPU pods share a GPU-HPN node, assigning GPUs that span hardware group boundaries degrades inter-GPU communication performance. Container Compute Service (ACS) prevents this by dividing each node's GPUs into topology-aligned partitions and assigning each pod a contiguous set of devices based on the physical GPU interconnect layout.
Prerequisites
Before you begin, ensure that:
Your pods use the
gpu-hpncompute class and run on the corresponding node types
How it works
GPU devices on a node use one or more channels to interconnect and communicate. On a GPU-HPN node, GPUs within the same group are directly interconnected, while groups connect across boundaries through PCIe. ACS divides GPUs into topology-aligned partitions so that each pod receives devices that share the fastest interconnect.
The following figure shows an eight-GPU node arranged in two groups of four, where intra-group GPUs are directly interconnected and inter-group traffic uses PCIe.
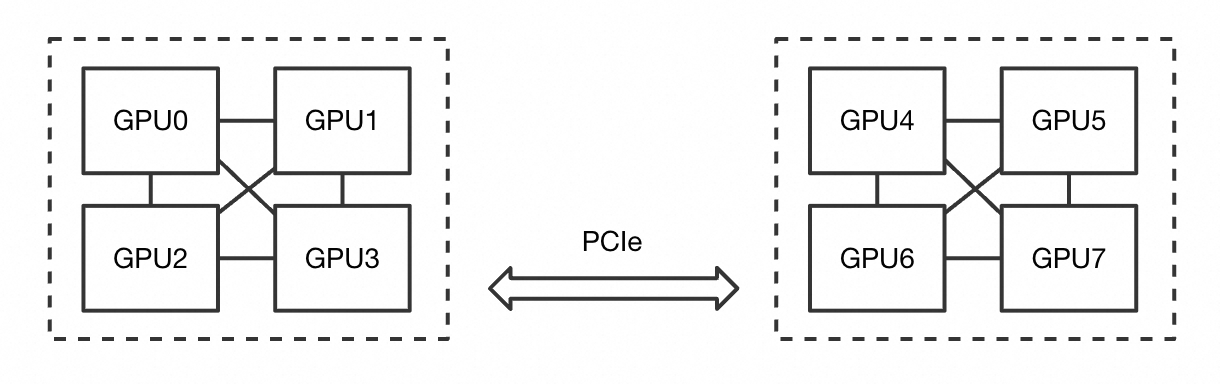
ACS assigns devices based on the number of GPUs a pod requests:
| GPUs requested | Possible device assignments |
|---|---|
| 8 | [0,1,2,3,4,5,6,7] |
| 4 | [0,1,2,3], [4,5,6,7] |
| 2 | [0,1], [2,3], [4,5], [6,7] |
| 1 | [0], [1], [2], [3], [4], [5], [6], [7] |
As pods are created and deleted, GPU devices can become fragmented into unusable partitions. A pod that requires a contiguous partition may enter the Pending state and remain there until the partition is freed. The scheduler does not automatically resolve this — you must free the partition manually by evicting lower-priority pods.
Partition tables by node type
The available partitions vary by node model. The following sections list the partition layouts for each supported node type.
gpu.p16en-16XL
This node has 16 GPUs of the P16EN type. ACS creates partitions as follows:
| GPUs requested | Possible device assignments |
|---|---|
| 16 | [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] |
| 8 | [0,1,2,3,4,5,6,7], [8,9,10,11,12,13,14,15] |
| 4 | [0,1,2,3], [4,5,6,7], [8,9,10,11], [12,13,14,15] |
| 2 | [0,3], [1,2], [4,7], [5,6], [8,11], [9,10], [12,15], [13,14] |
| 1 | [0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15] |
Check scheduling results
View device assignment for a pod
For each GPU-HPN pod, the assigned devices are recorded in the pod's annotations under the alibabacloud.com/device-allocation key.
apiVersion: v1
kind: Pod
metadata:
annotations:
alibabacloud.com/device-allocation: '{"gpus": {"minor": [0,1,2,3]}}'Diagnose a Pending pod
If a pod cannot be scheduled, run kubectl describe pod to view the failure reason:
kubectl describe pod pod-demoA message containing Insufficient Partitioned GPU Devices indicates the pod is stuck due to GPU partition fragmentation:
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 26m default-scheduler 0/5 nodes are available: 2 Node(s) Insufficient Partitioned GPU Devices, 1 Node(s) xxx, 2 Node(s) xxx.Resolve partition fragmentation
To free up a contiguous partition for the pending pod:
Determine how many GPUs the pending pod requests — for example, eight GPUs.
On the target node, check the
alibabacloud.com/device-allocationannotation of each running pod to see which devices are assigned.Identify which pods to evict so that the freed devices satisfy both the count requirement and the partition constraints. For example, a pod requesting eight P16EN GPUs requires that all devices in
[0,1,2,3,4,5,6,7]or[8,9,10,11,12,13,14,15]are unassigned.Evict the identified pods:
kubectl evict <pod-name> # or kubectl delete pod <pod-name>
Scheduler compatibility
The following table shows which schedulers are topology-aware for GPU-HPN nodes.
| Scheduler type | Conditions | Behavior |
|---|---|---|
| ACS default scheduler | All of the following conditions are met: the cluster type is ACS; the schedulerName of the pod is default-scheduler; one of the following version conditions is met: the scheduler version is v1.32.0-apsara.6.11.8.507bee55 or later, v1.31.0-aliyun-1.5.0 or later, v1.30.3-aliyun-1.6.0 or later, or any version from 1.33 onwards; OR the scheduler is another version and Enable custom tags and scheduler for GPU-HPN nodes is not checked. See kube-scheduler. | The scheduler is aware of the current partition allocation on the node. Nodes that do not meet the partition requirements are excluded from scheduling. The failure event for an affected pod includes Insufficient Partitioned GPU Devices. |
| ACK default scheduler | All of the following conditions are met: the cluster is an ACK managed cluster, ACK One registered cluster, or ACK One distributed workflow Argo cluster; the schedulerName of the pod is default-scheduler; the scheduler version is v1.30.3-apsara.6.11.8.\* or later, v1.32.0-apsara.6.11.8.\* or later, v1.33.0-apsara.6.11.8.\* or later, v1.34.0-apsara.6.11.8.\* or later, or any version from 1.35 onwards. See kube-scheduler. | |
| Other cases | Cases that do not meet the preceding conditions. | The scheduler is not partition-topology-aware. The GPU-HPN node packs devices during allocation. If partition requirements are not met, the pod stays in the Pending state until requirements are satisfied. The failure message includes Insufficient Partitioned GPU Devices. To resolve this, see Resolve partition fragmentation. |
FAQ
How do I avoid partition fragmentation in the first place?
The most effective approach is to set different group tags for nodes to separate workloads by GPU requirement. Assign nodes dedicated to large tasks (such as eight-GPU jobs) separately from nodes used by small tasks (such as single-GPU jobs). This prevents large and small workloads from competing for the same partitions.
If your cluster has too few nodes for this kind of grouping, use GPU pod capacity reservation to reserve resources for specific workloads in advance.
When fragmentation has already occurred, use descheduling to evict lower-priority pods and free up partitions for pending workloads.
What should I know about partition scheduling when using a custom scheduler?
When a custom scheduler assigns a pod to a node, ACS handles device allocation on that node and packs pods tightly to minimize fragmentation. The custom scheduler only needs to account for the total GPU capacity of a node — it does not need to be aware of partition constraints.
For GPU resources, configure the MostAllocated node scheduling policy. This keeps workloads consolidated on fewer nodes, which reduces the chance of fragmentation across the cluster.